どうも、AdansonsのPdMの樋口です。
タイトルの通りですが、機械学習をやるときにありがちな面倒臭い作業を自動化するBaseというツールを作っています。
テストユーザーを募集しているので、ぜひフィードバックしてください!
Get Invitation Form
↓↓↓
データをコード上で解析に使えるようになるまでに手間かかりすぎ!
アノテーションに人手がかかることはよく注目されるけど、アノテーションなどのメタデータを記録したファイルとデータファイルを紐付けて解析するための事前準備ってめちゃくちゃ手作業で頑張ってるよね、って実体験を踏まえて考え始めたのがこのツールを作り始めたきっかけです。
特に画像や音声データなどの非構造化データを使う際は、データファイルにメタデータを付与することが難しいので、複数のCSVファイルを参照しながらデータを選出する複雑なデータローダー関数を実装したり、フォルダ構造やファイル名としてメタデータを付与する作業が必要になるわけです。
まだメタデータのファイルの内部構造が整っている場合ならマシなんですが、アノテーターによってカラム名がちょっと変わったり、カラムの順番が入れ替わったりした日には最悪で、プロジェクトメンバーの誰かが手作業で内部構造を修正するか、データローダー関数側で対応しようとして分岐に溢れた複雑で保守性に欠けたコードを産み出すことになります...orz

また、フォルダ構造としてメタデータを記述すると、メタデータを更新・修正するのが難しくなるだけでなく、データをプロジェクトメンバーそれぞれのローカルに配置して解析する場合であれば、解析コードやデータローダー関数が動かなくなることもあります。
こういった事前準備とも言える作業って、データサイエンティストのバリューが出るところではないにも関わらず、多くの人が手作業で解決していてかつ技術的負債になるのは、労多くして功少なしともいうべき事態です。
今よりもっとメタデータを柔軟に追加(紐付け)・編集できるようになり、データセット作成が簡単になれば、これらの課題が解決するだけでなく、より細かい条件でデータをフィルターしながらデータセントリックに深い考察が得られるようになってデータサイエンティストとしてのバリューをこれまで以上に発揮できると思うわけです。
「人工知能の権威アンドリュー・エンが語る「データの質」の重要性」
だからフォルダ名やCSVなどの外部ファイルを読み取るコードを実装しなくても、簡単にデータを条件で絞り込むためのツールを作ったよ!

要は、メタデータのファイルやフォルダ構造に記録されたメタデータを抽出し、整理されたデータベースを作るツールです。
これだけ聞くといわゆるデータカタログなどのサービスとあまり違いがわからないと思うので、こだわりポイントをちょこっと紹介したいと思います。
ポイント1. メタデータファイルの内部構造の表記揺れに対応した抽出ができるようにする
見ての通り官庁主導で声かけするぐらい、世の中にはそのままでは解析に使えないデータ(しかも貴重なデータ)が溢れています。
人に見やすい構造≠機械が解析しやすい(機械判読可能な)構造です。
また、機械が自動的に生成するデータであっても、部署間で仕様変更の共有が十分になされず、構築したデータパイプラインが突然停止することもあります。
データは利用者ごとに都合のいい構造が違うわけですから、データの生成者と解析者のそれぞれにとって都合がいい構造と相互変換できるようなインタフェースを作るべきです。
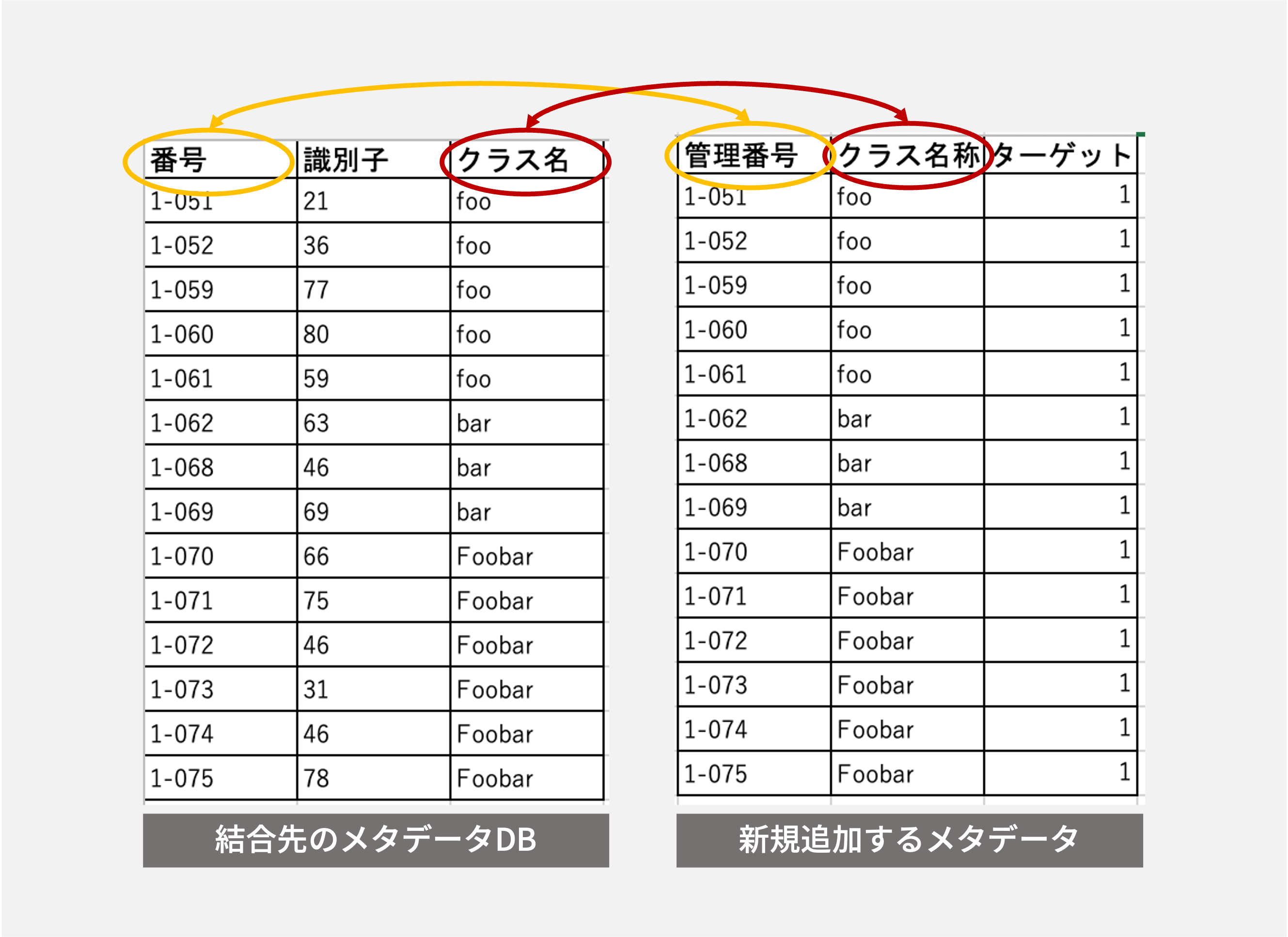
ポイント2. メタデータの値の表記揺れや重複を判別し、自動でメタデータDBに追加メタデータのテーブルを統合できるようにする
データセットの事前準備で、手作業が多発するもう1つの原因は、メタデータの表記揺れです。
例えばアノテーターによってテーブルデータのカラム名に表記揺れがあったり、メタデータファイルを生成した機械によっては重複した内容のカラムであってもデータ型の種類(文字列, 数値, ...)が違うことがあります。
これらの仕様の揺らぎによるエラーが生じないように手作業で修正するのは、決して楽な作業ではないですし、メタデータのテーブル同士の情報を紐付ける際に、その揺らぎに対応した分岐を実装をすることは保守性が高いとは言い難いです。
そのため、表記揺れに寛容なシステムを作るべきです。
ポイント3. 画像などのデータファイルはアップロードせず、Hash値を識別子に使用することで、安全で軽量高速なデータベースにする
メタデータは多くの場合、CSVやExcel、JSON形式で記述されており、比較的ファイルの容量は小さいですが、画像や音声といったデータファイルは1つ1つの容量が大きく、数も多いです。
データセット作成するたびに大容量通信をするのは現実的ではなく、また機密性の観点からもデータファイルはユーザー自身の管理下で安全に保管するべきです。
メタデータとデータファイルの紐付けにはデータファイルの識別子があれば十分であり、それにHash値を採用することでフォルダ構造やファイル名を好き勝手編集してもデータファイルを紐付けることができるため、実行環境によってフォルダ構造が一致せず、解析コードが動作しないという問題を防ぐことができます。
このツールを使ってあなたのプロジェクトのデータを整理するには
現在、無料機能を開放してテストユーザーを募集しています!
- Formにメアドを登録する
- Slackに入る
- Slack上で自動BotからAccess Keyを受け取る
- BaseをGithubから
pipでインストールして初めてコマンドを実行する際にAccess Keyを登録する
そしてぜひフィードバックをお願いします!
Get Invitation Form
↓↓↓
(5/18追記)
Baseでデータを解析可能な状態にするために必要な3つのコマンドについて紹介する記事を書きました!