ちょっと調べる機会があったので、まとめておく。自分用メモ。
インスタンス認識、および画像検索とは
画像認識によると、
インスタンス認識とは
東京タワーを見て電波塔と認識するのではなく、東京タワーとして認識するように対象物体そのものを特定すること
画像検索問題とは
入力画像からデータベース内の画像をすばやく探す問題
画像検索はインスタンス認識の中心的な課題の一つ。
インスタンス認識の実現方法
- 蓄積された画像群から局所特徴を抽出し、画像データベースを作成する。
- クエリ画像の局所特徴を抽出する。
- クエリ画像の局所特徴を1つ取り上げ、画像データベースの全局所特徴と比較する。最も類似した局所特徴をもつデータベース内の画像に1票を投じる。この投票を入力画像がもつ局所特徴すべてに対しておこなう。
- データベース内で最も票を獲得した画像の物体をクエリ画像の物体として認識する。
課題は以下の2点。
- 局所特徴すべてを覚えておくのは大量のメモリを必要とする
- すべての局所特徴との類似度計算は計算コストが高い
BoVW
局所特徴をベクトル量子化することでメモリ容量の削減は可能。BoVWはBag of Visual Wordsの略で、Bag of Wordsのコードワードバージョン。画像検索に適したBoVWの拡張として、TF-IDFの利用がある。また、転置ファイルインデックス(コードワードと画像の対応表)を用い、内積計算を類似度の指標とすることで画像検索をすることもできる。
空間的関係性の考慮
BoVWは空間情報を利用していない。よって、空間情報を利用すれば精度は上がると考えられる。そこで、アフィン変換を利用する。クエリ画像とデータベース内の画像との局所特徴同士の空間的関係性をアフィン変換を利用して評価する。アフィン変換の推定方法としてRANSAC(random sanmple consensus)と呼ばれるアルゴリズムが提案されている。
- 変換に矛盾しない局所特徴のペア数の最大値を$N_{max}$=0 とする。
- 合致した局所特徴のペアのうち、いくつかをランダムに選択する。
- 選択された局所特徴ペアからアフィン変換のパラメータを推定する。
- 推定された変換に矛盾しない局所特徴ペアを探す。この局所特徴ペアの数を$N_{tmp}$とし、矛盾しない局所特徴ペアから変換を再推定する。
- もし$N_{tmp}$ > $N_{max}$であれば、$N_{max}$ ←$N_{tmp}$として、再推定された変換を保持する。
- ステップ2に戻る。
この検証プロセスは計算コストがかかるため、転置ファイルインデックスを用いて、対象を絞り込むとよい。
質問拡張
クエリ画像に対して検索された上位の結果を改めてクエリとして再利用し、新たな検索結果を得て検索性能の向上を試みる手法。
average query expansionは元のクエリと検索結果の平均を用いて、クエリとする。一方、discriminative query expansionは上位の結果と下位の結果を分離するモデルを構築し、このモデルをクエリとする。また、目的は同じだが、Diffusionと呼ばれるものもある。Efficient Diffusion on Region Manifolds: Recovering Small Objects with Compact CNN Representationsを参照。
データベース内の画像の特徴ベクトルの拡張
上の質問拡張はクエリの特徴ベクトルを拡張することによって、検索結果を増やしていたが、データベース内の画像の特徴ベクトルを拡張することでもこれは実現可能。データベース内の画像同士で類似度を測っておき、それが一定以上の値であれば隣接する画像とみなして、グラフ構造を構築する。そして、検索時にはグラフ構造上の注目画像に隣接する画像に含まれる局所特徴を注目画像の局所特徴として加えることで、データベース内の画像の特徴ベクトルの拡張をおこなう。
効率的なベクトル量子化
階層的K-meansがある。特徴空間に対して、再帰的にk-meansで分割していき、特徴量をコードワードに割り振る。
画像検索
クエリ画像とデータベース内のすべての画像と距離を測り、昇順にソートすることでデータベース内のすべての画像をランキングすること。ただし、これでは計算時間がかかりすぎる。
木構造の利用
kd-tree。
まず、特徴空間をK-meansのように階層的に分割。具体的には空間の軸を1つ選び、設定した閾値を境界として空間を2つに分ける。閾値の決め方は色々あって、例えば分布のばらつきが大きい軸の中央値とする方法などがある。分割されたセルがノードに対応してこの操作を分割された空間に繰り返し適用することで木構造を構築する。末端の葉ノードに対応するセルに含まれる特徴ベクトルの重心を計算し、この重心を葉ノードの代表ベクトルと考える。
こうして構築した木構造を使って、入力クエリを子ノードに割り振る。最終的には葉ノードに割り振る。入力クエリと割り振られた葉ノードの代表点との距離をdとすると、クエリの最近傍のデータは代表点と距離dの超球内に存在する。したがって、この超球と重なる葉ノードのセルをすべて取り上げて、このセルに含まれるデータとクエリの距離を測ることで最近傍のデータを発見できる。ただ、次元の呪いを受けやすい。
バイナリコード変換
特徴ベクトルをバイナリコード(ベクトルの各要素が+1または-1で表されるベクトル)に変換する。ハミング距離を用いることで高速に計算可能。SIMDや距離の計算がXOR一発であること、並列計算可能であることなどから考えると、ある程度の画像までは特に工夫はいらなそう。
ただ、これにハッシュテーブルを組み合わせる方法もある。ランダム射影やPCAを用いたハッシングやスペクトルハッシングなどがある。
効率的な類似画像検索のためのハッシングという網羅的な資料があり。
直積量子化
特徴ベクトルをM個のサブベクトルに分割し、各サブベクトルで張られる空間において、サイズKのコードブックをもつベクトル量子化器を考える。これを考えることにより、全体として$K^M$のコードワードを表現できるが、実際に保持するコードワード数はMKだけですむために効率的である。これを直積量子化と呼ぶ。この手法を用いることで、元の特徴空間の距離を高速に計算できる距離に近似できる。
surveyする
上記で基本的な知識は得た?として、survey論文的なpaperを読む。
Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarkingというpaperによくまとまっているように見える。
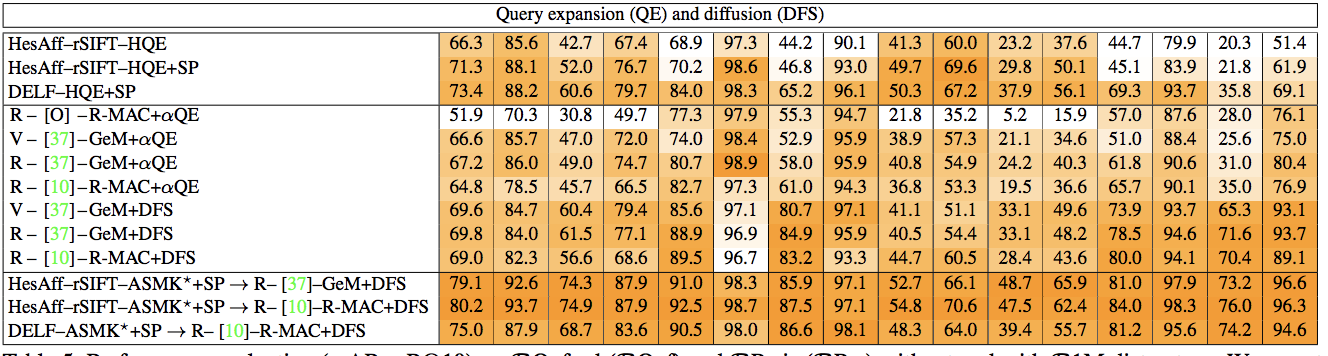
この論文は、Local-feature-based methodsと CNN-based global descriptor methodsの比較が主題。前者が上で述べたBoVW的なアプローチ(局所的な特徴を使うという意味で)で後者が特徴ベクトルの生成にCNNを使って、画像全体を表すベクトルを出力して、あとは近いベクトルを探す手法だと思う。ちなみに上の表は上2つが非CNNのアプローチで、3番目から下はCNNを用いたアプローチ。一番上のセクション(SIFTを使っているのとDELF)はlocal featureを使ったアプローチで、真ん中は、CNN-based global desriptor methods。一番下のセクションは単一の手法ではなく、部分的に組み合わせている。やっぱりアンサンブルが最強なのね。
Starting the diffusion process from geometrically verified images obtained by BoW methods combines
the benefits of the two worlds.
アンサンブルについて述べているのはここで、Diffusionするときに対象をlocal-feature based な手法で絞ると良いらしい。
総括は
The new dataset and protocols reveal space for improvement by CNN-based global descriptors in cases where local features are still better.
と言っている。とりあえずはCNN-based global descriptorを使うアプローチでいいのかな。
上の表で緑の10と緑の37があるが、これは参考文献を示している。これはfine tuningの仕方は37のpaperに従いました、という意味らしい。重要論文の雰囲気がするので、たどっておく。
- Fine-tuning CNN Image Retrieval with No Human Annotation
- End-to-end Learning of Deep Visual Representations for Image Retrieval
ネットワークはfine-tuningしないといけないと思っていたが、そうでもないらしい。直接使っても割と良い性能らしい。
Fine-tuning CNN Image Retrieval with No Human Annotation
要約すると、the unsupervised fine-tuning
of CNNs for image retrieval をしている。
- SfM情報を用いて、データを分類
- 白色化はfine-tuningとは別に行列を推定
- trainable pooling layerの導入
- a novel α-weighted query expansion
End-to-end Learning of Deep Visual Representations for Image Retrieval
- データセットを綺麗にする
- a siamese architecture that combines three streams
with a triplet loss - RMAC
descriptor(regional maximum
activations of convolutions )
また、ざっとこれらの論文を見た感じ、特徴ベクトルを得たあとの計算は内積を使っている。これは他の手法との比較のため内積を使っている。よって、実際にはもっと精度が出るやり方(いわゆるapproximate-nearest neighbor search meth)を使えば良いだろう。