今回は「A Second Chance to Get Causal Inference Right: A Classification of Data Science Tasks」という相関関係(記事の中では「予測」)と因果関係の違い、それぞれのタスクで使われるアナリティクスのタイプの違いを解説し、今こそ「因果推論」というものをもっと多くの人に正しく広めようとするエッセイが最近出ていたので、ここで紹介したいと思います。
長いので、今回は前半部分です。また来週に後半を紹介します。
以下、要訳。
A Second Chance to Get Causal Inference Right: A Classification of Data Science Tasks - Link
20世紀の始めに、モダン統計学の創始者たちは、データから何がわかって、そしてわからないかに関しての重要な判断を下しました。それは、統計学の手法を使って因果関係を推論することができるが、それはランダム化比較実験をした上で、「実験データ」を使うことによってのみ可能だというものです。
もちろん多くのサイエンティスト(科学者)達はこの統計学者達の評決を無視し、「観察データ(過去データ、私達が一般的に手にするタイプのデータのことです。)」を使って医療における治療による副作用、ライフスタイルのアクティビティによる健康に対する影響、教育政策がもたらす社会的なインパクトなどを研究し続けました。
残念なことに、こうしたサイエンティストたちは、彼らの因果関係に関する質問に答えるための統計学の知識やスキルを持っていなかったのです。
そうして、因果関係に関する質問を解決することに対して1世紀にも渡って拒否し続けてきたために、今日でさえ、サイエンスの研究分野のいたるところに混乱が見られます。
サイエンスとデータ分析に橋をかけるために、統計学者、疫学者、計量経済学者、コンピュータ・サイエンティストたちは、「観察データ」から因果関係による影響量を計測するための公式な手法を開発しました。
最初はそれぞれの分野は違った因果関係に関する質問を強調し、異なった用語を作り、異なったデータ分析の手法を好みました。しかし21世紀の始まりまでには、いくつかのコンセプトにおける違いは残ったものの、定量的な因果推論の統一された理論が出来上がったのです。
データサイエンスのタスクの分類
データサイエンティストはよく彼らの仕事を、データから「インサイトを得る」または「意味を抽出する」と定義します。
こうした定義はデータサイエンスのサイエンス的な使用に関してあまりにもあいまいです。データが提供することができる「インサイト」や「意味」に関して、正確にカテゴリ分けをすることで、そのために必要となるデータ、仮定、アナリティクスのタイプに関してよりシステム的に考えていくことができるはずです。
そこでデータサイエンスのサイエンス的な貢献を3つのタスクにまとめると、それは「記述」、「予測」、「反事実的な予測」ということになります。
「記述」はデータを使って世の中のある特徴に関する定量的なサマリ情報を提供します。「記述」のタスクとは、例えば大量のヘルスケアのデータから糖尿病の患者の割合を計算したりすることです。「記述」のタスクで使われるアナリティクスは、基礎的な計算(平均や割合)から教師なしの学習アルゴリズム(クラスタリングなど)といった高度な手法やデータの可視化などが含まれます。
「予測」は、データを使って世の中のある特徴(インプット)と世の中の別の特徴(アウトプット)をマッピング(結びつける)することです。
「予測」はシンプルなタスク(例えば、患者が入院する時のアルブミンのレベルと集中治療室にいる患者が一週間以内に死ぬことの関連性を数値化すること)から始まり、入院時に計測された何百もの変数を使ってどの患者が一週間以内に死ぬのかを予測するといったもっと複雑なものへと進んでいきます。
「予測」のタスクに使われるアナリティクスは基礎的な計算(相関係数、リスク差など)から高度なパターン認識の手法や、分類に使われる教師あり学習のアルゴリズム(ランダムフォレスト、ニューラルネットワークなど)、または多変量の同時確率分布といったものまであります。
訳者注:アルブミンとは動植物の細胞・体液などに含まれる一群の可溶性タンパク質の総称のこと。
「反事実的な予測」はデータを使って、世の中のある特徴を予測するのですが、それは世の中が今とは違っていたかもしれないということを考慮した上での予測です。ここでは因果関係を推論していくことが必要になります。
例えば、もし観察対象の人たちの全員が大腸がんの検査を受けた場合、もしくはそうでなかった場合の死亡率を推定しようとするものです。
因果推論のタスクに使われるアナリティクスはランダム化比較実験のような基礎的なものから、治療 - 交絡因子のフィードバックを持った観察研究におけるg-methodsの実装と言った複雑なものまであります。
以上の3つ全てのタスクに「統計的な推論」が必要とされます。例えば、対象とする母集団からサンプルされたデータをもとにしているのであれば95%信頼区間の情報が欲しいと思うかもしれません。
カテゴリー分けしようとする時によくあることですが、以上の3つのタイプの違いはいつもはっきりしているとは限りません。しかし、こうした3つのタイプに分けることで、データサイエンスにおけるそれぞれのタスクを成功させるために必要となる、データの要件、仮定、そしてアナリティクスに関する議論を進めやすくなります。
サイエンスとはそもそも質問によって定義されるものであり、彼らが使うツールによって定義されるわけではありません。天体物理学は星の構成を学ぶ学問であって、スペクトロスコープ(分光器)を使う学問ではありません。同じように、データサイエンスとは記述、予測、そして因果推論(半事実的な予測)の専門分野であり、機械学習のアルゴリズムや他の技術的なツールを使うことを目的とする専門分野ではありません。
もちろん、データの獲得、保存、統合、アクセス、処理のために開発されたツールや、スケールできて並列で処理できるようなアナリティクスの進歩からデータサイエンスは恩恵を受けています。データサイエンスがサイエンス的なタスクを行っていく上でこうしたデータエンジニアリングは欠かせない力となっているのです。
あとがき
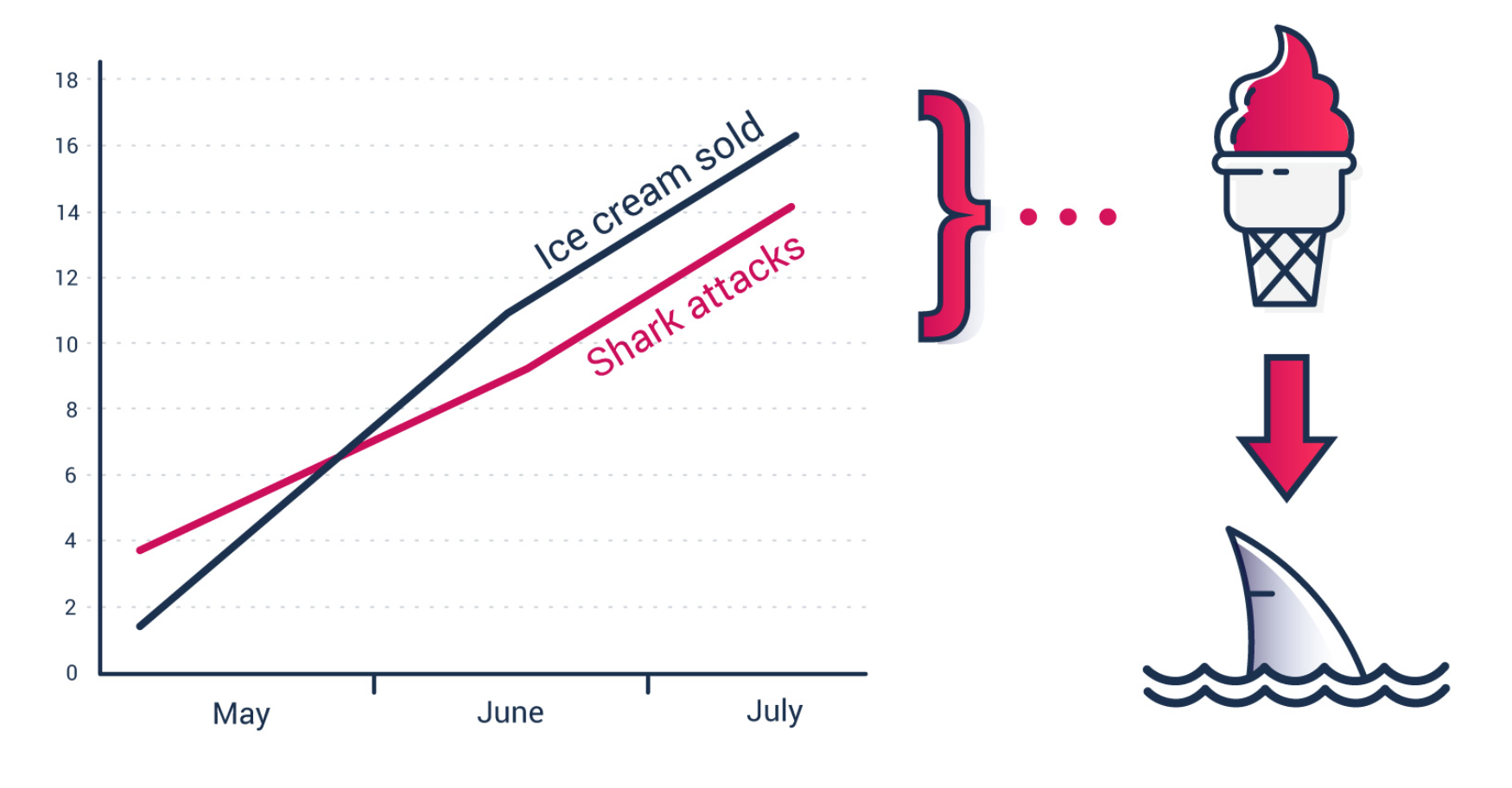
これまでにも私のブログ記事やメルマガ「Weekly Update」でもよく取り上げてきましたが、相関関係と因果関係は似ていますが実は違うものです。
例えばEコマースのサイトがあったとして、顧客がウェブサイトで費やしている時間と顧客が費やすお金の総額に相関関係があるという場合を考えてみましょう。より多くの時間を費やせば、より多くのお金を費やしてくれるといった関係です。
この時、この関係は今のところ相関関係であるということが分かっていると言うだけで、因果関係であるということは分かっていません。つまり、長い時間を費やすことが、多くのお金を費やしてくれることの原因であると言えるかどうかはまだ分かっていません。
というのも、ひょっとしたら長い時間を費やしている顧客はある特定のタイプの商品を買おうとしているのかもしれず、そうした商品を買うプロセスには時間がかかっているだけなのかもしれません。
もしそうであれば、本当の因果関係というのはある特定の商品、つまり単価の高い商品を買うということが顧客が費やすお金の総額の原因になっているという、ある意味当たり前のことであった、みたいな場合なのかもしれません。
この時、相関関係と因果関係を間違えてしまうと、つまり、顧客がウェブサイトで費やしている時間が長くなるから、費やすお金の総額が大きくなる、というように理解してしまうと、ウェブサイトで費やす時間を長くするような施策を打とうということになってしまいかねません。(さすがに、そんなことは実際にはないと思いますが。)
後になってそれがただの相関関係だけだったということがわかった時は、当たり前のように思うものですが、人間はその時その時ではそれを因果関係とついつい思い込んでしまったりするものです。
上記の本文を読むと「相関関係」と「因果関係」の違いがはっきりしてくるかもしれませんが、ところが、この相関関係と因果関係の違いというものは、実は本当に難しいものです。サイエンスの研究の世界でもそこがあいまいであったり、勘違いしていたり、因果関係だと思われていたものが後になって覆されるということはよくあることなのです。
ただ、それでは因果関係が難しいからといって、あきらめるか、もしくは無視するかとしてしまったのではしょうがないと思います。私達は、そもそも不確実な世界に生きているわけですし、さらには不確実な人間という生き物を相手にビジネスをしているわけです。ですのでビジネスの世界にはそもそも完全な答えなどというものはないのです。
ただ、それでも、サイエンスがそうであるように、必死に真実に迫っていくという努力をすることで、時間とともにより正しい因果関係を理解していくことができ、そのことによって施策の精度が上がり、よりよい成果を上げていくことができるようになるわけです。
そして、そのためにはまず、相関関係と因果関係の違いをおさえ、その違いを見極めるための思考のフレームワークを持っておくといいと思います。その上で、統計学の知識とスキルがあると、データを使って因果関係に関する仮説をより効果的に構築していくことができるようになります。
ここで重要なのは、因果関係に関する完全なる答えを求めるのではなく、まずは今、因果関係だと思っている関係性が実は相関関係に過ぎないのかもしれないと受け入れることです。
そういった態度を持つことで初めて、データを使って因果関係に関する仮説を構築し、検証していく仕組みを作っていくモチベーションが生まれ、一歩づつ真実に近づいていくことができるようになると思います。
これこそが、現代のビジネスに必要な、データを使ったサイエンス的な改善のプロセス、つまり「仮説」と「実験」を繰り返すことで改善させていくというアプローチです。そして、これは将来のことではなく、すでに今日シリコンバレーに代表されるデータ先進企業がやっていることなのです。
- ファイナンシャル・タイムスがシリコンバレーのSaaS企業のようにデータを使って成長しているという話 - Link
- Netflixがカスタマーを誰よりも理解するためのデータ分析プロセス、コンシューマー・サイエンスの紹介 - Link
データサイエンス・ブートキャンプ、7月開催!
次回のデータサイエンス・ブートキャンプは7月です!
ビジネスを成長させるためにはデータを使って因果関係に関する仮説を構築し、実験するというサイクルを効率的に回していく必要があります。そしてそのためには統計学を含むデータサイエンスの手法を習得する必要があります。
最終的にビジネスの現場で意思決定を行うためにどうデータを使うのかという視点でどんどんと進化させていっている「データサイエンス・ブートキャンプ」ですが、次回は7月、その次は11月です。
ぜひ「データ・インフォームド」な意思決定を行いたい方、統計を基礎からしっかりと学びたいという人は参加してみてください。
詳細はこちらのページにあります。