Grow All !!
初めまして!普段、フロントエンド業務をしているKeitaNと申します。
弊社ニジボックスではリクルート共創の名の下、親会社であるリクルートさんのサービス開発に勤しんでおります。
その中で、過去に某就活支援サービス案件に参画した際、
- Excelでディレクターさんがデータ更新。ツールでJSON変換して表示
- 開発さんがAPIを用意。Ajaxを叩いてデータ取得して表示
という2つのデータ運用形式を体験し、「データって、ExcelからJSONに形式を変換できるんだ...!」とぼんやり印象に残っていました。
また、直近でDjangoやRDBについて個人学習する機会があり、RDBでのテーブルについて軽く学びました。
その時々で感じたことを元に、JavaScript (以下JS)のオブジェクトやJSONと、RDBでのテーブルとのデータ形式(構造)の違い・データの互換性について気になり書いた次第です。
それでは、ゆっくりしていってね!
概要
- JSのオブジェクトやJSON、RDBにおけるテーブルについて軽く話すよ
- オブジェクトやJSONと、テーブルを比較して話すよ
- その他、データ周りの技術に関する小噺をするよ
JS内部のデータ形式やデータ表現の形式
最初に、JS内部のデータ形式やデータ表現の形式はおよそ以下かと思います。
【JS内部のデータ形式】
①ネストされたオブジェクト
②オブジェクトの配列
③多次元配列
【データ表現の形式】
④JSON
⑤CSV
③多次元配列の記載について。
const array = ["A", "B", "C"];
のような一次元配列を普段よく使用しますが、今回は"配列のみでのオブジェクト再現"の文脈で展開していくため ③多次元配列 と記載しております。
データ表現の形式 について
JSONやCSVはテキストベースのデータ交換用フォーマットで、データ形式としては「単なる文字列」であるため、このような記載としました。
オブジェクト世界観
...とその前に、そもそものオブジェクト(指向)について軽く振り返りましょう。
MDNでは以下のように表現されています。
オブジェクトとは、関連するデータや機能の集合体です。
また、JavaScript Primerでは以下のように記載されています。
オブジェクトはプロパティの集合です。プロパティとは名前(キー)と値(バリュー)が対になったものです。
或いは、"ゆるコンピュータ科学ラジオ"さんの動画では以下のように解説されています。(オブジェクト指向について面白く話されて頭に入りやすく、第1~5回をまとめて観るのがオススメです!)
堀本さん「世界をより写実的に描くんならプログラミングをどうしたらよいか、そのパラダイムこそがオブジェクト指向でございます。」
オブジェクトは、森羅万象・あらゆる万物を"オブジェクト"というモノとして捉える世界観です。最近では オブジェクト指向の概念を仏教になぞらえた話や オブジェクト指向菩薩の開眼も耳にしましたね。
そのオブジェクトの例を、大好評配信中の 「最上の、切なさを。」 をテーマにしたRPG ヘブンバーンズレッドで考えてみましょう。
const Ruka = {
height: 159,
instrument: "Vocal",
seraph: "BraveBlue",
seraphimCode: "あたしの伝説はこれから始まる"
};
ここに、キャラクターオブジェクトが誕生しました。本作の主人公です。
更にキャラクター達が集まり、バンド活動を始めました。
洋楽直系のスクリーモ、叙情系ハードコアサウンドを独自の方法論で昇華させた音楽性、2025年2月15日に神奈川県民ホール大ホールでのライブを控えた超絶人気バンドのShe is Legendです。
①ネストされたオブジェクト
このShe is Legendを①ネストされたオブジェクトで表現すると以下の通りです。
const She_is_Legend = {
Ruka: {
height: 159,
instrument: "Vocal",
seraphimCode: "あたしの伝説はこれから始まる",
},
Yuki: {
height: 160,
instrument: "Drums",
seraphimCode: "Hello World",
},
Megumi: {
height: 159,
instrument: "Guitar",
seraphimCode: "救世主様のお出ましや",
},
};
バンドオブジェクトの中にkey(各キャラクター名)が存在し、対応するvalueに各キャラクターオブジェクト(各キャラクター情報)が存在します。
以下は値の取得方法の一例です。
// Optional chaining演算子(`?.`)とブラケット記法を組み合わせ
console.log(She_is_Legend["Ruka"]?.["instrument"]); // => "Vocal"
②オブジェクトの配列
個人的には、ネストされたオブジェクトは実際の開発現場ではあまり見かけず、②オブジェクトの配列の方が見かける機会が多いと思います。
const She_is_Legend = [
{
name: "Ruka",
height: 159,
instrument: "Vocal",
seraphimCode: "あたしの伝説はこれから始まる",
},
{
name: "Yuki",
height: 160,
instrument: "Drums",
seraphimCode: "Hello World",
},
{
name: "Megumi",
height: 159,
instrument: "Guitar",
seraphimCode: "救世主様のお出ましや",
},
];
先ほどのネストされたオブジェクトにおけるkeyの値も、nameプロパティとして追加しました。配列の中に各キャラクターオブジェクトが格納されています。
以下は値の取得方法の一例です。
// 欲しい値が何番目のオブジェクトかすでに把握している場合
console.log(She_is_Legend[1]?.instrument); // => "Drums"
または、特定条件で探す場合の例です。
// 特定条件で探す場合
const Megumin = She_is_Legend.find(person => person.name === "Megumi");
console.log(Megumin?.seraphimCode); // => "救世主様のお出ましや"
③多次元配列
ネストされたオブジェクトと同様、開発現場ではあまり見かけませんが、更にkeyを省略して端的に圧縮する、③多次元配列 でも表現できます。
多次元配列:二次元配列以上の配列のこと。
普段使用する配列(一次元配列)はx軸の1次元で左から右へ直線で流れます。そこからxy軸の縦横に並べた時は二次元、さらにxyz軸の奥行きを加えた三次元...と配列が二次元以上に増えた配列を指します。(四次元以上の配列も存在します。)

よく使用する(一次元)配列でキャラクターを表現するとこうなります。
const Ruka = [159, "Vocal", "あたしの伝説はこれから始まる"];
また、先ほどのバンドオブジェクトを二次元配列で表現するとこうなります。
const She_is_Legend = [
["Ruka", 159, "Vocal", "あたしの伝説はこれから始まる"],
["Yuki", 160, "Drums", "Hello World"],
["Megumi", 159, "Guitar", "救世主様のお出ましや"],
];
以下は値の取得方法の一例です。
// 一つ目の[1]で縦軸から"Yuki"配列を選択、2つ目の[3]で横軸の配列内の値を取得
console.log(She_is_Legend[1][3]); // "Hello World"
④JSON
他に、AjaxでAPIからデータ取得を行う場合は④JSONを使用するでしょう。
JSON(JavaScript Object Notation):JavaScriptオブジェクトの構文に従ったテキストベースのデータ形式。
※「13日の金曜日」に現れる殺人鬼や、"ヤモリ"と呼ばれる、元13区出身の喰種のことではありません。
[
{
"name": "Ruka",
"height": 159,
"instrument": "Vocal",
"seraphimCode": "あたしの伝説はこれから始まる"
},
{
"name": "Yuki",
"height": 160,
"instrument": "Drums",
"seraphimCode": "Hello World"
},
{
"name": "Megumi",
"height": 159,
"instrument": "Guitar",
"seraphimCode": "救世主様のお出ましや"
}
]
先ほどのオブジェクトの配列と似ていますが、いくつか違いもあります。以下はその中からの抜粋です。
- JSONでは、プロパティ名でのダブルクォートが必須+末尾のカンマはNG
e.g. 末尾: 上記では最後のオブジェクトや、各seraphimCodeプロパティ - JSONでは、メソッドや未定義(undefined)は含められない
- オブジェクトの配列(.js)とJSON(.json)で拡張子が異なる
- オブジェクトの配列は直接操作可能だが、JSONは文字列として扱うため、JSON.parse()でパース(解析)してオブジェクトに変換する必要がある
JSONを使う理由
そもそも、なぜオブジェクトの配列ではなくJSON形式でデータのやり取りを行うのでしょうか?
JSONが "JavaScriptオブジェクトの構文に従ったテキストベースのデータ形式" なのであれば、「わざわざJSONにせんでも、JSONの元になったJSのオブジェクト形式利用すれば話早いんとちゃうか?」とも思います。
APIでAjaxからデータを取得するのにJSONが使われる理由を、JSONの標準仕様を定義した文書(ECMA-404) を読み、次のように考えました。
Ecma International:European Computer Manufacturers Association(以前の欧州電子計算機工業会)。コンピューター・ハードウェアや通信、プログラム言語の標準規格を策定する非営利組織。
JSON is a lightweight, text-based, language-independent syntax for defining data interchange formats. It was derived from the ECMAScript programming language, but is programming language independent. JSON defines a small set of structuring rules for the portable representation of structured data.
JSON は、データ交換形式を定義するための軽量でテキストベースの言語に依存しない構文です。ECMAScript プログラミング言語から派生したものですが、プログラミング言語に依存しません。JSON は、構造化データの移植可能な表現のための小さな構造化ルール セットを定義します。
つまり、JSONは特定の言語に依存せず、軽量で移植しやすいデータ構文で、そのメリットから使用されていそうです。また、JSONにおける「関数を含められない」などのルールによって、
- 単純なデータのみに集中できる(余計な内容・記法などが混じらない)
- データ交換の手段で使用するため、多言語間や多層間での通信において関数などを渡されても困るから
- 悪意ある関数での意図しない操作の可能性などを考慮しなくてすむ
といった、運用面やセキュリティ面でのメリットもあるかと思いました。
⑤CSV
フロント開発現場での利用は全く聞いたことはありません(Excelの保存形式として見かけることはあります)が、CSVも選択肢として技術的には可能でしょう。
CSV:Comma-Separated Values(カンマで区切られた値)。
name,height,instrument,seraphimCode
Ruka,159,Vocal,"あたしの伝説はこれから始まる"
Yuki,160,Drums,"Hello World"
Megumi,159,Guitar,"救世主様のお出ましや"
CSVの記法については次の通りです。
- ヘッダー行:1行目のname, height, instrument, seraphimCode は列名を表す
- データ行:2行以降には、各列のデータがカンマで区切られて記載される
- CSVはカンマと改行で各データを表現し、string/numberなど型は関係しない
CSVはどちらかというと、Pythonにおけるデータ分析で活用される拡張子の印象があり、以下のフローになりそうです。
- CSV形式でデータウェアハウスなどにインポートする
- PythonのPandasなどを用いてデータ分析を行う
- 分析結果をJSONに変換。APIでフロントエンド側に渡して表示する
幕間
長々となりましたが、JS内部のデータ形式やデータ表現の形式について見てきました。オブジェクトリテラル・keyとvalueの組み合わせから始まり、徐々に配列の書き方に寄って記載する情報量が減ると多次元配列に至りました。また、多次元配列とCSVは、見た目もかなり近しいように感じます。
上記の内、フロントエンド開発の現場で使用するのは②オブジェクトの配列と④JSONが、個人的には多い気がします。
では続いて、DBにおけるテーブル(行列)について見ていきましょう。
RDBでのテーブル表現
RDB:Relational Database(表で構成し、関連付けるデータベース)。DBは他にも、階層型データベース(ツリー状に構成)やネットワーク型データベース(網状に構成)という種類も存在します。
テーブル世界観
(こちらを引用しました。)
・テーブル・DB設計は「属性」と「関係」の2つだけ
・「属性」は必要なものを書くだけ
・「関係」は 1:1 / 1:N / N:N しかない(しかも、ほとんど 1:N)
DB・テーブルの世界観は「属性」と「関係」の2つです。
単一のテーブル
属性は、キャラクターを表現すると以下のようになります。
| id | name | height | instrument | seraphimCode |
|---|---|---|---|---|
| PK | string | int | string | string |
※PK:primary key(主キー)。重複しないよう一意に識別するためのキー。
e.g. 社員管理システムでの「社員番号」
先ほどのオブジェクトにおけるkey名が1行目に入り、テーブルのカラムになります。
この雛形にキャラクターオブジェクトでのvalueを入れると次のようになります。
| id | name | height | instrument | seraphimCode |
|---|---|---|---|---|
| 1 | Ruka | 159 | Vocal | あたしの伝説はこれから始まる |
これで、主人公 茅森月歌のデータがテーブルに登録されました。
続けて、他キャラクターの情報も登録し、memberテーブルを完成しましょう。
| id | name | height | instrument | seraphimCode |
|---|---|---|---|---|
| 1 | Ruka | 159 | Vocal | あたしの伝説はこれから始まる |
| 2 | Yuki | 160 | Drums | Hello World |
| 3 | Megumi | 159 | Guitar | 救世主様のお出ましや |
列でそのテーブルで扱う「属性」情報が追加され、行で各キャラクターが追加されていきます。以下はこのテーブルにおけるSQLでの取得方法の一例です。
1: テーブル全体で取得する場合
SELECT * FROM member;
2: 特定の列(カラム)で取得する場合
-- name列だけ取得
SELECT name FROM member;
3: 特定の行(レコード)で取得する場合
-- name列が"Ruka"の行を取得
SELECT * FROM member WHERE name = 'Ruka';
4: 特定の行と列で取得する場合
-- seraphimCode列を取得しつつ、nameが"Megumi"の行を条件指定
SELECT seraphimCode FROM member WHERE name = 'Megumi';
基本的にSQLでのデータの探し方としては、
1: 全体(テーブル)
2: 縦方向(列・カラム)
3: 横方向(行・レコード)
4: 縦横の交点(フィールド)
と、全体または縦横のxy軸で条件に応じて探します。
※多くの実処理としては、以下のように行われます。
1: FROM句でテーブル(全体)を指定する。
2: WHERE句で行(レコード)を条件でフィルタリングする。
3: SELECT句で必要な列(カラム)だけを選択する。

複数テーブル間の紐付け
また、RDBではその名の通り、各テーマごとにデータを管理するテーブルを作成し、外部キーを使用することで関連づけることができます。
例えば先ほどのmemberテーブルとは別に、部隊名のsquadテーブルを作成します。
| id | squadName |
|---|---|
| PK | string |
部隊テーブルはこのような感じです。
| id | squadName |
|---|---|
| 1 | 31A |
| 2 | 31B |
| 3 | 31C |
1つの部隊に複数のメンバーを紐づける場合
先ほどのmemberテーブルにsquadテーブルのidを外部キー(squadId)として追加します。
| id | name | height | instrument | seraphimCode | squadId |
|---|---|---|---|---|---|
| PK | string | int | string | string | FK |
※外部キー:FOREIGN KEY(FK)。あるテーブルが別のテーブルのデータを参照するために使用するもの
| id | name | height | instrument | seraphimCode | squadId |
|---|---|---|---|---|---|
| 1 | Ruka | 159 | Vocal | あたしの伝説はこれから始まる | 1 |
| 2 | Yuki | 160 | Drums | Hello World | 1 |
| 3 | Megumi | 159 | Guitar | 救世主様のお出ましや | 2 |
この例では外部キーのsquadIdとsquadテーブルから、RukaとYukiが31A、Megumiが31Bに所属していると分かります。1つの部隊に複数のメンバーが所属できます。
部隊とメンバーが「多対多」の関係の場合
1人のメンバーが複数の部隊に所属する、または1つの部隊が複数のメンバーを持つ場合、中間テーブルを作成します。
| id | squadId | memberId |
|---|---|---|
| PK | FK | FK |
中間テーブルに外部キーのmemberIdとsquadIdの値を入れてみます。
| id | squadId | memberId |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 1 |
| 4 | 2 | 3 |
この例では、31A部隊にRukaとYukiが、31B部隊にはRukaとMegumiが所属していることが分かります。
オブジェクト・JSONと、テーブルの比較
改めて、先ほどのオブジェクトの配列やJSONと、テーブルを比較して見ましょう。
const She_is_Legend = [
{
name: "Ruka",
height: 159,
instrument: "Vocal",
seraphimCode: "あたしの伝説はこれから始まる"
},
{
name: "Yuki",
height: 160,
instrument: "Drums",
seraphimCode: "Hello World"
},
{
name: "Megumi",
height: 159,
instrument: "Guitar",
seraphimCode: "救世主様のお出ましや"
}
];
[
{
"name": "Ruka",
"height": 159,
"instrument": "Vocal",
"seraphimCode": "あたしの伝説はこれから始まる"
},
{
"name": "Yuki",
"height": 160,
"instrument": "Drums",
"seraphimCode": "Hello World"
},
{
"name": "Megumi",
"height": 159,
"instrument": "Guitar",
"seraphimCode": "救世主様のお出ましや"
}
]
オブジェクト・JSONとテーブルで、以下のように対応していることがわかります。
- 配列の番号⇄id
- 各key⇄各列(カラム)
- 各オブジェクト⇄各行(レコード)
- 各value⇄各フィールド
つまり、認識する世界観・表現方法が「オブジェクト(と、それを模したJSON)」か「テーブル(行列)」かの違いなだけで、本質的な源流の"データ"という大元の単位から見て考えると互換可能だとわかります。
厳密には、「オブジェクトではメソッド(関数)を持てる」「DBでは一意の値を示すプライマリーキーの設定が一般的」などそれぞれ細かなルールの違いがあり、オブジェクト⇄テーブル間で完全な互換性とは言い切れません。ここでは "シンプルな値プロパティの集合としてのオブジェクトの場合" としてお考えください。
次元感覚
また、これは個人的、あるいはFEからキャリアを開始した方にとってのあるあるかもしれませんが、普段業務でコードを読む際は上から下への一次元の感覚に慣れています。

配列内の各オブジェクトを縦方向、各オブジェクト内の各プロパティの値も縦方向で読んでいきます。
一方、先ほどのDBでのテーブルでは行と列、x軸とy軸の二次元の感覚があると思います。

その次元感覚から改めて比較した際、次のように言えそうです。
- DBにおける行でのキャラクター追加(y軸方向で増えていく)は、オブジェクトでも行で追加される(y軸方向で増える。水色線。)
- DBにおける列での属性追加(x軸方向で増えていく)は、オブジェクトでは行で追加される(y軸方向で増える。橙色線。)
- 各値を、DBではx軸とy軸の交点で表現できる。オブジェクトはy軸のネストで表現できる
目的データまでの探索
※以下は自分の中でもまだ上手く咀嚼できておらず、感覚値としてです。
「DBではx軸とy軸の交点で表現できる。オブジェクトはy軸のネストで表現できる」について、データの探索や操作の観点で考えてみます。
- ネスト構造の場合:特定の値に辿り着くまで、for文やmap関数で同一階層内全体を1つずつ再帰的に調べながらネストというアビスを一層ずつ探窟しないといけない。(度し難い...!)
- テーブル形式の場合:データが同一階層の行列上で全て配置されている。列・行に対しての操作を簡単に行うことができる
※ただし、実際のRDBの内部処理も「全探索してフィルタリングやピックを行う」ため、ネスト構造や多次元配列での操作と原理的には似ています。
データの探索や分析などを行う上ではテーブル形式が適しているため使用され、データの関連性・まとまりを表現する上ではネスト構造が適しておりフロントエンド開発でオブジェクトやJSONが使用されているかと思います。
多次元配列(二次元配列)とテーブルの比較
以上はJSONとテーブルの比較でしたが、多次元配列と比較した場合はどうでしょうか。
const She_is_Legend = [
["Ruka", 159, "Vocal", "あたしの伝説はこれから始まる"],
["Yuki", 160, "Drums", "Hello World"],
["Megumi", 159, "Guitar", "救世主様のお出ましや"],
];
// 一つ目の[1]で縦軸から"Yuki"配列を選択、2つ目の[3]で横軸の配列内の値を取得
console.log(She_is_Legend[1][3]); // "Hello World"
こちらはオブジェクトにおけるkey-valueの関係がなくなり、値のみを格納する配列が複数存在し、その複数配列を1つの配列が格納するイメージです。
また探し方も、1つ目の指定で縦軸、2つ目の指定で横軸とxy軸での探索がDBと近しく、 多次元配列(二次元配列)はテーブルを文字記号で擬似再現したもの と言えるかと思います。

追記:
上記は「表」として視覚的に比較しましたが、RDBではカラムに名前がついているので、むしろ「オブジェクトの配列」のほうが近い存在です。
更に付け加えると、オブジェクトの配列も「多次元配列をわかりやすくしたもの」といえます。
オチ
......という、もしかすると人によっては「当たり前やん!」な内容だったかもしれません。
しかし自分の場合、
- フロントエンドからキャリアを始め、普段働く上ではデータを"オブジェクト"という単位・世界観で捉える先入観があったこと
- DB学習でテーブル形式を、案件でExcelの行列(テーブル)からツールでのJSON変換を知ったこと
- 「FE領域の学習としてFEの知識」「DB領域の学習としてDBの知識」と、学習時も先入観で視点が狭まり、そもそもの「データ」全体や形式について今まで疑問にも思わず考えてこなかったこと
という状態から始まり、衝動と勢いから調べつつ今回のアドカレを走り続けました笑
次はもう少し、DBの領域を詳しくなりたいですね...あと機械学習分野も。
ここまでお読み頂いた皆様、誠にありがとうございました。
つっこみどころは多々あるかと思います。ぜひコメントいただければ幸いです!
最後に謎かけで締めさせて頂きたいと思います。
それでは、
「人間が理解しやすいデータ表現」とかけまして、「エンタメコンテンツ」とときます。
そのこころは...
どちらも 「2次元」 が良いでしょう!
。゚(゚ノ∀`゚)゚。アヒャヒャヒャヒャ!!
おしまい。
以降はちょっとしたおまけです。
小噺
インピーダンスミスマッチ
こちらは社内勉強会にてリクルートの方に教わった概念・言葉です。
つまり、インピーダンスがミスマッチします(?)
インピーダンス:電流の流れを妨げる「抵抗」のようなもの
e.g. スピーカーとアンプのインピーダンスが合わず、「音質が悪い/出ない」など
→スピーカーとアンプの間にインピーダンスミスマッチ
Wikipediaの文章を引用します。
オブジェクト指向プログラミングとリレーショナルデータベースは異なるデータモデルを持つ。リレーショナルデータベースの関係モデルは整合性を重視した2次元表の構造を持っており、データ同士は関係(リレーション)によって表現される。一方オブジェクト指向プログラミングのデータはひとまとまりのオブジェクトとして扱われ、関係モデルにおける関係と同じような構造を持つとすれば、オブジェクト指向としての恩恵が得られるモデル設計ができない。逆も然り、オブジェクトモデルをリレーショナルデータベースで実現しようとすると、整合性が損なわれたり、関係が表現できなくなる。このデータ構造や概念の隔たりがインピーダンスミスマッチと呼ばれる。
今回の記事では "シンプルな値プロパティの集合としてのオブジェクトの場合" だとRDBのテーブルと互換性ありそう!と展開しましたが、引用内の指摘の通り、オブジェクト指向・RDBというデータ表現の構造上の差異から同一な表現を自体ができないことを指す話だと思います。以下はその例です。
- オブジェクトではメソッドを持つが、RDBでは持たない
- 「オブジェクトのプロパティがオブジェクト」という形式をRDBでは表現できない
...こちら、まだ自分の中でも咀嚼中の概念ですmm
もし興味ある方がおられれば下記記事などで掘り下げて頂くと、世界が広がって面白いかと思います!
ORMとPrisma
ORM:オブジェクト関係マッピング(Object-Relational Mapping)。
オブジェクトと関係(RDB:関係データベース)のマッピング(項目Aに項目Bを割り当てるルール、規則のこと)
オブジェクト指向プログラミングと関係データベースの互換性を向上させるために設計されたプログラミング技術です。ORMの基本的な構造は、プログラミング言語のクラスとデータベースのテーブルをマッピングすることから始めます。これにより、エンジニアは直接SQLクエリの作成することなく、ORMを通じてデータベースと相互作用できます。
多くのプログラミング言語はオブジェクトを扱うので、そのオブジェクトをRDBに保存できるように、対応付けを簡単にするためORMを使います。
もっと簡単にいうと、SQLを直接書くことなく、オブジェクトのメソッドでDB操作ができる、ということです。
簡潔に言うと、「SQLを直接書かず、オブジェクトでDBを操作することができる」技術です。
直近で少し学んだPythonのDjangoではORMを使ってClassでDBのテーブル定義や操作を書くことができました。
最近ではNode.jsによるORM、「Prisma」もあり、SQLではなく、JSでのDB操作が可能になるそうです。
次元(ベクトル、行列、テンソル)
以下もまた、自分の中で咀嚼できておらず、これから学習していきたい内容です...!ご興味湧かれた方がおられれば、ぜひdigってみてください!
"ベクトル"という言葉はとある学園都市第一位の一方通行さんの印象からご存知の方は多いかと思いますが、テンソルについては初耳の方も多いのではないでしょうか??(自分も今回調べた際、初耳でした。)
きっかけ
上記で、「テーブルはx軸y軸の表現でうんぬん」みたいな話を行いました。
そこで、こうも思った方はおられませんでしょうか?
「......DBにおけるテーブル(行列)がxy軸なら、z軸も加わると更に便利では...?」と。
↓こんなイメージです。
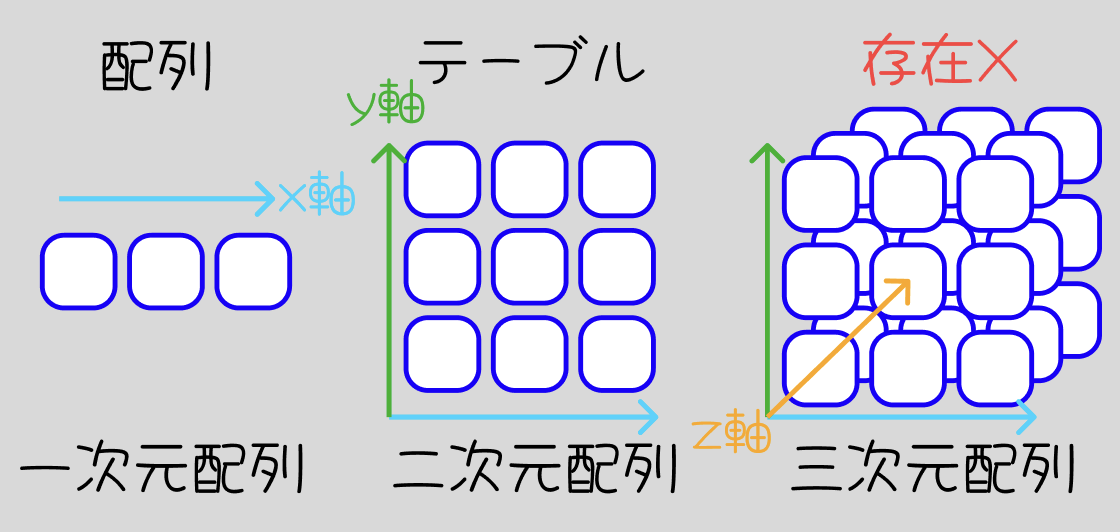
その話をChatGPTと壁打ちすると、上記のベクトルやテンソルって言葉があるらしい...と知った経緯です。どうやら機械学習やデータサイエンス、数学やディープラーニング関連で出てくる言葉のようです。
用語集
こちらを参照しました。
- スカラー:0次元。単一の数値を表すもの。大きさや値だけをもつ
e.g. 「気温」「身長」「重さ」 - テンソル:沢山の数値の集まりで、数値の種類(次元/軸の数)がいくつあるかを表す
- ベクトル:1列(または1行)のみで表現する1種類(1次元)のテンソル
- 行列:行と列の2種類で表現する2種類(2次元)のテンソル
「1種類で4項目のテンソル」なら「4次元のベクトル」ということになりますし、「2種類で3項目と4項目のテンソル」なら「3行4列の行列」ということになります。
ここでのベクトルは、フロントエンド開発における配列とも言えるかと思います。
より高次元へ
2次元の行列まではつきやすいですが、3次元以上のイメージがつきにくく、以下はChatGPTと壁打ちした内容の整理です。
3次元テンソル
- 3次元テンソルは「複数の2次元テーブルを積み重ねたもの」のイメージ
e.g. 「縦×横×高さ」という形でキューブ状にデータを格納など - カラー画像:「高さ × 幅 × カラーチャネル(RGB)」の3次元テンソルで表現
e.g. 256×256×3(高さ256ピクセル、幅256ピクセル、RGBの3チャンネル) - 動画:「フレーム数 × 高さ × 幅」の3次元テンソルで表現
4次元テンソル
- 4次元テンソルは「3次元テンソルの集合」のイメージ
e.g. 「3次元キューブ」を複数並べる。 - バッチ処理された画像データ:ディープラーニングで複数の画像を一括処理する際、画像データは「バッチサイズ × 高さ × 幅 × チャネル」という形で扱う
e.g. 32×256×256×3(32枚の256×256サイズカラー画像)
5次元以上のテンソル
- より高次元のテンソルは「さらなる次元のデータ構造」だが、人間には直感的に理解しづらく、数学や物理学では多次元データを扱うときに使用する
- 物理学のシミュレーション:時空間(時間+空間)を扱うシミュレーションデータ
統計モデル:高次元の特徴量を持つデータ(例えば、各ユーザーの複数条件に基づく行動データ)。
| 次元数 | 名称 | 例 |
|---|---|---|
| 0次元 | スカラー(Scalar) | 単一の数値(例: 5, 3.14) |
| 1次元 | ベクトル(Vector) | 数値の並び(例: [1, 2, 3]) |
| 2次元 | 行列(Matrix) | テーブル(例: [[1, 2], [3, 4]]) |
| 3次元 | テンソル(Tensor) | キューブ(例: 画像のデータ) |
| 4次元以上 | 高次元テンソル(High-dimensional Tensor) | バッチデータや物理シミュレーション |
図にするとこのような感じになるかと思います。

個人的見解・仮説
- 人類は縦 × 横 × 奥行きの三次元空間に生きている。なので、同次元より下の次元の方が理解・操作しやすいのではないか。(なので、"時間"の概念も踏まえた四次元の感覚に慣れると、三次元でのデータ表現も容易になるのではないか。)
- 人類がデータ・情報を操作する上で、紙やパソコン(モニター)など「平面」の媒体に慣れてきた(技術コストや資本コスト観点で、3次元空間でのデータ表現はハードルが高かった)。近年のApple Vision Proのように、XR領域の技術が発展し「空間」でのデータ表現・編集のコストが下がっていけば、テーブルに変わる三次元の表現手法が生まれ、また慣れによって三次元の次元感覚も身につくのではないか
その他ワード
他にも、機械学習の領域においては「次元の呪い」や「次元削減」という厨二病っぽくてワクワクする言葉・概念もあります。(言葉として認知した段階で、これから理解に至るまで咀嚼していきます...!)
(次元の呪いとは)データの次元数が高次元になると、データが空間の外側に集中して分布する現象です。
次元削減とは、多次元からなる情報を、その意味を保ったまま、それより少ない次元の情報に落とし込むことです。
次元の呪いや次元削減の話を知ると、高次元データは人間にとって直感的な理解が難しく、2次元に削減することで視覚的にデータのパターンや関係を把握しやすくする意図がありそうです。
またテーブルが活用されている理由も、人間にとってデータの理解・認識・可視化がしやすい最適な二次元のツール/フレームワークだからかもしれません。
あと、最近見たこちらの動画も面白かったです。
「位相的データ解析」という分野を研究されている方で、特許に関する430次元のデータを二次元で表現される、という内容です。
もし他に「データ関連で、こんな面白い言葉や概念があるよ!」というのがございましたら、ぜひコメント頂けると幸いです!!
今度こそ、おしまい。
参考資料サイト一覧