やりたいこと
「動画データ⇒音声データ抽出⇒自動で文字起こし」をやってみたい。
※細かい設定とか背景とかは置いておいて、
とりあえず試してみたい!というモチベーションでやってます。
色々説明不足な点があるのは悪しからず。
きっかけ
- 社内の有志による活動でAIを使った何かをやりたい
- Teams会議の文字起こしツールを作ってみるかという話に(Teamsにも文字起こし機能はありますが、、、)
- 調べるとGCPの機能だけでできそうな感じだった
⇒やってみよう!
環境
- OS: Ubuntu 20.04.4 LTS
- Python: 3.8.8
やりかた
-
Speech-To-Textを使用する方法
⇒まず最初に思いついた方法。 - Cloud Video Intelligence APIを使用する方法
⇒調べたら動画から直接文字起こしする方法があった、、
今回は「Speech-To-Textを使用する方法」について紹介します。
「Cloud Video Intelligence APIを使用する方法」の記事はこちら 現在記事作成中。
準備
1. GCPのコンソールにログインしてプロジェクトを作成
2. GCSのバケットを作成しておく
※ググったらやり方出てくるので詳細は割愛。
動画の文字起こしをする
手順
- 動画データ(mp4)を音声データ(wav)に変換する
- 音声データをSpeech-To-Textでテキストに変換する
動画データ(mp4)を音声データ(wav)に変換する
ffmpegのインストール
$ sudo apt-get update
$ sudo apt-get -y install ffmpeg
ffmpeg-pythonのインストール
$ pip install ffmpeg-python
動画データ(mp4)を音声データ(wav)に変換
$ python
>>> import ffmpeg
>>> stream = ffmpeg.input("myVideo.mp4")
>>> stream = ffmpeg.output(stream, "myAudio.wav")
>>> ffmpeg.run(stream)
音声データをGCSにアップロード
GCPのコンソール上から簡単にアップロードできる
※もちろんコマンドラインからでも可
↓アップロード成功すると、こんな感じ

いざ、Speech-to-Text
手順
-
Speesh-to-Textの「New Transcription」から新しいTranscriptionを作成
-
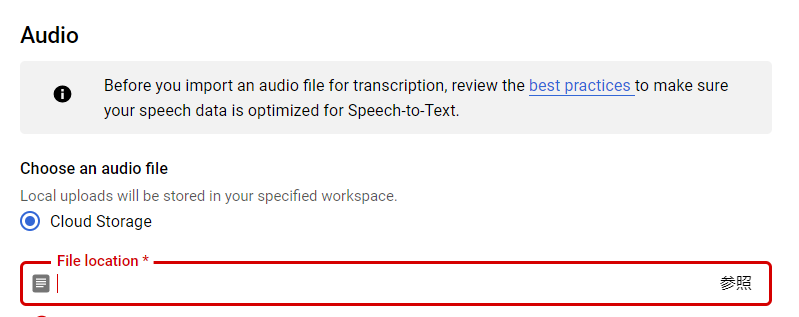
Audio ConfgurationでCloudStorageから音声ファイルを選択
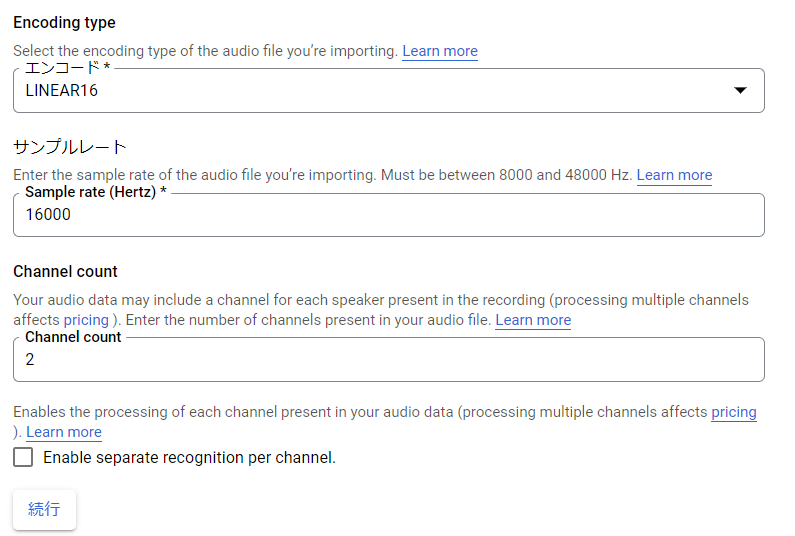
※残りの設定はアップロードしたファイルに合わせて自動で設定される
-
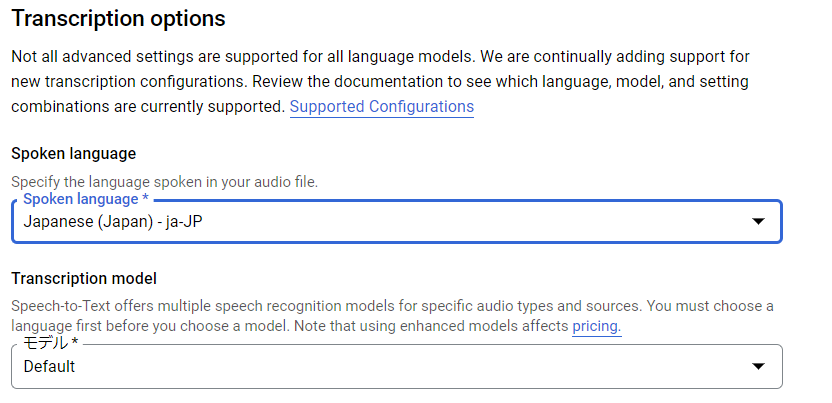
Transcription optionsで言語を選択
-
送信
※Model adaptationは試してないので詳細は割愛

結果
翻訳が終わるとテキストが出力される。CSV形式でDLも可能。
所感
- 機械学習に関する知識はほぼ使わずにできた。
- ちゃんとパイプラインを組めば、動画をアップロードから
テキスト取得までのワークフローも自動化できそう。 - 取得したテキストは正確ではないが何について話しているか何となく把握できるレベル。
※議事禄にするにはまだ精度が足りなそう、、、
参考記事
-
ジコログさんの記事
ffmpegインストールと実行の部分のコードを参考にさせて頂きました。