はじめに
このブログをご覧いただきありがとうございます。
今回はSnowflakeとDataikuのコラボについて、簡単に紹介しています。
最後まで、読んでいただけると嬉しいです。
本ブログの流れ
・Snowflakeの特徴・メリット
・Dataikuの特徴・メリット
・Snowflake・Dataikuのコラボメリット
・まとめ
1.Snowflake
Snowflakeは、単なるDWHを超えてデータシェアリング、マルチクラウドレプリケーションなどを備えたプラットフォームサービスに進化を遂げた「Data Cloud」です。
一般的に、企業のビッグデータ活用に必要なシステム領域は、「データレイク」「データウェアハウス」「データマート」の3点で構成されます。
Snowflakeの data cloud は、この3つすべてをカバーすることが可能です。
特徴
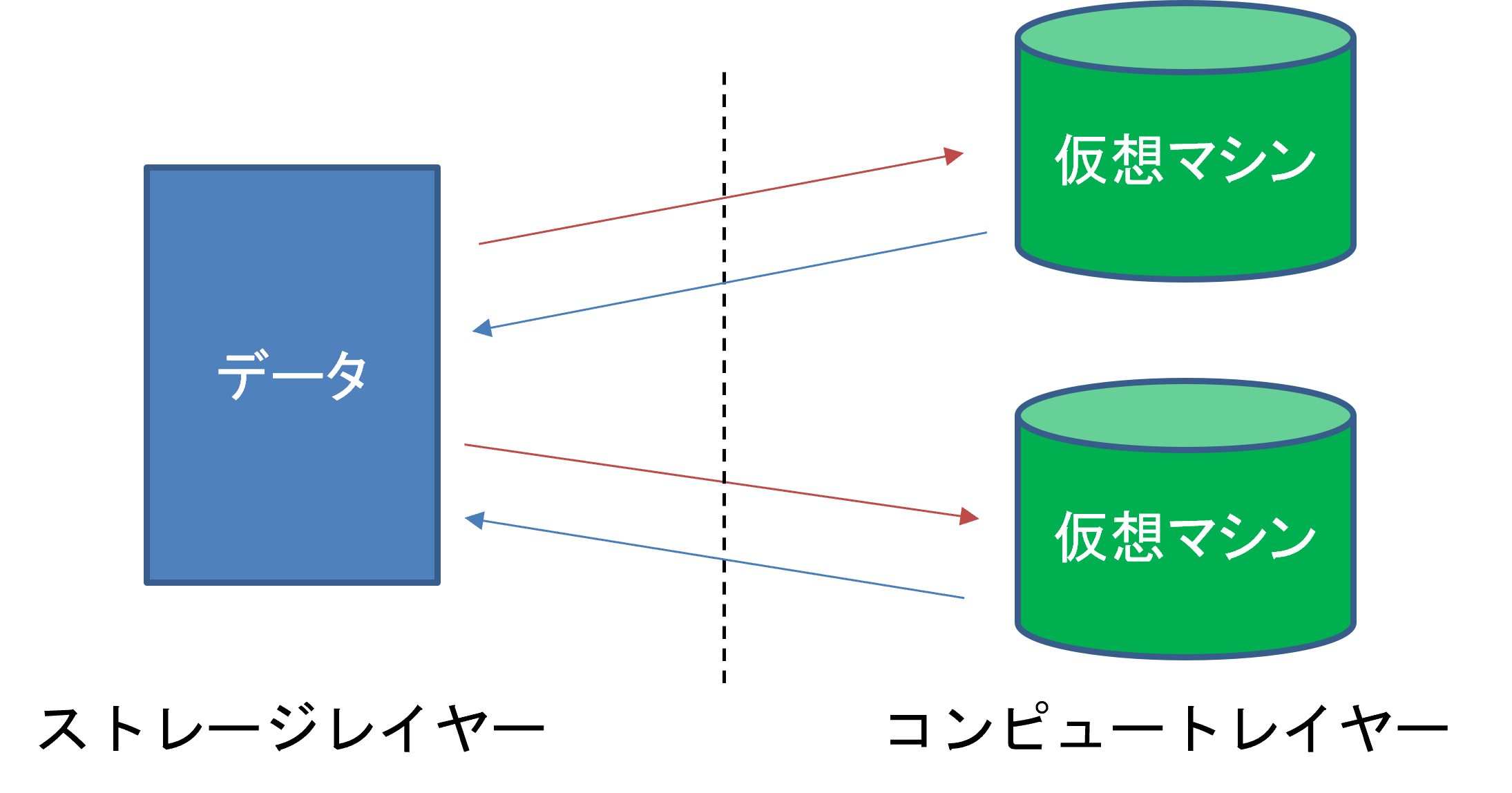
今までDWHはデータの保管やデータを使って加工する処理が1つのレイヤー(層)で管理されていましたが、Snowflakeはデータを保管するストレージレイヤーとデータを使って処理するコンピュートレイヤーが完全に分離しているアーキテクチャとなっているのが大きな特徴になります。
またSnowflakeはコンピュートした分、支払う従量課金制も大きな特徴となっています。
Snowflakeの主な金額は、データのストレージ料金 + ウェアハウスサイズ × 時間 になります。
メリット
Snowflakeのメリットは複数のワークロードで大規模並列処理が可能なことです。
先ほど説明しましたが、Snowflakeはストレージレイヤーとコンピューㇳレイヤーが分離しているのが特徴です。
なので、1つのデータを複数のワークロードで使用することが可能です。
処理する仮想マシンのウェアハウスサイズを容易に変更できるので、適正なサイズを使うことによってコストかつ時間効率の向上につなげることができます。
またSnowflake同士のデータの共有や管理が、とても簡単なのがメリットになります。
2. Dataikuについて
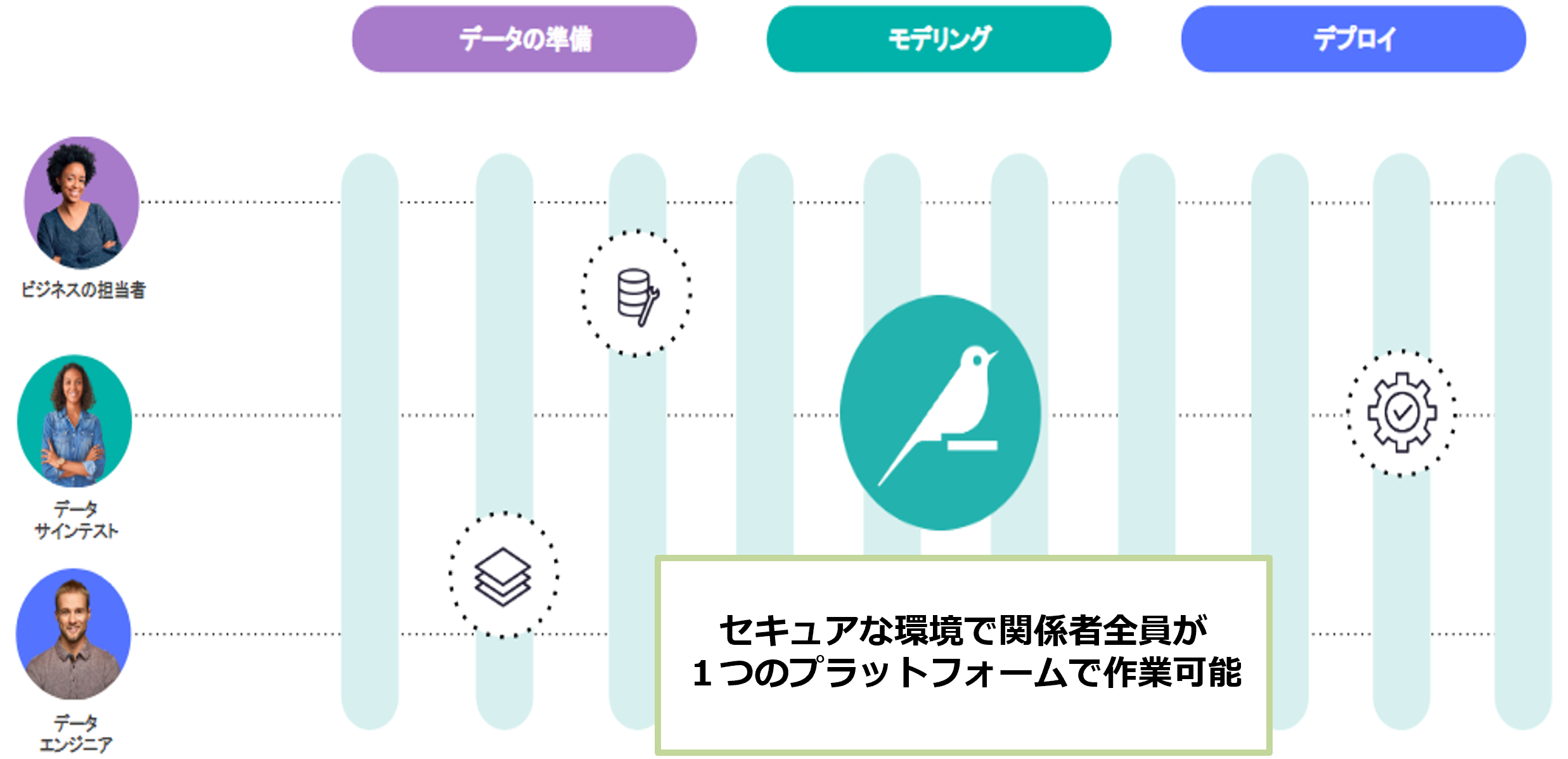
「Dataiku」(データイク)は、データの準備からデータの加工、モデリング(機械学習モデルの作成)、デプロイまでの
全工程を一つのUIでカバーする「データサイエンス・機械学習プラットフォーム」です。
■特徴
Dataikuのコンセプトは、データサイエンティストから初級アナリストまで様々な
メンバーで構成されるデータ分析チームの誰もが扱いやすいコラボレーション
データサイエンスプラットフォームです。
1つのプラットフォームで関係者全員が共同で課題を解決することができ、
データの準備からデータの加工、モデリング(機械学習モデルの作成)、デプロイまでの全工程をブラウザーのGUI操作で作成することができます。
■メリット
メリットは4つあります。
・1点目
データ準備からデプロイといった一連の全工程を1つのツールでカバーしていることです。
・2点目
Dataikuでは細やかな権限管理やすべての操作ログを残すことができるので、安全で効率的なデータ分析ができます。
・3点目
非コーダーはGUI操作で簡単にデータ処理や機械学習モデルを作成することができます。またコーダーは今まで書いてきたプログラムを無駄なく有効利用することができます。
・4点目
Dataikuでは作成したフローを自動で実行する機能や結果をグラフなどで表現するダッシュボード、データ分析を継続的に運用する上で必要な機能を完備していることです。
3. SnowflakeとDataikuのコラボメリット
コラボメリットは2つあります。
・1つ目
1つ目のメリットは、ツール間のデータ転送が不要なことです。
下図は、Dataikuのフローを示します。
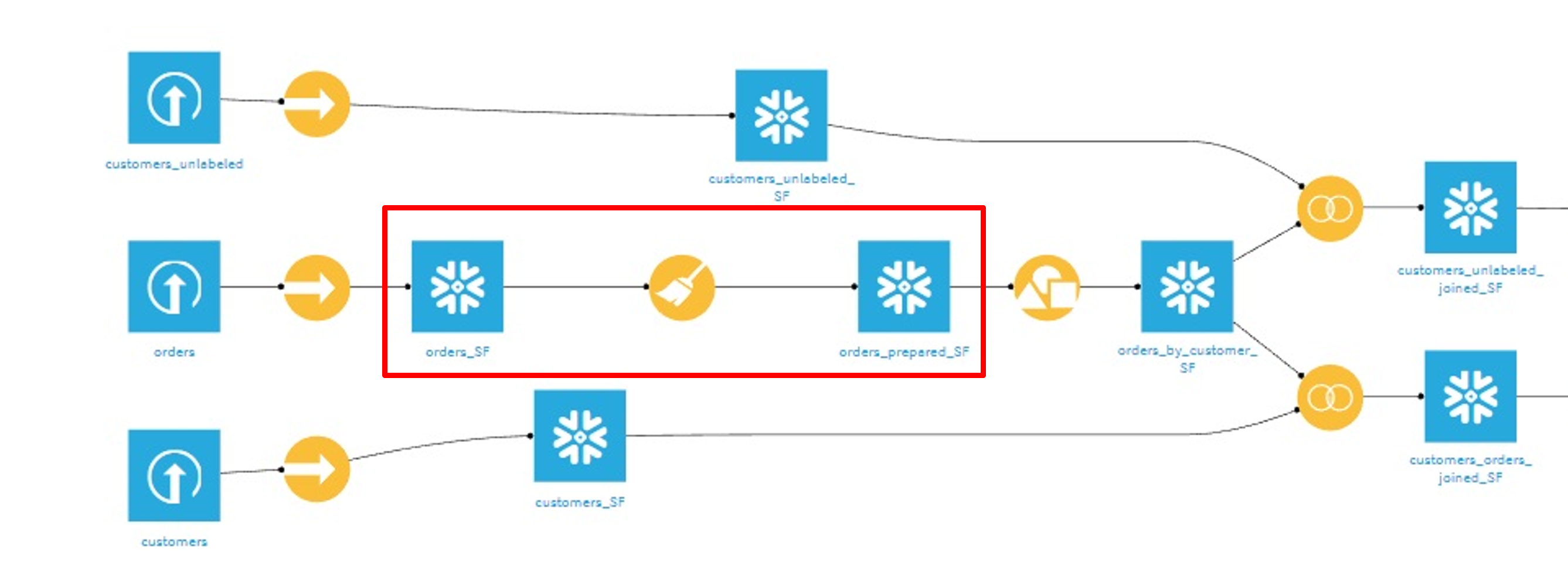
赤い四角で囲まれている部分は、左側のデータセット(orders_SF)を加工して右側のデータセット(orders_prepared_SF)に出力しているフローを表しています。
入力データと出力データが同じデータベースに配置されている場合、データの処理をデータベース・エンジン側で処理をします。
これにより、DataikuとDB間(今回はSnowflake)とのデータ転送が不要になります。
さらにSnowflakeは前章のメリットにもあります、仮想マシンのウェアハウスサイズを変更できることから大量データの処理が得意なサービスでもありますので、大量データ処理の作業効率の向上につなげることができます。
・2つ目
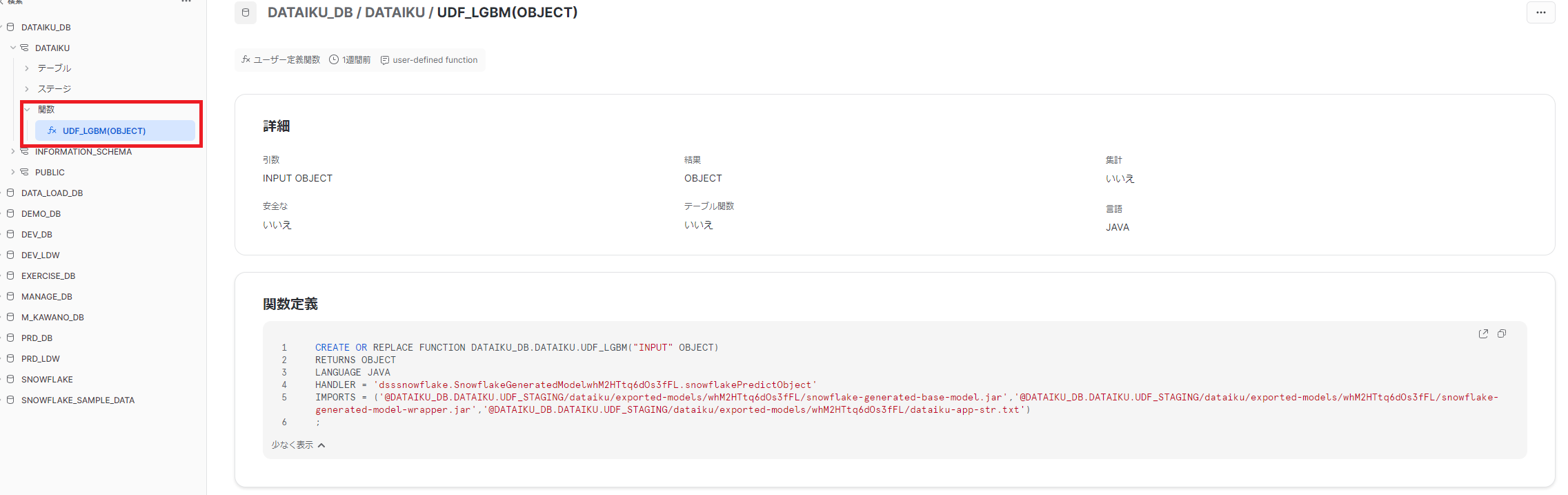
2つ目のメリットは、SnowflakeはDataikuで作成した機械学習モデルをUDFとして実行することができます。
UDFとはUser Define Function の略称でSnowflake側で実行するために必要なユーザ定義関数のことです。
手順として、Dataikuで作成した機械学習モデルをSnowflakeにエクスポートします。
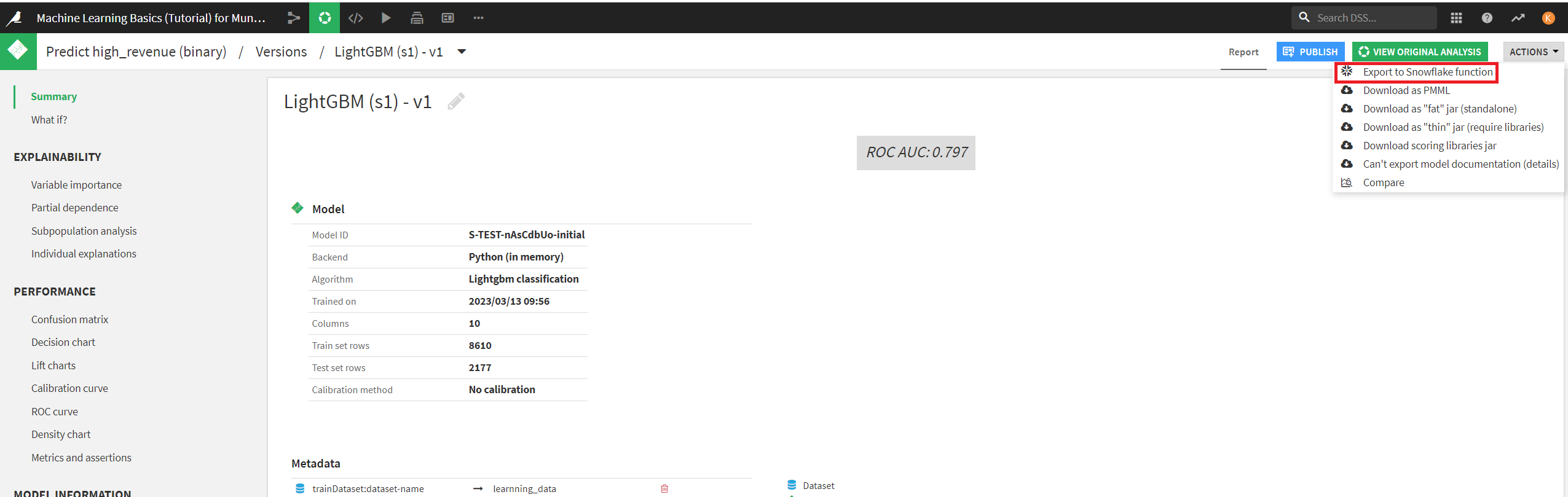
Snowflakeへの接続名とユーザ定義関数名を設定して、エクスポートします。
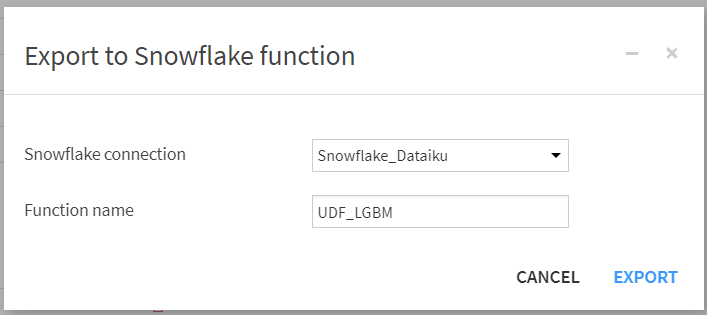
エクスポートに成功しましたら、SnowflakeにUDFが登録されていることを確認します。
確認できましたら、ワークシートにSQL文を書き、登録したUDFを呼び出しテストデータを予測を実行します。下図はSQL文とその結果を表しています。
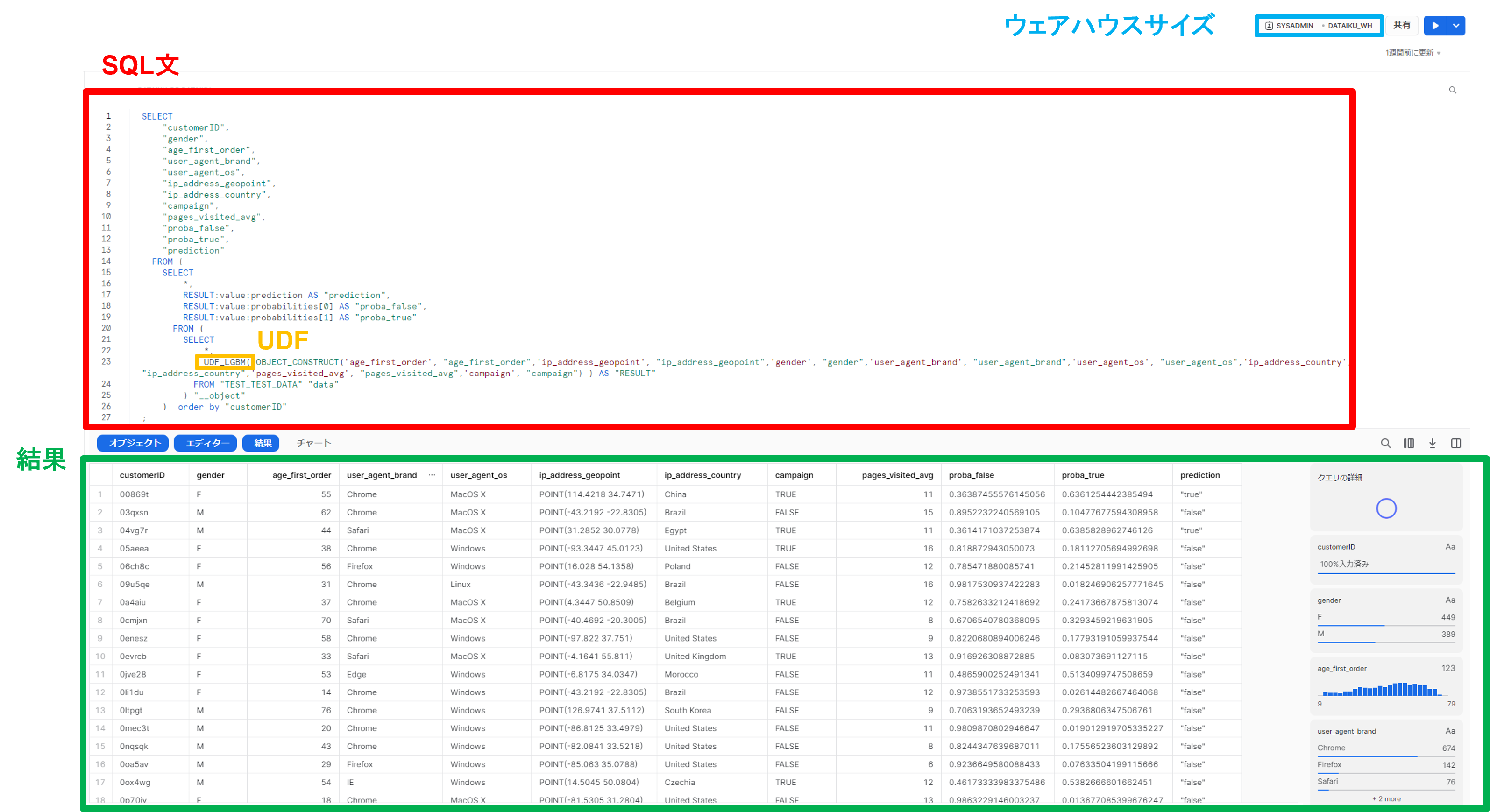
Snowflakeは大量データでの処理が可能なので、データ数によってDataikuを使って機械学習をするのか、Snowflake使い分けるのも1つの手法です!
この章では、DataikuとSnowflakeのコラボメリットについて説明してきました。
4.まとめ
今回は、SnowflakeとDataikuのコラボによって生まれるメリットについてご紹介してきました。
今回の記事をまとめると
・Dataikuはデータ処理をDB(データベース)側のエンジンで実行することができるため、データ間の転送が不要
・SnowflakeではDataikuで作成した機会学習モデルはUDFとして登録することができる。
・登録したUDFを使用し、Snowflake側でSELECT文で推論を実行することができる。
・Snowflakeは最適なストレージと計算リソースを活用できるので、コスト削減と時間効率UPにつながります。
現代、データはとても価値あるモノになってきました。本記事を読んでいただき、少しでも参考になれば嬉しく思います。
本ブログを読んでくださり、ありがとうございました。
Have a good day!