こんにちは。Kazuki Otaです。この記事はISer Advent Calendar 2020の23日目の記事として書かれました。昨日は、RisebbitさんによるCPU実験で作った命令セットの紹介でした。
今日は、ボードゲームWebアプリ1とそのAIを作ったので、それについて書きます!
はじめに
2016年に、DeepMind社のAlphaGoが、囲碁の人類チャンピオンであるLee Sedol九段を打ち破り、話題となりました。その後、AlphaGoの改良版、AlphaZeroが、自己対戦のみの学習によって、チェスのstockfishや将棋のelmo(どちらも当時の最強ソフト)を同時に打ち破りました。 2
オリジナルのボードゲームでも、自己対戦のみの学習で、人間よりも強い人工知能を作れるのでしょうか?
この記事では、Marchというオリジナルのボードゲームを作成しました。また、その対戦相手をしてくれる人工知能を最も単純なモデルである2層全結合NNを、30万局自己対戦させることで生成しました。その結果、私と良い勝負をする程度の人工知能が完成しました。さらに、その人工知能とweb上で対戦できるようにしました。
目次
この記事では、次の順序で説明していきます。
- ゲームのルール:今回学習するゲーム、Marchのルールについて説明します。
- 人工知能の作り方:今回作成した人工知能のモデルについて説明します。
- 結果:人工知能がどの程度の強さになったのか、を述べます。
- 考察:人工知能との対戦を終えて、感じたことや考察したことを述べます。
ゲームのルール
このセクションでは、今回学習するゲームのルールについて説明します。
このゲームは、March:Simple Chess Web Appで遊ぶことができます。1
ルール
- 2人で遊ぶ交互手番制の対戦ゲームです。
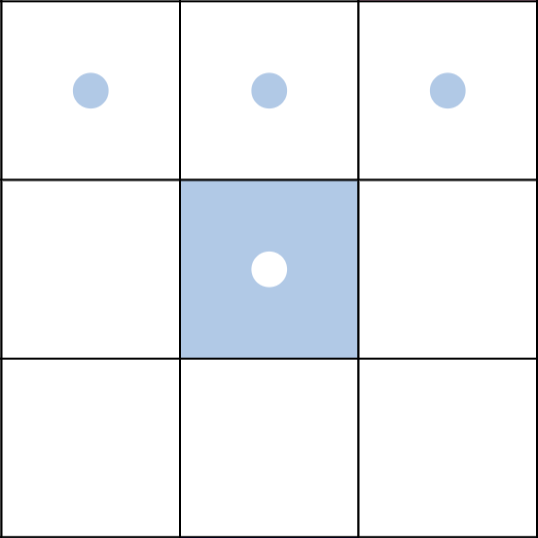
- コマの初期配置は次の通りです。
 - 青が先手で、赤が後手です。
- 青赤それぞれ、濃い色がキングで、薄い色がポーンです。
- 自分の手番にできることは、自分のコマを1つ選び、動かすこと。
- キングもポーンも、コマの動きは共通です。前に1マスか、斜め前に1マス進むことができます。
- 青が先手で、赤が後手です。
- 青赤それぞれ、濃い色がキングで、薄い色がポーンです。
- 自分の手番にできることは、自分のコマを1つ選び、動かすこと。
- キングもポーンも、コマの動きは共通です。前に1マスか、斜め前に1マス進むことができます。
 - 相手のコマが居るマスに移動したら、そのコマを取ることができます。取られたコマは、ゲームから取り除かれます。
- 自分の他のコマが居るマスには移動できません。
- 次のどちらかを満たせば勝利です。
- Catch: 相手のキングを取る。
- Try: 自分のキングを相手陣の最奥段まで進める。
- 相手のコマが居るマスに移動したら、そのコマを取ることができます。取られたコマは、ゲームから取り除かれます。
- 自分の他のコマが居るマスには移動できません。
- 次のどちらかを満たせば勝利です。
- Catch: 相手のキングを取る。
- Try: 自分のキングを相手陣の最奥段まで進める。
実際に遊んでみよう
- このゲームは、March:Simple Chess Web Appで遊ぶことができます。1
- 練習用に、BabyAIとEasyAIが登録されています。
- BabyAI: 合法手をランダムに指します。
- EasyAI: 3手先までを読んで駒得するように指します。
- ぜひ一度遊んでみて、ゲームの感覚を掴んで欲しいです。
- 練習用に、BabyAIとEasyAIが登録されています。
- 持ち時間について
- 持ち時間は、両者とも最初は60秒です。
- 1手指し終わるごとに、持ち時間が10秒増えます。(フィッシャールール)3
- 持ち時間が0になったら負けです。
バリアントルール
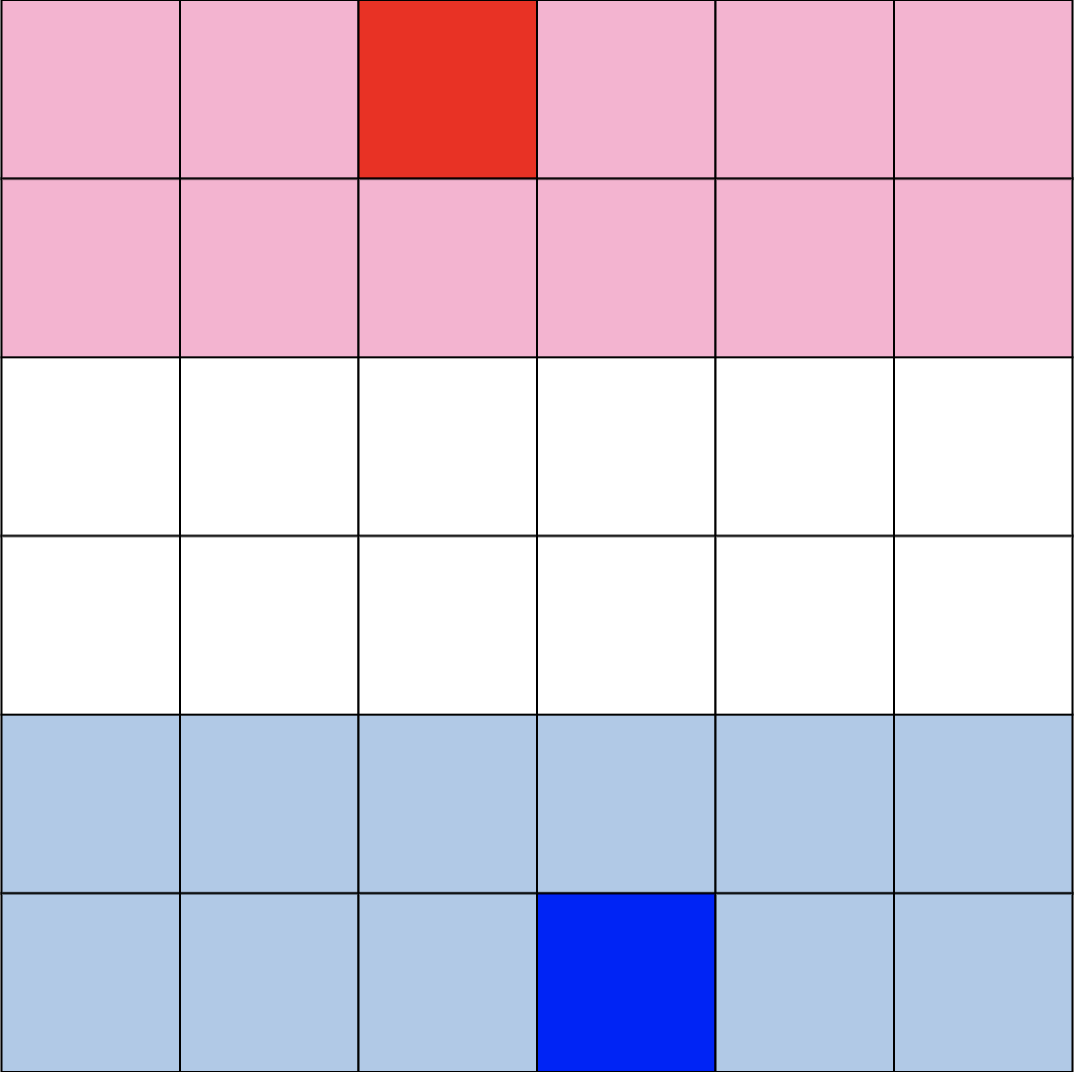
- 実はこのゲームは、初期配置が2つ存在します。
- 上で紹介した初期配置はBlitzという名前の初期配置です。
- 実はもう1つ、Grandという名前の初期配置(下図)も用意してあります。
- Blitzでの対戦に慣れてきたら、ぜひGrandでの対戦にも挑戦してみてほしいです。
人工知能の作り方
このセクションでは、人工知能の具体的な作り方を説明します。
興味がなければ、結果のセクションまで飛んでも大丈夫です。
今回は、2層のニューラルネットワークを、NegaMax法の考え方に基づいて強化学習させていきます。次の順番で説明していきます。
- NegaMax法について
- ニューラルネットワークについて
- 強化学習について
- 学習回数について
- 人工知能と人間の対戦方法
NegaMax法について
- 評価関数とNegaMax法を用いて、学習を進めていきます。
評価関数の定義
- 【定義】評価関数$f$
- 評価関数$f$は、局面$x$を受け取って評価値$f(x)$を返す関数です。
- 定義域について
- 局面$x$は、次の4つの情報から構成されます。
- 手番プレイヤーのキングの位置
- 手番プレイヤーのポーンの配置
- 非手番プレイヤーのキングの位置
- 非手番プレイヤーのポーンの配置
- 局面$x$は、次の4つの情報から構成されます。
- 値域について
- 関数$f$は、$-1 \le f(x) \le 1$を満たす値を返します。
- 受け取った局面が、手番プレイヤーにとって有利であれば$1$に近い値を、不利であれば$-1$に近い値を返します。
- 定義域も値域も、「先手にとって」ではなく、**「手番プレイヤーにとって」**で定義されている点が重要です。
評価関数の理想形(NegaMax法)
- NegaMax法とは、探索アルゴリズムの1種です。4
- 原理は、MiniMax法と全く同じです。
- 【定義】子局面関数$g$
- 関数$g$は局面$x$を受け取り、$x$の次の局面の集合$g(x)$を返す関数です。
- 【定理】評価関数の理想形
- 手番プレイヤーは常に最善の手を指すものと仮定します。
- このとき、理想的には、評価関数$f$は次の等式を満たすはずです。
- 理想形: $\displaystyle f(x) = \max_{y \in g(x)} (-f(y))$
- 証明
- 次の局面$y$の評価値$f(y)$は、次の手番プレイヤー、すなわち、相手にとっての評価値です。
- したがって、自分にとっての評価値は、$-f(y)$になります。
- 自分は$-f(y)$の中で最も有利になる局面を選択すれば良いので、現在の局面$x$の評価値は$\displaystyle \max_{y \in g(x)} (-f(y))$となります。
- この理想形に近づくように、評価関数$f$を学習させていきます。
ニューラルネットワークについて
- 評価関数$f$に、2層ニューラルネットワーク5を用います。
- ニューラルネットワークの詳細仕様は次の通りです。
- 入力層は256ノード。
- 36マスのボードを周囲に壁を加えて64マスに拡張し、4種類のコマそれぞれが存在しているかを表すone hot ベクトルを入力として使います。
- 中間層は50ノード。
- 出力層は1ノード。
- 中間層と出力層に、シグモイド関数を活性化関数として使用しています。
- 入力層は256ノード。
強化学習について
-
今回は、強化学習の中でも、Q学習に近い手法を用います。
-
【定義】 絶対評価関数$h$
- $h$は、局面$x$を受け取り、$-1, 0, 1$のいずれかを返す関数とします。
- 局面$x$において、手番プレイヤーが既に勝利している場合は1を返します。
- 局面$x$において、手番プレイヤーが既に敗北している場合は-1を返します。
- 局面$x$において、まだゲームが続行している場合は0を返します。
-
【定義】修正付き評価関数$\tilde f$
- $\tilde f$は、局面$x$を受け取り、評価値$\tilde f(x)$を返す関数とします。
- ゲームが決着している場合は$-1$か$1$を返し、そうでない場合は$f(x)$の値を返します。
- これは、次のように実装できます。
- $\tilde f(x) = [{\rm if;} |h(x)| = 1 {;\rm then;} h(x) {;\rm else;} f(x)]$
-
強化学習の進め方
- NegaMax法の考え方に基づいて、次のように評価関数$f$を修正します。
- $\displaystyle f(x) \leftarrow \max_{y\in g(x)} (-\tilde f(y))$
- $\leftarrow$記号は、厳密には次のような意味です。
- 勾配降下法により、左辺の値が右辺の値に近づくようにパラメータを修正する。
学習回数について
- 30万局をAI同士で対戦させました。
- 次の3局をセットで行いました。
- 先手:学習中の人工知能、後手:合法手をランダムに指す人工知能。
- 先手:合法手をランダムに指す人工知能、後手:学習中の人工知能。
- 先手:学習中の人工知能、後手:学習中の人工知能。
- 3局が終わるたびに、その中に出てきた局面について、上記のパラメータ修正を行いました。
- 次の3局をセットで行いました。
- 棋譜データなどの教師データは使っていません。
人工知能と人間の対戦方法
- 人工知能が人間と対戦するときは、現局面から1手進めた局面をすべて列挙し、評価関数の値が最も小さい(次の手番である人間が最も不利になる)局面を選択するように実装しました。
結果
-
まずは実際にAIと対戦してみてください。1
- NormalAIとして登録されています。
- 私と対戦してみたところ、良い勝負か、私が少し勝ち越す程度の棋力になっていました。
- この記事の結論は、「人工知能は人間より強くなれなかった」です。
考察
- 実際に対戦してみて、次のような感想を抱きました。
- NormalAIは、一定のパターンにハマってしまうと弱い。
- 1手先しか読んでいないのに、この程度の棋力が出せるのは優秀である。
- 2層NNではなくて、他の手法を用いると、もっと高い性能が出るかもしれないです。
- 例えば、畳み込み層を用いることで、局所的な戦型の評価(王手がかかっているなど)が効率的に学習できるかもしれません。
- また、ガウス過程とも相性が良いかもしれません。絶対評価関数の分散を0として学習を進めていけば、どの局面がまだあまり学習できていないのかがわかるようになるかもしれないと期待しています。
- また、今回の実験を通して、対戦ゲームAIの強さの定量的評価の難しさを痛感しました。
- 対戦相手がいなければ評価ができないため、定量的な性能評価が難しいです。
- 今後も、ゲームの人工知能について研究していきたいと思います。
おわりに
- いかがでしたか。
- 感想など、コメントに頂けると嬉しいです。
- 良い戦術や定跡を見つけたら、それもコメントで教えてください。
- March:Simple Chess Web AppでNormalAIを攻略してみてください。
- もし良かったらLGTMもして頂けると、読まれていることがわかって、とっても喜びます。😊