世の中のオタク達はどのような技術に精通している、または興味があるのか
「エンジニア界隈にはオタクが多い」
聞いたことがあるような言葉ですね。業界で働いている方ならそう感じていらっしゃる方も多いのではないでしょうか。
Qiitaでも、アニメ等のコンテンツと関連のある記事がたくさんあると思います。
かく言う私もオタクな訳ですが、今回QiitaAPIについて学習する中で以下のようなことに興味を覚えました。
「世の中のオタク達はどのような技術に精通している、または興味があるのか」
動機としては、これを調査することで自分と似た趣味の人たちがどのような技術に関心を持っているのか知りたいという興味本位なところが大きいです。
それ以外では、自分の好きなことと絡めて技術を習得していくというのはモチベーションを保ちやすく効率がいいと聞いたので、今後自分でどのようなことをやっていくかの参考にできればという考えもあります。
Qiitaには記事の情報を一括で取得するAPIがあるということで、今回はそちらを使ってアニメ関連の記事のデータを取得しようと思います。
それでは、実装とその結果について、順番に書いていきたいと思います。
(結果だけが気になる方は最後まで読み飛ばしてください!)
環境
Node-RED(Heroku環境上で実装)
JavaScript
Node-REDのフロー
今回、以下のようなフローを作成しました。
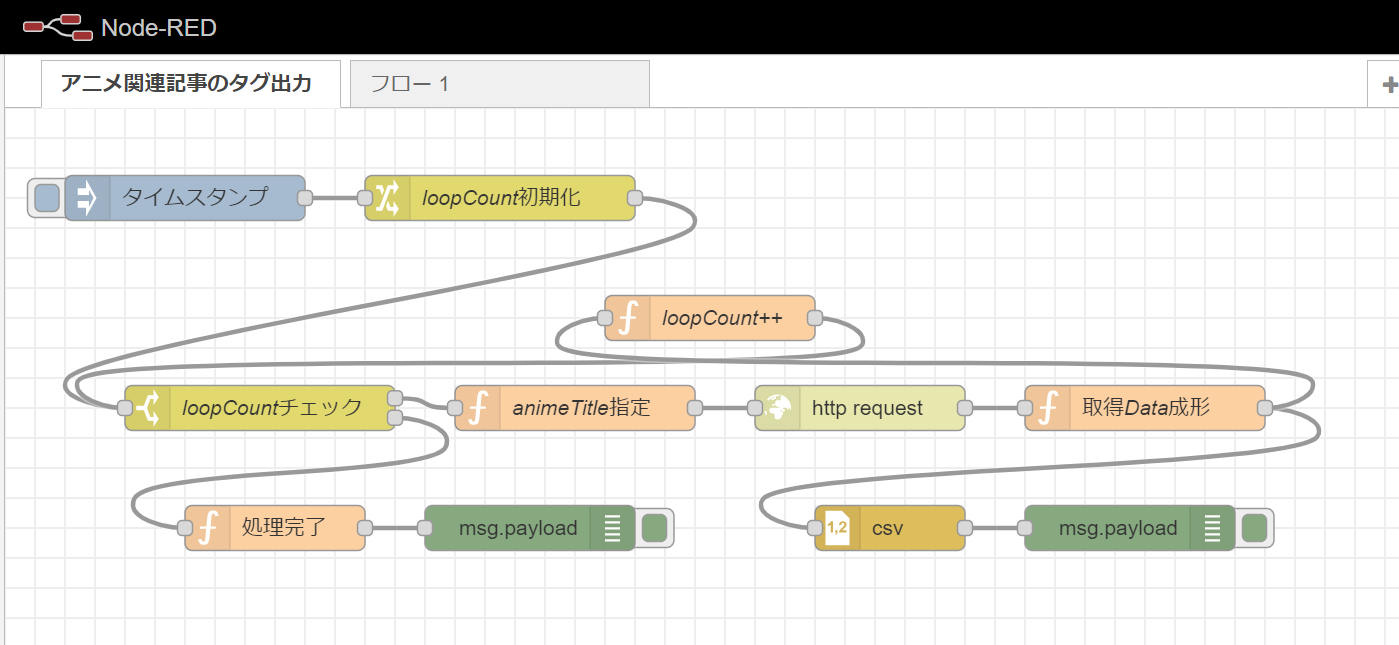
フローをJSON形式で出力したものは以下になります。
[{"id":"6153ec41.8085b4","type":"tab","label":"アニメ関連記事のタグ出力","disabled":false,"info":""},{"id":"4147378a.e3fe28","type":"inject","z":"6153ec41.8085b4","name":"","props":[{"p":"payload"},{"p":"topic","vt":"str"}],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","payload":"","payloadType":"date","x":120,"y":60,"wires":[["6874abe3.523554"]]},{"id":"a8062bd8.de1f98","type":"http request","z":"6153ec41.8085b4","name":"","method":"GET","ret":"txt","paytoqs":"ignore","url":"https://qiita.com/api/v2/items?page=1&per_page=100&query='{{{query}}}","tls":"","persist":false,"proxy":"","authType":"","x":570,"y":200,"wires":[["67b9aa52.79c2e4"]]},{"id":"bab23651.89d368","type":"function","z":"6153ec41.8085b4","name":"animeTitle指定","func":"//QiitaAPIで検索するコンテンツのタイトルを定義\nvar titleArray = [\"ラブライブ\",\n \"アイドルマスター\",\n \"ウマ娘\",\n \"バンドリ\",\n \"ゆるキャン\"]\nvar count = msg.loopCount\n\n//APIのパラメーター指定\nmsg.query = encodeURI(titleArray[count])\nflow.set(\"animeTitle\",titleArray[count])\n\nreturn msg;","outputs":1,"noerr":0,"initialize":"","finalize":"","libs":[],"x":380,"y":200,"wires":[["a8062bd8.de1f98"]]},{"id":"c1d54ba8.e948f8","type":"debug","z":"6153ec41.8085b4","name":"","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"payload","targetType":"msg","statusVal":"","statusType":"auto","x":750,"y":280,"wires":[]},{"id":"67b9aa52.79c2e4","type":"function","z":"6153ec41.8085b4","name":"取得Data成形","func":"var response = msg.payload\n//APIから取得したデータをJson形式に変換\nvar data = JSON.parse(response)\nvar animeTitle = flow.get(\"animeTitle\")\nvar array = []\n\n//取得データを1件ずつ読み込み\nfor(let i = 0; i < data.length; i ++){\n if(data[i]instanceof Object){\n var tag = []\n for(let n = 0; n < 5; n ++){\n //タグの情報を1件ずつ読み込み\n if(data[i].tags[n]instanceof Object){\n tag.push(data[i].tags[n].name)\n }else{\n tag.push(\"\")\n }\n }\n //カンマ区切りのCSV形式でレコード追加\n array.push(animeTitle + \",\" + data[i].title.replace(\",\",\"\") + \",\" + tag)\n }\n}\n\nmsg.payload = array\nreturn msg;","outputs":1,"noerr":0,"initialize":"","finalize":"","libs":[],"x":760,"y":200,"wires":[["a18098a8.8ba518","ef9cc61a.c32b28"]]},{"id":"a18098a8.8ba518","type":"csv","z":"6153ec41.8085b4","name":"","sep":",","hdrin":"","hdrout":"none","multi":"one","ret":"\\n","temp":"","skip":"0","strings":true,"include_empty_strings":"","include_null_values":"","x":590,"y":280,"wires":[["c1d54ba8.e948f8"]]},{"id":"6874abe3.523554","type":"change","z":"6153ec41.8085b4","name":"loopCount初期化","rules":[{"t":"set","p":"loopCount","pt":"msg","to":"0","tot":"num"}],"action":"","property":"","from":"","to":"","reg":false,"x":330,"y":60,"wires":[["350aa9ce.7a7c86"]]},{"id":"350aa9ce.7a7c86","type":"switch","z":"6153ec41.8085b4","name":"loopCountチェック","property":"loopCount","propertyType":"msg","rules":[{"t":"lt","v":"5","vt":"num"},{"t":"else"}],"checkall":"true","repair":false,"outputs":2,"x":170,"y":200,"wires":[["bab23651.89d368"],["3d7eda5.6069226"]]},{"id":"ef9cc61a.c32b28","type":"function","z":"6153ec41.8085b4","name":"loopCount++","func":"msg.loopCount += 1\nreturn msg;","outputs":1,"noerr":0,"initialize":"","finalize":"","libs":[],"x":470,"y":140,"wires":[["350aa9ce.7a7c86"]]},{"id":"3d7eda5.6069226","type":"function","z":"6153ec41.8085b4","name":"処理完了","func":"msg.payload = \"処理完了\"\nreturn msg;","outputs":1,"noerr":0,"initialize":"","finalize":"","libs":[],"x":180,"y":280,"wires":[["a343085e.3aa868"]]},{"id":"a343085e.3aa868","type":"debug","z":"6153ec41.8085b4","name":"","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"payload","targetType":"msg","statusVal":"","statusType":"auto","x":350,"y":280,"wires":[]}]
フローの中身、ソースコード
では、フローの中身やコードについて少し詳しく書いていきたいと思います。
まずはQiitaAPIを呼び出す際のパラメーターとして検索する文言を設定する箇所ですが、今回は自分が好きで、かつ知名度が高く記事も多いと思われるコンテンツを5つピックアップして指定する形にしました。

//QiitaAPIで検索するコンテンツのタイトルを定義
var titleArray = ["ラブライブ",
"アイドルマスター",
"ウマ娘",
"バンドリ",
"ゆるキャン"]
var count = msg.loopCount
//APIのパラメーター指定
msg.query = encodeURI(titleArray[count])
flow.set("animeTitle",titleArray[count])
return msg;
その後、実際にQiitaAPIを使って記事のデータを取得します。
今回使用したAPIは以下になります。
GET /api/v2/authenticated_user/items
(参考)
Qiita API v2ドキュメント
そして、取得した記事データをJSON形式として1件ずつ読み込み、その記事に設定されているタグ(1記事に対して最大5件)を取得し、CSV形式にしていきます。

var response = msg.payload
//APIから取得したデータをJson形式に変換
var data = JSON.parse(response)
var animeTitle = flow.get("animeTitle")
var array = []
//取得データを1件ずつ読み込み
for(let i = 0; i < data.length; i ++){
if(data[i]instanceof Object){
var tag = []
for(let n = 0; n < 5; n ++){
//タグの情報を1件ずつ読み込み
if(data[i].tags[n]instanceof Object){
tag.push(data[i].tags[n].name)
}else{
tag.push("")
}
}
//カンマ区切りのCSV形式でレコード追加
array.push(animeTitle + "," + data[i].title.replace(",","") + "," + tag)
}
}
msg.payload = array
return msg;
ここまでの処理をループさせ、指定したコンテンツ分だけAPIを呼び出し、都度データを出力させています。
※フローのループ処理については以下の記事を参考にしました。
enebularでif分岐やwhileループのようなデータの流れを組むときのTIPS
なお、今回はAPIを呼び出す回数が5回と少なかったため、結果をマージしてCSV形式に整える処理は組まず手で行いました。

↓
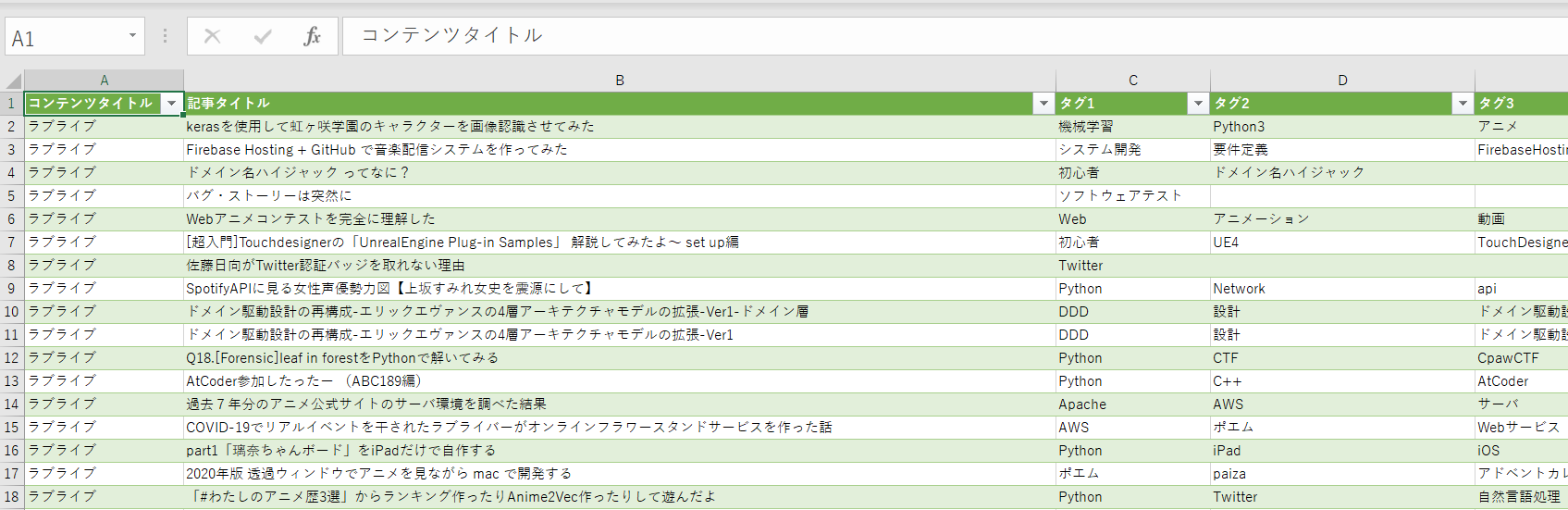
これで分析に必要なデータが整いました。
集計結果
では、お待ちかね(?)の集計結果発表です!ドン!
| 順位 | タグ | 記事数 |
|---|---|---|
| 1 | Python | 70 |
| 2 | AWS | 21 |
| 2 | 機械学習 | 21 |
| 4 | 13 | |
| 4 | JavaScript | 13 |
| 6 | 初心者 | 11 |
| 7 | 自然言語処理 | 9 |
| 7 | Node.js | 9 |
| 9 | ポエム | 8 |
| 9 | データ分析 | 8 |
| 9 | Ruby | 8 |
| 9 | Python3 | 8 |
※総記事数:286件、総タグ数:1430件
※2022/4/8時点のデータ
※コンテンツ名等のタグは集計から除外
今回検索したすべての記事のうち、約4分の1がPython関連の記事であることが分かりました。
考察
1位は断トツでPythonという結果になりました。
Pythonと言えば今流行りの言語という感じですが、やはりオタクが流行に敏感ということがこういうところにも表れてるんですかね!(適当)
…もう少し真面目に考察すると、2位にAWS・機械学習が入っているところを見るに、各コンテンツに関する様々な解析を、AWS環境でPythonを使って行っている人が多いというように感じます。
(例えばキャラの画像を画像解析にかけたり、セリフを自然言語解析にかける等)
また、初心者タグが6位に入っていることからは、自分の好きなコンテンツと絡めてこれまで触ったことのない技術を試してみようという気概がうかがえますね。
あとがき
今回はお試し実装ということで、自分の好きなコンテンツ5つで分析した結果なので、他のコンテンツでやってみれば結果は変わってくるかもしれません。
そんなことも含めて、今回頭には思いついたが時間やスキルの関係上今回は実装しなかったものは以下のようにいくつかあるので、今度時間があれば挑戦してみたいと思います。(多分やらない)
- どこかからコンテンツの一覧を取得して、その分だけAPIを呼び出しデータを取得できるようにする。
- レスポンスデータをプログラムでマージし、CSVファイルとして出力できるようにする。
- コンテンツ毎の傾向についても深堀して分析する。
以上、ここまでお読みいただきありがとうございました!