説明可能かつ調節可能な自然言語学習
はじめに
本記事は,自然言語処理 Advent Calendar 2019, 自然言語処理 #2 Advent Calendar 2019 の12/16(月)の記事です.
本日は KDD2019に採択されたYao Mingらの論文
『Interpretable and Steerable Sequence Learning via Prototypes』
を紹介したいと思います.1
この論文はめちゃくちゃ面白くて, 読んでいてかなりテンションが上ったので, それを皆様にも共有したいと思い, この記事を書きました.
拙い部分もあるとは思いますが, ご一読いただけると幸いです.
系列データとは
系列データとはデータ(単語, 記号もしくはベクトル)が任意の個数連なったデータと定義します.
自然言語(テキスト)や時系列データは系列データです.
データの順序に意味を持ち, 順序を入れ替えると別のデータとなります.
系列データ : A B A B C B A B C
A, B, C : 単語, 記号もしくはベクトル
系列データ 「A B C」 と 「C B A」 は異なったデータ
系列データ分類
DeepLearningによる系列データ分類等のタスクはRNN, LSTM, GRU, BERT, XLNetなど次々に高精度な手法が提案されてきました.
しかし, 予測結果に対してどうしてそのような予測結果を出力したかの根拠を人に説明できない, いわゆるブラックボックスな手法ばかりです.
ブラックボックスな手法は予測の過程が分からないため, 調整を行うことが難しいことも問題点として挙げられます.
提案手法ざっくりとまとめると
予測と説明方法の例として論文中の例を引用します.
これはレビューコメントのポジティブなものかネガティブなものかを予測する問題です.
入力: pizza is good but service is extremely slow
予測: ネガティブ
説明: (類似度 0.69) * (ネガティブ重み 2.1) good food but worst service
+ (類似度 0.30) * (ネガティブ重み 1.1) service is really slow
このように入力テキストに対して, 類似したテキストの類似度とその重みを示すことができます.
提案手法ではユーザが用意したいくつかの系列データ(プロトタイプ系列データと呼ぶ)との類似性を計算し, その類似性に重みをかけて予測を行います.
LSTM等の系列学習モデルは系列データから高次元空間(以後, 特徴空間と呼ぶ)のベクトルへ変換するエンコーダと考えることができます.
この特徴空間は分類をしやすい空間となっていますが, 人が意味を解釈するのは難しい空間です.
特徴空間上の距離は, 2つの系列データの(エンコーダが捉えた)特徴の類似性を表しています.
【ブラックボックス系列データ分類】
入力系列データ(A B A C) =エンコーダ=> 特徴空間ベクトル(1.0, 0.1) =分類器=> 予測(ネガティブ)
【提案手法】
系列データサンプル(A B) =エンコーダ=> 特徴空間ベクトル(0.8, 0.2)
系列データサンプル(C B) =エンコーダ=> 特徴空間ベクトル(0.1, 1.0)
: :
入力系列データ(A B A C)と系列データサンプル(A B)の類似性 10
入力系列データ(A B A C)と系列データサンプル(C B)の類似性 1
類似性ベクトル =分類器(線形モデル)=> 予測(ネガティブ)
予測根拠: (A B A C) と (A B)が類似性が高く, (A B)と類似性が高いものはネガティブである可能性が高い
本日紹介する論文は新しい方法で説明可能(Interpretable)と調整可能(Steerable)を実現した手法です.
説明可能性
この論文では説明可能性についての厳密な定義はされていません.
線形モデル, 決定木は説明可能なモデルであると言われており, 提案手法も線形モデルを使って説明可能性を担保しています.
問題定義
系列データの多クラス分類を行う.
訓練データセットとしてラベル付き系列データセット$\mathcal{D} = \{((\boldsymbol{x}^{(t)})_{t=1}^T, y)\}$が与えられる.
未知の系列データに対する予測を行う.
$(\boldsymbol{x}^{(t)})_{t=1}^T$ : 系列データ
$\boldsymbol{x}^{(t)} \in \mathbb{R}^n$ : $t$ 番目の入力ベクトル
$T$ : 系列の長さ
$y \in {1,...,C}$ : 系列データのクラスラベル
$C$ : クラス数
提案手法
ProSeNet
提案手法のネットワーク構成は以下となります.
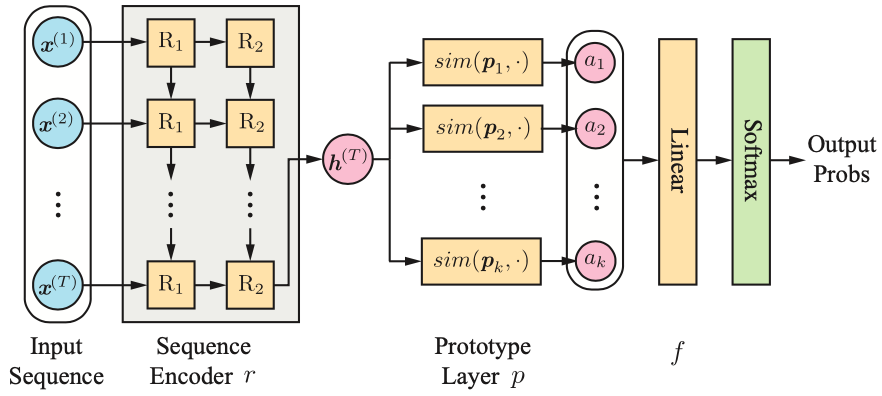
- 系列エンコーダ (Sequence Encoder $r$)
- プロトタイプ層 (Sequence Layer $p$)
- 全結合層 (Linear $f$)
3つによって構成されています.
系列エンコーダ
系列エンコーダでは系列データを特徴量ベクトル $\boldsymbol{e} \in \mathbb{R}^m$ に変換を行います.
このブロックはLSTM, 双方向LSTM(Bi-LSTM), GRUなどの系列学習モデルで実装する事ができます.
筆者らの実験ではそれらの最終ステップの隠れ状態 $\boldsymbol{h}^{(T)} $ を用いてます.
入力データ : 入力系列データ $(\boldsymbol{x}^{(t)})_{t=1}^T$
学習パラメータ : 系列学習モデル $r$ の学習パラメータ
出力データ : 特徴量ベクトル $\boldsymbol{e} =r((\boldsymbol{x}^{(t)})_{t=1}^T)\in \mathbb{R}^m$
プロトタイプ層
プロトタイプ層は $k$個のプロトタイプベクトル $\boldsymbol{p_i} \in \mathbb{R}^m$ を持っていて, 系列データの特徴ベクトル $\boldsymbol{e} \in \mathbb{R}^m$ との類似度を出力します.
プロトタイプベクトルは学習可能なパラメータで, 誤差逆伝播法により学習します.
$k$ 個のプロトタイプベクトルはそれぞれ独立した意味を持って, それぞれ特徴ベクトル $\boldsymbol{e}$ との類似性 $a_i$(スカラ)を計算し, $k$ 次元の類似性ベクトル $\boldsymbol{a}$ を得ます.
類似性の計算は $L_2$距離の2乗を用いても良いですが, 筆者らはそれに指数関数を使っています.
d_i^2 = \|\boldsymbol{e} - \boldsymbol{p_i}\|_2^2 \\
a_i = \exp(-d_i^2) \\
\boldsymbol{a} =
\left(
\begin{array}{c}
a_1 \\
a_2 \\
\vdots \\
a_k
\end{array}
\right)
入力データ : 系列データの特徴ベクトル $\boldsymbol{e} \in \mathbb{R}^m$
学習パラメータ : $k$個のプロトタイプベクトル $\boldsymbol{p_i} \in \mathbb{R}^m$
出力データ : 類似ベクトル $\boldsymbol{a} \in \mathbb{R}^k$
全結合層
類似ベクトル $\boldsymbol{a}$ に重みをかけてクラス予測値 $\boldsymbol{z} = \boldsymbol{Wa}$ を出力します.
ここで $\boldsymbol{W}$ は $C×k$ の重み行列, $C$ は出力サイズ(クラス数)です.
全結合層の出力の後にSoftmax関数でクラスの分類予測を行います.
筆者らは説明可能性を高めるために $\boldsymbol{W}$ の要素は非負となるように制約を加えています.
入力データ : 類似ベクトル $\boldsymbol{a} \in \mathbb{R}^k$
学習パラメータ : $\boldsymbol{W}$
出力データ : 予測値ベクトル $\boldsymbol{z} = \boldsymbol{Wa}$
学習方法
このネットワークの学習パラメータ $\Theta$ は系列エンコーダ $r$ と全結合層 $f$ の学習パラメータとプロトタイプ層 $p$ のもつプロトタイプベクトル集合から成ります.
このネットワークは全て偏微分可能な関数で表現されているため, パラメータ $\Theta$ は誤差逆伝播法で学習することが可能です.
精度を良くするために訓練データセット $\mathcal{D}$ に対するクロスエントロピーロスを最小化するようにパラメータ $\Theta$ を訓練していきます.
CE(\Theta, \mathcal{D}) = \sum_{((\boldsymbol{x}^{(t)})_{t=1}^T, \boldsymbol{y}) \in \mathcal{D}} \boldsymbol{y} \log \hat{\boldsymbol{y}} + (1 - \boldsymbol{y}) \log (1 - \hat{\boldsymbol{y}})
提案手法ではこれに加えて, 4つの正則化項を加えています.
(個人的にこの正則化がとても興味深かったです.)
多様性正則化
筆者曰く, プロトタイプの数 $k$ を大きく(具体的にはクラス数の2, 3倍) にすると, 学習が進むにつれてプロトタイプベクトルは互いに似た値をとってしまいがちであるため, プロトタイプベクトルを多様性を得るためにプロトタイプベクトル同士の距離が近いことに対するペナルティを加えます.
R_d(\Theta) = \sum^k_{i=1}\sum^k_{j=i+1}\max(0, d_{min} - \|\boldsymbol{p}_i - \boldsymbol{p}_j\|_2)^2
ここで $d_{min}$ は2つのプロトタイプベクトルが近いかどうかの閾値となります.
筆者らの実験では $d_{min}$ は 1.0 もしくは 2.0 を採用しています.
これにより, プロトタイプベクトル同士が特徴空間上で離れるようになり, プロトタイプベクトルの多様性を獲得します.
クラスタリング正則化と根拠正則化
説明可能性を高めるために, クラスタリング正則化 $R_c$ と根拠正則化 $R_e$ を加えます.
これはLiら[1]によって提案された方法です.
訓練データの特徴ベクトルとプロトタイプベクトルを近づける正則化を行います.
特徴空間は説明が困難な空間であるため, 未知の系列データの特徴ベクトルに対しても説明が困難です.
それに対し, 訓練データの特徴ベクトルに近いかどうか(類似しているかどうか)というのは説明ができそうです.
そのため, プロトタイプベクトルを訓練データの特徴ベクトルに近づける正則化を行います.
1つ目は訓練データの特徴ベクトルに対してプロトタイプベクトルを近づける正則化です.
R_c(\Theta, \mathcal{D}) = \sum^k_{(\boldsymbol{x}^{(t)})_{t=1}^T \in \mathcal{X}} \underset{i=1,..,k}{\min} \| r((\boldsymbol{x}^{(t)})_{t=1}^T) - \boldsymbol{p}_i\|_2^2
ここで $\mathcal{X}$ とは訓練データセット$\mathcal{D}$の系列データの集合です.
2つ目はプロトタイプベクトルに対して訓練データの特徴ベクトルを近づける正則化です.
R_e(\Theta, \mathcal{D}) =
\sum^k_{i=1}
\underset{(\boldsymbol{x}^{(t)})_{t=1}^T \in \mathcal{X}}{\min} \| \boldsymbol{p}_i - r((\boldsymbol{x}^{(t)})_{t=1}^T)\|_2^2
プロトタイプベクトルを訓練データの特徴ベクトルに近づけるには2つのアプローチがあり,
- プロトタイプベクトルが訓練データの特徴ベクトルに近づく.
- 訓練データの特徴ベクトルがプロトタイプベクトルに近づく(ようにエンコーダ $r$ を学習.する)
クラスタリング正則化と根拠正則化はどちらも1, 2を促しています.
スパース正則化
さらに説明可能性を高めるために 全結合層の重み $\boldsymbol{W}$ に対して $L_1$ のペナルティを与えます. これにより, 不要な重みが小さくなります.
また前述の通り $\boldsymbol{W}$ の要素は非負となるように制約を加えています.
最適化目的関数
最終的にクロスエントロピーロスに4つの正則化項を加えたものを最小化するように学習します.
Loss(\Theta, \mathcal{D}) =
CE(\Theta, \mathcal{D}) +
\lambda_c R_c(\Theta, \mathcal{D}) +
\lambda_e R_e(\Theta, \mathcal{D}) +
\lambda_l \|\boldsymbol{W}\|_1
$\lambda_c$, $\lambda_e$, $\lambda_l$ は各正則化項の重みを調整するハイパーパラメータです.
クロスバリデーションによって値を選択します.
ドメイン知識によるProSeNetの調整
プロトタイプベクトルから訓練データセット内の近い系列データを見つけることができます.
\boldsymbol{p}_i \leftarrow
\underset{\boldsymbol{e} \in r(\mathcal{X})}{\rm argmin}
\| \boldsymbol{e} - \boldsymbol{p}_i \|_2
提案手法では説明性, 性能を良くするためにユーザはプロトタイプベクトルを編集することができます.
つまりユーザはプロトタイプ系列データ $seq$ を好きに選んで, プロトタイプベクトル $r(seq)$ とすることができます.
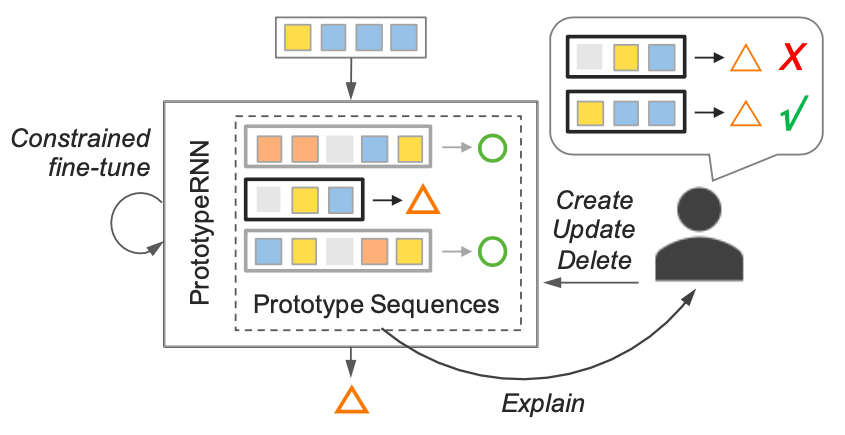
更新と検証により人がドメイン知識を組み込むことができるスキームとなっています.
実験結果
本論文では6つもの面白い実験結果がありますが, そのうちの1つだけ紹介します.
あるレストラン利用者レビューのテキストと評価☆(5段階)のデータセットを元にポジティブネガティブの2値分類を行っています.
実験の精度の表は以下となります.
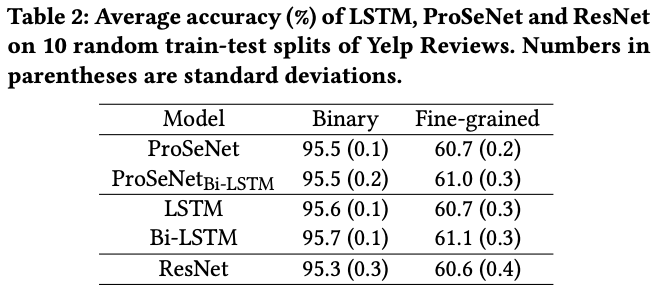
なんと双方向LSTM(Bi-LSTM)と同等の精度を出しています.
(これはめちゃくちゃすごいと思います.)
結果の可視化はこのようにできます.

まとめ
この論文はKDDに採択されるだけあって, とても良い論文だったと思います.
今回, 論文の一部しかまとめることができませんでしたが, 面白さを少しでも共有できていれば嬉しいです.
今回初めて(?)記事を投稿しましたが, とても楽しく書くことができました.
しばらく忙しくて, 次はいつ投稿できるか分かりませんが, また時間を作って投稿したいと思っています.
また, 修正するべき箇所等ございましたら, コメント等でお知らせいただけると幸いです.
P.S.
ソースコードはこちらで公開される予定のようですが, 現在(2019/12/16)は残念ながら準備中のようです.
参考文献
[1] Oscar Li, Hao Liu, Chaofan Chen, and Cynthia Rudin. 2018. Deep Learning for Case-based Reasoning through Prototypes: A Neural Network that Explains its Predictions. In AAAI Conference on Artificial Intelligence.
-
画像や数式は論文から引用しています. ↩