InfluxDBから取得されるデータのフォーマットがPythonでグラフ作成を行うには利便性が低いため,データの前処理を行う
以下に現在出力されるCSVファイルのフォーマット例と理想のフォーマット例を示す.
現在のフォーマット
| 日付 | CPU使用量 | Pod名 |
|---|---|---|
| YYYY-MM-DD-HH-MM-SS | num | pod1 |
| YYYY-MM-DD-HH-MM-SS | num | pod1 |
| YYYY-MM-DD-HH-MM-SS | num | pod2 |
| YYYY-MM-DD-HH-MM-SS | num | pod2 |
| YYYY-MM-DD-HH-MM-SS | num | pod3 |
| YYYY-MM-DD-HH-MM-SS | num | pod3 |
理想のフォーマット
| 日付 | Pod1 | Pod2 | Pod3 |
|---|---|---|---|
| YYYY-MM-DD-HH-MM-SS | CPU使用量1 | CPU使用量1 | CPU使用量1 |
| YYYY-MM-DD-HH-MM-SS | CPU使用量2 | CPU使用量2 | CPU使用量2 |
| YYYY-MM-DD-HH-MM-SS | CPU使用量3 | CPU使用量3 | CPU使用量3 |
理想のフォーマットのようにCSVファイルを新規書き込みを行うのではなく,CPU使用量をPodごとにまとめることにした.
作成イメージを以下に示す.
{Pod1:[CPU使用量1,CPU使用量2,CPU使用量3],Pod2:[CPU使用量1,CPU使用量2,CPU使用量3],Pod3:[CPU使用量1,CPU使用量2,CPU使用量3]}
上記のようにすることで,理想のフォーマットで考えていたようにデータを扱えるようになった.
これらを実装した処理を以下に記載する
def data_preprocessing(csv):
Pods_dic = {}
with open(csv) as f:
r = reader(f)
for i,row in enumerate(r):
#最初の4行をスキップする
if i < 4:
continue
#Pod名をリストにappend
try:
pod = row[len(row)-1]
if pod not in Pods_dic:
Pods_dic[pod] = []
except:
pass
#CPU使用量をリストにappend
try:
amount = int(float(row[6]))/ 1000000000
Pods_dic[pod].append(int(float(row[6]))/ 1000000000)
except:
pass
for i in Pods_dic:
print(f"Pod名:{i} CPU使用量:{Pods_dic[i][:5]},,,")
実行結果を一部記載する
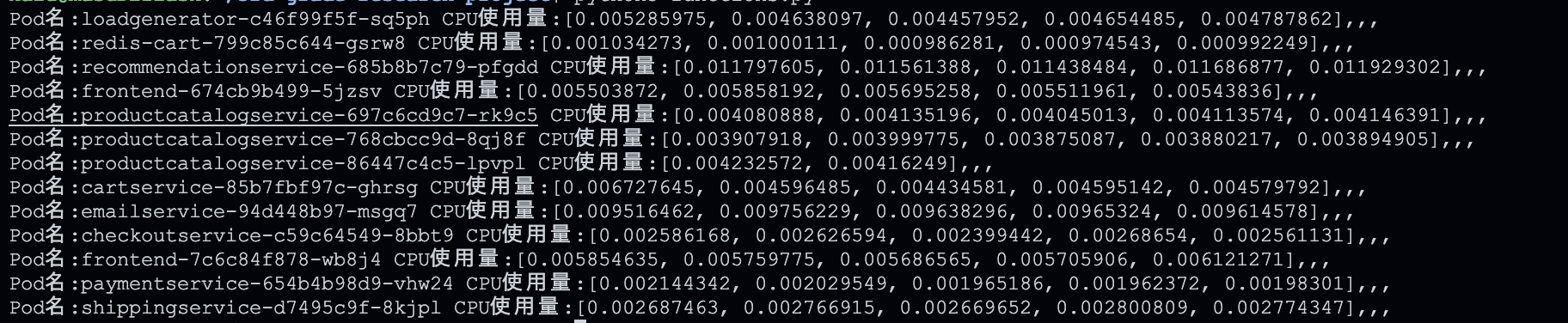
PodごとのCPU使用量の時間推移のグラフを作成する際にこの前処理を行うことでPythonのmatplotlibのみで可能となる.