膨大なデータの処理に困ったことありませんか?
はじめに、この度は本ブログを読んでいただき誠にありがとうございます。
よろしければ最後まで読んでみてください。
現在ではデータという存在は必要不可欠な存在になっています。その存在は1日経つ度に大量に生まれてきます。
そんな中、データを扱っている業務の中で以下のような問題に遭遇したことはありませんでしょうか?
・膨大なデータを高速に処理したい
・データ量の加工に時間がかかる
・データ量が多く処理が重い
上記の課題以外にもデータの加工や処理速度の問題に遭遇したことがあると思います。
本ブログは「ある機械学習ツール」を使うと、上記の問題を解決できる方法を紹介したいと思います。
最後までよろしくお願いいたします。
機械学習ツール「Dataiku」
前章を読んでいただいて、ふと疑問が思い浮かんだ方や「あれ?おかしくない?」と思った方もいらっしゃるのではないでしょうか?
・普通、データ加工するならデータベースを使用するのに、どうして機械学習ツールを使うの?
・機械学習ツールで本当に解決できるの?
そう思った方もいると思います。
安心してください!私も最初は思いました👍
ですが、ある機械学習ツールを使用すると上記の問題を解決することができるのです。
ある機械学習ツール、その名は……Dataiku(データイク)です!!!!
聞いたことない人もいると思いますので、簡単に説明したいと思います。
Dataikuとは、データ準備からデータ加工、AutoML(機械学習)、デプロイまでの一連の流れを1つのプラットフォームで行うことができるツールとなります。(Dataikuについて詳しい説明は本ブログ最後にリンクを貼りますので、そちらをクリックしてください。)
今回はDataikuの機能にありますExecution Engines機能、こちらが前章の問題を解決してくれる機能となりますので、次章から説明したいと思います。
Execution Engines機能
まずDataikuは機械学習ツールです。このDataikuは多種多様なデータベース(DB)に接続することができます。

上の図には、一部抜粋してますが、有名なところで言いますとPostgreSQLやMySQL、Oracle、snowflakeにも接続することができます。それ以外にも接続できますが、本目的から離れてしまうので、気になる方はコメント欄で質問してください。
では、この章の題名にも書いてありますExecution Engines機能について説明してきたいと思います。
一言でいうと、接続先のデータベース(DB)側のエンジンでデータ加工を処理してくれる機能となっています。
説明下手すぎない!?!?!?(自分にツッコミ!)
茶番に付き合っていただきありがとうございます。
さてもう少し具体的な例を挙げながら、Execution Engines機能について説明していきたいと思います。
以下の図をご覧ください。今回はデータベースの接続先をsnowflakeに設定しています。
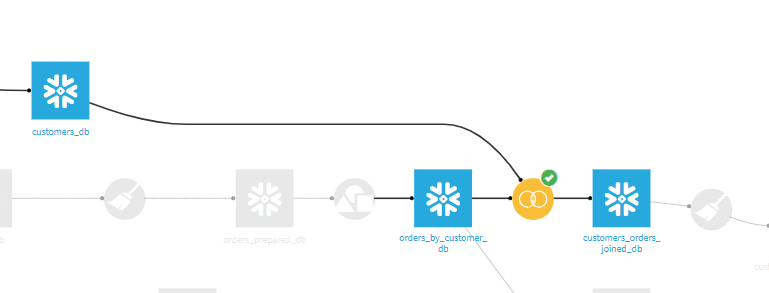
こちらはDataikuのあるプロジェクトのフローの一部を抜粋してあります。Dataikuでは水色の四角がデータセット、黄色い丸はデータセットを加工する処理を表してあります。今回はデータベースの接続先をsnowflakeに設定してありますので、snowflake側にあるデータを読み込んでいます。
今回のフローは2つのデータセットを結合(join)する処理を表しています。結合するデータセットは左上のデータセット「customers_db」と中央のデータセット「orders_by_customer_db」です。2つのデータセットを結合し、データセット「customers_orders_joined_db」を作成しています。
本来の処理は、まずDataikuが処理するために必要なデータセットをsnowflake側から読み込み、Dataiku側のエンジンで加工したい(例:結合、グループ化etc...)処理を行い、処理を終えたらsnowflake側にデータを転送する処理が一般的な流れになります。この流れの場合、膨大なデータ量になるとDataikuとデータベース間の転送する処理が重くなり、多くの時間を要してしまいます。
ここでExecution Engines機能が活躍します。Execution Engines機能は、加工したいデータが同じデータベースだった場合、Dataikuはデータベースにあるデータを読み込みません。データベース(今回だとsnowflake)側のエンジンで加工処理を行い、作成したデータセットをDataikuが読み込みます。
つまり、データ加工するデータセット(上記の図でいうとデータセット「customers_db」、「orders_by_customer_db」)を読み込む処理が不要になります。
このようにデータベース側で処理することでデータベースとDataiku間のデータ転送が発生しないため、膨大なデータを高速に処理することができ、更にDataikuサーバへの負荷を分散することができるため、本ブログの冒頭に書きました問題も解決することができます。
まとめ
今回はDataikuのExecution Engines機能について書きました。このような機能があるため、膨大なデータでも処理速度をあげることができます。
またDataikuはGUI操作でクリックのみで簡単にAutoMLまで作成できる機械学習ツールとなっています。
ご興味を持たれた方・ご質問がある方は、コメント等にて、お気軽にお問い合わせください。
また以下のリンクにDataikuについての内容が記載されてますので興味持った方はクリックしてみてください。
大変長くなりましたが、本ブログを読んでいただき誠にありがとうございました。
Have a good life!!!
過去のブログ
https://qiita.com/KawanoMunekazu/items/5c79fb6942629719c578