はじめに
2019/04/18、Cognitive Servicesに新しくAnomaly Detector APIが追加されました。
Anomaly Detector APIは、読んで字のごとく「異常検知」に特化したAPIで、時系列数値データに含まれる異常な挙動の検出を簡単なREST APIで利用できるようです。
せっかくなので、適当なサンプルデータを使ってAnomaly Detector APIの異常検知を試してみます。
Anomaly Detector APIの仕様等々
※以下、執筆時点(2019/04/25)での情報となります。
APIメソッド
Anomaly Detector APIでは
- Detect anomaly status of the latest point in time series.
- Find anomalies for the entire series in batch.
の2つのメソッドが使用できます。
これらの違いは、最終データポイントの判定結果を返すか、すべてのデータポイントの判定結果を返すか、というものでリクエスト形式はともに同じものとなっています。
実利用においては、「Find anomalies for the entire series in batch.」でパラメータ調整を行い、リアルタイムでの異常検知に「Detect anomaly status of the latest point in time series.」を使用するという形になると思われます。
リクエスト形式
APIのリクエスト本文は、JSON形式でデータの粒度を示す「granularity」と時系列データ「series」が含まれる必要があります。
「granularity」は時系列の間隔を指定するパラメータで「daily」、「minutely」、「hourly」、「weekly」、「monthly」、「yearly」の6パターンが指定できます。
「series」は「timestamp」と「value」をペアにしたオブジェクトの配列を指定し、データ数は最小で12、最大で8640とし、時系列でソートされている必要があります。また、「timestamp」はISO 8601のUTCタイムスタンプ、「value」は数値型とし、1つでも型の異なる値が入るとリクエストエラーとなります。
そのほか、パラメータとして「sensitivity」、「period」、「maxAnomalyRatio」、「customInterval」が使用できるようです。
四半期ごとの時系列データを使用する場合は、以下のようなリクエスト本文とすればよさそうです。
{
"series": [
{
"timestamp": "1972-01-01T00:00:00Z",
"value": 826
},
{
"timestamp": "1972-04-01T00:00:00Z",
"value": 902
},
...
],
"granularity": "monthly",
"customInterval": 3,
"maxAnomalyRatio": 0.25,
"sensitivity": 95,
"period": 4
}
データ欠損
データ欠損は期間全体の10%まで許容されるようです。10%を超える欠損が含まれる場合はリクエストエラーが発生します。
レスポンス
Anomaly Detector APIの成功時のレスポンスは、以下のようなJSON形式となります。
「expectedValues」は学習モデルから得られる予測値で、異常判定のマージン「upperMargins」、「lowerMargins」と組み合わせて閾値を求めることができます。
「isAnomaly」、「isNegativeAnomaly」、「isPositiveAnomaly」はそれぞれ異常判定の真偽値で、異常判定閾値から外れた場合は「true」となりますが、「isNegativeAnomaly」は下限閾値、「isPositiveAnomaly」は上限閾値から外れた場合のみの判定となっています。
「period」はデータの周期性を示す値で、特定のパターンが何データポイントごとに現れるかの判定結果となります。
リージョン
「西ヨーロッパ」、「米国西部2」の2リージョンで利用可能です
利用料金
利用料金は以下の通りです。パブリックプレビューのため、Standardは一般公開時の価格の50%となっています。
| インスタンス | 料金 (プレビュー) |
|---|---|
| Free (F0) | 20000 無料トランザクション/月 |
| Standard (S0) | ¥17.584 / 1,000トランザクション |
検証データ
適当なサンプルデータといっても都合のいいセンサーデータを持っているわけではないので、検証データには、中部電力ホームページの「電力需給状況のお知らせ」にある「過去実績データ」を使ってみます。
試しに2018年データを可視化すると、電力データは気象条件に大きく影響を受け、夏季、冬季は特に冷暖房の使用等に伴って電力需要が増大することがわかります。
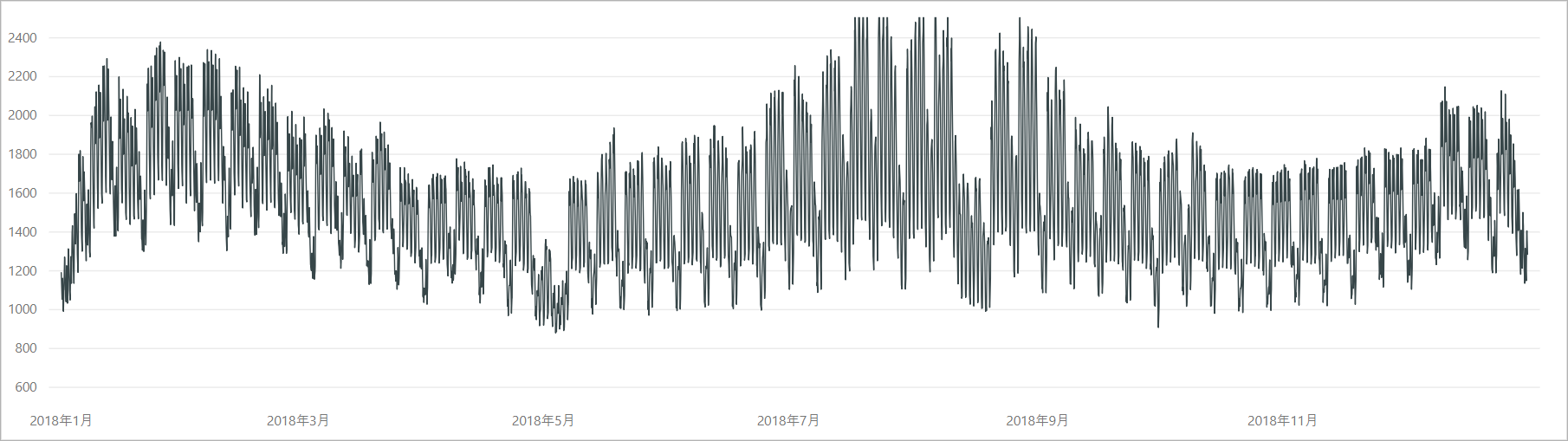
また、電力需要は1日、1週間単位で周期的なパターンを示すことがわかります。人や業務機器が稼働する平日日中帯は電力需要が大きく、土日等の休日は相対的に電力需要が小さくなります。
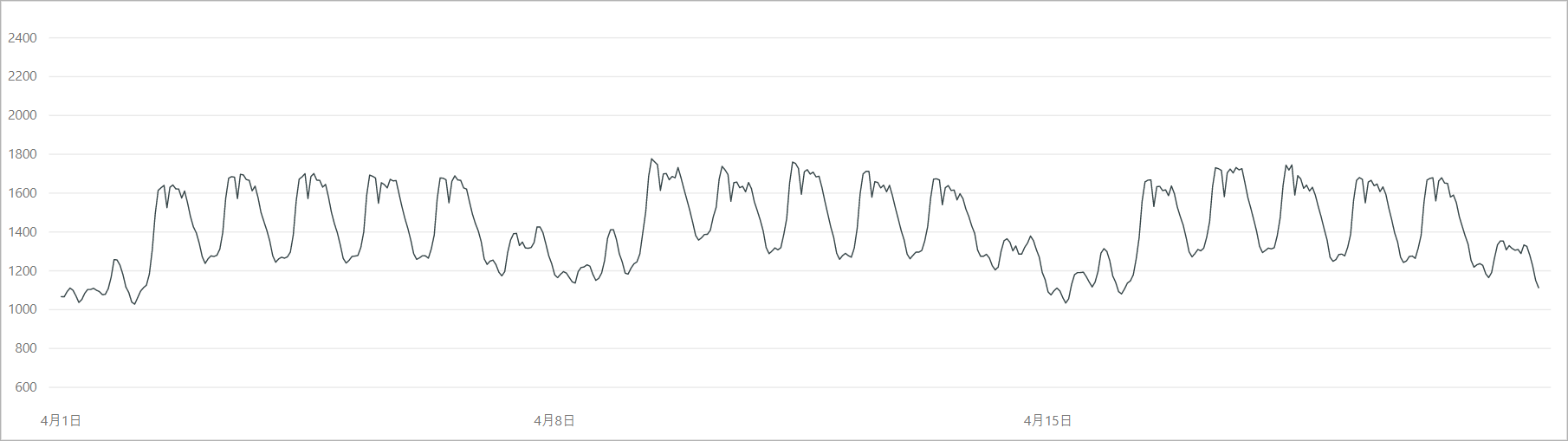
今回の検証には、電力需要データのうちの2018年4月~5月を使用します。
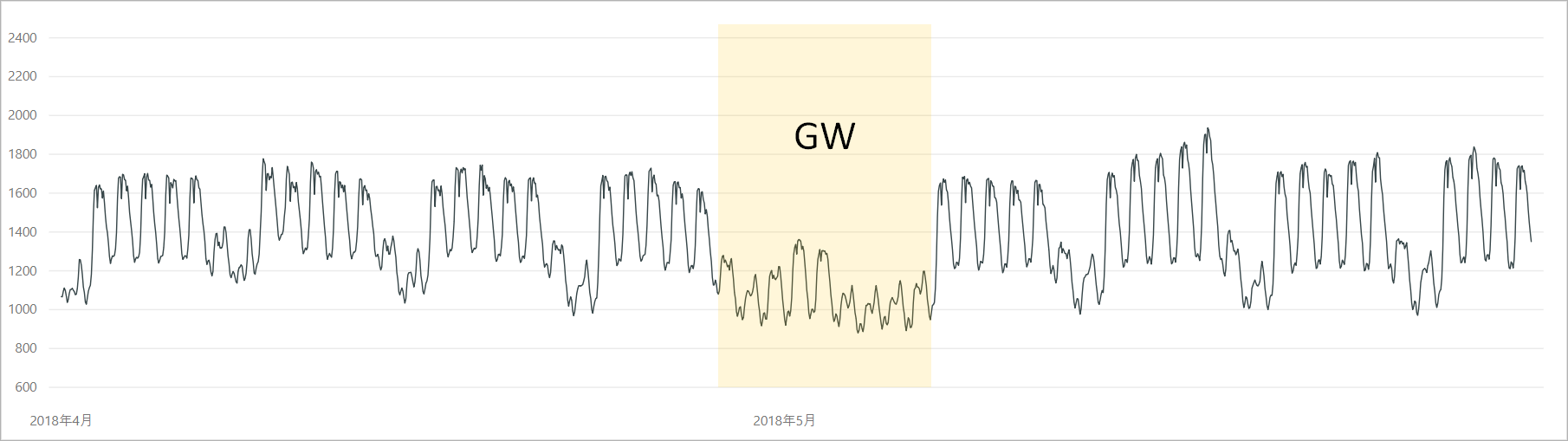
この時期は冷暖房の使用が少なく電力需要は比較的安定しますが、期間にゴールデンウィークがあり、前後の週と比較して電力需要の落ち込みが発生します。
もちろんこれを「異常」とは言えませんが、「通常とは異なる」という点から異常検知のサンプルとして使ってみます。
Anomaly Detectorの作成
Azureポータルの「リソースの作成」から「Anomaly Detector」を選択して作成を開始します。
必要な内容を入力して、作成を行います。
作成が完了したらAPIキーを取得します。リソースに移動し、メニューの「キー」からAPIキーをコピーして控えておきます。
スクリプト
今回は、PythonでAnomaly Detector APIにリクエストしています。
Anomaly Detector APIは、Face APIといったCognitive ServicesのAPIとリクエスト方法が変わらないため、簡単に利用できます。
# coding: utf-8
import pandas as pd
import json
import requests
def main():
# 対象期間
begin = '2018-04-01 00:00:00'
end = '2018-06-01 00:00:00'
# 電力需要データの読み込み
df = pd.read_csv("./areajuyo_current.csv", encoding="shift-jis")
# データ加工
df["timestamp"] = df["DATE"] + " " + df["TIME"]
df.loc[:, ["timestamp"]] = pd.to_datetime(df["timestamp"], format="%Y/%m/%d %H:%M")
df = df[["timestamp", "実績(万kW)"]]
df = df.rename(columns={"実績(万kW)": "value"})
# 検出対象データの抽出
df_req = df[(df.timestamp >= begin) & (df.timestamp < end)].reset_index()
df_req
# リクエスト用時系列データに変換
df_req.loc[:, ["timestamp"]] = df_req["timestamp"].dt.strftime("%Y-%m-%dT%H:%M:%SZ")
series = json.loads(df_req.to_json(orient="records"))
# リクエスト設定
api_key = "{APIキー}" # 取得したAPIキー
endpoint = "https://westus2.api.cognitive.microsoft.com/anomalydetector/v1.0/timeseries/entire/detect"
headers = {
"Ocp-Apim-Subscription-Key": api_key,
"Content-Type": "application/json"
}
body = {
"series": series[:8640],
"granularity": "hourly"
}
# Anomaly Detector APIにリクエスト
res = requests.post(endpoint, headers=headers, json=body)
results = res.json()
# レスポンスの保存
json.dump(results, open("./response.json", "w"), indent=4)
# 判定結果の統合、保存
del results["period"]
df_res = pd.concat([df_req, pd.DataFrame(results)], axis=1)
df_res.loc[:, ["timestamp"]] = pd.to_datetime(df_res["timestamp"], format="%Y-%m-%dT%H:%M:%SZ")
df_res.to_csv("./detect_results.csv")
if __name__ == "__main__":
main()
実行結果
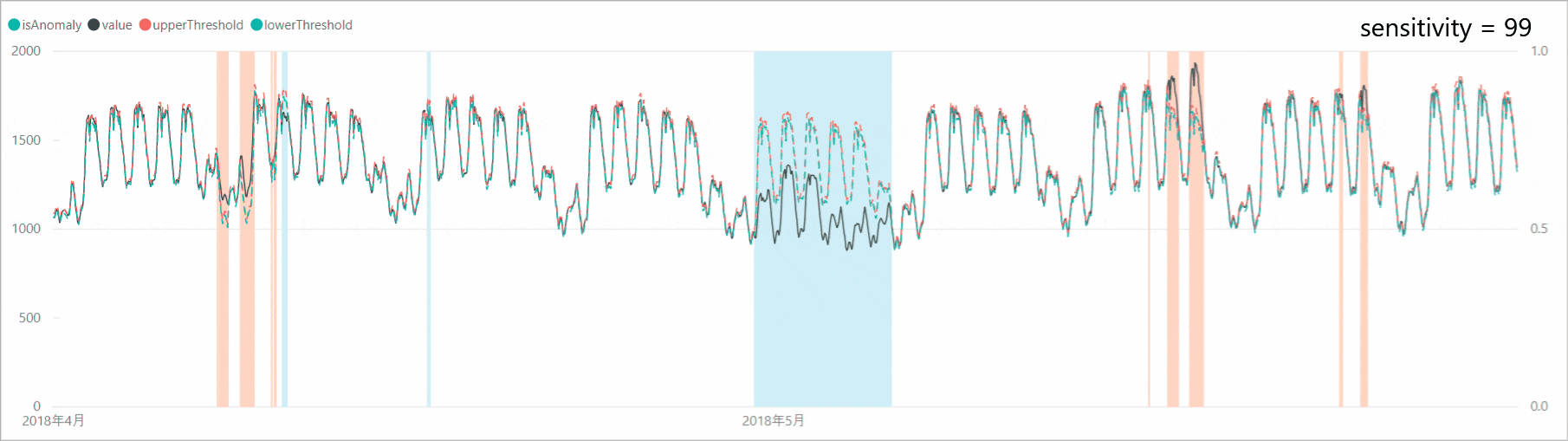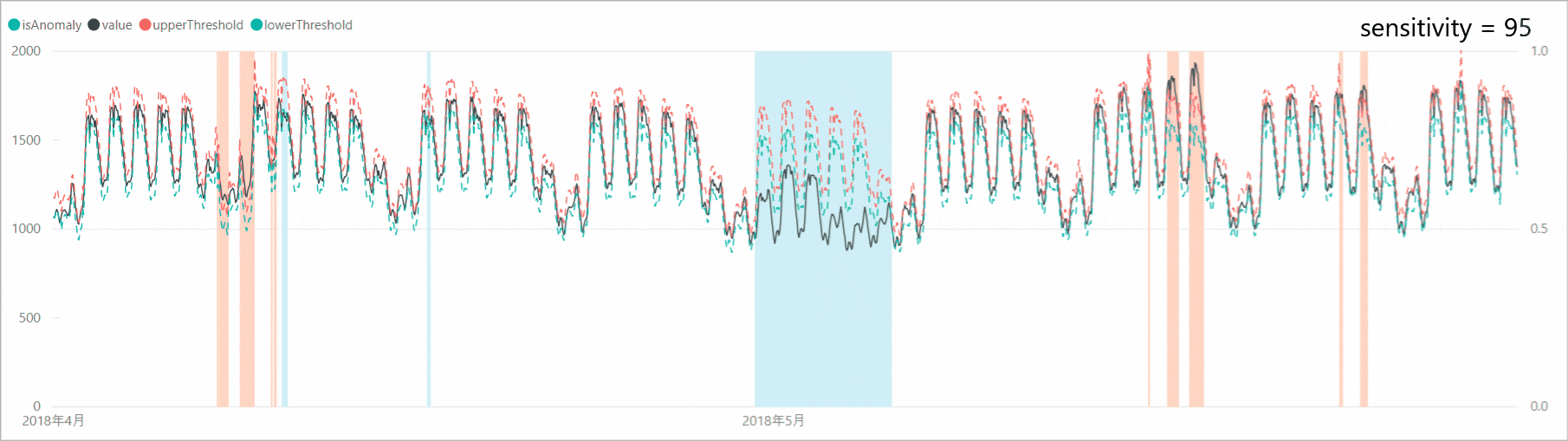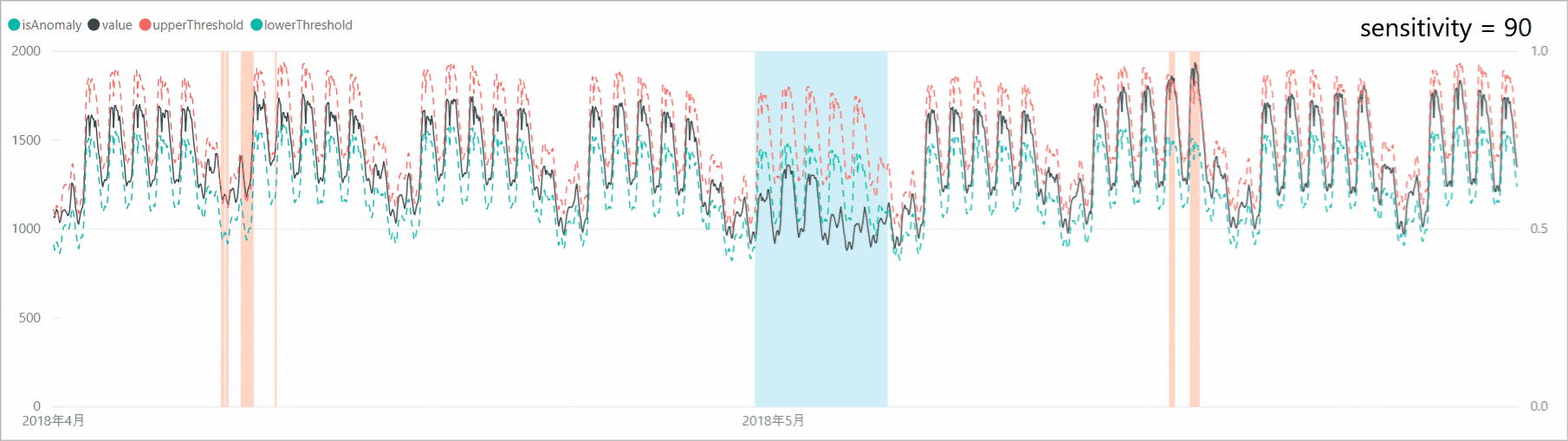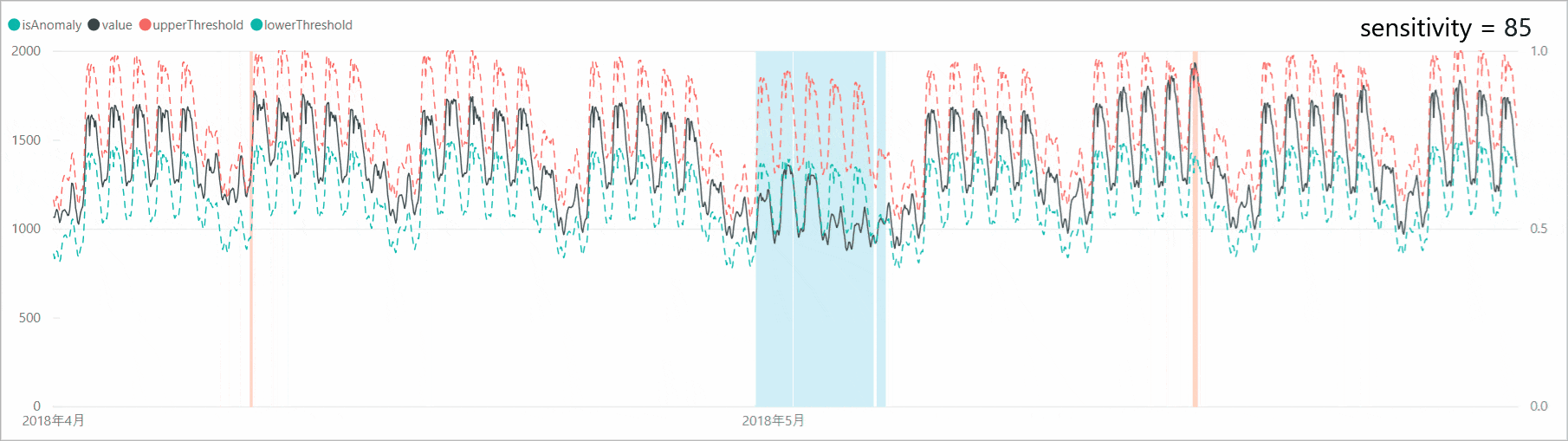
スクリプトを実行して得られた結果を可視化してみると、ゴールデンウィーク期間の平日の電力需要を「異常」として検知できていました。
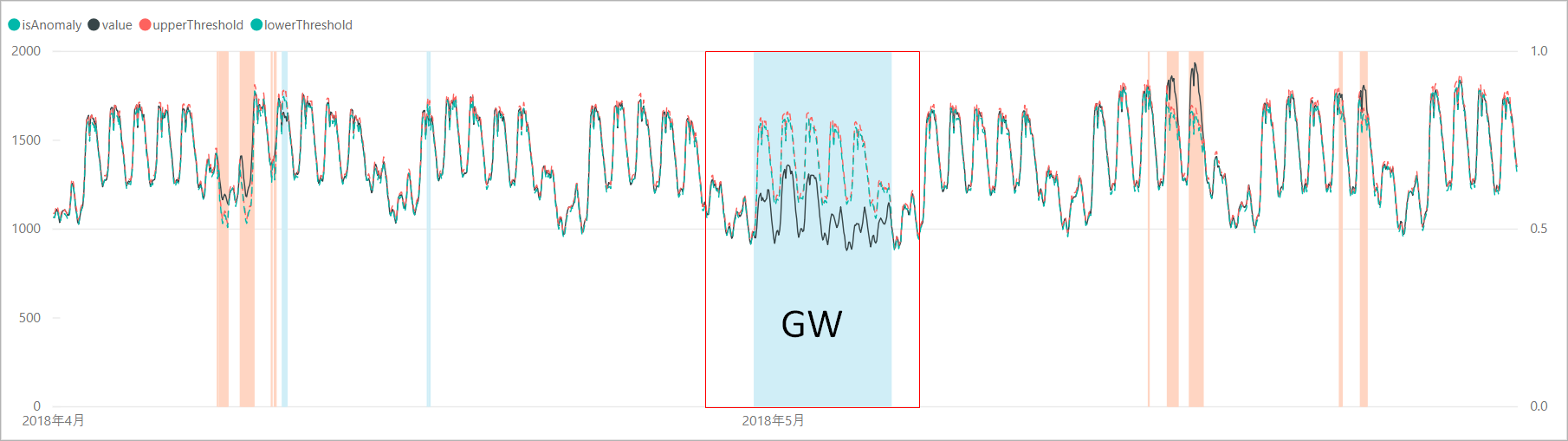
ゴールデンウィーク期間の閾値のカーブを見ると、前後の週と似たような電力需要カーブを示しており、1週間のパターンに基づいて需要の予測をしていることがわかります。
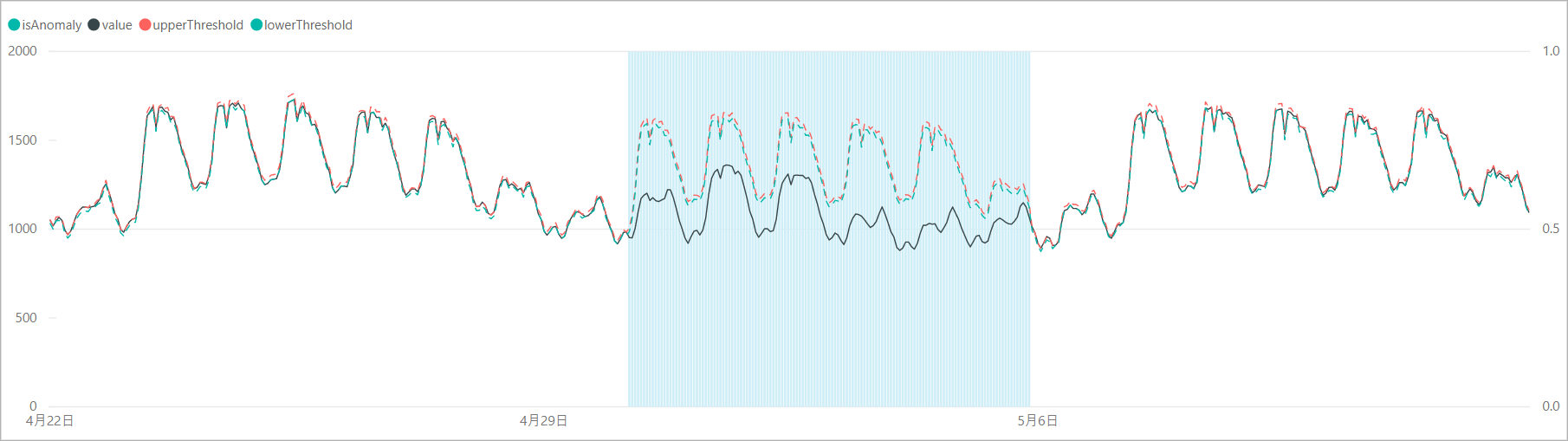
レスポンスの「period」を見ると168 (= 7×24)となっており、電力需要のパターンが1週間単位で現れることを判定できていました。
{
"expectedValues": [
1077.67,
...
],
"isAnomaly": [
false,
...
],
"isNegativeAnomaly": [
false,
...
],
"isPositiveAnomaly": [
false,
...
],
"lowerMargins": [
10.7767,
...
],
"period": 168,
"upperMargins": [
10.7767,
...
]
}
異常判定の調整
リクエスト本文に「sensitivity」オプションを付加すると、異常検知の感度調整をすることができます。感度が高すぎると判定マージンが狭くなり、誤検知も増えるため、「sensitivity」で本当の異常値のみを検知するよう調整します。
とはいえ、今回のデータは「異常」があるわけではないので「sensitivity」の調整による閾値、異常判定の変化を確認します。スクリプトでは、リクエスト本文の設定を以下のように変更します。
body = {
"series": series[:8640],
"granularity": "hourly",
"sensitivity": 99 # => 95, 90, 85
}
「sensitivity」を99、95、90、85と下げていくと、判定マージンが広がり、異常と判定されるポイントが減少していくことがわかります。なお、「sensitivity」が99の場合は、設定しない場合と結果が同じであり、「sensitivity」のデフォルト値は99となっているようです。
まとめ
Anomaly Detector APIは、非常に簡単なリクエストでデータの時系列パターンを判定し、異常を検知できることがわかりました。今回は単純なパターンでの検証でしたが、決まったパターンを持つ時系列データに対しては、モデル作成といった面倒な作業無しに異常検知の仕組みを導入できそうです。
まだ公開されたばかりということもあって、使用できるメソッドは少なく、実行のたびに過去データを送信する必要があるなど、やや使い勝手の悪い面もありますが、Face APIのようにカスタマイズができるように変更が加えられ、より使いやすいAPIになっていくことに期待したいところです。