はじめに
前回、Unity上で強化学習を行えるプラグインであるML-Agentsを導入し、サンプルのゲームを動かしました。
今回はその続きとして、すでに構築されているサンプルの環境ではなく、新たな学習環境を自分自身で作成し強化学習を行うプロセスについて説明します。
この記事では、下のようにランダムな場所に出現するターゲットを自動で認識して射撃をおこなうエージェントを作っていきます。

強化学習とML-Agents
ML-Agentsを触っていく前に、簡単に強化学習と今回使うML-Agentsについて確認しておきます。
強化学習
強化学習とは人工知能の一分野である機械学習の中でも意思決定のための学習を行う手法です。ある環境におかれたエージェント(知的活動を行う対象)が「どのように意思決定をして行動すれば目標を達成することができるのか」ということを定式化して学習を行います。現実世界では、将棋や囲碁のようなゲームや自動運転車、ロボット制御、化学物質の設計などに応用されています。
より具体的には、強化学習の目標はエージェントが置かれた環境から測定できるものを入力として行動をし、その結果得られる報酬の総和を最大化する方策(ある時点でのエージェントの振る舞い方)を学習することになります。特に、ある状態である1つの行動をしたときに受ける即時報酬ではなく、長期的な利益を最大化させることを目指すことに注意してください。
例えば、ある火災現場において自動で火災原因を見つけ消火活動を行う自律消防ロボットを考えます。この時、エージェントであるロボットは常にセンサー(熱センサー、温度センサー、タッチセンサーなど)を通じて環境を認識し、この情報を元にどのように行動するか(移動する、ホースで水をかけるなど)を決定します。このロボットを学習するためには、火を消すことができたときに大きなプラスの報酬を与え、時間が経過するごとに小さなマイナスの報酬を与えるというような報酬信号を与えてやります。この時、ロボットの各行動全てのタイミングで報酬が提供されるわけではなく、ロボットが全体の消火活動に成功したか、もしくは失敗した場合にのみ報酬が提供されることに注意してください。これが長期的な利益を最大化することを目指すということであり、強化学習の特徴でもあります。
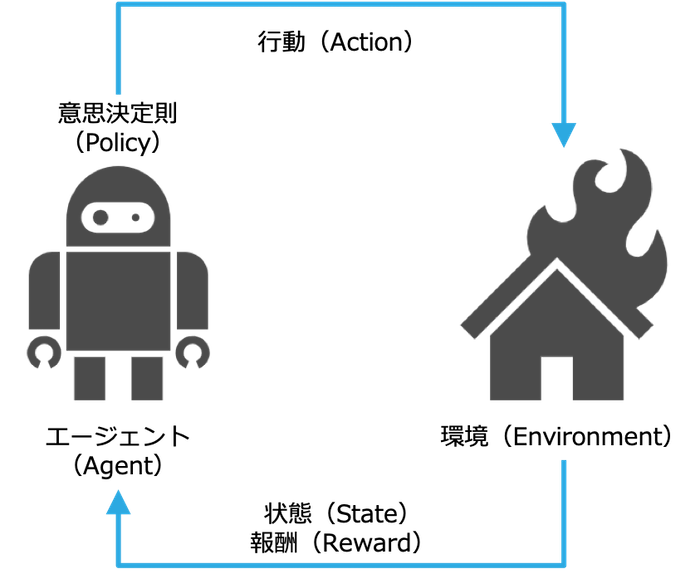
ML-Agents Toolkit
ML-Agents (Unity Machine Learning Agents Toolkit) はUnityで強化学習、模倣学習、遺伝的アルゴリズムやその他の機械学習の学習環境を構築するためのフレームワークです。ML-Agentsを使用すると、以下の3つの要素を定義するだけで簡単にエージェントの動作を訓練することができます。
-
観測
- 訓練を行う環境においてエージェントが何の情報にアクセスすることができるか
-
行動
- エージェントが環境において取ることのできる行動
-
報酬
- エージェントの行動が目的に対してどの程度良かったか(悪かったか)
この3つの要素を定義した後、エージェントの動作を訓練していきます。訓練には、同じ環境下で何度も何度も試行錯誤を繰り返し、報酬を最大化する行動を学んでいきます。
訓練手法
ここでは、ML-Agentsが提供する訓練手法の中で主なものを取り上げます。しかし、そこまで高度な学習環境を設定しない限りこれらの手法の細部まで理解する必要はありません。
深層強化学習
- Proximal Policy Optimization (PPO)
- Soft Actor-Critic (SAC)
ML-Agentsでは1つ目のPPOがデフォルトのアルゴリズムとなっており、今回の例でもPPOを用いて学習します。この手法は他の強化学習の手法と比べても実装が非常にシンプルかつ安定して高いパフォーマンスを出すアルゴリズムとして知られており、広く標準的に用いられている手法の1つです。
詳しくは、原論文を参照していただきたいのですが、PPOは方策のパラメータを勾配法で最適化する**方策勾配法 (Policy Gradient)**を用いる手法の一つで、方策の更新の際、更新前後の方策の比を一定の範囲に制限(クリッピング)することで急激に方策が変化するのを防ぐというのが特徴です。数式を追う必要はないですが、後々パラメータを設定しないといけないので一応目的関数を示しておきます。
L^{C L I P}(\theta)=\hat{E}_{t}\left[\min \left(r_{t}(\theta) \hat{A}_{t}, \operatorname{clip}\left(r_{t}(\theta), 1-\varepsilon, 1+\varepsilon\right) \hat{A}_{t}\right)\right]
パラメータ
- $ \theta $ : 方策パラメータ
- $ \hat{E}_{t} $ : 期待値のサンプル平均近似
- $ r_{t} $ : 更新前の方策と更新後の方策の比
- $ \hat{A}_{t} $ : 時刻 $t$ でのアドバンテージ(純粋な行動の価値)の推定量
- $ \varepsilon $ : ハイパーパラメータ(0.1または0.2)
模倣学習
模倣学習は、他人が行う行動を模倣して(真似して)学習する手法です。ML-Agentsでは、人間が操作するエージェントの行動を模倣して学習を行います。ML-Agentsでは次の2つの手法が提供されています。
- GAIL(Generative Adversarial Imitation Learning)
- Behavioral Cloning (BC)
0. ML-Agents 環境構築
ML-AgentsはUnity上で、強化学習、模倣学習、その他機械学習が行えるプラグインです。
前回もML-Agentsの導入を行いましたが、最新バージョンは導入の仕方が変わっているので改めてインストール方法を簡単に説明します。
環境
- Unity2019.4
- ML-Agents Release10
- Python3.7
Unityのインストール
Unityをダウンロードし、インストールします。
ML-Agents は Unity2018.4 以降のバージョンにしか対応していません。
今回は、Unity2019.4を使用していきます。
Pythonのインストール
ML-Agentsのインストールが終わったらPythonと、周辺ライブラリを入れます。
まず、Anacondaをダウンロードし、インストールします。
Anacondaのインストールが終わったらML-Agents用の仮想環境を用意します。
公式ではPython3.6かPython3.7が推奨されています。今回は、Python3.7を使用していきます。
conda update -n base conda
conda create --name mlagents python=3.7
source activate mlagents
ML-Agentsリポジトリをクローン
適当なディレクトリにML-Agentsリポジトリのクローンを作成します。
git clone --branch release_10 https://github.com/Unity-Technologies/ml-agents.git
com.unity.ml-agentsパッケージのインストール
- Unity上で
Window->Package Managerに移動します。 -
Package Managerwindowで、+ボタンをクリックします。 -
Add package from disk...を選択します。 - クローンしたディレクトリ内の
com.unity.ml-agentsに移動します。 -
package.jsonファイルを選択します。
参考画像
ml-agentsパッケージのインストール
クローンしたディレクトリに移動し、ml-agentsパッケージをインストールします。
pip3 install -e ./ml-agents-envs
pip3 install -e ./ml-agents
1. Unity上で学習環境の作成
今回は学習環境として以下のものを含む非常にシンプルなSceneを作成します。
- エージェントが移動するフィールド
- 射撃対象のターゲット
- 自動でターゲットを射撃するエージェント
| フィールド | ターゲット | エージェント |
|---|---|---|
 |
 |
 |
フィールドとターゲット
フィールドとターゲットに関してはColliderが含まれていれば何でも大丈夫ですが、今回はそれぞれPlaneとCubeで作成し、名前をFloorとTargetにします。
ターゲットに関する補足
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class TargetScript : MonoBehaviour {
GameObject agent;
ShootingAgentScript script;
void Start() {
agent = GameObject.Find("ShootingAgent");
}
void OnCollisionEnter(Collision collision)
{
if (collision.gameObject.tag == "Bullet") {
script = agent.GetComponent<ShootingAgentScript>();
script.Hit();
}
}
}
エージェント
今回のML-Agentsで強化学習を行うにあたってメインのゲームオブジェクトとなるのがこのエージェントです。エージェントに強化学習を行うための機能を実装していき、自動でターゲットを認識し射撃をおこなうよう訓練をしていきます。
エージェントオブジェクトは以下の手順で作成します。
- Cubeを作成し、名前をShootingAgentにします。
- Rigidbodyコンポーネントを追加します。
エージェントについての詳細は次章で説明します。
ビュレット
エージェントから射出する弾はBulletという名前で下のBulletScriptをアタッチしたSphereオブジェクトのプレハブとして用意します。また、このオブジェクトのTagをBulletに変更しておいてください。
BulletScript
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class BulletScript : MonoBehaviour
{
public GameObject particleObject;
void Start() {
Destroy(this.gameObject, 0.5f);
}
}
2. エージェントの実装
ShootingAgentにShootingAgentScriptという新しいスクリプトを追加し、編集していきます。
-
using Unity.MLAgents;、using Unity.MLAgents.Sensors;を追加します。 - スーパークラスをMonoBehaviourからAgentに変更します。
- 3つのメソッドを付け加えます。
- OnEpisodeBegin()
- CollectObservations(VectorSensor sensor)
- OnActionReceived(float[] vectorAction)
それぞれのメソッドをどのように書くかは次のサブセクションで説明しますが、簡単にそれぞれの機能を説明します。
OnEpisodeBegin()
エージェントは何回も同じような環境で試行を繰り返し、失敗や成功しながら与えられたタスク(今回はターゲットを自動で認識して射撃すること)を学習していくわけですが、その時各試行の初期状態(エージェントやターゲットの配置など)をどのようにするかを**OnEpisodeBegin()**に書きます。
CollectObservations()
各試行では、エージェントは与えられた環境の情報(ターゲットの位置や自分の位置・向きなど)を収集し、ブレインに送信します。ブレインはその情報を元にエージェントにどのように行動をすべきか指示します。その際、エージェントが何の情報を収集するかということを**CollectObservations(VectorSensor sensor)**内に書き下します。
OnActionReceived()
最後に、エージェントが行動をした結果タスクにおいて成功や失敗をし、それを元にエージェントに報酬を与えます。成功した場合は高い報酬を与え、失敗した場合は低い報酬を与えたり、全く報酬を与えなかったりします。どのような条件のときにどのような報酬を与えるのかということを**OnActionReceived(float[] vectorAction)**に書きます。
OnEpisodeBegin()
OnEpisodeBegin()には各試行のエージェントや環境上のオブジェクトの初期状態を記載します。
今回の例では、エージェント(ShootingAgent)がターゲット(Target)の射撃に成功するたびにその試行が終了し、ターゲットをランダムな場所に移動させます。また、エージェントがフィールドの外にはみ出してフィールドから落ちた場合、エージェントの速度を0に戻し、フィールド上の初期位置に戻します。
public class ShootingAgentScript : Agent {
Rigidbody agentRigidbody;
void Start() {
agentRigidbody = GetComponent<Rigidbody>();
}
public Transform target;
public GameObject bullet;
public override void OnEpisodeBegin() {
if (this.transform.localPosition.y < 0) {
// 床の下に落ちた場合エージェントを初期位置に戻す
this.agentRigidbody.angularVelocity = Vector3.zero;
this.agentRigidbody.velocity = Vector3.zero;
this.transform.localPosition = new Vector3(0, 0.5f, 0);
}
// ターゲットを新たなランダムな場所に移動させる
target.localPosition = new Vector3(Random.value * 8 - 4,
0.5f,
Random.value * 8 - 4);
}
}
CollectObservations(VectorSensor sensor)
エージェントは、与えられた環境から情報を収集しブレインに送信します。このメソッドでは何の情報を収集するか、すなわち、エージェントの訓練のために用いるニューラルネットワークに何の情報を入力するのかというのを定義します。
今回の例では、 エージェントが収集する情報として、エージェントの位置と向き及びターゲットの位置が含まれます。
public override void CollectObservations(VectorSensor sensor) {
sensor.AddObservation(target.localPosition);
sensor.AddObservation(this.transform.localPosition);
sensor.AddObservation(this.transform.forward);
}
OnActionReceived(float[] vectorAction)
OnActionReceived()には、エージェントがどのような行動をとった場合、どのくらいの報酬を与えるかということを書きます。
OnActionReceived()はエージェントの行動を引数に取るので、OnActionReceived()の中身の前にまず、エージェントにどのような行動が許されているかをMoveAgent()に記述していきます。今回の例では、エージェントにはxおよびz方向への移動とy軸を中心とした回転、さらに射撃(bulletオブジェクトの発射)の行動を取ることができるとします。
public void MoveAgent(ActionSegment<int> act) {
var dirToGo = Vector3.zero;
var rotateDir = Vector3.zero;
var forwardAxis = act[0];
var rightAxis = act[1];
var rotateAxis = act[2];
var shootAction = act[3];
switch (forwardAxis) {
case 1:
dirToGo = new Vector3(0f, 0f, 0.1f);
break;
case 2:
dirToGo = new Vector3(0f, 0f, -0.1f);
break;
}
switch (rightAxis) {
case 1:
dirToGo = new Vector3(0.1f, 0f, 0f);
break;
case 2:
dirToGo = new Vector3(-0.1f, 0f, 0f);
break;
}
switch (rotateAxis) {
case 1:
rotateDir = transform.up * -1f;
break;
case 2:
rotateDir = transform.up * 1f;
break;
}
if (shootAction == 1) {
GameObject bullets = Instantiate(bullet) as GameObject;
Vector3 force;
force = this.gameObject.transform.forward * 300.0f;
bullets.GetComponent<Rigidbody>().AddForce(force);
bullets.transform.position = this.transform.position;
}
transform.Rotate(rotateDir, Time.deltaTime * 100f);
transform.Translate(dirToGo);
}
この行動を元に、エージェントが最適なアクションを取る(今回でいうと、できるだけ早くターゲットを認識し射撃行為を行う)ように報酬を与えます。今回は、ターゲットを射撃することができた場合に1.0の報酬を与え、フィールドから落ちた場合には報酬を与えず初期状態に戻します。さらに、できるだけ早くターゲットを射撃するように学習を行うため、時間が経過するごとに-0.001の報酬を与えます。
public override void OnActionReceived(ActionBuffers actionBuffers)
{
SetReward(-0.001f);
if (isDamage) {
SetReward(1.0f);
EndEpisode();
}
else if (this.transform.localPosition.y < 0)
{
EndEpisode();
}
MoveAgent(actionBuffers.DiscreteActions);
}
ここで、isDamageは初期状態ではfalseになっているbool変数で、エージェントが射出した弾がターゲットと衝突した瞬間にtrueになる設計になっています。
エージェントの全体像
前章までで、エージェントの実装は完了ですが、説明の分かりやすさのために省いた部分も含めエージェントにアタッチするShootingAgentScriptの全体のコードを改めて提示します。
ShootingAgentScript
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;
public class ShootingAgentScript : Agent {
Rigidbody agentRigidbody;
void Start() {
agentRigidbody = GetComponent<Rigidbody>();
}
public Transform target;
public GameObject bullet;
public bool isDamage;
public override void OnEpisodeBegin() {
if (this.transform.localPosition.y < 0) {
this.agentRigidbody.angularVelocity = Vector3.zero;
this.agentRigidbody.velocity = Vector3.zero;
this.transform.localPosition = new Vector3(0, 0.5f, 0);
}
target.localPosition = new Vector3(Random.value * 8 - 4,
0.5f,
Random.value * 8 - 4);
isDamage = false;
}
public void Hit() {
isDamage = true;
}
public override void CollectObservations(VectorSensor sensor) {
sensor.AddObservation(target.localPosition);
sensor.AddObservation(this.transform.localPosition);
sensor.AddObservation(this.transform.forward);
}
public bool ReloadCheck() {
if (GameObject.FindGameObjectWithTag("Bullet")) {
return false;
}
else {
return true;
}
}
public void MoveAgent(ActionSegment<int> act) {
var dirToGo = Vector3.zero;
var rotateDir = Vector3.zero;
var forwardAxis = act[0];
var rightAxis = act[1];
var rotateAxis = act[2];
var shootAction = act[3];
switch (forwardAxis) {
case 1:
dirToGo = new Vector3(0f, 0f, 0.1f);
break;
case 2:
dirToGo = new Vector3(0f, 0f, -0.1f);
break;
}
switch (rightAxis) {
case 1:
dirToGo = new Vector3(0.1f, 0f, 0f);
break;
case 2:
dirToGo = new Vector3(-0.1f, 0f, 0f);
break;
}
switch (rotateAxis) {
case 1:
rotateDir = transform.up * -1f;
break;
case 2:
rotateDir = transform.up * 1f;
break;
}
if (shootAction == 1 && ReloadCheck()) {
GameObject bullets = Instantiate(bullet) as GameObject;
Vector3 force;
force = this.gameObject.transform.forward * 300.0f;
bullets.GetComponent<Rigidbody>().AddForce(force);
bullets.transform.position = this.transform.position;
}
transform.Rotate(rotateDir, Time.deltaTime * 100f);
transform.Translate(dirToGo);
}
public override void OnActionReceived(ActionBuffers actionBuffers) {
SetReward(-0.001f);
if (isDamage) {
SetReward(1.0f);
EndEpisode();
}
else if (this.transform.localPosition.y < 0)
{
EndEpisode();
}
MoveAgent(actionBuffers.DiscreteActions);
}
public override void Heuristic(in ActionBuffers actionsOut) {
var discreteActionsOut = actionsOut.DiscreteActions;
discreteActionsOut.Clear();
if (Input.GetKey(KeyCode.W)) {
discreteActionsOut[0] = 1;
}
if (Input.GetKey(KeyCode.S)) {
discreteActionsOut[0] = 2;
}
if (Input.GetKey(KeyCode.A)) {
discreteActionsOut[2] = 1;
}
if (Input.GetKey(KeyCode.D)) {
discreteActionsOut[2] = 2;
}
if (Input.GetKey(KeyCode.E)) {
discreteActionsOut[1] = 1;
}
if (Input.GetKey(KeyCode.Q)) {
discreteActionsOut[1] = 2;
}
discreteActionsOut[3] = Input.GetKey(KeyCode.Space) ? 1 : 0;
}
}
3. Unityエディター上での設定
最後にShootingAgentのコンポーネントの一部を変更して終了です。
-
TargetオブジェクトとBulletオブジェクトをShootingAgentのShootingAgentScriptのフィールドにドラッグします。 - Add Componentから
Decision Requesterスクリプトを追加し、Decision Periodを10にします。 - さらに、同じようにして
Behavior Parametersスクリプトを追加し、パラメータを下のようにします。-
Behavior Name: Shooting -
Vector Observation > Space Size: 9 -
Vector Action > Space Type: Discrete -
Vector Action > Branches Size: 4 -
Vector Action > Branches Size > Branch 0 Size: 3 -
Vector Action > Branches Size > Branch 1 Size: 3 -
Vector Action > Branches Size > Branch 2 Size: 3 -
Vector Action > Branches Size > Branch 3 Size: 2
-
4. 学習
学習の設定
クローンしたML-Agentsリポジトリの中のconfig/ディレクトリの下に学習の設定(ハイパーパラメータ)を書いたconfig.yamlを作成します。
今回は、PPO (Proximal Policy Optimization) と呼ばれる強化学習手法を用いて学習を行います。
behaviors:
Shooting:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 100000
time_horizon: 64
summary_freq: 1000
学習の実行
ML-Agentsリポジトリに移動し、以下のコマンドを実行します。
mlagents-learn config/config.yaml --run-id=shooting
すると、下のように表示されます。
▄▄▄▓▓▓▓
╓▓▓▓▓▓▓█▓▓▓▓▓
,▄▄▄m▀▀▀' ,▓▓▓▀▓▓▄ ▓▓▓ ▓▓▌
▄▓▓▓▀' ▄▓▓▀ ▓▓▓ ▄▄ ▄▄ ,▄▄ ▄▄▄▄ ,▄▄ ▄▓▓▌▄ ▄▄▄ ,▄▄
▄▓▓▓▀ ▄▓▓▀ ▐▓▓▌ ▓▓▌ ▐▓▓ ▐▓▓▓▀▀▀▓▓▌ ▓▓▓ ▀▓▓▌▀ ^▓▓▌ ╒▓▓▌
▄▓▓▓▓▓▄▄▄▄▄▄▄▄▓▓▓ ▓▀ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▄ ▓▓▌
▀▓▓▓▓▀▀▀▀▀▀▀▀▀▀▓▓▄ ▓▓ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▐▓▓
^█▓▓▓ ▀▓▓▄ ▐▓▓▌ ▓▓▓▓▄▓▓▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▓▄ ▓▓▓▓`
'▀▓▓▓▄ ^▓▓▓ ▓▓▓ └▀▀▀▀ ▀▀ ^▀▀ `▀▀ `▀▀ '▀▀ ▐▓▓▌
▀▀▀▀▓▄▄▄ ▓▓▓▓▓▓, ▓▓▓▓▀
`▀█▓▓▓▓▓▓▓▓▓▌
¬`▀▀▀█▓
Version information:
ml-agents: 0.22.0,
ml-agents-envs: 0.22.0,
Communicator API: 1.2.0,
PyTorch: 1.7.0
2020-12-12 23:47:09 INFO [learn.py:275] run_seed set to 0000
2020-12-12 23:47:10 INFO [environment.py:205] Listening on port 0000. Start training by pressing the Play button in the Unity Editor.
この状態でUnityに戻り、Playボタンを押すと学習が開始されます。学習が始まるとコンソール上には、下のように学習の状況が描画されます。
Shooting. Step: 1000. Time Elapsed: 180.311 s. Mean Reward: 0.356. Std of Reward: 0.492. Training.
Shooting. Step: 2000. Time Elapsed: 325.077 s. Mean Reward: 0.342. Std of Reward: 0.491. Training.
Shooting. Step: 3000. Time Elapsed: 464.584 s. Mean Reward: 0.425. Std of Reward: 0.500. Training.
Shooting. Step: 4000. Time Elapsed: 602.867 s. Mean Reward: 0.349. Std of Reward: 0.490. Training.
Shooting. Step: 5000. Time Elapsed: 746.095 s. Mean Reward: 0.344. Std of Reward: 0.491. Training.
Shooting. Step: 6000. Time Elapsed: 889.383 s. Mean Reward: 0.450. Std of Reward: 0.501. Training.
Shooting. Step: 7000. Time Elapsed: 1026.152 s. Mean Reward: 0.335. Std of Reward: 0.490. Training.
Shooting. Step: 8000. Time Elapsed: 1169.780 s. Mean Reward: 0.454. Std of Reward: 0.504. Training.
Shooting. Step: 9000. Time Elapsed: 1319.780 s. Mean Reward: 0.464. Std of Reward: 0.509. Training.
...
学習の結果
100000ステップまでの報酬を図にすると下図のようになり、試行を重ねるごとにエージェントが取得する報酬の値が大きくなっていることが分かります。
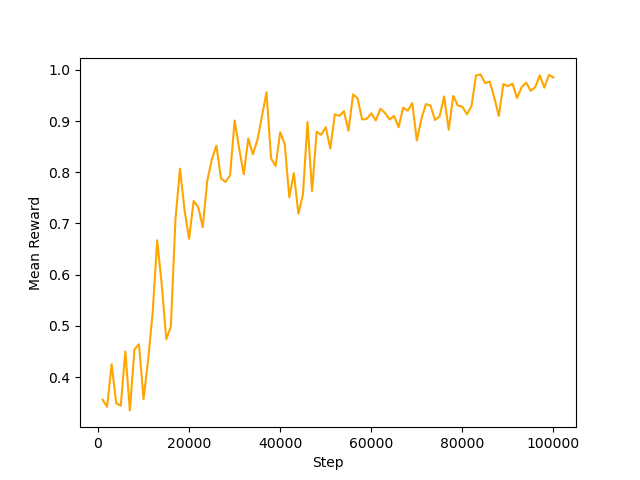
学習を開始してすぐ(1000 step)のエージェントと学習が終わったとき(100000 step)のエージェントの動きを比較してみます。初めのうちはエージェントがフィールドの上をデタラメに動き、ごくたまにターゲットを射撃することができているという状態です(左図)が、学習が進んでくるとなかなかのスピードでターゲットを認識し射撃することができるようになっている(右図)のが分かります。
| 1000 step | 100000 step |
|---|---|
 |
 |
さいごに
今回、ML-Agentsを用いてランダムに出現するターゲットを自動で射撃するエージェントを作ってきました。ML-Agentsの進歩のおかげもあってそこまで苦労することなく(強化学習の深い知識がなくても)ある程度思い通りの学習をすることが可能になってきたので、ゲームの対戦相手やオープンワールを巡回するキャラクターの自動生成、自動運転やロボットのシミュレーションなど様々な用途の中で興味を持ったものに強化学習を応用してみるとよいのではないでしょうか。
参考文献
強化学習の応用例
[1] David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang,
Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen,
Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel, and
Demis Hassabis. “Mastering the game of go without human knowledge”. Nature (2017).
[2] Ahmad El Sallab, Mohammed Abdou, Etienne Perot, Senthil Yogamani. “Deep reinforcement learning framework for autonomous driving”. Autonomous Vehicles and Machines, Electronic Imaging (2017).
[3] Yu Fan Chen, Michael Everett, Miao Liu, Jonathan P. How. “Socially aware motion planning with deep reinforcement learning”. arXiv:1703.08862 (2017).
[4] Nicola De Cao, Thomas Kipf. “MolGAN: An implicit generative model for small molecular graphs”. ICML workshop (2018).
ML-Agents
[5] 「Unity ML-Agents」〔https://unity3d.com/jp/machine-learning〕 (最終検索日 : 2020 年 12 月 13 日)
[6] Arthur Juliani, Vincent-Pierre Berges, Ervin Teng, Andrew Cohen, Jonathan Harper, Chris Elion, Chris Goy, Yuan Gao, Hunter Henry, Marwan Mattar, Danny Lange. “Unity: A General Platform for Intelligent Agents”. arXiv:1809.02627 (2020).
強化学習・模倣学習
[7] J Schulman, F Wolski, P Dhariwal, A Radford and O Klimov. “Proximal Policy Optimization Algorithms”. arXiv:1707.06347 (2017).
[8] Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, Sergey Levine. “actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor”. ICML (2018).
[9] Jonathan Ho, Stefano Ermon. “Generative Adversarial Imitation Learning”. NeurIPS (2016).
[10] Shreyansh Daftry, J Andrew Bagnell, Martial Hebert. “Learning transferable policies for monocular reactive mav control”. ISER (2016).