はじめに
PC作業中にどうしてもだんだん頭が下がってしまい姿勢が悪くなってしまうので、
M5StickVで姿勢をチェックする装置を作りました。


M5StickVはニューラルネットワークプロセッサ(KPU)とデュアルコア 64 bit RISC-V CPU搭載したAIカメラです。
これで簡単にエッジコンピューティングができます。
具体的な内容は動画をご参照ください。
姿勢が悪くなってくると、音声とLEDでお知らせしてくれます。
どうしても作業していると姿勢が悪くなってしまうので、音声とLEDで通知してくれるやつを作りました。
— Katsu Shun (@katsushun89) November 18, 2019
悪い姿勢、良い姿勢、離席中の画像を各々保存してMobileNetの転移学習を用いて、悪い姿勢を検出したときに通知してくれるようにしました!
♯M5StickV pic.twitter.com/TjqtM4D1TB
MobileNetの転移学習
学習にはMobileNetの転移学習を用いています。
学習自体はすでにあるものを参考にしただけですが、いくつかやってみてわかったことがあるのでそれを記事にまとめます。
MobileNetの転移学習・StickVで使用可能なkmodelへの変換は、トランジスタ技術の2019年11月号(世界のAIマイコン特集)に記載されていたものをほぼそのまま流用しましたので割愛します。
Google ColaboratoryにデータセットをGoogle Drive経由でアップロードするだけでM5StickVで使用可能なkmodel作成ができて、大変お手軽でした。
またM5StickV公式が出しているV-Trainingという画像データをアップロードするだけでModel作成してくれるサービスでもおそらく同様のことは実現できると思われます。
固定バンパーの3Dプリント
M5StickVをいろいろなところに固定したかったので、ひっかけられるようなバーをつけられるようなケースをモデリングしました。(こちら後で微修正後に公開します。)

(追記)Thingiverseで3Dモデル公開しました。
Thingiverse M5StickV Bumper/Hanger
お遊びでLED前面に姿勢が悪いマーク(猫背アイコン)をつけました。

データ集め
取得したいデータセットのクラスはこの3つです。
- Good Pose:背筋が伸びた良い姿勢
- Bad Pose:背もたれにもたれて頭が下がった姿勢
- Absence:離席中
リピート撮影機能
この3つの画像データを集めるために、M5StickVでリピート撮影機能を用意しました。
コードはこちらです。
10秒おきに撮影した画像をSDカードに保存します。
import sensor
import image
import lcd
import os
import utime
from fpioa_manager import fm
# Button A
fm.register(board_info.BUTTON_A, fm.fpioa.GPIO1)
btn_a = GPIO(GPIO.GPIO1, GPIO.IN, GPIO.PULL_UP)
# LED Blue
fm.register(board_info.LED_B, fm.fpioa.GPIO6)
led_b = GPIO(GPIO.GPIO6, GPIO.OUT)
led_b.value(1)
is_push_btn_a = 0
is_requested_cap = 0
INTERVAL_TIME = 1000 * 10
pre_cap_time = 0
is_enable_rec = False
lcd.init()
lcd.rotation(2)
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.run(1)
path = "save/"
ext = ".jpg"
cnt = 0
image_read = image.Image()
x_pos = 260
y_pos = 170
radius = 10
while True:
current_time = utime.ticks_ms()
img=sensor.snapshot()
if current_time - pre_cap_time > 5:
led_b.value(1)
if current_time - pre_cap_time > INTERVAL_TIME:
pre_cap_time = current_time
if is_enable_rec:
is_requested_cap = 1
#led_b.value(0)
#print(pre_cap_time)
if is_requested_cap == 1 and is_push_btn_a == 0:
print("save image")
cnt += 1
fname = path + str(cnt) + ext
print(fname)
img.save(fname, quality=95)
is_push_btn_a = 1
is_requested_cap = 0
if btn_a.value() == 0 and is_push_btn_a == 0:
print("hoge")
print(is_enable_rec)
is_push_btn_a = 1
is_enable_rec != is_enable_rec
if is_enable_rec:
is_enable_rec = False
print("disable rec")
else:
is_enable_rec = True
print("enable rec")
if btn_a.value() == 1 and is_push_btn_a == 1:
is_push_btn_a = 0
if is_enable_rec == True:
img.draw_circle(x_pos, y_pos, radius, color = (255, 0, 0), thickness = 1, fill = True)
lcd.display(img)
画像データの撮影・確認
正直これが一番時間がかかりました。
自動で繰り返し撮影するので撮りたい位置にセットして、数時間後に確認という流れになります。
なかなか良い分類のデータセットが集まらず、位置の調整を繰り返しました。
悪い姿勢を判別したかったのですが、最初は自身の身体全体が写るような机の上方から画角で撮影しました。
ただ、そうすると、good_pose,bad_poseの誤認識の割合が高くとても使えるものではなかったです。
実際に自分で画像をみてもこれはあまり見分けがつかないなという印象でした。

上方視点(bad_pose)

上方視点(good_pose)

いくつか画像データ例を載せました。よくみるとbad_poseでは背もたれに寄りかかっているのがわかりますが、全体をみるとぱっとみそこまで大きな差があるようにはみえないです。
やはり画像でのClass分けでは人間の目で見ても区別がつきにくいものは分類しづらいようです。(学習モデル作成やパラ調を頑張ればもっといけるかもしれないですが、その辺はノー知識なので勘どころがわからないです。)
そこでその後はカメラの位置を日ごとに下に下げていきました。

 上の位置から撮影した画像データも同様にモデル作成しても評価で明確な差がありませんでした。
上の位置から撮影した画像データも同様にモデル作成しても評価で明確な差がありませんでした。
最終的に落ち着いたポジションがこちらです。
机から10cmほどの高さで、ディスプレイ左横に位置するかたちになりました。

正直この位置ですと、
- good_pose:顔がほぼ写らない
- bad_pose:顔が写る(もしくは顎程度まで写る)
という明確な差があります。
実際の画像データ例がこちらです。
ディスプレイ横視点(bad_pose)

※顔はさすがにモザイクかけましたが逆に怪しくなってしまった気がします(笑)
ディスプレイ横視点(good_pose)
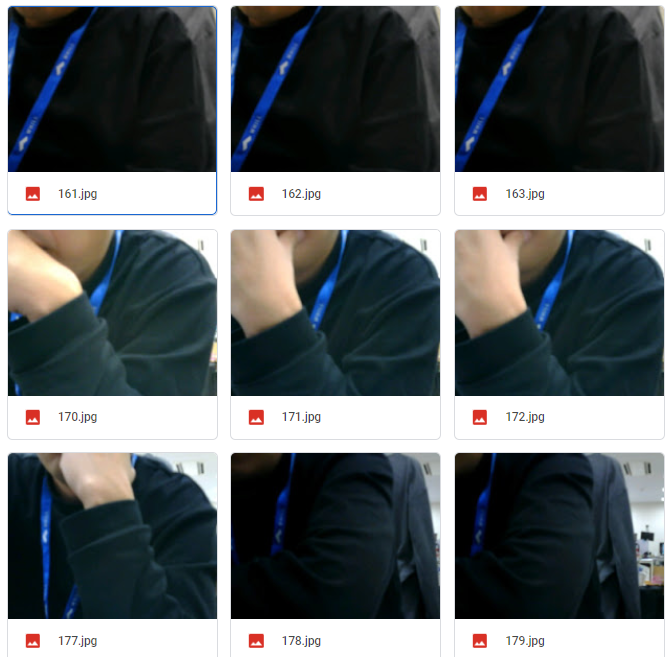
画像をみてもらえばわかるように、上方視点のときと比べるとかなり差が大きいです。
これで学習を走らせて、混同行列(confusion matrix)をみると明確にbad/good_poseで差が出ました。

データセットの画像数は
- Good Pose:315
- Bad Pose:200
- Absence:190
です。10秒間隔で自動撮影した画像なので似た画像が多かったので、データ数はもっと少なくても良いかもしれません。
これでモデル作成完了です。
姿勢の通知
学習したModelが出来ましたので、kmodelに変換したものをM5StickVのSDカードに入れて、
Class分類するpythonのコードを書きます。これも例が出ているのでそれを参考にしました。
また、bad_poseの確率が0.8を超えたらLED:青点灯、10秒連続で検出したら音声再生「姿勢が悪いようです。」と出力するようにしました。
import audio
import sensor
import image
import lcd
import time
import utime
import KPU as kpu
from fpioa_manager import fm
from machine import I2C
from Maix import I2S, GPIO
fm.register(board_info.LED_B, fm.fpioa.GPIO6)
led_b = GPIO(GPIO.GPIO6, GPIO.OUT)
led_b.value(1) #RGBW LEDs are Active Low
i2c = I2C(I2C.I2C0, freq=400000, scl=28, sda=29)
fm.register(board_info.SPK_SD, fm.fpioa.GPIO0)
spk_sd=GPIO(GPIO.GPIO0, GPIO.OUT)
spk_sd.value(1) #Enable the SPK output
fm.register(board_info.SPK_DIN,fm.fpioa.I2S0_OUT_D1)
fm.register(board_info.SPK_BCLK,fm.fpioa.I2S0_SCLK)
fm.register(board_info.SPK_LRCLK,fm.fpioa.I2S0_WS)
wav_dev = I2S(I2S.DEVICE_0)
def play_sound(filename):
try:
player = audio.Audio(path = filename)
player.volume(100)
wav_info = player.play_process(wav_dev)
wav_dev.channel_config(wav_dev.CHANNEL_1, I2S.TRANSMITTER,resolution = I2S.RESOLUTION_16_BIT, align_mode = I2S.STANDARD_MODE)
wav_dev.set_sample_rate(wav_info[1])
while True:
ret = player.play()
if ret == None:
break
elif ret==0:
break
player.finish()
except:
pass
def setup():
img_size = 224 # 上記のセルで IMAGE_SIZE に指定したのと同じ値
lcd.init()
lcd.rotation(2)
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_windowing((img_size, img_size)) #キャプチャの段階でサイズを合わせる
sensor.skip_frames(time = 1000)
sensor.run(1)
setup()
lcd.clear()
lcd.draw_string(0,0,"MobileNet Demo")
lcd.draw_string(0,10,"Loading labels...")
# ラベルファイルの読み込み
f=open('/sd/labels.txt','r')
labels=f.readlines()
f.close()
print(labels)
# kmodelをKPUにロードする
task = kpu.load('/sd/model.kmodel')
clock = time.clock()
print("load model")
keep_cnt = 0
is_noticed = False
while True:
img = sensor.snapshot()
clock.tick()
# カメラから取得した画像に対してkmodelによる推論を実行
fmap = kpu.forward(task, img)
fps=clock.fps()
# 結果の中から一番確率が高い物を取得
plist=fmap[:]
pmax=max(plist)
max_index=plist.index(pmax)
max_label=labels[max_index].strip()
print("%.2f:%s", pmax, max_label)
lcd.display(img)
if 1 == max_index and pmax > 0.8:
led_b.value(0)
keep_cnt += 1
if keep_cnt > 10 : keep_cnt = 10
else:
led_b.value(1)
keep_cnt = 0
is_noticed = False
print(keep_cnt)
if keep_cnt >= 10 and is_noticed == False:
is_noticed = True
play_sound("/sd/voice/notice_bad_pose.wav")
kpu.deinit(task)
結果は冒頭のTwitter動画の通りです。
気づいたこと
初めて自分でモデル作成して、クラス分類してみました。まだ推論試して1日程度ですが、いくつか気づいたことを箇条書きします。
- 服装が違っても認識してくれました。意外とGrayscaleに変換しないとダメかなと思ってましたが、データセット:黒い服、推論時:薄い青いシャツでも問題なく認識してくれました
- 場所(学習時:会社の自席、推論時:自宅)でも認識してくれました。背もたれの高さも色も若干違いますし、背景はかなり違いますがそれでも問題なかったです
- データセット作ったときは「悪い姿勢=顔がある」という結局顔認識しているだけではという気がしていましたが、案外顔がすべて入っていなくても(顎や口程度が写っていれば)正しく分類されました。(これも動画参照)
さいごに
最初に、ぶら下げるカバーを作ったり、繰り返し画像撮影できるコードを作ったので、これがあれば他にも分類したいものを見分けるアプリケーションが簡単に作れそうです。
機械学習の知識が一切なくてもここまで出来るのはとても便利ですし、何よりM5StickVはあの大きさで単体でエッジコンピューティング出来るので、カメラがネットにつながって情報漏洩が心配という人も安心して使えるのが何気に良いところだなと思いました。
あとはデータセットが明確に区別できるような画角をどう見つけるかが肝だと感じました。
そこが見つけられたら後はデータを取って学習させるだけです。
皆さんも身近なものを分類してみてください!