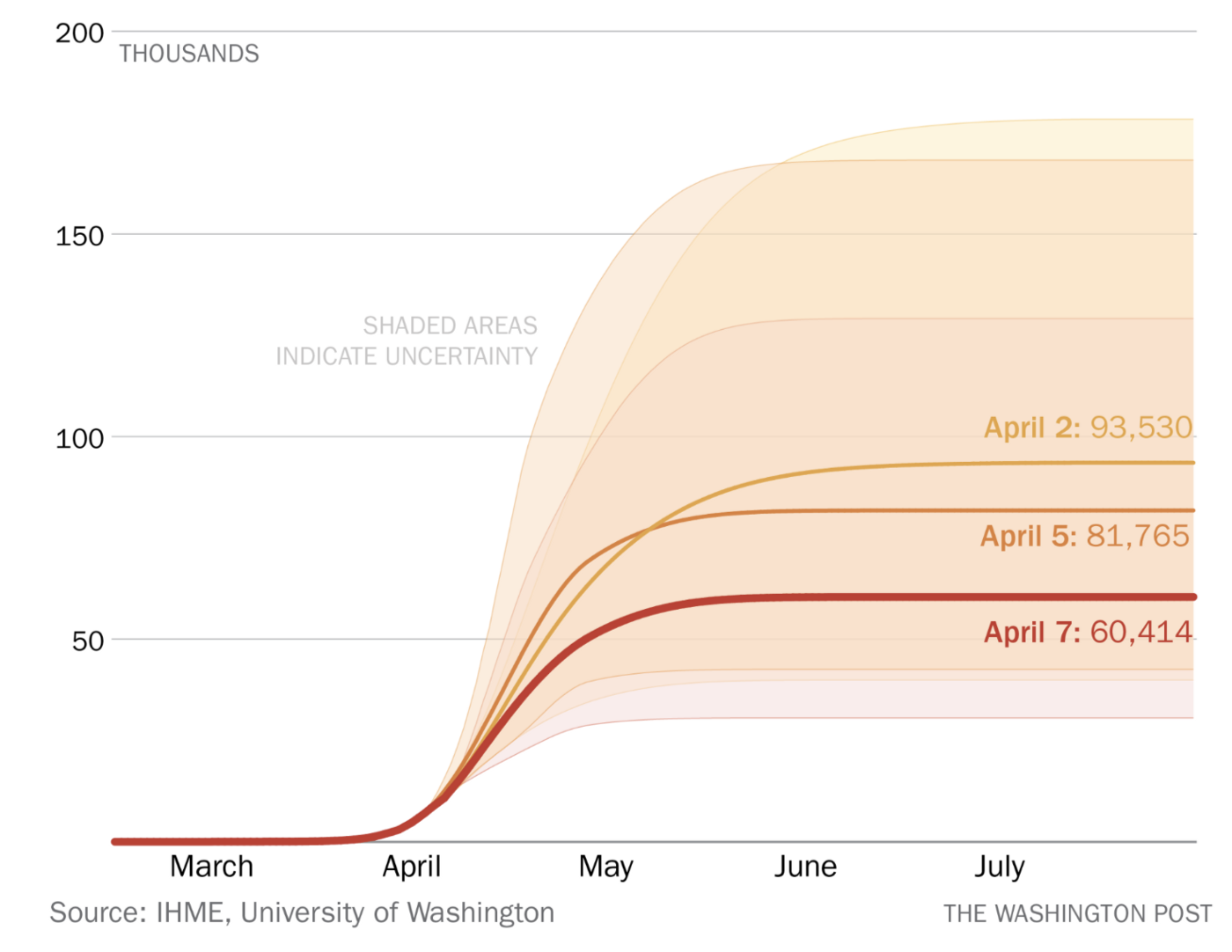
最近別の記事で、コロナウイルスの感染者数に関するデータはその背景を理解することなしに使うのは危険であるという内容の話をしましたが、今回は、コロナウイルスの感染者数を予測するモデルを使うときには気をつけなくてはいけない、という内容のエッセイがイギリスにおける統計学の学会である、王立統計学会(Royal Statistical Society)の中にあるデータ・サイエンス部のトップの人によって出されていました。
とくにそのモデルを作る人(科学者)、モデルによって出される数字を伝える人(ジャーナリスト)、モデルから得られる情報をもとに政策を作る人(政治家)は、責任が大きく、さらに間違いによる影響や被害が大きいだけに細心の注意を払うべきで、そのためのガイドラインを6つのルールとしてまとめています。
これは、コロナウイルスなどの感染症ウイルスの予測モデルに関わる人達だけでなく、広く一般の我々にとっても有効なアドバイスだと思います。というのも、世の中にはありとあらゆる領域予測モデルがあふれていて、そこから出てくる数字を私達は毎日のようにニュースとして目にするからです。
さらに、データ分析に関わっている人であれば、普段のビジネスのデータをもとに予測モデルを作ったり、そこから得られたインサイトを他の人と共有することもあるかと思います。
以下に、簡単に翻訳したのでぜひ読んでみて下さい。
All models are wrong, but some are completely wrong - リンク
by Chair of the Royal Statistical Society Data Science Section
先週、ファイナンシャル・タイムスは、タイトルが「コロナウイルスはイギリスの人口の半分をすでに感染してしまった」という記事の中でCOVID-19の感染の進行に関する新しい数学モデルをレポートしました。そのモデルは、他の研究者たちがPと呼ばれるパラメーター、(感染者の中で重症の人たちの割合)をいじるとかなり大きな違いを出すものでした。
ファイナンシャル・タイムスは、大半の研究者がおそらくありえないだろうとする値をそのようなPというパラーメータに設定し、そこから得られた予測の数字を、このような炎上するようなタイトルをつけた記事としてパブリッシュすることを選んだのです。
その記事が出されて以来、何百人もの科学者がその結果を批判し、その記事の著者は、彼らは予測しようとしているわけではないのだと、公的に弁解することに追い込まれました。
気候科学者たちの間違いから学べること
疫学者、伝染病学者たちは気候科学者のコミュニティが10年前に犯した同じ間違いを犯しているようです。気候科学の業界で起きた一連の危機は、気候科学者たちが痛い思いのするレッスンから、どのように政策立案者や公衆にコミュニケートしていくべきかを学ばせることとなったのです。
2009年にイースト・アングリア大学の気候研究ユニットがハッキングされ、気候サイエンスコミュニティ全体の信頼に対する疑念が生じることになってしまいました。気候研究ユニットの所長がコンピューターのコードとデータを公開することを拒んだ時に信頼は完全に失われてしまいました。この危機は気候サインエスのコミュニティに何年にも渡る暗い影を落とすことになったのです。
5回目の国際植物防疫条約(IPPC)のレポートが出されるまでには、予測モデルの持つ不確実性に関する明確なコミュニケーションと、モデルとデータに関する透明性を強制するためのメカニズムが作られるべきです。感染症のコミュニティは気候科学者たちがこれまでに学んだレッスンを学ばなくてはいけません。そして素早く学ばなくてはいけないのです。
この数日の間に、何人かの感染症の専門家ではない人たちが、都合が良すぎる、または単純に間違っているコロナウイルスに関する予測によってメディアの注目を集めました。イデオロギーにとりつかれた評論家たちはこうした結果を使って社会的距離のルールを緩和することを正当化しました。それが破壊的な結果をもたらすかもしれないにもかかわらずです。
モデルを扱うものが守るべき6つのルール
科学者とジャーナリストは予測モデルの作成にあたって避けては通れない不確実性というものを伝えることに道徳的な責任を持っています。これは非常に重要なことです。
そこで、ここに政策立案者、ジャーナリスト、そして科学者が守るべきいくつかのルールを挙げておきます。
ルール1:科学者とジャーナリストは予測の発表を行う時はそれに関連する不確実性のレベルを表現するべきだ。
全ての数学モデルは不確実性を含んでいる。研究者は結果が正しいということに対して自分たちが持つ確実性を伝える努力をするべきだ。
いくつかのありうる結果のシナリオを提供するべきである。1つの極端な結果だけでなく。
ルール2:ジャーナリストはパブリッシュする前に他の専門家の人達からのコメントを得るべきだ。
COVID-19に関するジャーナリズムの中でもっともひどい類のものは、このシンプルなルールを破ったものだ。他の科学者はそういった記事が出た後に反対の意見を述べることになった。しかしその頃には、誤解を与える記事はすでに何百万人の読者が目にすることとなり、一般大衆の意識の中に入り込んでしまったのである。
ルール3:科学者はモデルにとって重要な入力要素と仮定としていることをわかりやすく説明するべきだ。
そのモデルは入力するパラメーターにどれだけ敏感なのか。それらのパラメーターに対してあなたはどれだけ自信があるのか。他の研究者はそれに反対しているのか。
ルール4:透明性を可能な限り提供すること。
科学的な精査を行うことができるように使ったデータとコードを公開すること。他の専門家が素早くその研究成果に対して意見を言うことができるために、オープンな査読(ピアレビュー)を心がけるべきだ。
ルール5:政策立案者は複数のモデルを使い、十分な情報をもって政策を作っていくべきだ。
ニール・ファーガソンによって作られたインペリアル・カレッジの予測モデルは、イギリスのパンデミック政策のほぼ唯一のインプットとして使われた。他のグループからの他のモデルは考慮されたのだろうか。複数のモデルの間ではどれくらいの違いがあったのだろうか。
ルール6:モデルが感染症の専門でない人によって作られた時はそのことを指し示すこと。
私達は感染症の専門家に、新鮮なアイデアを出すために電気の変電所のデザインをお願いするだろうか。私達は、パンデミックとなるような感染症に関する予測モデルを電気技師が作ってきたときには、最新の注意を払うべきではないでしょうか。
以上、翻訳終わり。
最後に
予測モデルというのは扱いが難しいですね。とくにそれが多くの人に影響があり、さらに間違いによる被害が大きい場合には作る方も、使う方も注意が必要です。
これは実際に自分が予測モデルを使う方になってみると分かるのですが、その予測結果というのは多くの人たちが思っているほど確かなものではありません。
もちろん、比較的予測しやすいものも多くあります。しかし、今回のようなすごい勢いで感染者数が拡大していく感染症の予測というのは、そのドメインの知識と経験があったとしても難しいものだと思います。
地域によって、学校閉鎖などを始めとした施策は違いますし、それにどのくらいの人たちが従うのか、どれだけ忠実に従うのかというのも影響するでしょう。また、すでに感染者数が拡大している他の国のデータもどこまで信頼性があるものなのか見極めるのは難しいでしょう。
こうしたモデルを作るのは難しいにもかかわらず、できた瞬間からまるで単純なものかのように伝言ゲームが始まります。それが一番ひどいのはメディアだと思います。特に現在のようなオンラインでいかにインパクトのあるタイトルをつけることでクリック数が上がりそのことが収益になるようなビジネスモデルを持ったメディアであれば、どうしても単純でセンセーショナルになるような伝え方に偏っていきます。
これは現在のメディアのビジネスモデルが変わらない限り、変わることはないと思います。
ということは、私達一般市民のほうが、そういった予測モデルから出される結論や数字に疑問を持つ態度が必要になります。どのようにモデルが作られているのか、そのもととなるデータはどのようなものなのか、このモデルが答えることができるのはどういった質問で、逆に答えることができないのはどういった質問なのか、といった質問をしていくという具合です。
今ほど、データ・リテラシーの向上が必要な時はないのではないかと思います。私達も、データサイエンスのトレーニングや、セミナー、ブログ記事などを通して、より多くの人たちがデータ・リテラシーを向上させていくことができるような機会を、これからも引き続きたくさん提供していきたいと思っています。
データサイエンス・ブートキャンプ、5月開催!
次回のデータサイエンス・ブートキャンプは5月です!
データサイエンスやデータ分析の手法を1から体系的に学び、現場で使えるレベルのスキルを身につけていただくためのトレーニングです。
またデータやデータサイエンスの手法を使ってビジネスの問題を解決していくための、質問や仮説の構築の仕方などを含めたデータリテラシーも基礎から身につけていただくものとなっております。
ぜひこの機会に参加をご検討ください!
詳細はこちらのページにあります。