自然言語処理の画期的なモデル - BERT
BERT [Bidirectional Encoder Representations from Transformers] は、Googleのチームに2018年の秋に発表された。トランスフォーマーアーキテクチャを使って、大量のデータで非常に大きいネットワークを画期的な方法でモデルを学習した結果である。学習方法と精度についてこの記事をご参照ください。
オープンソース・情報を自由に交換することを大事にしている機械学習のフィールドでは、新しいアイデアを arxiv.org で論文として公開し、github でモデルを共有することが基本的なやり方である。新しいアイデアが公開されたとたんに、世界の機械学習の研究者や開発チームが参考したり、再利用したりできる。
オープンソースの文化の結果、BERTが公開されて数か月たったら、
Open AI、Facebook、NVidia、BaiduなどのすべてのIT大企業がこの新しいアーキテクチャに基づいてモデルを作った。
2017年からの進化、特にBERTからの画期的な影響については、このナイス図 をご参照ください。
BERTよりデカイモデルが最近流行
BERTの精度向上の原因は、アーキテクチャや学習データの量だけではなく、パラメータ数でもある。
BERTが大きいです。でかい。というより、デカイ。BERTの「小さい」版は、一番単純なバージョンのパラメータ数は1億である。また、BERTに基づいたほかのモデルはさらに大きくきている。
- Open AI のGPT-2:15 億
-
Nvidia の Megatron-ML:83 億
2020年に発表されたGoogleのチャットボット Meena :26 億 - Microsoft の T-NLG:170 億
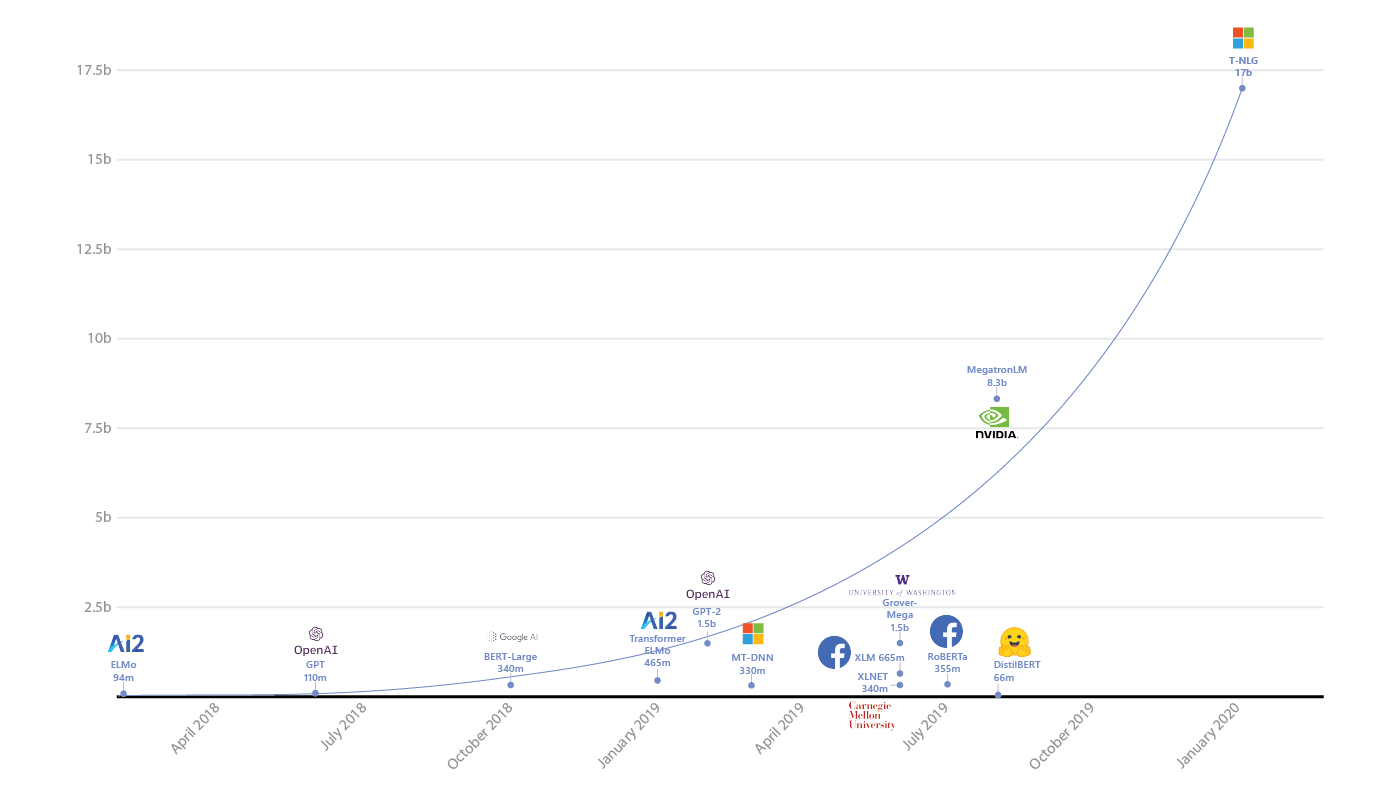
ディープラーニングでは、データ量とネットワークのサイズが上がることによって、精度もあがる。
ただし、このようのデカイネットワークには、いくつかの課題が発生する。
温暖化を防ぐには、転移学習の場合重みを固定したままにしよう
何億パラメータを大量のデータで学習するには、いくるかかったかは公開されていないが、電気代だでけでも何千万円かかったと考えられる。このようのモデルを自分の課題にカスタマイズするには、ゼロで学習させることは現実的ではない。グーグルやマイクロソフトじゃないと、転移学習でやるしかない。家のパソコンを使ってゼロから学習させたら、GPUが暖房の代わりになるでしょう。溶ける可能性もある。
学習はコストが当然かかるけど、Inference [モデルで特定なインプットに対してアウトプットを予測すること] もコストがかかる。最近話題になった AI Dungeon がこの課題を直接に感じて、記事も書いた。この規模のモデルのメモリ要件は数ギガバイト。また、処理にも時間がかかりますので、精度が高くても、スピードが大事な活用の場合では、適切なシステムではない。
まとめると、ITの大企業で最近開発された自然言語処理モデルの精度は確かに高いですが、学習・処理は大変である。クラウドで大変。エッジでさらに大変である。
さらに読む
改善方法・解決方法
ハードウェア購入・クラウド型の無限な予算 - 稟議無しで無限な予算を取れたら、お気軽に数万個のTPUでいけると考えらる。グーグルの予算なかったら、どうやってこのようの精度を出すモデルを使えるでしょうか?
一つの解決方法として、DistilBERTのような縮小版のモデル。元のモデルに「教育」される小さ目なモデルを学習させる。この学習方法の結果、精度は元のモデルほどよくはないですが、サイズを何十倍も縮小することができる。「Knowledge Distillation」について、この記事をご参照ください。。
2020年2月の論文でもアマゾンから発表された論文でトランスフォーマーアーキテクチャを縮小する方法が紹介された。
精度のニーズが常に上がることによって、このようの課題はなくならない。一般の会社でもこのようなモデルを利用できるように、ハードウェア進化、クラウド費やコスパがいいトランスフォーマーアーキテクチャが必要になる。