データ分析を勉強中です。そんな中、PyCaretが非常に使いやすく感動しています。
最近はチュートリアルを眺めながら、以下を写経してGithubに上げたりしてました。
・クラス分類
・回帰分析
・クラスタリング
・異常検知(教師無し学習)
・自然言語処理
・相関ルールマイニング
表題の件
TitanicでPyCaretのアンサンブル学習を実施してFold数調整で、そこそこなスコア(0.80382)が出たのでメモ。
アンサンブル学習凄いと言うよりは、短く書けてPyCaret凄い。と言うお話です。
分析の序盤は、安易にアンサンブル学習に手を出さず、EDAや特徴量エンジニアリングをしっかりやることが大事だと思うので、本当にメモ程度のお話です。
Notebook
今回の実装のNotebookは、Kaggleの以下ページで公開しています。
https://www.kaggle.com/kazuhito00/pycaret-blend-models-fold-n-titanic-sample
実装の簡単な説明
!pip install pycaret
→pipでPyCaretをインストールしています。この時は最新安定板(1.0.0)をインストールしています。
import os
import random
import numpy as np
import pandas as pd
→PyCaret以外のインポート文です。
def random_seed_initialize(seed=42):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
→乱数シードの初期化用の関数です(PyCaret以外)
random_seed_initialize()
→乱数シードの初期化です。
train_data = pd.read_csv('../input/titanic/train.csv')
test_data = pd.read_csv('../input/titanic/test.csv')
submission_data = pd.read_csv('../input/titanic/gender_submission.csv')
→Titanicの学習データ/訓練データ/提出用雛形の読み込みです。
from pycaret.classification import *
→PyCaretのクラス分類用のインポート文です。
exp = setup(data=train_data, target='Survived',
ignore_features = ['PassengerId', 'Name'], session_id=42)
→学習用データのPyCaret用のセットアップです。
目的変数は'Survived'、Titanicの説明変数は多数の議論と検証がなされていますが、
ひとまず'PassengerId'と'Name'を無視するよう設定しています。
また、session_idを指定しPyCaret内の乱数シードを固定しています。
fold_start_number = 2
fold_end_number = 30 + 1
except_count = 0
for i in range(fold_start_number, fold_end_number, 1):
try:
blend_models(fold=i, verbose=False)
except:
except_count += 1
save_experiment('TitanicBlendModelsExperiment')
experiment = load_experiment('TitanicBlendModelsExperiment')
→fold数を2から30までの間で1刻みでブレンディングを実施しています。
blend_models()はモデルを指定しなければ、PyCaretでサポートしているモデルを
全て使用してブレンディングを行います。
また、後で確認するために実験結果を保存/読み込みしています。
accuracy = []
best_fold_number = 0
best_accuracy = 0
best_model = None
for i in range(fold_end_number - fold_start_number - except_count, 0, -1):
fold_num = len(experiment[-i*2+1]['Accuracy']) - 2
accuracy_mean = experiment[-i*2+1]['Accuracy']['Mean']
model = experiment[-i*2]
if best_accuracy < accuracy_mean:
best_fold_number = fold_num
best_accuracy = accuracy_mean
best_model = model
accuracy.append([fold_num, accuracy_mean])
print('best fold number:' + str(best_fold_number))
print('best accuracy:' + str(best_accuracy))
→実験結果を保持している変数experimentから、Accuracy平均値を確認し、
一番高い数値のaccuracy平均値のモデルを取得しています。
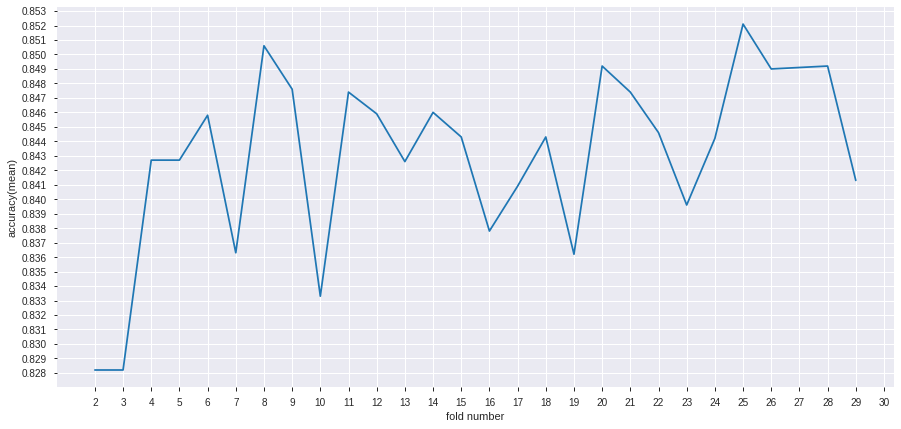
ちなみにKaggle Notebook上での実行結果は、
「best fold number:25」「best accuracy:0.8521」でした。
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(15, 7))
plt.xticks(np.arange(2, 30 + 1, 1))
plt.yticks(np.arange(0.82, 0.86, 0.001))
sns.lineplot(x="fold number", y="accuracy(mean)", data=pd.DataFrame(accuracy, columns=['fold number', 'accuracy(mean)']))
→fold数の違いによるAccuracy平均値を折れ線グラフで確認しています。
predictions = predict_model(best_model, data=test_data)
predictions.head()
→テストデータに対し推論を実行しています。
submission_data['Survived'] = round(predictions['Label']).astype(int)
submission_data.to_csv('submission.csv',index=False)
submission_data.head()
→推論結果を提出用ファイルに書き込んでいます。
これを提出したら0.80382のスコアでした。
以上。