はじめに
Webメディアの執筆作業に継続的インテグレーション(Continuous Integration)、継続的デリバリー(Continuous Delivery)の考えを取り入れ、GitHub/CircleCIを使って効率化をした話です。最初の環境構築さえしてしまえば、非エンジニアでも問題なくこの仕組みに乗ることが出来ています。これらのツールは発想次第でいろいろな使い方ができるということを、メディアの運営者やエンジニアに限らずいろいろな人に知って頂ければ良いのかなと。
背景
この仕組みは私がWebメディアを運営する会社にて、開発と記事のライティングや編集を同時に経験したことをベースに作り上げました。記事執筆をしていると、書いた記事をどう保管するのか・編集者の修正を執筆者にフィードバックするにはどうするのか・といった課題が出てきます。その問題を解決するため、Github/CircleCIを活用した記事運用フローを考案し、試してみました。
やったこと
運用その(1) GitHubで記事を管理する
手始めに、記事をGitHubで管理することにしました。以前はGoogle Documentで共有して執筆・編集をしていましたが、それでは編集前後の差分が分かり辛く、執筆者へのフィードバックが困難でした。そこで差分管理+共有がしたい、それならGitHubだよね、ということで記事専用レポジトリを作成して使い始めました。
もちろん運用するにあたりブランチの運用フローを決めるわけですが、ここで特徴的なのはGit FlowおよびGitHub Flowには全く従っていないということです。執筆者はガンガンmasterにコミットします。
もちろん理由があり、先ほど述べたとおりGitHub活用の主目的を「編集前・後の差分を分かりやすく残していくこと」としています。そのため執筆時点での差分はさほど重要ではなく、masterがクリーンである必要性もありません。1記事を複数人で書くことも無いので、基本的にコンフリクトも起きません。そういう訳で、「執筆完了した時点でGitHubに記事が登録されている」という点だけ守れば、いつ記事を作成してもいいし、何度masterにコミットしてもOKというフローにしています。
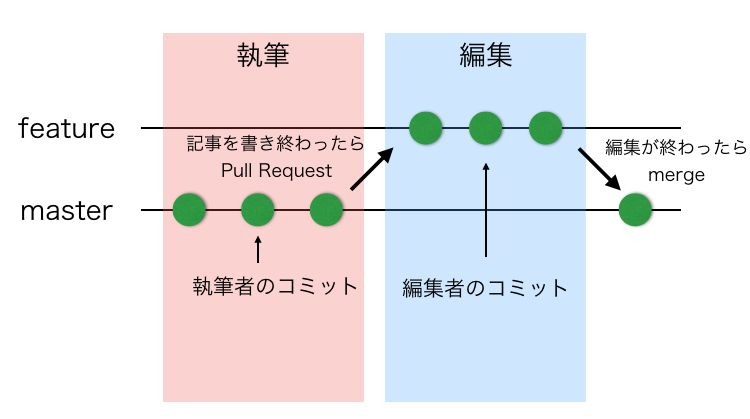
編集のフローに入るため、執筆者が書き終えた段階でPull Requestを作成します。編集者はそのプルリク上で記事を編集し、記事が完成したらプルリクをマージします。このフローにすることで、編集前・後の差分をプルリクエスト単位でキレイに残すことが出来るのです。
ちなみに現時点では、執筆した記事の登録や編集作業はすべてGitHubのサイト上で行っているため、作業者はgitのコマンドを叩いたりする必要はありません。1ファイル単位での変更ならweb上でも意外と問題なく出来てしまうものです。このフローがいい感じに回り始めたらElectronで専用クライアント作ってみたいですね。
運用その(2) CircleCIで記事の品質を評価する
取材をしていると、昨今のモダンな開発組織では当たり前のようにCircleCIを活用し、自動でテストやLint、CodeClimateを使った品質の確保などを行っています。そんな話を聞いていて、ふと「これって記事にも使えるんじゃないの?」という声が降ってきました。記事もコードも同じテキストファイル。静的解析が出来ないわけないじゃないかと。
というわけで、CircleCIを使ってPull Requestが作られた記事に対して以下のチェックを行っています。ちなみにここではCIでテストをFailedにするのではなく、チェック内容をAPI経由でIssueにコメントするだけとしています。メディアの特性にもよりますが、インタビュー記事だと特に「文章が崩れているのも正解」というケースがあり、表現の自由度を担保するためにそうしています。
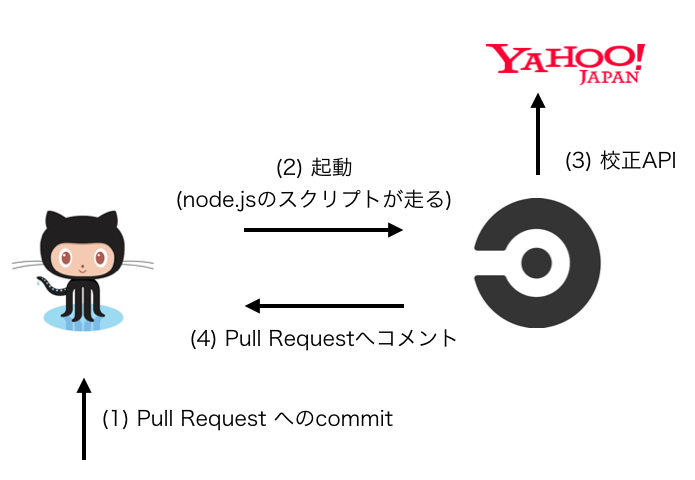
CircleCIでは以下のようなメトリクスをチェックしています。どのようにチェックをしているのかは、本記事の最後に載せているレポジトリを参照してください(リファクタリングしてないのでコードの品質については。。)。
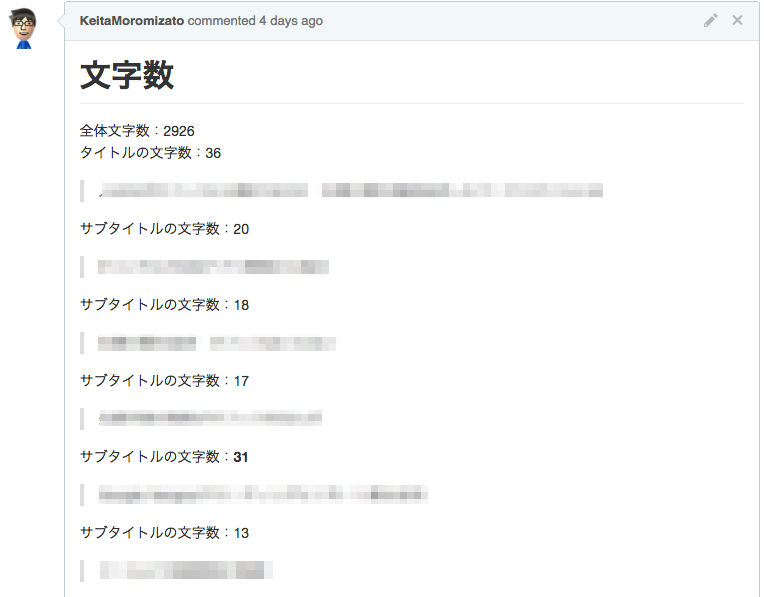
全体の文字数、タイトル・見出しの文字数
記事本文の文字数は目安として〇〇文字くらいというものが決まっているので、書いた記事が長いのか短いのかを自覚してもらう目的です。とは言え雰囲気で分かる部分でもあるので、それほど重要視はしていないです。重要なのはタイトル・見出しの文字数。特にタイトルはSNS/ポータル上でのアイキャッチとなるため、文字数に強い縛りを設けています。文字数に気をつけていても、執筆中や編集中についうっかりオーバーしてしまうため、CIで自動的に警告を出すようにしています。
CIのチェックが完了すると、以下の画像のようにPull Request上にコメントが流れます。自分のtokenでAPIを叩いているので自作自演っぽいですがbotですw
Yahoo! 校正支援APIを使った自動校正
機械で判定できるエラーは人間がチェックする必要がない、というコードレビューにも通じる話です。自動校正で指摘された箇所は最低限直してから編集に入ります。また、編集中に誤って誤字ってしまった事にも気付けます。メディア御用達である「共同通信社 記者ハンドブック」を元にしているらしく、体感としては結構役に立っています。
次のようにPull Requsetのコメントに表として出力しています。
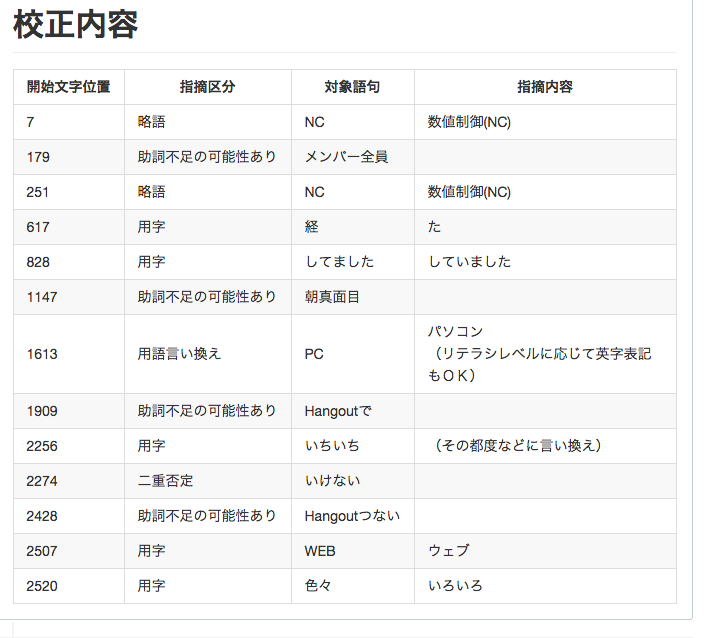
結構優秀な校正なのですが、メディアの性質によっては不要なワードもあります(WEB -> ウェブ など)。不要なものが毎度出てきても意味が無いので、フィルタリング機能を実装しました。簡単なJSON形式のファイルをレポジトリに含めており、エンジニア以外でも追加・変更ができる構成になっています。
Yahoo! キーフレーズ抽出APIを使ったキーワード抽出
キーワードを抽出すること自体には大した意味はありませんが、記事内での単語出現回数を可視化するために使用しています。弊社では「一つの章で、ある単語が3回以上出現している」場合に警告を出す仕組みにしています。同じ言葉が繰り返される記事は冗長に見えるため、3回以上出現している場合は別の表現に言い換えましょう、という目安として使用しています。
運用その(3) CircleCIでWord形式にエクスポートする
最後に、編集が終わるとMarkdown形式の記事をMicrosoft Word形式に変換し、指定した場所にエクスポートするようにしています。完成した記事をインタビュー先企業に送るためにはWord形式にする必要が有るためです。Markdownが世界標準になってくれれば良いんですけどね。この機能はPull Requestがmasterにマージされたことを契機として動きます。
実はシステム的にはここが一番面倒でした。実現したかったのは「Pull Requestがマージされたタイミングで、そのPRで編集した記事をWord形式でExportする」ということ。一般的な継続的デリバリーの文脈では、masterにコミットされた(= マージされた)ときにまるっとデプロイするというケースが多いです。ただし今回は「マージされた時の差分ファイルだけデプロイ(= export)したい」「前述のとおり、執筆中はPull Requestを通さずにmasterに直接コミットされる」という開発ではあまり見かけないレアケースです。幸い前者はCircleCIの環境変数でコミットハッシュが取れるので難しくなかったですが、後者がCircleCIだけでは判定が厳しい。エンジニアとしては残念な回答になりますが、最終的にはコミットコメントにMerge pull request #が含まれているかを見ることにしました...
const isPullRequestMerged = data.commit.message.indexOf('Merge pull request #') !== -1;
おまけ Chrome Extensionの活用
上記のフロートは関係は薄いですが、記事執筆に役立つChrome Extensionを書きました。chrome-text-counterというもので、Chrome上でテキストを選択したときに、右上にフワッと選択された文字数が出るものです。
これはGitHubで記事を執筆・編集する上で出た要望を元に作りました。CIでも文字数はカウントしていますが、編集を時にも文字数をカウントしたいという要望を受けたので作りました。Chrome Webストアにもすでに類似するExtensionはありましたが、そのどれもがテキストを選択した後にワンアクション(右クリックなど)が必要なもので、記事を書くスピード感には合わないものでした。
コード量的には10行程度の簡単なものですが、個人的には気に入っています。
https://github.com/KeitaMoromizato/chrome-text-counter
おわりに
大手メディアでは自動校正ツールを自作しているという話も聞きますが、この方法なら駆け出しのメディアでも工夫次第で記事のクオリティアップ、作業の効率化ができるのではないかと思います。Qiitaのような場に技術文章を書いている人も試してみると良いのではないでしょうか。
ここから追記
textlintの活用
上記の校正システムを自前で作ってたのですが、textlintのルールとして一般化しました。textlintはver5から非同期APIに対応したため、Yahoo校正APIもLintのルールとして使用することが出来ます。作成したRuleは以下の4つです。
textlint-rule-ja-yahoo-kousei
Yahooの校正APIを叩くtextlintのルールです
textlint-rule-max-appearence-count-of-words
段落内の単語の出現回数をチェックします。内部的にはkuromoji.jsを使用しています。
textlint-rule-max-length-of-title
タイトルの文字数をチェックします。たぶん、textlintの作者の意図としては本来textstatのルールにするべきだとは思いますが、多くのメディアやSEOを気にかけるライターにとってはタイトル文字数はLintでチェックすべき指標だと思います。
textlint-rule-ng-word
NGワードを登録しておくと、そのワードが出た時にエラーを出してくれます。ConfigでNGワードを登録しなければこのルールは何も動作しません。
サンプル
これらのルールを使用してCIに組み込んだサンプルレポジトリです。textlint、configの使用方法などの参考になればと思います。
https://github.com/KeitaMoromizato/continuous-writing-sample
実際にPullRequestを上げるとこんな感じになります。メッセージはもう少し改善したい。
https://github.com/KeitaMoromizato/continuous-writing-sample/pull/5
参考
上に挙げたtextlintを使用したレポジトリを参照下さい。
以下のレポジトリに今回のコードを置いています。実際に使っている環境から切り離しただけで、まだ汎用的に作れていないのですが参考までに。
https://github.com/KeitaMoromizato/continuous-writing