前置き
DNS水責め攻撃の概要については、JPRS Orange森下さんのPDFがわかりやすいと思いますのでリンクさせてもらいます。
ISPなんかのキャッシュサーバだと、オープンリゾルバではなく、イングレスフィルタリング(BCP38)を実装してスプーフィング対策も万全にした上で水責めに加担してしまったりします。
そもそも水責めは権威に対するアタックという事になっていますが、捌くクエリの多いキャッシュサーバだとファイルディスクリプタ等の問題で障害に繋がったりもするのです。
Q:何故対策しているのに防げないのか。
A: 問い合わせ元、allow-recursionである利用者=エンドユーザの対策がガバガバだから。
です![]()
エンドユーザに例えばPPPoEでDNS配ったりすると、10数年前の性善説に基づいたルータなんかで大解放されたりしてしまうんですね。
つまりパケットの着信は防ぎようがありません。
Q:どう対策するか
A: これはDNS+運用のレイヤでがんばりましょう
* セルフポイズニングだったり....
* 地道に送信元(エンドユーザ)に対策をお願いしてみたり....
もう少し検出の精度を上げられれば、セルフポイズニングの自動化あたりは出来るかもしれませんね。
Q:どう気付くか
A: ここを Norikra (Fluentd + Elasticsearch + Kibanaも含む) で頑張りましょう
というお話です ![]()
一度にずらっと書くと長くなりそうなので、今回はNorikraだけにフォーカスして書きます。
ゴール
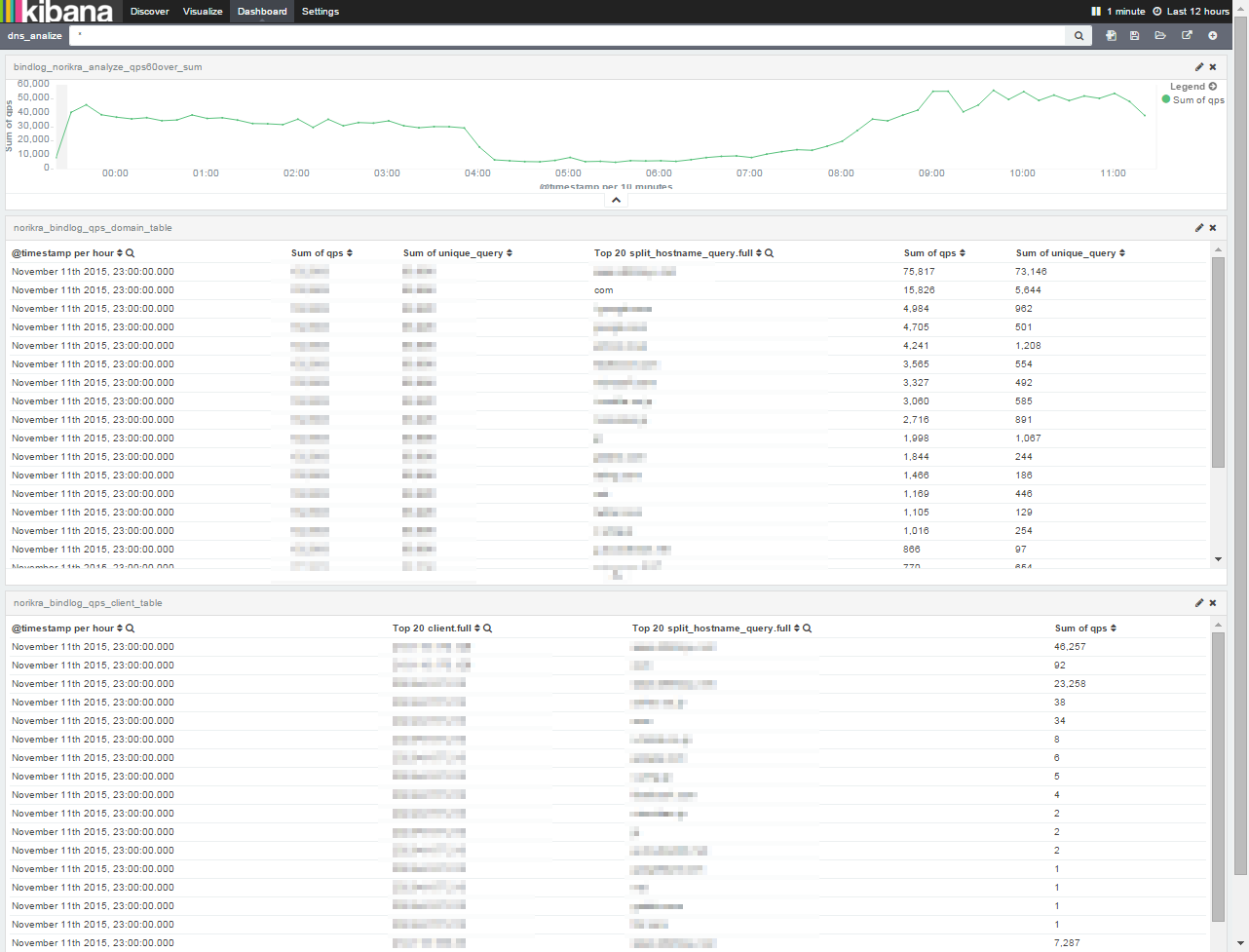
なんとなく検出と切り分けに使えそうなイメージを持ってもらえたでしょうか。
見せられない個所が多くて申し訳ないのですが、上から順に以下の通りに並んでいます。
- [抽出条件]※後述の[intermediate_queue_01] に基づいたqpsのサマリを折れ線グラフにしたもの
- 合致した単位時間あたりのドメインTOP20
- 2に合致するドメインを検索したクライアントの単位時間qps TOP20(ドメイン毎)
言葉にするとそもそも分かりづらい内容なのか、伝え方が下手なのか、両方なのか。
何をしているのか伝わりづらかったら申し訳ありません。
計算条件が多段になるので、生データからリアルタイム集計しようとするとElasticsearchの負荷が高くなりすぎるという問題からNorikraの登場と相成りました、という事が伝われば何よりです。
製作者であるtagomoris氏に感謝です。
Norikraの動作環境
| HW | SPEC |
|---|---|
| CPU | Xeon E5540@2.53GHz 中の8core |
| memory | 12GB |
| name | version |
|---|---|
| jruby | 1.7.20.1 |
| norikra | 1.3.1 |
HWについては、ブレードサーバ上のESXiでリソース占有型での構築です。
ストレージについては触れていませんが、エンタープライズ用途のSSD共有ストレージなので早いものを使っていますが、それほど重要なファクターではないので7200rpmのSATA HDDでも用は足りると思います。
3000万/day程度の処理をさせていて、今後クラスタ全体で1億クエリ程度を見込んでいます。
AWSインスタンスなら m4.xlarge あたりで十分ではないでしょうか。
Norikraの設定内容
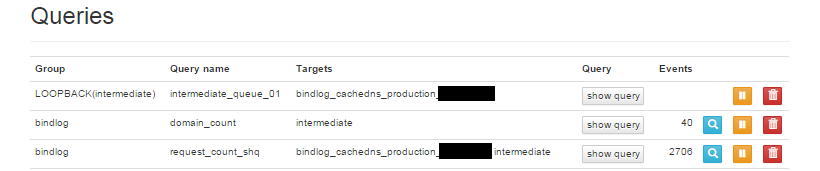

塗りつぶしている個所は、Fluentdのtagにホスト名が埋め込まれていたので一応伏せさせてもらいましたというだけです。
本当は検証用データが用意出来ればそれが良かったのですが、良いダミーデータを作ったところで骨折り損ですし、画像が見苦しい点はご勘弁ください。
設定自体は結構シンプルにまとまったなと思っています。
中間ファイル
Norikraって実は中間ファイルを作って、ループバックさせて多段で処理する事が出来ます。(v1.0.0以降)
やり方は簡単で、groupを以下のように指定するだけです。
LOOPBACK(<Target名>)
ただ、これをやるとどんどんリアルタイム性が失われていくと思うので、明確な理由が無い限りは1発の処理で終わらせたほうがよいだろうなと思います。
設定ファイル@json
"queries": [
{
"name": "intermediate_queue_01",
"group": "LOOPBACK(intermediate)",
"expression": "
SELECT
COUNT(split_hostname_query) AS qps,
split_hostname_query,
COUNT(DISTINCT query) as unique_query\r
FROM
bindlog_cachedns_production.win:time_batch(60 sec)\r
GROUP BY
split_hostname_query\r
HAVING
COUNT(split_hostname_query) > 60 AND
split_hostname_query is not NULL AND
COUNT(DISTINCT query) > COUNT(split_hostname_query) / 10\r
ORDER BY
COUNT(split_hostname_query) DESC\r
"
},
{
"name": "domain_count",
"group": "bindlog",
"expression": "
SELECT
qps,
split_hostname_query,
unique_query\r
FROM
intermediate.win:time_batch(60 sec)"
},
{
"name": "request_count_shq",
"group": "bindlog",
"expression": "
SELECT
P2.split_hostname_query as query,
P1.client as client,
COUNT(*) as qps\r
FROM
bindlog_cachedns_production.win:time_batch(60 sec) as P1,
intermediate.win:time_batch(60 sec) as P2\r
WHERE
P1.split_hostname_query LIKE P2.split_hostname_query\r
GROUP BY
P2.split_hostname_query,
P1.client\r
HAVING
COUNT(P1.query) >= 1"
}
設定ファイル(Norikra query)の解説
intermediate_queue_01
qps,split_hostname_query,unique_query の3カラムを持つ中間ファイルをgroupにLOOPBACK(intermediate)指定して作っています。
やっている事は単純で、以下の条件をANDでフィルタしています。
- 1分間あたりの流量が60以上(COUNT(split_hostname_query) > 60 )
- FQDNのPrefix(host名部分)を取り除いたドメイン名がNULLでない( split_hostname_query is not NULL)
- FQDNのPrefix(host名部分)のパターンが当該FQDNのクエリ数の10%を超えている事(COUNT(DISTINCT query) > COUNT(split_hostname_query) / 10)
特に最後のルールがキモなんですが、DNS水責めではhost名部分をランダムにした所謂カミンスキー型の手法がとられます。
同一ドメイン宛クエリ中のユニークなホスト名が10%を超えるという結果は正常なクエリ中にはほとんど出現しませんので、単に数量が多い google 等のメジャードメイン宛の正常クエリをdropさせる事が出来ています。
ちなみに FQDNのPrefix(host名部分)を取り除いた split_hostname_query という要素は、Fluentd側でパースしています。
Fluentd側の詳しい実装等については別記事でご紹介する予定です。
domain_count
これは intermediate の内容をそのままFluentdへsourceとして送らせています。
request_count_shq
FROM句の通りP1がbind生ログ、P2が中間ファイルを指しています。
中間ファイルにあがってきたドメインをbind生ログ上で何回クエリしていたかという情報を、sourceアドレス毎にカウントしています。
問題点
- あまりエレガントではない事。
- request_count_shq の処理でJOINした中間ファイルとbind生ログは、厳密には同じ時間軸を参照しておらず、スライディングウィンドウの位置が1回分、60secずれてしまいます。
なので、発生タイミングと終息タイミングは+-60sec程度の誤差がある状態な事。
EPL難しいです。奥が深い。
この記事がEPLマスターな方の目に留まって、さらっとアドバイスいただける事を期待しています。
Fluentd設定
# Norikra client fetch
<source>
type norikra
norikra localhost:26571
<fetch>
method sweep
target bindlog
tag query_name
tag_prefix norikra
interval 10s
</fetch>
</source>
最後に、Norikra上のFluentdでこのようにtargetとして出力group名である「bindlog」を指定すればOKです。