はじめに
今話題のオープンデータですが、必ずしもCSVなどの生データではない事で、微妙に扱いにくいデータに仕上がっている事があります。
保有しているデータを新たに出している事自体は当然褒められるべき事で、「ほんとだったら生データ欲しいなァ〜」くらいの気持ちで期待している訳ですね。
そんな訳で、PDFで出したから悪いわけではありません、が、データの活用に際しては、PDFではなくより機械で読みやすい形式にする必要があります。
今回は、札幌市交通局が公開した朝ラッシュ時間帯の車内混雑状況についてのPDFデータを題材に、CSVデータを錬成する手順を紹介してみます。
方針
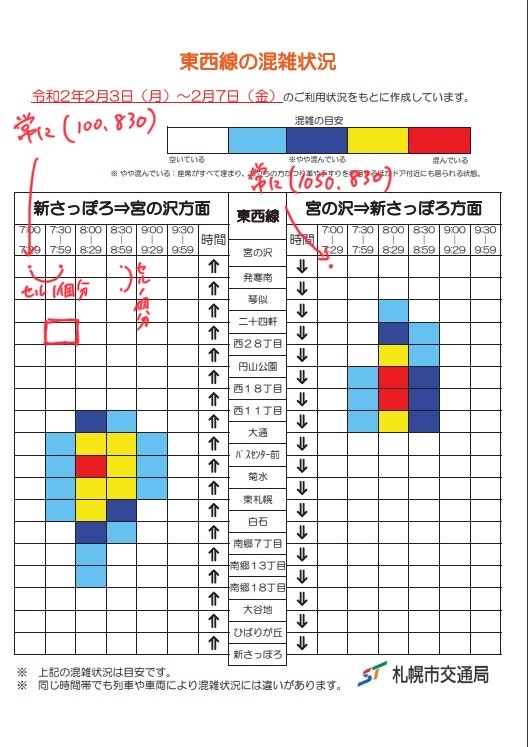
上記ウェブサイトで得られるPDFファイルはこのような書式です

一応データは構造化されていて、エクセルをPDF出力した感じです。
なので「構造から解析路線」が思い浮かびます、が、表に格納されている日本語が解析時に化けてしまうなど手間がかかりそうでした。
そんな訳で次に、以下の画像のような手順を考案。
画像処理ソフト使うのが面倒だったのでiPadで手書きです。
要は、いくつかPDFを見ると、左表も右表も、左上のセルは常に同じ位置にあって、セルのサイズも全部同じという事がわかった訳です。
ならば、画像で言う赤点の箇所のRGB値(=色)を抽出・混雑度データに変換してやれば、望みのデータとなる訳ですね。
結論
こんな風に実装できました
https://github.com/Kanahiro/sapporo_subway_analyze/
こんな風にCSVを出力します

赤いとこは4、白は0で青は2になっている事がわかりますね。
では、PDF読み込み→画像に変換→指定ピクセルの色を取得→色から当該セルの混雑度データを生成→CSVファイルに、という手順を追ってみます。
PDFから画像に変換
参考:PythonのPDF処理まとめ(結合・分割, 画像変換, パスワード解除)
pdf2imageを利用します。使い方は上記記事を参照。
なお、記事ではpip install popplerとありますが、現在はpipではインストール出来ません。
Linuxなら以下です。他のOSの説明は省略します。
sudo apt install poppler-utils
画像から指定ピクセルのRGB値を取得
pdf2imageで読み込んだデータは、numpyのarrayに変換する事が出来ます。
つまり、ピクセル構造と一致した2次元配列に、RGB配列を突っ込んで、3次元配列となります。
# convert_from_pathはpdf2imageの関数
pdf_images = convert_from_path(pdffile)
img_array = np.asarray(pdf_images[0])
'''
img_arrayのサンプル
[[[255 255 255]
[255 255 255]
[255 255 255]
...
[255 255 255]
[255 255 255]
[255 255 255]]
[[255 255 255]
[255 255 255]
[255 255 255]
...
[255 255 255]
[255 255 255]
[255 255 255]]
[[255 255 255]
[255 255 255]
[255 255 255]
...
[255 255 255]
[255 255 255]
[255 255 255]]
(中略)
...
[[255 255 255]
[255 255 255]
[255 255 255]
...
[255 255 255]
[255 255 255]
[255 255 255]]
[[255 255 255]
[255 255 255]
[255 255 255]
...
[255 255 255]
[255 255 255]
[255 255 255]]
[[255 255 255]
[255 255 255]
[255 255 255]
...
[255 255 255]
[255 255 255]
[255 255 255]]]
PDFの端っこは白いので当たり前ですが[255 255 255]すなわち白ばかりですね。
ピクセル単位に配列に格納出来ました。
特定ピクセル(data_of_pixel)へのアクセスは
x = START_CELL[0] + c * CELL_SIZE[0] #x座標
y = START_CELL[1] + r * CELL_SIZE[1] #y座標
data_of_pixel = img_array[y][x]
となります。これで、PDFを変換した画像の、特定の箇所のRGB値を取得出来ました。
混雑度の判定
上記の画像から、白、水色、青、黄色、赤の順で混雑度が高い事を示す事がわかります。
ところが、右上の凡例とデータエリアで、若干RGB値が異なるPDFに仕上がっていました。
幸い、段階ごとにそれなりに色の違いが大きいので、ここは凡例とデータエリアのセルとのRGB値の差の大きさで判定したいと思います。
# 混雑度凡例のRGB値
CROWD_RGBs = [
[255, 255, 255],
[112, 200, 241],
[57, 83, 164],
[246, 235, 20],
[237, 32, 36]
]
def rgb_to_type(rgb_list)->int:
#色差の閾値
threshold = 50
color_array = np.asarray(rgb_list)
for i in range(len(CROWD_RGBs)):
crowd_rgb_array = np.asarray(CROWD_RGBs[i])
color_dist = abs(color_array - crowd_rgb_array)
sum_dist = color_dist.sum()
if sum_dist < threshold:
return i #0 - 4 混み具合
この関数にRGB値のlistを渡すと、混雑度を0-4の整数値で返します。
何をしているかというと、先ほど取得したピクセルのRGB値と、混雑度凡例のRGB値を比較しています。
RGB値それぞれの差の絶対値の総和を色差と定義し、その差が50以内の場合、混雑度を確定しています。
これで、すべてのセルの混雑度を判定し、CSVにすれば冒頭のCSVデータが完成します。
終わりに
こういった処理はオープンデータ界隈ならあるあるネタなんでしょう。「餅から米をつくる」とおっしゃっていた方もいましたが、これで私も錬米術師を名乗ってもよいでしょうか?ただやはり、一次データ(餅)がない限り米の錬成は出来ない訳なんで、そこには感謝しかない訳です、いつもありがとうございます。データの量は増えてきたので、次はそのデータの質の段階になっていくのかな…。