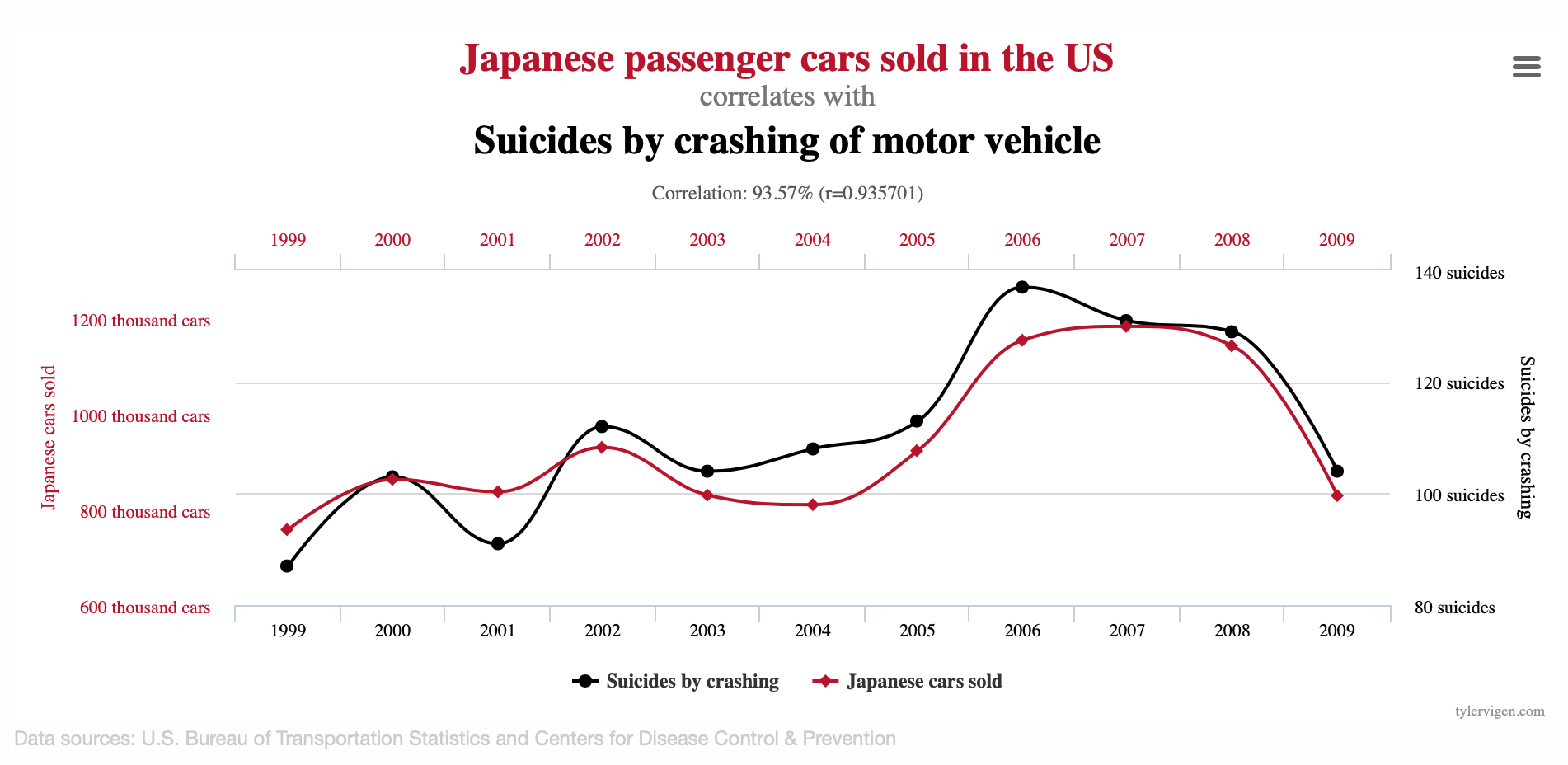
先週に引き続いて、今週も「A Second Chance to Get Causal Inference Right: A Classification of Data Science Tasks」という予測と因果推論の違いを説明し、今こそ「因果推論」というものをもっと多くの人に正しく広めようとするエッセイからの紹介です。
前回は、データサイエンスのタスクを、記述、予測、因果推論(反事実的予測)という3つのカテゴリーに分け、それぞれの定義的な違いの話をしました。
今回はより具体的に、予測と因果推論は何が違うのかというのを、機械と人間、もっと正確に言うと、自動化できるかどうか(機械)、人間によるドメイン知識を必要とする(人間)かどうか、といった点から解説しています。
以下、要訳。
予測と因果推論の違い
データサイエンスはビジネスのアプリケーションを得意とします。ショッピングや映画のレコメンデーション、クレジット・スコアの評価、株の売買のアルゴリズム、広告の配信などといったものがあります。
データサイエンティストの中には彼らのスキルをバイオ医療のアプリケーションとともにサイエンスの研究分野に持ち込んだりもしています。Googleの糖尿病の診断のためのアルゴリズムなどがいい例です。
こうしたアプリケーションには一つの共通したことがあります。それらはすべて予測であって、因果関係ではないということです。それは単にインプット(人間の網膜のイメージ)をアウトプット(網膜症の診断)に結びつけているに過ぎないのです。
こうした予測のアプリケーションは、もし違うアクションを取っていたら世の中がどうなっていたのだろうか、ということはまったく気にしません。例えば、もし網膜の手術をしたらその診断結果が変わったのかどうかといったことです。
予測のためのタスクは自動化できる
観察されたインプットと観察されたアウトプットをマッピングする(結びつける)のは自動化されたデータ分析と相性がいいです。なぜならこうしたタスクは、次のものを必要とするからです。
- インプットとアウトプットを持った大きなデータ・セット
- インプットとアウトプットを結びつけるアルゴリズム
- 結びつきがうまく言ってるかどうかを評価するための指標
こうしたものが揃えば、予測のタスクはデータドリブンなアナリティクスとして自動化され、インプットとアウトプットのマッピングは人間が介入することなしにどんどんと改善されていきます。
より正確には、予測のタスクのうちの簡単に自動化できる部分というのは、ドメイン知識を必要としないものなのです。
もちろん予測の中にも、ドメイン知識を必要とするようなタスクはあります。何をインプットとして何をアウトプットとするのかといったサイエンス的な質問を定義したり、必要なデータソースを見つけたり、もしくはデータを生成したりするときなどです。
しかしインプットとアウトプットの候補が決まり、予測の精度を計測できるようになれば、後はドメイン知識を必要としません。なぜなら、この段階では、機械学習のアルゴリズムが勝手にマッピングを行い、それを評価するために計測された数値を分析していくことができるからです。
こうした結果作られたマッピングの仕組みは人間の目には見えないかもしれません。多くの深層学習のアプリケーションがそうであるように。
予測 vs. 因果推論 - ドメイン知識の役割についての違い
ドメイン知識が果たす役割こそが、予測と因果推論の間の決定的な違いになります。因果推論のタスクは質問を定義し(どの処方がどういう結果をだすかという因果の影響)、必要なデータソースを特定するためだけでなく、研究の対象であるシステムの中にある構造的な因果関係を説明するためにも必要になります。
因果に関する知識は、たいていの場合は証明することができない仮説という形をとりますが、データ分析を行うためのガイドラインとして必要で、因果関係に関する解釈のための数値による推定結果を判断するために必要となるのです。
言い換えると、因果推論の結果が正しいかどうかは、データから得られる情報を補完するという形で、多くの場合不完全な人間の知識にかかっているというわけです。
結果として、観察データをもとに因果推論の正確さを数値化できるようなアルゴリズムというのはない、ということになるのです。
ドメイン(業務)に関する専門的な知識が果たす役割が予測と因果推論においてどう違うのかを、例を使ってもう少し具体的に見ていってみましょう。
具体的な例:乳児の死亡の予測と原因
健康に関する大量のデータを使って生まれて間もない赤ちゃんが死ぬかどうかをアウトプットとして予測したいとしましょう。この場合、妊娠中のお母さんから得られた生体的な属性と生活スタイルに関する属性がインプットとなります。
私達はドメイン知識を使って何がアウトプットで何がインプットの候補かということを決め、さらに興味の対象に関するある特定のデータを選びました。データに関する唯一の要件は候補となるインプットはアウトプットよりも時間的に先にわかっているような情報である必要があるということです。
ここまでくれば、後は私達にはドメイン知識はもう必要ありません。アルゴリズムがインプットとアウトプットのマッピングを勝手に行ってくれます。そしてそれは私達人間が行うであろうマッピングよりもはるかにうまくやってくれるのです。
それでは、ここで、おなじ健康に関するデータを使って妊娠中の母親がタバコを吸っていることが赤ちゃんの死亡の原因になるかどうかを知りたいとします。
ここで重要な問題は「交絡」というものです。妊娠中にタバコを吸っていた母親と、吸っていなかった母親は多くの属性に関してばらばらです。例えばアルコールの消費量、食べていたもの、妊娠中に適した治療や診断を受けることができていたかどうか、など。そして、こうしたことは赤ちゃんの死亡率に影響を与えます。
それゆえ、因果に関する分析をするには、妊娠中の喫煙と赤ちゃんの死亡率の両方に相関するような、つまり「交絡」する属性を見つけ、調整することが必要となります。
しかし、妊娠中の喫煙と赤ちゃんの死亡率の両方に相関する全ての属性が調整の必要な交絡因子といわけではありません。
例えば、生まれた時の体重は妊娠中の喫煙と赤ちゃんの死亡率の両方と強い相関をもっていますが、生まれた時の体重を調整するとバイアスを作ってしまいます。なぜなら体重は妊娠中の喫煙によって因果的に影響するリスク要因であるからです。
生まれた時の体重を調整することで、よく言われる「生まれた時の体重パラドックス(birthweight paradox)」というバイアスを作ってしまうことになります。それは、妊娠中に喫煙してた母親から生まれてきた体重の軽い赤ちゃんの方が、喫煙してなかった母親から生まれてきた赤ちゃんよりも死亡率が低いという現象です。
因果に関するドメイン知識を持たないアルゴリズムはデータの中にある相関関係にのみ頼ることになります。そのことで、例えば体重などのように、どの属性を選ぶかによってバイアスを作り出してしまう可能性があるのです。
「生まれた時の体重パラドックス」現象というのは、自動的な調整が因果関係に関する間違った結論を導き出してしまうといういい例です。
対照的に、ドメイン知識を持った人間の専門家は、多くの変数(例えば体重のような)は調整されるべきでないと判断できます。なぜならそれらが因果関係の構造のなかでどういう立場であるかを理解しているからです。
人間の専門家はどの属性が調整されるべきか(たとえそれらがデータの中になかったとしても)を判断することができるので、そうした属性がデータの中にない時でも、因果推論の信頼性を評価するために感度分析を提案することができます。
逆に因果的な構造を無視するアルゴリズムは、そうした調整すべき属性がデータの中になかった場合、何か特別な警告を出すことはないのです。
因果関係に関する仮説を実証するためのランダム化比較試験
因果推論において因果に関するドメイン知識が果たす大きな役割を考えれば、研究者が、因果の知識に頼るような因果推論を使わなくてもいい手法を採用としようとするのは驚くべきことではありません。
ランダム化比較試験はそうした時に用いられるベストな方法です。研究対象のシステムについての詳細な因果関係に関する知識がないときに、治療 (Treatment) をランダムに割り当てられた患者に対して与えることで、治療を受けたグループの平均的な因果による影響の推定値を、バイアス無しで求めることができるのです。
商用ウェブ・アプリケーションの世界では、ランダム化比較試験はシンプルな因果に関する質問に答えるために、A/Bテストという名前のもとによく使われています。
しかし、サイエンティストによる研究対象である健康や社会といった、大変複雑なシステムの場合、ランダム化比較試験を行うことは可能でなかったり、行うに十分な時間がなかったり、そもそも道徳的な問題があってできなかったりするということは多々あります。
予測と因果推論に関する混乱
予測と因果推論において、専門のドメイン知識が果たす異なる役割を正しく理解しないことによって、データサイエンスの世界では多くの混乱が生じています。
回帰などの予測分析の手法が、因果に関する知識といっしょに使うことで因果推論にも使われるということが、こうした混乱をいっそうひどくします。
予測と因果推論の両方とも、サイエンス的な質問を構築するために専門のドメイン知識を必要とします。しかし、因果推論のみがそうした質問に答えるために因果に関してのドメイン知識を必要とするのです。
結果として、因果関係に関する推定が正しいかどうかというのは、データから出される指標を使って評価することができません。たとえ、興味の対象を完全に計測することができたとしてもです。
要訳、終わり。
あとがき
よくデータ分析に関する話の中で、相関関係と因果関係は違うという話が出てきます。(はい、私もよくします。)
しかし、これはもっともな話なのですが、それでも大きな問題があります。
それは、データをもとに意思決定を行おうとしている人が本当に知りたいことは因果関係だ、というジレンマです。
なので、データを分析した人が、データから得られたインサイトが相関関係に関するものだと言い張ってしまっても、そこから意思決定を行いたいと思っている人と平行線をたどるだけとなってしまいます。
そこで相関関係と因果関係は違う、因果関係を発見または確認するのは難しい、と言って止まるのではなく、むしろ因果関係に迫っていくための仮説を構築していく努力をし続けるべきだと思います。
そのために、「手っ取り早い」のが本文の中にもあったランダム化比較試験、または俗に言うA/Bテストなわけです。A/Bテストを行うというのは、優柔不断だからではなく、その前にデータをもとに(いつもそうとは限りません)因果関係に関する仮説を構築してあって、それが正しいのかどうかを検証するために行っているわけですね。
ただ、本文でも述べられていましたが、ソフトウェアをベースにしたアプリケーションの場合と違って、実際にはA/Bテストが簡単に行えない場合というのも多々あります。
そんなときには、諦めるのではなく、逆にデータとデドメイン知識の両方を組み合わせることで、より洗練された因果関係に迫っていくための仮説を構築していくことができるのです。業務やビジネスに関するドメイン知識があることで、どの変数を選択すべき(または選択すべきでない)かについてのよりよい判断ができますし、どのデータを調整すればいいのか、どういった関係を分析すればいいのかといった事に関する判断もしやすくなります。
これこそが、データサイエンス、特に意思決定のためのデータサイエンス(ディシジョン・サイエンス)にはドメイン知識が必要だとよく言われる所以で、私が日頃からビジネス側の人間こそがデータを分析できるようになるべきで、専門家に放り投げてしまってはいけないと主張し続けている理由でもあります。
意思決定には、因果関係の理解が必要で、データを使って因果関係を理解するためには、ドメイン知識が必要になるわけで、ゆえに、ビジネスの業務をふだん行っている人間こそが価値のあるデータ分析を行ういう点では有利であるはずなのです。
機械学習の自動化というのは昔からよく言われていることですが、結局人間の介在しないようなデータ分析というのは、すでに出すべき答えがわかっている場合に、どうやってそうした機械的な作業を最適化することができるかという話に行き着きます。
しかし、実世界のビジネスの世界では、行うべきことが決まっていたり、打つべき施策がわかっているという場合はまずありませんし、予測すれば終わりと言った単純な場合もなかなかありません。
そこで、結局は人間による、ある意味泥臭いデータ分析を行っていくということになります。しかし逆に考えれば、意思決定のためのデータサイエンス、またはデータ分析というのは、この先も自動化されていくということはないと言えるわけです。
さらに機械的な仕事よりも、クリエイティビティを含め人間的な要素をより要求される仕事なのですから、実際は泥臭い仕事というよりは、子供の行うような泥んこ遊びに近いようなもっとエキサイティングな仕事だと言えるのではないでしょうか?(笑)
データサイエンス・ブートキャンプ、7月開催!
次回のデータサイエンス・ブートキャンプは7月です!
ビジネスを成長させるためにはデータを使って因果関係に関する仮説を構築し、実験するというサイクルを効率的に回していく必要があります。そしてそのためには統計学を含むデータサイエンスの手法を習得する必要があります。
最終的にビジネスの現場で意思決定を行うためにどうデータを使うのかという視点でどんどんと進化させていっている「データサイエンス・ブートキャンプ」ですが、次回は7月、その次は11月です。
ぜひ「データ・インフォームド」な意思決定を行いたい方、統計を基礎からしっかりと学びたいという人は参加してみてください。
詳細はこちらのページにあります。