CyberAgentLM2とは
2024年6月13日 に株式会社サイバーエージェントから公開された75億パラメータの日本語のVLMである.商用利用可能な画像チャットモデルである.
VLM(大規模視覚言語モデル)とは
画像やテキストから学習できるマルチモーダルモデルとして広く定義されている.画像とテキストの入力を受け取り,テキスト出力を生成する生成モデルの一種である.現在,既存で公開されているVLMは,英語が中心とした学習のため,日本文化の理解や日本語での会話に強いVLMは少ない状況である.
CyberAgentLM2で遊んでみる
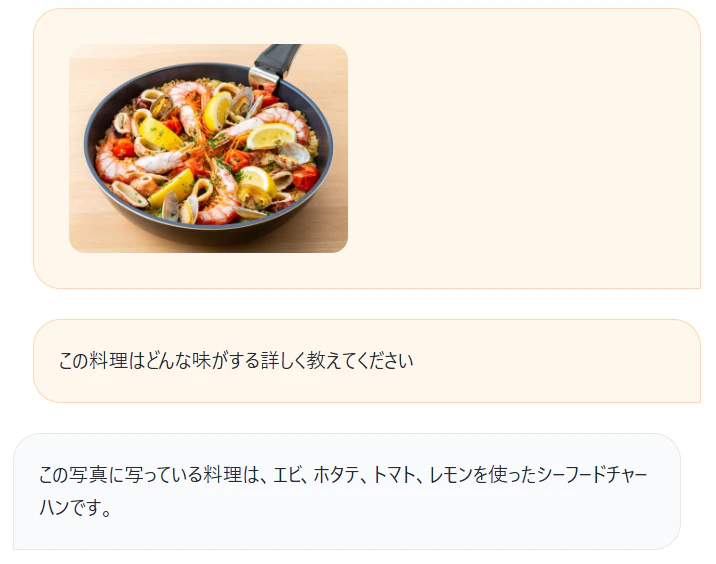
スペイン料理のパエリアの味を詳しく教えてもらう.
中身の食材を判別出来ているが,料理名は,判断できてなさそう.
次に,日本特有である 着物 について説明してもらう.
着物や帯の柄を説明できている.加えて,背景の説明もされている.

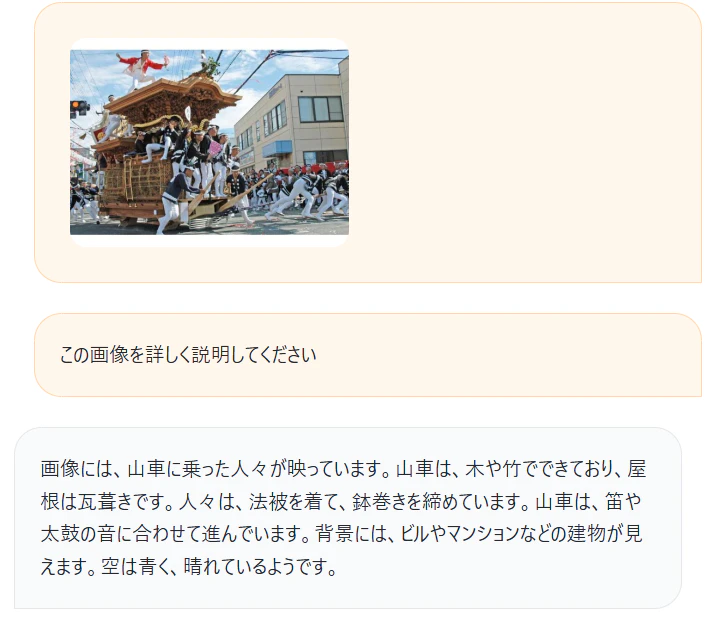
最後に,だんじりについて行ってみる.下の画像を見てわかる通り,だんじりという特定の言葉は説明文に記載されていなかったが,「山車」や「法被」など,日本の文化特有の言葉は,画像から認識することが出来ている.
最後に
今回は,CyberAgentLM2を簡単に取り上げた.今後,もう少し詳しく触って,わかったことがあれば,追記をしたいと思う.今回が,初執筆なので,慣れない部分が多く,読みにくいと感じた方がいるかもしれない.これから,そのようなことがないように工夫を施していきたいと考える.
参考文献
-Vision Language Modelの技術詳細と推論と学習
-Vision Language Models Explained
-独自の日本語LLM「CyberAgentLM2」に視覚を付与したVLM(大規模視覚言語モデル)を一般公開―商用利用可能な画像チャットモデルを提供-