この記事はOpenCV Advent Calendar 2023の6日目の記事です。
2021年のAdvent Calendarで以下のような投稿をしました。
この投稿は、ある意味続編です🦔
結論
速、、、いや、やっぱ遅いかも(ONNXランタイムと比較して)
※1:CPU推論
※2:モデルによっては速い
バージョン
以下のバージョンで確認しました。
pip show opencv-python
Name: opencv-python
Version: 4.8.1.78
(省略)
pip show onnxruntime
Name: onnxruntime
Version: 1.16.3
(省略)
計測環境
Google Colaboratory上でCPU推論を行い「%%time」や「%%timeit」を使用して推論時間を計測しています。
(本来はもっと厳密な方法と環境で計測すべきでしょうが、、、ご容赦を。。。🙇
参考:CPU情報
!cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU @ 2.20GHz
stepping : 0
microcode : 0xffffffff
cpu MHz : 2199.998
cache size : 56320 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt arat md_clear arch_capabilities
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa mmio_stale_data retbleed
bogomips : 4399.99
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU @ 2.20GHz
stepping : 0
microcode : 0xffffffff
cpu MHz : 2199.998
cache size : 56320 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
apicid : 1
initial apicid : 1
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt arat md_clear arch_capabilities
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa mmio_stale_data retbleed
bogomips : 4399.99
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
ONNXランタイム VS OpenCV DNNモジュール VGG16推論時間比較
CPUで推論した場合、ぼちぼち推論時間がかかるVGG16で比較してみます。
VGG16のONNXモデルは、ONNX Model Zoo の vgg16-7.onnx を使用しました👀
蜂(Bee)の画像で推論してみます。

※ぱくたその画像を使用
以降のスクリプトは、Qiita-AdventCalendar-OpenCV-20231206-01.ipynbをColaboratoryで。
ONNXランタイム
モデルをロードして
import onnxruntime
onnx_session = onnxruntime.InferenceSession('vgg16-7.onnx', providers=['CPUExecutionProvider'])
画像の前処理をして
import cv2 as cv
import numpy as np
# 前処理
input_image = cv.resize(image, dsize=(224, 224))
input_image = cv.cvtColor(input_image, cv.COLOR_BGR2RGB)
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
input_image = (input_image / 255 - mean) / std
input_image = input_image.transpose(2, 0, 1).astype('float32')
input_image = input_image.reshape(-1, 3, 224, 224)
# 入力名・出力名取得
input_name = onnx_session.get_inputs()[0].name
output_name = onnx_session.get_outputs()[0].name
推論時間計測します。
%%timeit -r 7 -n 10
# 時間計測
onnx_session.run([output_name], {input_name: input_image})
実験時は559msと出ました👀
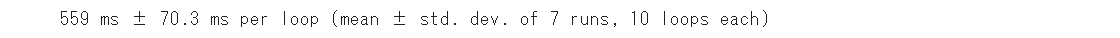
上位5クラスの推論結果を出してみます。
result = np.array(result).squeeze()
print(np.argsort(result)[::-1][:5])

あっていそうですね👀
309:Bee(蜂)
308:fly(蝿)
94:hummingbird(ハチドリ)
95:jacamar(キツツキ目の鳥(キリハシ))
946:cardoon(菊科の植物(カルドン))
OpenCV dnnモジュール
モデルをロードして、バックエンドターゲットをCPUにして
import cv2 as cv
net = cv.dnn.readNet('vgg16-7.onnx')
net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU)
画像の前処理をして
import numpy as np
# 前処理
input_image = cv.resize(image, dsize=(224, 224))
input_image = cv.cvtColor(input_image, cv.COLOR_BGR2RGB)
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
input_image = (input_image / 255 - mean) / std
input_image = input_image.astype('float32')
input_blob = cv.dnn.blobFromImage(input_image)
out_layer_name = net.getUnconnectedOutLayersNames()
# 入力BLOB設定
net.setInput(input_blob, 'data')
推論時間計測します。
%%timeit -r 7 -n 10
# 時間計測
net.forward(out_layer_name)
472msと出ました👀
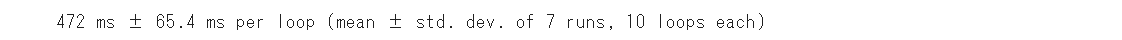
上位5クラスの推論結果を出してみます。
result = np.array(result).squeeze()
print(np.argsort(result)[::-1][:5])

あっていそうですね👀
309:Bee(蜂)
308:fly(蝿)
94:hummingbird(ハチドリ)
95:jacamar(キツツキ目の鳥(キリハシ))
946:cardoon(菊科の植物(カルドン))
ONNXランタイム VS OpenCV dnnモジュール
dnnモジュールでの推論のほうが、速いですね👀
1~2割高速化できるって感じですかね。期待🦔
| モデル | ONNXランタイム | dnnモジュール |
|---|---|---|
| VGG16 | 559ms | 472ms(84.4%) |
Winogradアルゴリズムによる高速化
「OpenCVのDNNモジュールが速いのは、Winogradアルゴリズム(若干の精度低下と引き換えにCNNの乗算回数を減らすアルゴリズム)による高速化がデフォルトで有効化されているから」と小耳にはさみました👀
と言うわけで、Winogradを無効化して試してみます。
net.enableWinograd(False)
%%timeit -r 7 -n 10
# 時間計測
net.forward(out_layer_name)

net.enableWinograd(True)
%%timeit -r 7 -n 10
# 時間計測
net.forward(out_layer_name)

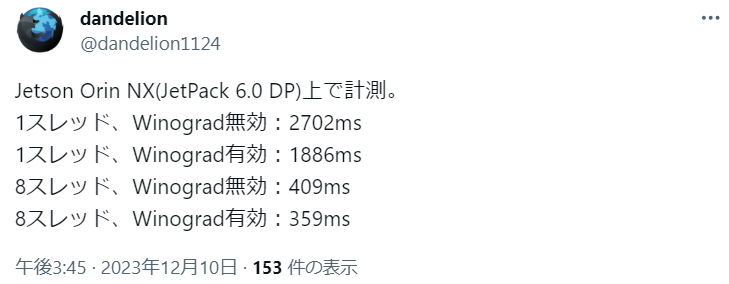
うーん?
APIの使い方間違った🤔?
それとも、バグってる?
要調査。
2023/12/06追記:
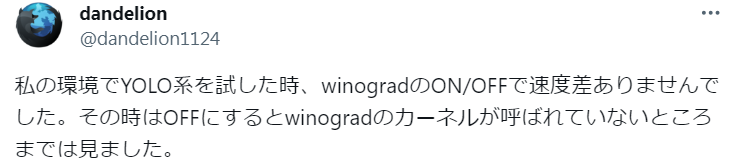
dandelionさんの調査を教えてもらいました🦔
根が深そうな雰囲気が出てきた。。。👀
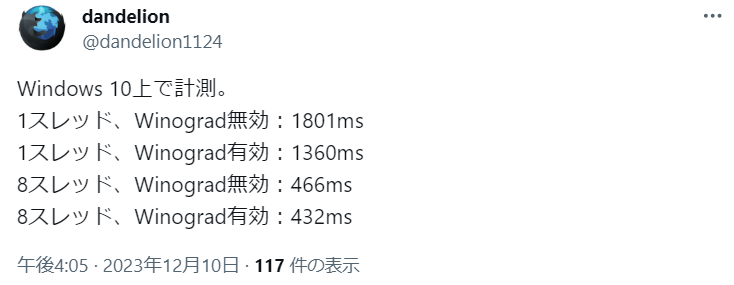
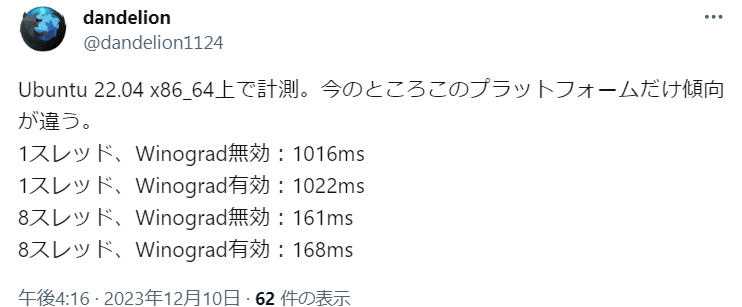
2023/12/10追記:
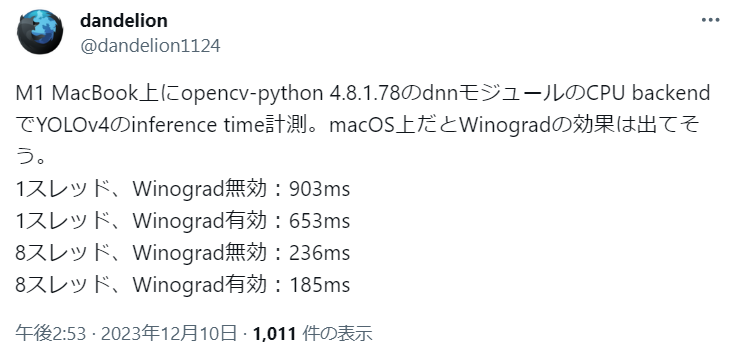
dandelionさんの調査を教えてもらいました🦔
Ubuntuさんどーなってんの😇
ONNXランタイム VS OpenCV DNNモジュール その他いくつかのモデルの推論時間比較
VGG16では期待感ありましたが、、、
他のモデルだと結果がふるわず、、、👀
| モデル | ONNXランタイム | dnnモジュール |
|---|---|---|
| MobileNetV2 | 15.3ms | 29.4ms(192.1%) |
| ResNet50V1 | 124ms | 160ms(129.0%) |
| YOLOv4 | 1.38s | 1.73s(125.4%) |
| YOLOX-S | 521ms | 850ms(163.1%) |
上記の計測に使用したスクリプトは、Qiita-AdventCalendar-OpenCV-20231206-02.ipynbで公開しています。
試したかったけど OpenCV 4.8.1.78 のdnnモジュールで読みこめなかったモデルたち
yolov3-10.onnx
以下のエラーが発生して読み込めず。
error: OpenCV(4.8.1) /io/opencv/modules/dnn/src/onnx/onnx_graph_simplifier.cpp:1257: error: (-210:Unsupported format or combination of formats) Unsupported data type: BOOL in function 'getMatFromTensor'
MaskRCNN-10.onnx
以下のエラーが発生して読み込めず。
error: OpenCV(4.8.1) /io/opencv/modules/dnn/src/onnx/onnx_importer.cpp:1083: error: (-2:Unspecified error) in function 'handleNode'
以上。