こんにちは。Preferred Roboticsで「カチャカ」を開発している村瀬です。
前回の記事では、kachaka-apiを使ってカチャカを思い通りに動かすための方法を説明し、例として、寿司を回したり、ジェンガを動かすサンプルが紹介されています。
紹介されている機能をカチャカに入れれば、普段使いの他に、友人を招いた時など新しいパーティーゲームもできて最高ですね!

ただちょっと考えてみて下さい。記事のままだと、パーティーゲームを開始するのに、わざわざパソコンを出してきて、ブラウザでJupyter Notebookを立ち上げて実行することになります。未来の生活を謳うスマートファニチャープラットフォームのはずが、パーティー中に突然パソコン開いてカタカタやり出すのはちょっといただけないですね。

というわけで、今回は『カチャカの画像を使って、タスクを開始する(例: パーティーゲームを開始する)』記事になります。カチャカが通常の働きをしてくれる最中、皆さんのアイデアで実装したタスクの実行タイミングを、画像を用いて判断させてみましょう。
事前準備
まず、前回の記事 を参考に、Jupyter Notebookにサンプルコードとkachaka-apiのダウンロードまでを実施して下さい。また、Playgroundにsshでログインする を実施頂き、パソコンからカチャカにsshログインできる状態にして下さい。
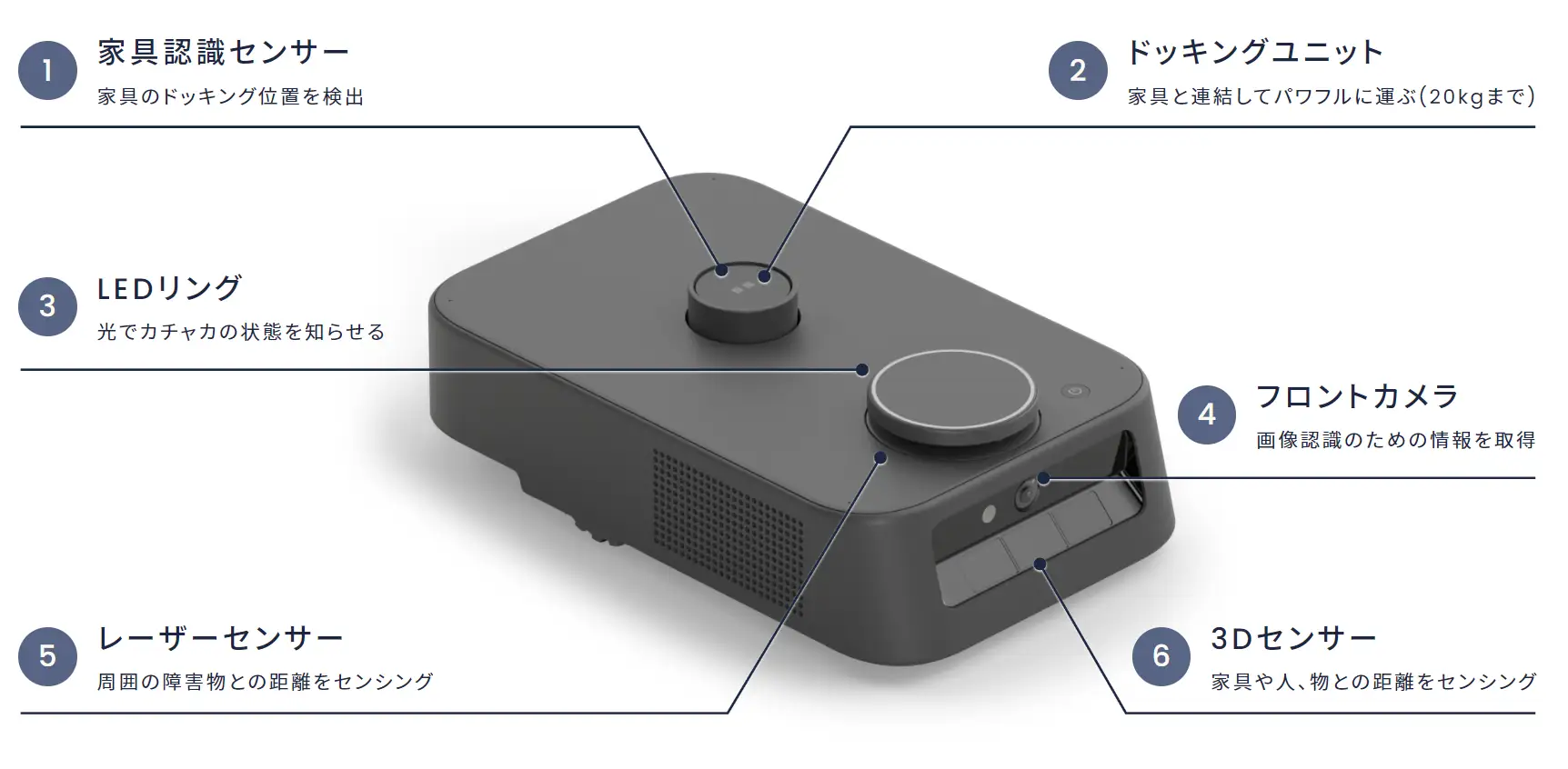
フロントカメラから画像を取得する
カチャカには様々なセンサーがついており、2023年9月時点のAPIでは、フロントカメラとレーザーセンサーからデータを取得することができます。今回はフロントカメラから得られるRGB画像を使用します。
では画像を取得してみましょう。
Jupyter Notebookでkachaka-api/python/demos以下にあるget_front_camera.ipynb を開き、順に実行して下さい。カチャカのフロントカメラから圧縮画像と生画像が1枚ずつ取得され、画面上に表示されます。
以下、重要な処理の抜粋です。
前回記事と同様、kachaka-apiを使用するのに便利なクライアントを作成します。
import kachaka_api
client = kachaka_api.KachakaApiClient()
以下の1行目が圧縮画像を取得する手続き、2行目が生画像を取得する手続きになります。
圧縮画像はデータサイズが小さく、生画像に比べ高速に取得可能ですが、画質が悪くなります。今回においては、圧縮画像で問題なく目的が達成可能なため、以降は全て圧縮画像を用いた実装を行います。
image = client.get_front_camera_ros_compressed_image()
image = client.get_front_camera_ros_image()
続いてget_front_camera_continuous.ipynb を開き、順に実行してみましょう。画像が連続的に取得され動画のように表示されます。
以下、重要な処理の抜粋です。
クライアント作成方法が、上記と少し異なる(.aioが間に挟まっている)ことに注意して下さい。
import kachaka_api
client = kachaka_api.aio.KachakaApiClient()
以下のようにasync for構文を用いて画像を取得しています。imageに前のサンプルと同じ圧縮画像データが格納され、同様にアクセスすることができます。
async for image in client.front_camera_ros_compressed_image.stream():
...
画像内のQRコードを読み込む
続いて、取得した画像を用いた認識を行ってみましょう。
上記のget_camera_front.ipynb サンプル実行時に、以下の行を実行していると思います。これにより、カチャカ体内にはOpenCVのpython版(GUIによる拡張が除外されたもの)がインストールされています。OpenCVとは、オープンソースのコンピュータビジョン用ライブラリで、様々な種類の画像認識を簡単に試すことができます。
!pip install -q opencv-python-headless
OpenCVを用いて、QRコードを認識してみます。
まず準備として、お手持ちのスマートフォンなどのブラウザで https://pf-robotics.github.io/textcode/ にアクセスし、”Text”の欄に適当な英数字を入力して下さい。対応するQRコードが生成されます。

続いてqrcode.ipynb を開き、順に実行してみましょう。動画が表示されたら、先程生成したQRコードをカチャカのフロントカメラの前にかざして下さい。以下のように、QRコードの領域とテキストの内容が認識されている様子が確認できます。

以下、重要な処理の抜粋です。
kachaka-apiを用いて取得した画像を、OpenCVで処理可能な形式に変換します。
cv_image = cv2.imdecode(np.frombuffer(image.data, dtype=np.uint8), flags=1)
QRコード認識を行う手続きは、たったこの2行だけです。
decoded_infoにテキストの内容が、cornersに画像内のQRコード領域情報が入っています。
qcd = cv2.QRCodeDetector()
decoded_info, corners, _ = qcd.detectAndDecode(cv_image)
OpenCVの関数を使って、結果(テキストの内容とQRコードの領域)を画像内に描画します。
cv_image = cv2.polylines(...)
cv_image = cv2.putText(...)
このサンプルを応用することで、『あるテキストをカチャカが認識したら、タスクを開始する』という処理を記述するイメージを持つことができると思います。
次の章に進む前に、1点、発展事項です(読み飛ばして次の章に進んで頂いても構いません)。
カチャカのフロントカメラは広角で、QRコードが画像の中心からずれると歪みが大きく、認識されづらくなってしまいます。
そこで、画像の歪み補正を行うことで、QRコードの認識率を向上させることができます。
下の画像において、左が補正前、右が補正後です。画角は狭くなってしまいますが、直線をしっかり拾えるようになり、認識しやすくなります。


歪み補正を行うには、カメラの内部パラメータ及び歪み係数を取得する必要がありますが、カチャカの機体毎に求められたそれらの値をAPI経由で取得することができます。
undistort.ipynb が、歪み補正した画像を取得し表示するサンプルとなっていますので、意欲のある方は、QRコードサンプルと組み合わせてみて下さい。
特徴点マッチングを使う
QRコードを見せる、というのもまだ抵抗感があるかもしれません。日常で人間が認識しているような物体をカチャカに認識させてみましょう。
まず、認識させたい物体を用意します。用いる認識器の都合上、(1) ”文字や絵がプリントされていて、はっきりした濃淡がある” (2) “ 柔軟物ではない” ものが望ましいです。
私はひとまず左手にポテトチップスがあったので、これを使います。これは上述の条件(1)と(2)を満たしています。

feature_matching.ipynb を開いて、順に実行して下さい。
途中、カチャカの画像とその中央付近に赤枠が表示されたら、その中に認識させたい物体を映し込みます。セルを実行後10秒で撮影されるので、お待ち下さい(もし間に合わなかった場合は、同じセルを再度実行して下さい)。

更に次のセルを実行すると、以下のような動画が表示されます。左側に撮影した画像が、右側に現在のカチャカの画像が表示され、類似箇所が線分で結ばれるのが確認できます。左下には、良く一致していると判断している対応点の個数が表示されています。
物体を動かして認識の様子を確認してみて下さい。

物体を完全にカチャカから見えないところに移動させると、以下のように一致点数が少なくなります。

近くに使いかけのアロンアルファも置いてあったので、試してみます。これは条件(1)を満たしていますが、柔軟物ではありますね。

撮像して....

ぐねぐね曲げたりしなければ認識できていますね。

認識できることを確認したら、同じNotebookの続きで以下を入力・実行し、画像を保存しておきます。
赤枠内になるべく背景が映り込まない、あるいは背景がなるべく無地の状態での撮影をオススメします。
cv2.imwrite("/home/kachaka/target_object.png", orig_image)
以下、重要な処理の抜粋です。
赤枠内の画像を抽出したorig_imageを対象に、特徴点と特徴量を以下2行で取得しています。今回はORB特徴量を抽出していますが、OpenCVでは他にも様々な特徴点・特徴量の抽出手法をサポートしていますので、是非調べてみて下さい。
orb = cv2.ORB_create()
orig_keypoints, orig_descriptors = orb.detectAndCompute(orig_image, None)
特徴点は、一般的に、濃淡がはっきりしているエッジやコーナーを検出することで取得され、特徴量は、特徴点の周りの画像情報を用いて、ある計算式を用いて値(これはベクトルで表されることが多いです)を算出します。
上述の条件(1)、(2)が大事な理由がここにあります。他の物体と区別しやすい特徴点・特徴量が算出できる(濃淡のはっきりしてるエッジやコーナーが多い)こと、またその値が変化しにくいこと(ぐにゃぐにゃ曲がる柔軟物だと変化しやすくなります)が重要です。
上記で取得した特徴量を、新規に取得した画像から算出した特徴量と比較する手順が以下になります。
keypoints, descriptors = orb.detectAndCompute(cv_image, None)
matches = bf.knnMatch(orig_descriptors, descriptors, k=2)
一致度が距離として算出された後、良い一致のみを抽出する手順が以下になります (詳細はLowe’s ratio testで調べてみて下さい)。
good = []
for m, n in matches:
if m.distance < ratio_threshold * n.distance:
good.append([m])
認識結果を使ってタスクを開始する
ではタスクと統合してみましょう。
前回記事の速度を指定して移動させる のところで紹介されていたコードを流用し、jenga_game_moveという関数を作り、特徴点マッチングで認識された良い一致の数がある閾値を超えたらjenga_game_move関数を呼び出すコードを書いてみます。
import asyncio
import cv2
import kachaka_api
import numpy as np
import time
velocity_duration_sequence = [
(0.5, 0.0, 5.0),
(0.0, -0.5, 5.0),
(0.0, 0.5, 5.0),
(0.0, -0.5, 5.0),
(0.0, 0.5, 5.0)
]
ratio_threshold = 0.75
good_matches_length_threshold = 20
def jenga_game_move(client):
client.speak("ゲームスタート")
client.set_manual_control_enabled(True)
for linear_speed, angular_speed, duration in velocity_duration_sequence:
start_time = time.time()
while time.time() - start_time < duration:
client.set_robot_velocity(linear_speed, angular_speed)
time.sleep(0.1)
client.set_robot_velocity(0.0, 0.0)
client.return_home()
async def trigger_task_by_perception():
aio_client = kachaka_api.aio.KachakaApiClient()
client = kachaka_api.KachakaApiClient()
orb = cv2.ORB_create()
orig_image = cv2.imread("/home/kachaka/target_object.png")
orig_keypoints, orig_descriptors = orb.detectAndCompute(orig_image, None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING)
async for image in aio_client.front_camera_ros_compressed_image.stream():
cv_image = cv2.imdecode(np.frombuffer(image.data, dtype=np.uint8), flags=1)
keypoints, descriptors = orb.detectAndCompute(cv_image, None)
matches = bf.knnMatch(orig_descriptors, descriptors, k=2)
good = []
for m, n in matches:
if m.distance < ratio_threshold * n.distance:
good.append([m])
if len(good) > good_matches_length_threshold:
jenga_game_move(client)
def main():
loop = asyncio.get_event_loop()
loop.run_until_complete(trigger_task_by_perception())
loop.close()
if __name__ == '__main__':
main()
good_matches_length_thresholdに書かれている数字は、特徴点マッチングを試した結果を元に変えてみることをおすすめします。
上記コードを trigger_task_by_perception.py という名前で /home/kachaka/kachaka-api/python に保存してください。 /home/kachaka/kachaka_startup.sh に以下の行を追加すると、カチャカ起動時に自動で実行されるようになります。
python3 -u /home/kachaka/kachaka-api/python/trigger_task_by_perception.py &
すぐに動作を試したい場合は 設定タブ → ロボットを選択 → 「カチャカAPI 」→ 「カチャカAPIを有効化する」をON => OFF => ON と切り替えてください。 サンドボックス環境が再起動して、すぐにスクリプトが実行されます。
jenga_game_move関数で指定した動きは、起動時には実行されませんが、target_object.pngに保存されたポテトチップスの箱を見せることで、カチャカは動き出します。
これで、画像を通してカチャカに新しいタスクを始めてほしい意図を伝えられるようになりました。
まとめ
画像認識を用いて、カチャカに好きなタイミングでタスクを開始させる方法を紹介しました。今回はOpenCVでサポートされている軽量な認識器を利用しましたが、もっとモダンな、深層学習ベースの認識などを使っていきたい場合は、カチャカの外で画像を取得し別のコンピュータで認識器を走らせる必要が出てきます。そういった例に関しても、今後紹介していきたいと思います。