目的
Google Assistant を Windows で動かし、テキスト入力に対してテキストを返すようにします。
デモ

やり方
基本的にはここを参考にするとできます。
公式サイト
Action Console
デバイスの登録・プロジェクトの設定などを行います。
Cloud Platform Console
認証の設定を行います。
Google Cloud を 有効化する必要はありませんが、Goolgle Assistantは有効化する必要があります。
注意点
1 . 会社や大学のアカウントですと、Acitvity Controls Page について、以下の設定ができないことが多いので、個人用アカウントを使うといいです。
Ensure the following toggle switches are enabled (blue):
Web & App Activity
In addition, be sure to select the Include Chrome history and activity from sites, apps, and devices that use Google services checkbox.
Device Information
Voice & Audio Activity
Activity Controls Page
2 . アプリについて
外部に公開し、テストユーザーに自分自身を追加してください。
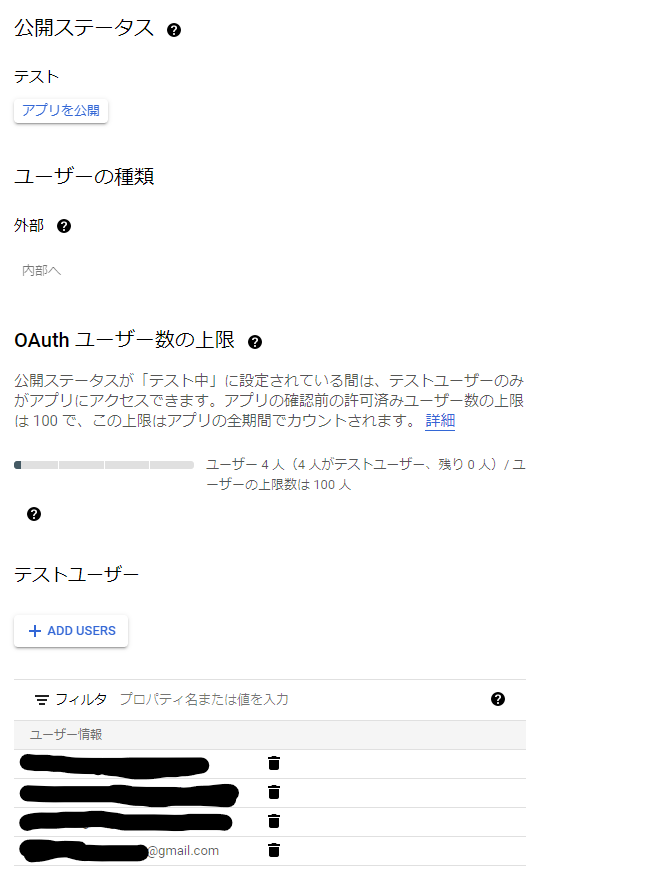
以下の部分のURLの接続部分で、部分で失敗します。
Generate credentials
Install or update the authorization tool:
python -m pip install --upgrade google-auth-oauthlib[tool]
Generate credentials to be able to run the sample code and tools. Reference the JSON file you downloaded in a previous step; you may need to copy it the device. Do not rename this file.
google-oauthlib-tool --scope https://www.googleapis.com/auth/assistant-sdk-prototype
--save --headless --client-secrets /path/to/client_secret_client-id.json
You should see a URL displayed in the terminal:
Please visit this URL to authorize this application: https://...
Copy the URL and paste it into a browser (this can be done on any system). The page will ask you to sign in to your Google account. Sign into the Google account that created the developer project in the previous step.
Note: To use other accounts, first add those accounts to your Actions Console project as Owners.
After you approve the permission request from the API, a code will appear in your browser, such as "4/XXXX". Copy and paste this code into the terminal:
Enter the authorization code:
SDKのインストールからの手順
Google Assistant SDKのインストール
pip install google-assistant-sdk
pip install google-assistant-sdk[samples]
認証Toolのインストール
pip install google-auth-oauthlib
pip install google-auth-oauthlib[tool]
認証
google-oauthlib-tool --scope https://www.googleapis.com/auth/assistant-sdk-prototype --save --headless --client-secrets path/to/client_???.json
テストします
python -m googlesamples.assistant.grpc.audio_helpers
そうすると、エラーが発生します。
AttributeError: 'array.array' object has no attribute 'tostring'
\path\to\python\lib\site-packages\googlesamples\assistant\grpc\audio_helpers.py
の57行目を
arr.tostring() -> arr.tobytes()
に変更します。
Google Assistant SDK のgithub
なぜか
google.assistant.embedded.v1alpha2
が入っていないので、githubからDLしてきて site-packages/google/assistant/embeddedの中に入れます。
text の入力テスト
site-packages/googlesamples/assistantの中にgrpcというフォルダーがあるので、それを丸ごと copyして実行したいフォルダーに置きます。
grpcの中に、以下のファイルを作成します.
# Copyright (C) 2017 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Sample that implements a text client for the Google Assistant Service."""
import os
import logging
import json
import click
import google.auth.transport.grpc
import google.auth.transport.requests
import google.oauth2.credentials
from google.assistant.embedded.v1alpha2 import (
embedded_assistant_pb2,
embedded_assistant_pb2_grpc
)
try:
from . import (
assistant_helpers,
browser_helpers,
)
except (SystemError, ImportError):
import assistant_helpers
import browser_helpers
#設定
ASSISTANT_API_ENDPOINT = 'embeddedassistant.googleapis.com'
DEFAULT_GRPC_DEADLINE = 60 * 3 + 5
PLAYING = embedded_assistant_pb2.ScreenOutConfig.PLAYING
class SampleTextAssistant(object):
"""Sample Assistant that supports text based conversations.
Args:
language_code: language for the conversation.
device_model_id: identifier of the device model.
device_id: identifier of the registered device instance.
display: enable visual display of assistant response.
channel: authorized gRPC channel for connection to the
Google Assistant API.
deadline_sec: gRPC deadline in seconds for Google Assistant API call.
"""
def __init__(self, language_code, device_model_id, device_id,
display, channel, deadline_sec):
self.language_code = language_code
self.device_model_id = device_model_id
self.device_id = device_id
self.conversation_state = None
# Force reset of first conversation.
self.is_new_conversation = True
self.display = display
self.assistant = embedded_assistant_pb2_grpc.EmbeddedAssistantStub(
channel
)
self.deadline = deadline_sec
self.end_query_list = ['は?', 'どこ?', '誰?', 'いつ?', '何?', '何ですか?', 'いつですか?', '誰ですか?', 'どこですか?']
def __enter__(self):
return self
def __exit__(self, etype, e, traceback):
if e:
return False
def assist(self, text_query):
"""Send a text request to the Assistant and playback the response.
"""
def iter_assist_requests():
config = embedded_assistant_pb2.AssistConfig(
audio_out_config=embedded_assistant_pb2.AudioOutConfig(
encoding='LINEAR16',
sample_rate_hertz=16000,
volume_percentage=0,
),
dialog_state_in=embedded_assistant_pb2.DialogStateIn(
language_code=self.language_code,
conversation_state=self.conversation_state,
is_new_conversation=self.is_new_conversation,
),
device_config=embedded_assistant_pb2.DeviceConfig(
device_id=self.device_id,
device_model_id=self.device_model_id,
),
text_query=text_query,
)
# Continue current conversation with later requests.
self.is_new_conversation = False
if self.display:
config.screen_out_config.screen_mode = PLAYING
req = embedded_assistant_pb2.AssistRequest(config=config)
assistant_helpers.log_assist_request_without_audio(req)
yield req
text_response = None
html_response = None
for resp in self.assistant.Assist(iter_assist_requests(),
self.deadline):
assistant_helpers.log_assist_response_without_audio(resp)
if resp.screen_out.data:
html_response = resp.screen_out.data
if resp.dialog_state_out.conversation_state:
conversation_state = resp.dialog_state_out.conversation_state
self.conversation_state = conversation_state
if resp.dialog_state_out.supplemental_display_text:
text_response = resp.dialog_state_out.supplemental_display_text
return text_response, html_response
class TextAssistant():
def __init__(self, device_model_id, device_id):
self.api_endpoint = ASSISTANT_API_ENDPOINT
self.credentials = os.path.join(click.get_app_dir('google-oauthlib-tool'),
'credentials.json')
self.device_model_id = device_model_id
self.device_id = device_id
self.lang = 'ja-JP'
self.verbose = False
#Displayをonにするとresponseが返らない。
self.display = False
self.grpc_deadline = DEFAULT_GRPC_DEADLINE
self.assistant = None
#初期化作業
self.setup()
def setup(self):
# Load OAuth 2.0 credentials.
# logging.basicConfig(level=logging.DEBUG if self.verbose else logging.INFO)
try:
with open(self.credentials, 'r') as f:
credentials = google.oauth2.credentials.Credentials(token=None,
**json.load(f))
http_request = google.auth.transport.requests.Request()
credentials.refresh(http_request)
except Exception as e:
logging.error('Error loading credentials: %s', e)
logging.error('Run google-oauthlib-tool to initialize '
'new OAuth 2.0 credentials.')
return
# Create an authorized gRPC channel.
grpc_channel = google.auth.transport.grpc.secure_authorized_channel(
credentials, http_request, self.api_endpoint)
logging.info('Connecting to %s', self.api_endpoint)
self.assistant = SampleTextAssistant(self.lang, self.device_model_id, self.device_id, self.display,
grpc_channel, self.grpc_deadline)
#無限ループによるチャットを行う.
def prompt_chat(self):
if self.assistant == None:
self.setup()
while True:
query = click.prompt('')
print(f"query {query}")
click.echo('<you> %s' % query)
response_text, response_html = self.assistant.assist(text_query=query)
if self.display and response_html:
system_browser = browser_helpers.system_browser
system_browser.display(response_html)
if response_text:
click.echo('<@assistant> %s' % response_text)
#テキストのQueryによりチャットを行う
def query(self, query_text):
if self.assistant == None:
self.setup()
response_text, response_html = self.assistant.assist(text_query=query_text)
print('<@assistant> %s' % response_text)
return response_text
def assistant_query(self, request):
for end in self.end_query_list:
if request.endswith(end):
return self.query(request)
return None
if __name__ == '__main__':
device_model_id = "maya-test-950fe-maya-assistant-f61sgf"
project_id = "maya-test-950fe"
assistant = TextAssistant(device_id=project_id, device_model_id=device_model_id)
# assistant.prompt_chat()
assistant.query('こんにちは。')
そのあとで、textinput_test.py を実行すると、
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
出るので、
pip uninstall protobuf
pip install protobuf==3.20
を行います。
こうすると...
<@assistant> はい、こんにちは。あなたとご挨拶ができてうれしいです 😃
今日のあなたの気分はいかがですか?
ただ、問題点が...
テキストだといい感じに返してくれない...

これを改良します。
原因は応答に関してはテキストがなく、音声だけがかえって来る場合があります。
なので、音声を記録して、それを whisper で書きおこしを行い、テキストの返しを行います。
whisper
whisperをDLしてきてpythonから使えるようにします。
ffmpegに関してはここから、windowsに対応した最新版のffmpegを入れます。
# Copyright (C) 2017 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Sample that implements a text client for the Google Assistant Service."""
import concurrent.futures
import json
import logging
import os
import os.path
import pathlib2 as pathlib
import sys
import time
import uuid
import click
import google.auth.transport.grpc
import google.auth.transport.requests
import google.oauth2.credentials
import sys
from google.assistant.embedded.v1alpha2 import (
embedded_assistant_pb2,
embedded_assistant_pb2_grpc
)
try:
from . import (
assistant_helpers,
audio_helpers,
browser_helpers,
device_helpers
)
except (SystemError, ImportError):
import assistant_helpers
import audio_helpers
import browser_helpers
import device_helpers
#音声の設定
ASSISTANT_API_ENDPOINT = 'embeddedassistant.googleapis.com'
END_OF_UTTERANCE = embedded_assistant_pb2.AssistResponse.END_OF_UTTERANCE
DIALOG_FOLLOW_ON = embedded_assistant_pb2.DialogStateOut.DIALOG_FOLLOW_ON
CLOSE_MICROPHONE = embedded_assistant_pb2.DialogStateOut.CLOSE_MICROPHONE
PLAYING = embedded_assistant_pb2.ScreenOutConfig.PLAYING
DEFAULT_GRPC_DEADLINE = 60 * 3 + 5
#設定
DEFAULT_GRPC_DEADLINE = 60 * 3 + 5
PLAYING = embedded_assistant_pb2.ScreenOutConfig.OFF
class SampleTextAssistant(object):
"""Sample Assistant that supports text based conversations.
Args:
language_code: language for the conversation.
device_model_id: identifier of the device model.
device_id: identifier of the registered device instance.
display: enable visual display of assistant response.
channel: authorized gRPC channel for connection to the
Google Assistant API.
deadline_sec: gRPC deadline in seconds for Google Assistant API call.
"""
def __init__(self, language_code, device_model_id, device_id,
display, channel, deadline_sec, conversation_stream):
self.language_code = language_code
self.device_model_id = device_model_id
self.device_id = device_id
self.conversation_state = None
# Force reset of first conversation.
self.is_new_conversation = True
self.display = display
self.assistant = embedded_assistant_pb2_grpc.EmbeddedAssistantStub(
channel
)
self.deadline = deadline_sec
self.conversation_stream = conversation_stream
def __enter__(self):
return self
def __exit__(self, etype, e, traceback):
if e:
return False
def assist(self, text_query):
"""Send a text request to the Assistant and playback the response.
"""
def iter_assist_requests():
config = embedded_assistant_pb2.AssistConfig(
audio_out_config=embedded_assistant_pb2.AudioOutConfig(
encoding='LINEAR16',
sample_rate_hertz=16000,
volume_percentage=0,
),
dialog_state_in=embedded_assistant_pb2.DialogStateIn(
language_code=self.language_code,
conversation_state=self.conversation_state,
is_new_conversation=self.is_new_conversation,
),
device_config=embedded_assistant_pb2.DeviceConfig(
device_id=self.device_id,
device_model_id=self.device_model_id,
),
text_query=text_query,
)
# Continue current conversation with later requests.
self.is_new_conversation = False
if self.display:
config.screen_out_config.screen_mode = PLAYING
req = embedded_assistant_pb2.AssistRequest(config=config)
assistant_helpers.log_assist_request_without_audio(req)
yield req
text_response = None
html_response = None
for resp in self.assistant.Assist(iter_assist_requests(),
self.deadline):
assistant_helpers.log_assist_response_without_audio(resp)
if resp.event_type == END_OF_UTTERANCE:
logging.info('End of audio request detected.')
logging.info('Stopping recording.')
# self.conversation_stream.stop_recording()
if resp.speech_results:
logging.info('Transcript of user request: "%s".',
' '.join(r.transcript
for r in resp.speech_results))
if len(resp.audio_out.audio_data) > 0:
# if not self.conversation_stream.playing:
# self.conversation_stream.stop_recording()
# logging.info('Playing assistant response.')
self.conversation_stream.write(resp.audio_out.audio_data)
if resp.dialog_state_out.conversation_state:
conversation_state = resp.dialog_state_out.conversation_state
logging.debug('Updating conversation state.')
self.conversation_state = conversation_state
if resp.dialog_state_out.volume_percentage != 0:
volume_percentage = resp.dialog_state_out.volume_percentage
logging.info('Setting volume to %s%%', volume_percentage)
self.conversation_stream.volume_percentage = volume_percentage
if resp.dialog_state_out.microphone_mode == DIALOG_FOLLOW_ON:
continue_conversation = True
logging.info('Expecting follow-on query from user.')
elif resp.dialog_state_out.microphone_mode == CLOSE_MICROPHONE:
continue_conversation = False
if self.display and resp.screen_out.data:
system_browser = browser_helpers.system_browser
system_browser.display(resp.screen_out.data)
self.conversation_stream._sink.close()
return text_response, html_response
import whisper
import time
class TextAssistant():
def __init__(self, device_model_id, project_id, output_file):
self.api_endpoint = ASSISTANT_API_ENDPOINT
self.credentials = os.path.join(click.get_app_dir('google-oauthlib-tool'), 'credentials.json')
self.project_id = project_id
self.device_model_id = device_model_id
self.device_id = None
self.lang = "ja-JP"
self.device_config = os.path.join(click.get_app_dir('googlesamples-assistant'), 'device_config.json')
self.verbose = False
#Displayをonにするとresponseが返らない。
self.display = False
self.grpc_deadline = DEFAULT_GRPC_DEADLINE
self.assistant = None
self.end_query_list = ['は?', 'どこ?', '誰?', 'いつ?', '何?', '何ですか?', 'いつですか?', '誰ですか?', 'どこですか?']
#初期化作業
self.output_audio_file = os.path.join(os.path.dirname(__file__), output_file)
self.audio_sample_rate = audio_helpers.DEFAULT_AUDIO_SAMPLE_RATE
self.audio_sample_width = audio_helpers.DEFAULT_AUDIO_SAMPLE_WIDTH
self.audio_iter_size = audio_helpers.DEFAULT_AUDIO_ITER_SIZE
self.audio_block_size = audio_helpers.DEFAULT_AUDIO_DEVICE_BLOCK_SIZE
self.audio_flush_size = audio_helpers.DEFAULT_AUDIO_DEVICE_FLUSH_SIZE
self.grpc_deadline =DEFAULT_GRPC_DEADLINE
self.once = True
self.model = whisper.load_model("medium").cuda()
self.setup()
def setup(self):
# Load OAuth 2.0 credentials.
logging.basicConfig(level=logging.DEBUG if self.verbose else logging.INFO)
try:
with open(self.credentials, 'r') as f:
credentials = google.oauth2.credentials.Credentials(token=None,
**json.load(f))
http_request = google.auth.transport.requests.Request()
credentials.refresh(http_request)
except Exception as e:
logging.error('Error loading credentials: %s', e)
logging.error('Run google-oauthlib-tool to initialize '
'new OAuth 2.0 credentials.')
return
if not self.device_id or not self.device_model_id:
try:
with open(self.device_config) as f:
device = json.load(f)
self.device_id = device['id']
self.device_model_id = device['model_id']
logging.info("Using device model %s and device id %s",
self.device_model_id,
self.device_id)
except Exception as e:
logging.warning('Device config not found: %s' % e)
logging.info('Registering device')
if not self.device_model_id:
logging.error('Option --device-model-id required '
'when registering a device instance.')
sys.exit(-1)
if not self.project_id:
logging.error('Option --project-id required '
'when registering a device instance.')
sys.exit(-1)
device_base_url = (
'https://%s/v1alpha2/projects/%s/devices' % (self.api_endpoint,
self.project_id)
)
self.device_id = str(uuid.uuid1())
payload = {
'id': self.device_id,
'model_id': self.device_model_id,
'client_type': 'SDK_SERVICE'
}
session = google.auth.transport.requests.AuthorizedSession(
credentials
)
r = session.post(device_base_url, data=json.dumps(payload))
if r.status_code != 200:
logging.error('Failed to register device: %s', r.text)
sys.exit(-1)
logging.info('Device registered: %s', self.device_id)
pathlib.Path(os.path.dirname(self.device_config)).mkdir(exist_ok=True)
with open(self.device_config, 'w') as f:
json.dump(payload, f)
# Create an authorized gRPC channel.
grpc_channel = google.auth.transport.grpc.secure_authorized_channel(
credentials, http_request, self.api_endpoint)
# self.set_conversation_stream()
self.conversation_stream = None
self.assistant = SampleTextAssistant(self.lang, self.device_model_id, self.device_id, self.display,
grpc_channel, self.grpc_deadline, self.conversation_stream)
def set_conversation_stream(self):
self.audio_sink = audio_helpers.WaveSink(
open(self.output_audio_file, 'wb'),
sample_rate=self.audio_sample_rate,
sample_width=self.audio_sample_width
)
self.conversation_stream = audio_helpers.ConversationStream(
source=None,
sink=self.audio_sink,
iter_size=self.audio_iter_size,
sample_width=self.audio_sample_width,
)
self.assistant.conversation_stream = self.conversation_stream
#無限ループによるチャットを行う.
def assistant_prompt_chat(self):
while True:
query = click.prompt('')
print(f"query {query}")
click.echo('<you> %s' % query)
self.set_conversation_stream()
response_text, response_html = self.assistant.assist(text_query=query)
result = self.model.transcribe(self.output_audio_file, language="Japanese")
if self.display and response_html:
system_browser = browser_helpers.system_browser
system_browser.display(response_html)
if result:
click.echo('<@assistant> %s' % result["text"])
#テキストのQueryによりチャットを行う
def assistant_query(self, request):
self.set_conversation_stream()
self.assistant.assist(text_query=request)
self.assistant.conversation_stream._sink.close()
print(f"output file {self.output_audio_file}")
result = self.model.transcribe(self.output_audio_file, language="Japanese")
return result["text"]
if __name__ == '__main__':
device_model_id = "your device model id"
project_id = "your project id"
assistant = TextAssistant(device_model_id=device_model_id, project_id=project_id, output_file="test.wav")
assistant.prompt_chat()
あとはこれを実行するとデモのようになります。

おまけ
Google Assistantによる音声入力
# Copyright (C) 2017 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Sample that implements a gRPC client for the Google Assistant API."""
import json
import logging
import os
import os.path
import pathlib2 as pathlib
import sys
import uuid
import click
import grpc
import google.auth.transport.grpc
import google.auth.transport.requests
import google.oauth2.credentials
from google.assistant.embedded.v1alpha2 import (
embedded_assistant_pb2,
embedded_assistant_pb2_grpc
)
from tenacity import retry, stop_after_attempt, retry_if_exception
try:
from . import (
assistant_helpers,
audio_helpers,
browser_helpers,
device_helpers
)
except (SystemError, ImportError):
import assistant_helpers
import audio_helpers
import browser_helpers
import device_helpers
ASSISTANT_API_ENDPOINT = 'embeddedassistant.googleapis.com'
END_OF_UTTERANCE = embedded_assistant_pb2.AssistResponse.END_OF_UTTERANCE
DIALOG_FOLLOW_ON = embedded_assistant_pb2.DialogStateOut.DIALOG_FOLLOW_ON
CLOSE_MICROPHONE = embedded_assistant_pb2.DialogStateOut.CLOSE_MICROPHONE
PLAYING = embedded_assistant_pb2.ScreenOutConfig.PLAYING
DEFAULT_GRPC_DEADLINE = 60 * 3 + 5
class SampleAssistant(object):
"""Sample Assistant that supports conversations and device actions.
Args:
device_model_id: identifier of the device model.
device_id: identifier of the registered device instance.
conversation_stream(ConversationStream): audio stream
for recording query and playing back assistant answer.
channel: authorized gRPC channel for connection to the
Google Assistant API.
deadline_sec: gRPC deadline in seconds for Google Assistant API call.
device_handler: callback for device actions.
"""
def __init__(self, language_code, device_model_id, device_id,
conversation_stream, display,
channel, deadline_sec, device_handler):
self.language_code = language_code
self.device_model_id = device_model_id
self.device_id = device_id
self.conversation_stream = conversation_stream
self.display = display
# Opaque blob provided in AssistResponse that,
# when provided in a follow-up AssistRequest,
# gives the Assistant a context marker within the current state
# of the multi-Assist()-RPC "conversation".
# This value, along with MicrophoneMode, supports a more natural
# "conversation" with the Assistant.
self.conversation_state = None
# Force reset of first conversation.
self.is_new_conversation = True
# Create Google Assistant API gRPC client.
self.assistant = embedded_assistant_pb2_grpc.EmbeddedAssistantStub(
channel
)
self.deadline = deadline_sec
self.device_handler = device_handler
self.is_recognized = False
self.recognized_text = ""
def __enter__(self):
return self
def __exit__(self, etype, e, traceback):
if e:
return False
self.conversation_stream.close()
def is_grpc_error_unavailable(e):
is_grpc_error = isinstance(e, grpc.RpcError)
if is_grpc_error and (e.code() == grpc.StatusCode.UNAVAILABLE):
logging.error('grpc unavailable error: %s', e)
return True
return False
@retry(reraise=True, stop=stop_after_attempt(3),
retry=retry_if_exception(is_grpc_error_unavailable))
def assist(self):
self.conversation_stream.start_recording()
logging.info('Recording audio request.')
def iter_log_assist_requests():
for c in self.gen_assist_requests():
assistant_helpers.log_assist_request_without_audio(c)
yield c
logging.debug('Reached end of AssistRequest iteration.')
# This generator yields AssistResponse proto messages
# received from the gRPC Google Assistant API.
for resp in self.assistant.Assist(iter_log_assist_requests(),
self.deadline):
assistant_helpers.log_assist_response_without_audio(resp)
# Userの入力の終了
if resp.event_type == END_OF_UTTERANCE:
logging.info('End of audio request detected.')
logging.info('Stopping recording.')
self.conversation_stream.stop_recording()
# resp.speech_results が音声認識の結果
if resp.speech_results:
logging.info('Transcript of user request: "%s".',
' '.join(r.transcript
for r in resp.speech_results))
#ここで色々と設定.
if ''.join(r.transcript for r in resp.speech_results).strip() != "":
self.is_recognized = True
self.recognized_text = '、'.join(r.transcript for r in resp.speech_results)
return self.is_recognized, self.recognized_text
def gen_assist_requests(self):
"""Yields: AssistRequest messages to send to the API."""
config = embedded_assistant_pb2.AssistConfig(
audio_in_config=embedded_assistant_pb2.AudioInConfig(
encoding='LINEAR16',
sample_rate_hertz=self.conversation_stream.sample_rate,
),
audio_out_config=embedded_assistant_pb2.AudioOutConfig(
encoding='LINEAR16',
sample_rate_hertz=self.conversation_stream.sample_rate,
volume_percentage=self.conversation_stream.volume_percentage,
),
dialog_state_in=embedded_assistant_pb2.DialogStateIn(
language_code=self.language_code,
conversation_state=self.conversation_state,
is_new_conversation=self.is_new_conversation,
),
device_config=embedded_assistant_pb2.DeviceConfig(
device_id=self.device_id,
device_model_id=self.device_model_id,
)
)
if self.display:
config.screen_out_config.screen_mode = PLAYING
# Continue current conversation with later requests.
self.is_new_conversation = False
# The first AssistRequest must contain the AssistConfig
# and no audio data.
yield embedded_assistant_pb2.AssistRequest(config=config)
for data in self.conversation_stream:
# Subsequent requests need audio data, but not config.
yield embedded_assistant_pb2.AssistRequest(audio_in=data)
class GoogleAssistantSpeechRecognition:
def __init__(self, project_id, device_model_id, lang='ja-JP'):
self.api_endpoint = ASSISTANT_API_ENDPOINT
self.credentials = os.path.join(click.get_app_dir('google-oauthlib-tool'), 'credentials.json')
self.project_id = project_id
self.device_model_id = device_model_id
self.device_id = None
self.lang = lang
self.device_config = os.path.join(click.get_app_dir('googlesamples-assistant'), 'device_config.json')
self.display = False
self.verbose = False
self.audio_sample_rate = audio_helpers.DEFAULT_AUDIO_SAMPLE_RATE
self.audio_sample_width = audio_helpers.DEFAULT_AUDIO_SAMPLE_WIDTH
self.audio_iter_size = audio_helpers.DEFAULT_AUDIO_ITER_SIZE
self.audio_block_size = audio_helpers.DEFAULT_AUDIO_DEVICE_BLOCK_SIZE
self.audio_flush_size = audio_helpers.DEFAULT_AUDIO_DEVICE_FLUSH_SIZE
self.grpc_deadline = DEFAULT_GRPC_DEADLINE
self.setup()
def reset(self, lang):
self.lang = lang
self.setup()
def setup(self):
# Setup logging.
logging.basicConfig(level=logging.DEBUG if self.verbose else logging.INFO)
# Load OAuth 2.0 credentials.
try:
with open(self.credentials, 'r') as f:
self.credentials = google.oauth2.credentials.Credentials(token=None,
**json.load(f))
http_request = google.auth.transport.requests.Request()
self.credentials.refresh(http_request)
except Exception as e:
logging.error('Error loading credentials: %s', e)
logging.error('Run google-oauthlib-tool to initialize '
'new OAuth 2.0 credentials.')
sys.exit(-1)
# Create an authorized gRPC channel.
grpc_channel = google.auth.transport.grpc.secure_authorized_channel(
self.credentials, http_request, self.api_endpoint)
logging.info('Connecting to %s', self.api_endpoint)
self.audio_source = audio_helpers.SoundDeviceStream(
sample_rate=self.audio_sample_rate,
sample_width=self.audio_sample_width,
block_size=self.audio_block_size,
flush_size=self.audio_flush_size
)
self.audio_sink = audio_helpers.SoundDeviceStream(
sample_rate=self.audio_sample_rate,
sample_width=self.audio_sample_width,
block_size=self.audio_block_size,
flush_size=self.audio_flush_size
)
# Create conversation stream with the given audio source and sink.
self.conversation_stream = audio_helpers.ConversationStream(
source=self.audio_source,
sink=self.audio_sink,
iter_size=self.audio_iter_size,
sample_width=self.audio_sample_width,
)
if not self.device_id or not self.device_model_id:
try:
with open(self.device_config) as f:
self.device = json.load(f)
self.device_id = self.device['id']
self.device_model_id = self.device['model_id']
logging.info("Using device model %s and device id %s",
self.device_model_id,
self.device_id)
except Exception as e:
logging.warning('Device config not found: %s' % e)
logging.info('Registering device')
if not self.device_model_id:
logging.error('Option --device-model-id required '
'when registering a device instance.')
sys.exit(-1)
if not self.project_id:
logging.error('Option --project-id required '
'when registering a device instance.')
sys.exit(-1)
device_base_url = (
'https://%s/v1alpha2/projects/%s/devices' % (self.api_endpoint,
self.project_id)
)
self.device_id = str(uuid.uuid1())
payload = {
'id': self.device_id,
'model_id': self.device_model_id,
'client_type': 'SDK_SERVICE'
}
session = google.auth.transport.requests.AuthorizedSession(
self.credentials
)
r = session.post(device_base_url, data=json.dumps(payload))
if r.status_code != 200:
logging.error('Failed to register device: %s', r.text)
sys.exit(-1)
logging.info('Device registered: %s', self.device_id)
pathlib.Path(os.path.dirname(self.device_config)).mkdir(exist_ok=True)
with open(self.device_config, 'w') as f:
json.dump(payload, f)
device_handler = device_helpers.DeviceRequestHandler(self.device_id)
self.assistant = SampleAssistant(self.lang, self.device_model_id, self.device_id, self.conversation_stream, self.display, grpc_channel, self.grpc_deadline, device_handler)
def assist(self):
self.assistant.recognized_text = ""
self.assistant.is_recognized = False
return self.assistant.assist()