
はじめに
スタートアップではおなじみのコホート分析をサバイバル分析の手法を適用することによってどう簡単にできるか、RとExploratoryを使って紹介してみたいと思います。
もくじ
- そもそもコホート分析とは何か?
- なぜサバイバル分析?
- 使用するもの
- サバイバル分析のためのデータの準備
- サバイバル・カーブを計算してみる
- コホート毎のリテンション・カーブを分析
- コホートのコホート
- 最後に
そもそもコホート分析とは何か?
特にスタートアップであったり、さらには大きな会社の社内であっても、プロダクトやサービスの開発に関わっていたりすると、新規ユーザーの獲得数がどうであるかはさることながら、その獲得したユーザがどれくらい残っているのかを絶えずモニターしておくということが、非常に重要になってきます。
こちらは、カスタマー・リテンション率というKPIとして多くの方はモニターしていると思います。ここからもう一歩踏み入れて、そのカスタマー・リテンション率が時間とともにどう変化していったのかを理解することができると、新規獲得したカスタマーが将来どのくらいの率で、さらにどのくらいの期間カスタマーでいてくれるのかを推測もしくは予測することができ、さらにカスタマーのライフタイム・バリュー(LTV)の方も計算しやすくなります。こちらは以下のようなチャートでモニタリングしている方が多いのではないでしょうか?

縦軸がリテンション率、横軸は週になっています。こちらを見ると、リテンション率が時とともにどのように落ちていくか、もしくはどの辺で落ち着くかということがわかります。
さらにもう一歩踏みこんで、プロダクトやサービスを使い始めた時期をもとにグループを作って、そのグループ同士を見比べて、そのカーブがどのように変化していくのかを分析することを、コホート分析と言ったりします。これは、特にSaaS系スタートアップにとっては一番重要な分析と言っても過言ではないでしょう。
たまに以下のようなヒートマップを使って、ある新機能のリリースがどのようにユーザーのリテンションに影響しているかどうかをみる、みたいなものもスタートアップ関連のブログ等ではよく見かけますが、そもそもデータの可視化において、色の違いを見極めるというのは実は人間はあまり得意ではありません。
さらに一つ一つの区間の数字を読んでもたとえそれが上がったり、下がったりしたからといって、それがどれだけ信用のできる数字なのかというのは、なかなか掴みづらいというのが、実際ではないでしょうか。
それよりも、週ごと、もしくは月ごとのコホートをシンプルなライン・チャートにし、大まかなトレンドを見るということが統計学の専門の知識がない場合にも、実際に役立つのではないかと思います。ちなみに、人間は角度の違いを比べる方が色の違いを認識するよりも得意です。
どちらにしても、製品やサービスなどの新しい機能や自分たちが行った改善策が、どのようにビジネスに実際に影響を与えているのかを数値もしくはトレンドとして可視化し、それをもとに議論、または対策を立てていくことができるということで、他のスタートアップ同様、Exploratoryの社内でもカスタマー・リテンション率の改善のために、コホート分析は大変重宝しています。
サバイバル分析
実は、このコホート分析は、データ・サイエンスの業界ではサバイバル分析と呼ばれている手法を使うと、驚くほど簡単にできてしまい、さらにはもっと深く意味のある分析を行うことができます。サバイバル分析というのは、もともと医療の分野で、どの薬、治療を施すと患者が生き続ける期間が延びるかというリサーチをするために開発された複数の手法をまとめた総称です。この手の分析では、単純に患者が生きるか死ぬかというより、(人間は最終的にはみんな死んでしまいます。。。)死ぬまでの時間がどのように変化するかに興味の対象を置いた分析が必要になります。そして、この生きるか死ぬかというのを、カスタマーがカスタマーであり続けてくれる(retain)、もしくは離れていってしまう(churn)に置き換え、さらに、生きている時間というのを、カスタマーでいる時間と捉えると、このサバイバル分析の手法というのは実はカスタマーのリテンション率の分析であるコホート分析にしっかりと応用することができるわけです。
Rには、もちろん色々とサバイバル分析を行うパッケージがあるのですが、今日は、その中でも広くよく使われている survivalというパッケージを使って、サバイバル分析をコホート分析にどう応用できるかを紹介してみたいと思います。
使用するもの
本文の中ではRのUIであるExploratoryを使いますが、もしExploratory v3.1以降をすでにお使いの方は、こちらのシェアされているEDFをインポートして、ステップを追いながら読んでいくと、よりインタラクティブでわかりやすいかと思います。お持ちでない場合は、学校の先生もしくは生徒であれば無料ですし、そうでなくても30日間、クレジットカードなしで無料で使うことができますので、サインアップして、デスクトップアプリをダウンロードして試してみてください。
最後にRのコードものせていますので、もしR単体で再現したい方はそちらを試してみてください。
それでは、始めましょう。
サバイバル分析のためのデータの準備
サバイバル分析で使われるアルゴリズムは基本的に以下の二つの情報を必要とします。
- Event
- Time to Event
Eventはモニターしている人や、物に対して、こちらが分析したいイベントが起きたかどうかということです。今回のコホート分析の場合ですと、カスタマーが、サービスを使わなくなってしまったか、もしくはキャンセルしてしまったかということになります。
次のTime to Eventですが、こちらは、そのイベントが実際に起きるまでの時間です。コホート分析の場合ですと、カスタマーがサービスをやめるまでに、どのくらいの期間カスタマーであったかということになります。
ということで、以下のようなデータがあれば、すぐにサバイバル分析のアルゴリズムにかけることができます。

というのも、この、cancelled_dateからsignup_dateを引いたものが、先ほどの'Time to Event'に当てはまり、さらにStatusの列に"Cancelled"と入っているものを、キャンセルしたというEventと捉えればいいからです。
ところが、実際は、このようにデータがきれいにできていることは稀だと思います。特に、ほとんどのプロダクト、サービスにとってはそもそも明確なキャンセルしたかどうかというステータスすらないかもしれません。例えば、フェイスブックのようなサービスの場合、アカウントを削除してはいないけど、もう使わなくなってしまったというケースがあると思いますが、その場合は明確なキャンセルしたというEventにあたるものがデータの中にそもそもありません。
逆にスタートアップ等でサービスを提供している場合、集計しているデータというのは、ログイン履歴、アクセスログ、もしくはアクティビティログという形で、おおよそこんな感じではないでしょうか?

こちらのデータには、どのユーザーが、いつアクセスしたか、さらにどのOSもしくは、どこの国からアクセスしてきたかという情報が入っています。今日はこちらの、一般的なログ形式のデータを出発点として、Eventと、Time to Eventの情報を抽出し、そこからサバイバル分析の手法を使うステップに進んでみたいと思います。
データの加工
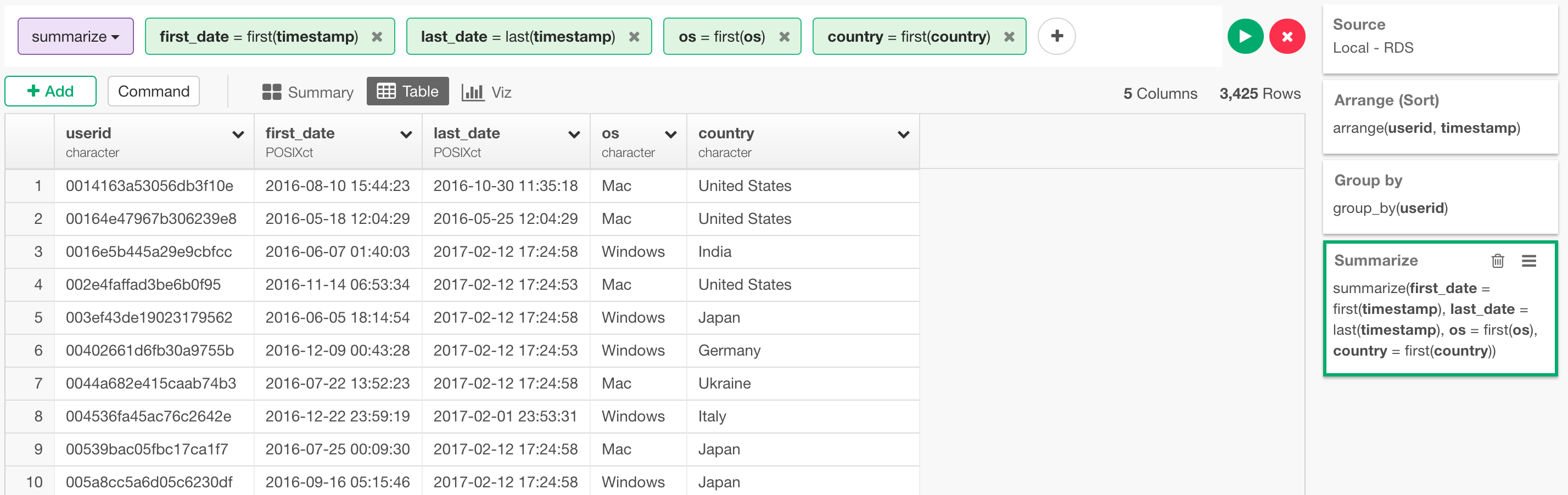
先ほども見たように、こちらのアクセスログには、一人のユーザーに対して複数の行がアクセスした回数分だけあります。サバイバル分析のアルゴリズムは1ユーザーあたり1行で、そこに先ほどのEventとTime to Eventの列を必要としているので、まずは最初に、以下のように集計(サマライズ)するところから始めます。
arrange(userid, timestamp) %>%
group_by(userid) %>%
summarize(first_date = first(timestamp), last_date = last(timestamp), os = first(os), country = first(country))
まず最初に、user, timestampの列でソートして、その後に、userの列で、データをグループ化します。こうすることで次のsummarizeで、それぞれのユーザーの最初のアクセス時間、さらには最後のアクセス時間を取り出すことができます。後で使うので、osとcountryの列の情報も同じfirst関数を使って取り出しておきます。
Exploratoryを使っている場合は、ステップごとに、列のヘッダー・メニューからコマンドを選んで付け加えていくことができます。

最終的に、Arrange、Group By、Summarizeの3つのステップを付け加えることによって以下のようになります。
こうして、ユーザー毎の最初のアクセス、最後のアクセス時間があることによって、簡単にユーザーがサービスを使っていた時間、つまりTime to Eventを以下のように計算できます。
mutate(lifetime = ceiling(as.numeric(last_date - first_date, units="weeks")))

last_dateからfirst_dateを引いた結果は、difftimeというオブジェクトになるので、それを、as.numericという関数を使って、numeric(数値)タイプに変えています。さらに、unitsという引数を使うことによって、週、日など、数値の単位を変えることができます。最後には、ceilingという関数を使って計算結果を整数になるように切り上げています。
次はEvent、つまりプロダクト、もしくはサービスを使うのをやめたかどうかということですが、これがほとんどのスタートアップ、特に最初の頃などは厄介なのではないでしょうか。というのも、サブスクリプションのようなサービスでいつキャンセルしたかどうかというデータがあると良いのですが、先ほども話したように、実際には無料であったり、もしくはモバイル・アプリのように一回買っておしまいであったり、もしくはE-commerceのように、カスタマーが本当にこちらのサービスを使うのをやめてしまったかどうかを判別するのが難しいことがよくあります。そこで、この「キャンセルした」というeventを任意に定義することになるのですが、これはそれぞれの会社やサービスなどで違ってくると思います。例えばExploratoryの場合では、長く使い続けるユーザーの場合は、最低でも1ヶ月に一度という形で使っていただいているので、4週間ログインがなければ、それは使わなくなってしまったとみなすという仮定をして、Eventの情報を作っています。こちらは具体的には以下のように割り出すことができます。
mutate(lifetime = ceiling(as.numeric(last_date - first_date, units="weeks")),
is_churned = last_date < now() - weeks(4))

ここでは最後にアクセスした日が4週間以上前であれば、使うのをやめてしまったということで、TRUEを返すようにして、Event用の列を作ります。
これで、EventとTime to Eventのデータができたので、このままサバイバル分析のアルゴリズムにかけるには十分なのですが、最後に、ユーザがどの月に使い始めたのかを元にしたグループ、つまりはコホートを作ってみましょう。こちらは、先ほどの同じmutateのステップに新しい計算を以下のように付け加えることができます。
mutate(lifetime = ceiling(as.numeric(last_date - first_date, units="weeks")),
is_churned = last_date < now() - weeks(4),
joined_month = floor_date(first_date, unit="month"))

ここでは、floor_dateという関数を使って、どの日であろうともいつもその含まれている月の値になるように月以下のデータを切り捨てています。ちなみに、その逆は、ceiling_date、四捨五入のようにしたい場合は、round_dateを使うと便利です。
サバイバル・カーブを計算してみる
それでは、必要なデータは一通り揃いましたので、いよいよサバイバル分析の手法の一つである、サバイバル・カーブというものを計算してみましょう。これは、今回の場合ですとリテンション率をEvent to Timeで使われている時間の単位毎(この場合は週)に計算した値を出すということになります。その結果をライン・チャートで可視化するとカーブが描かれるのでサバイバル・カーブ、もしくはリテンション・カーブと呼ばれていたりします。
こちらは、Addボタンを押して、Analyticsの下の、Calculate Survival Curveというメニューを選ぶことでアクセスすることができ、

開いたダイアログの中で、単純に、以下のようにTime to Event (lifetime)とEvent (is_churned)の列をそれぞれ指定し、

Runボタンを押すことによって、それぞれの週のリテンション率がいとも簡単に計算されます。

ちなみに、こちらは内部的にsurvivalパッケージのsurvfitという関数を呼んでいます。この結果のデータですが、簡単に説明しておくと、以下のようになります。
- time - 時間の単位、この場合は週
- n_risk - この週にやめる可能性があったユーザ数
- n_event- この週にやめたユーザー数
- n_censor - 少なくともこの週までやめずにいて、その後どうなるかの情報がないユーザー数
- estimate - この週までにやめていないユーザーの割合、つまりリテンション率
こちらのデータをライン・チャートを使って可視化すると以下のようになります。

便利なことに、こちらの計算結果の中には、信頼区間の情報も入っているので、上にあるようにRangeを選択することによって、一緒に可視化することができます。
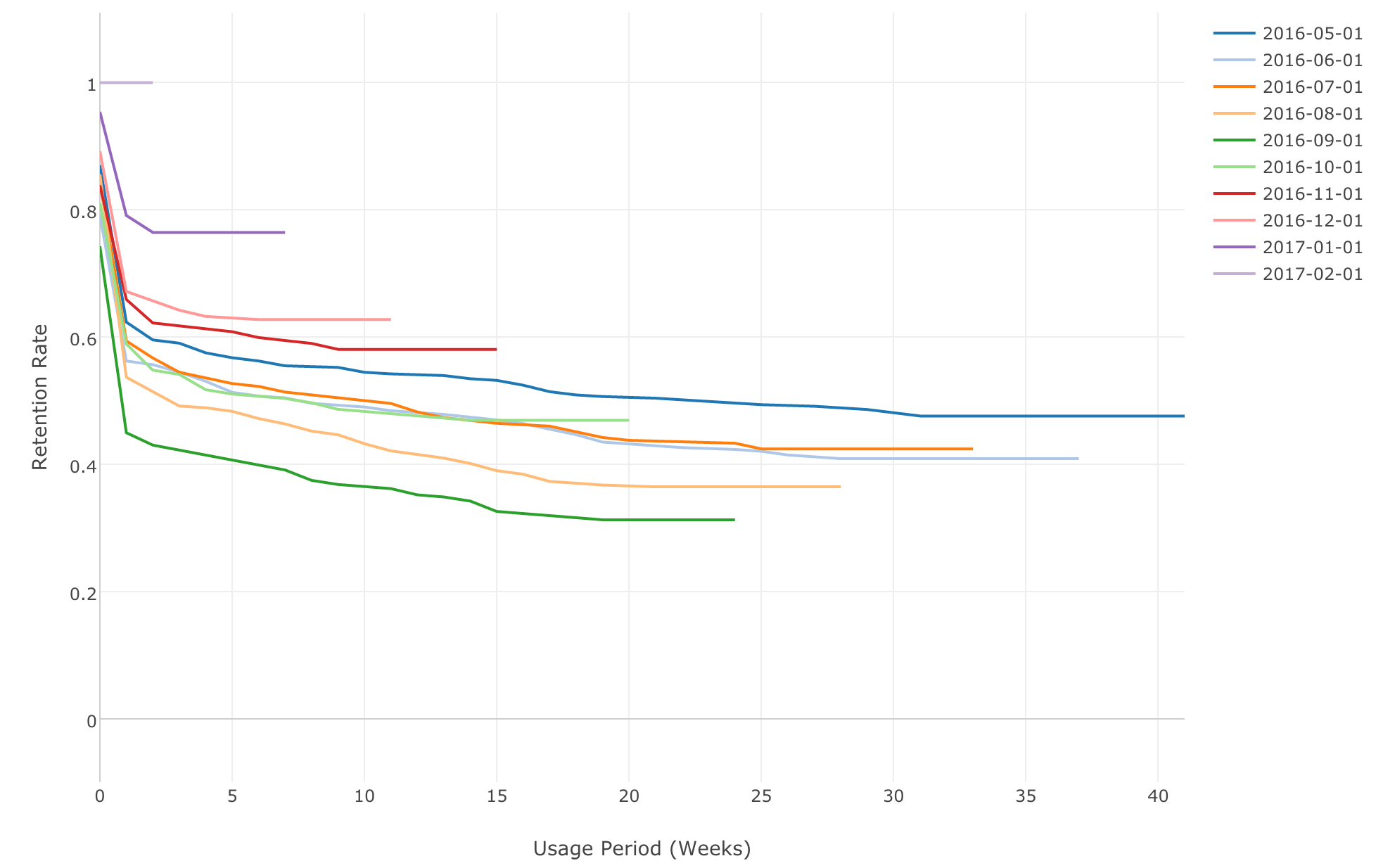
こちらを見ると最初の週に残っているユーザーが80%強ほど、さらに次の週までで残っているユーザーは60%強ということが見て取れると思います。
ところで、先ほどせっかく作った、コホート、つまりは、使い始めた月、もしくは国、さらにはOS毎のリテンション率のカーブはどうなのでしょうか?そちらの方を次に見てみましょう。
グループ毎のリテンション・カーブを分析
まずは最初に、使い始めた月ごとのコホートを見てみましょう。そのためには、Survival Curveを計算したステップの直前に、group_byという関数を使って、joined_monthごとにデータをグループ化するというステップを追加します。
ここで、一つだけ、Exploratoryのユーザーは知っておくと便利な情報なのですが、別のステップをクリックして移動する前に、右上にあるPinというボタンを押して、チャートの方をピンしてしまいましょう。

こうすることで、ステップを行ったり来たりしても、このチャートはいつもこのCalculate Survival Curveのステップのデータを表示し続けてくれます。
チャートがピンされるのが確認できたら、Mutateのステップに戻ります。そして、Addボタンの下から、Group Byを選びます。
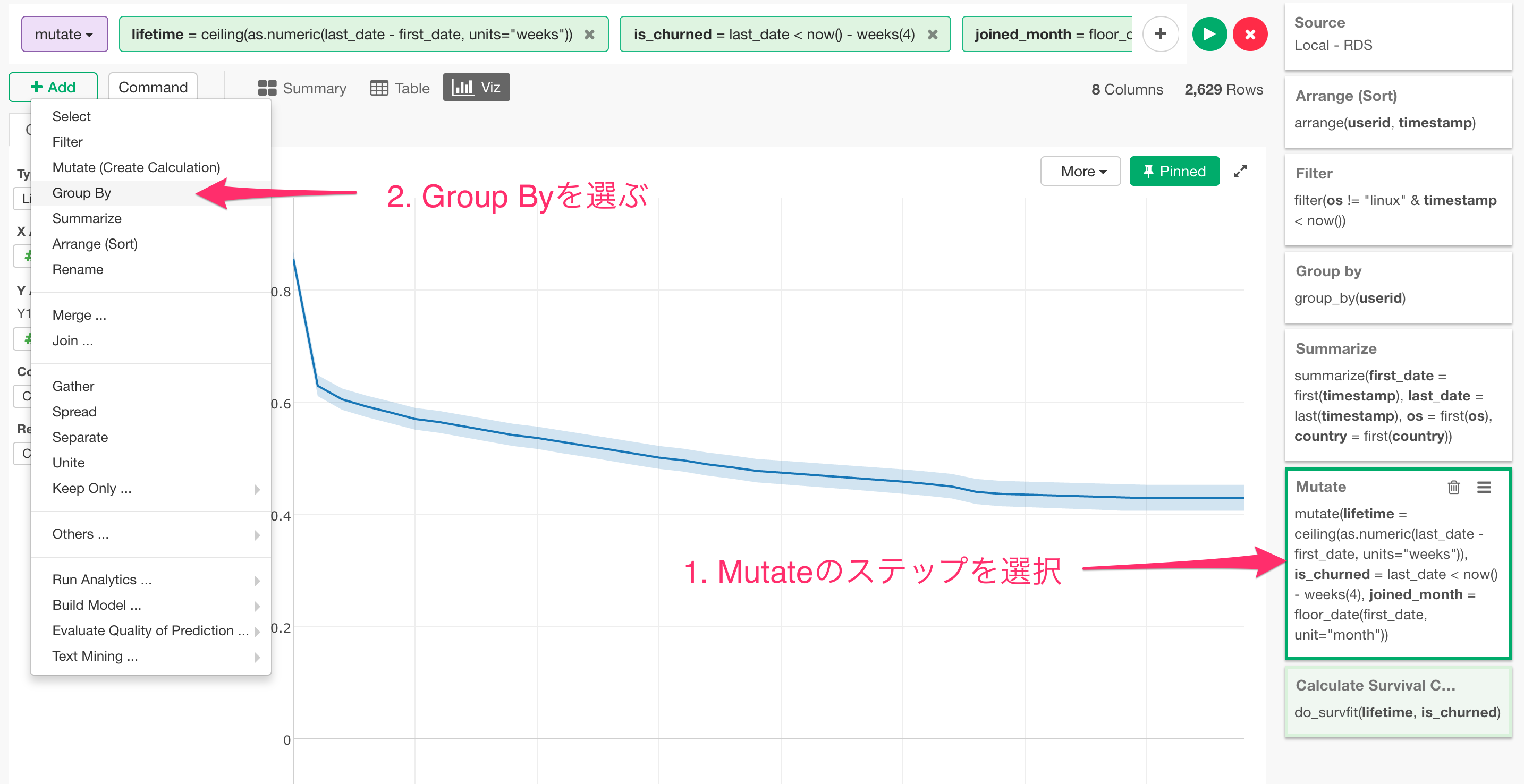
そしてそこで出てきた列リストから、joined_monthを選びます。

そうすると今度は、カーブが少しギザギザになるのが確認できると思います。
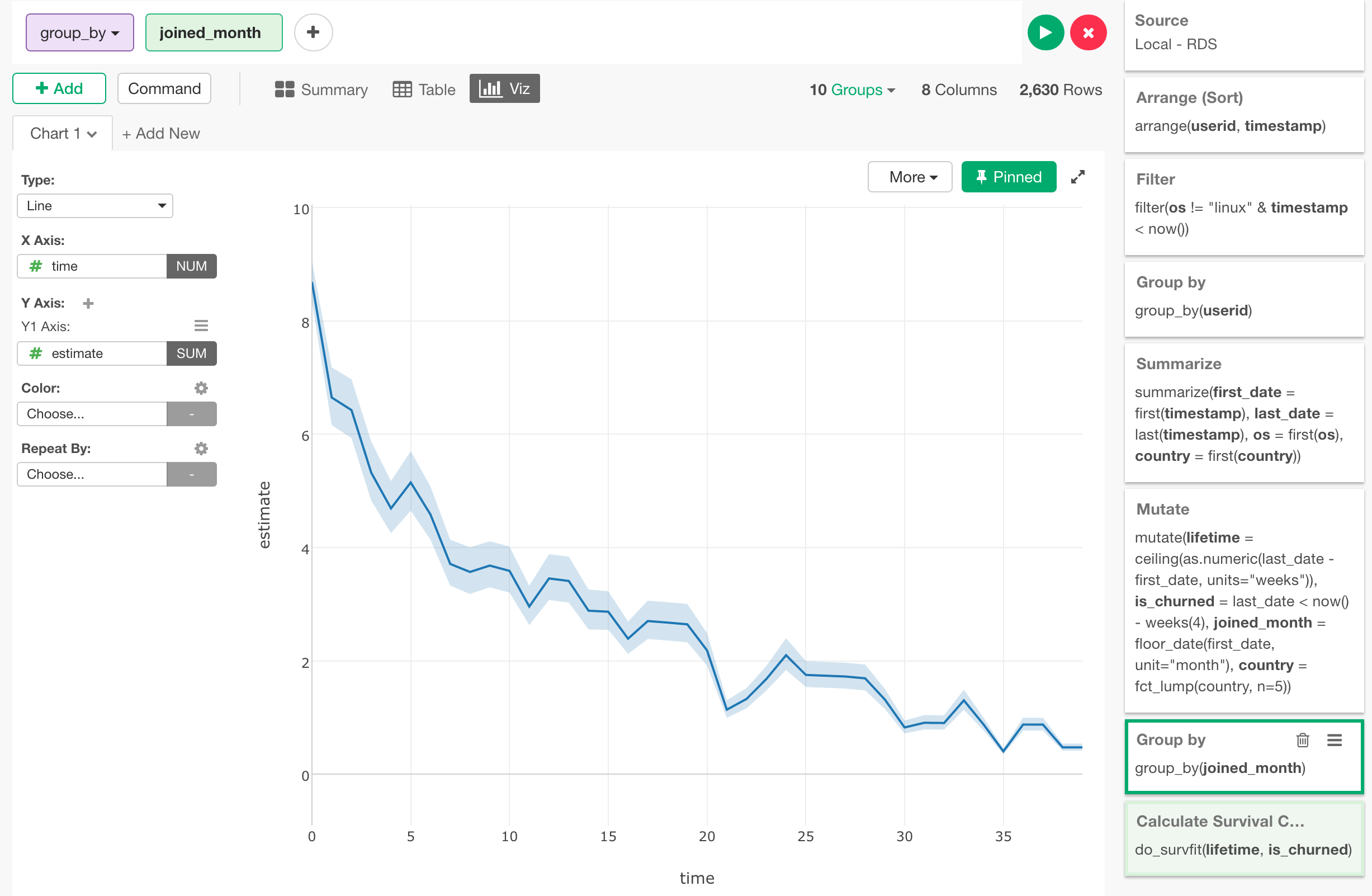
こちらは、joined_monthごとに、Survival Curveが計算されているからです。ここで、joined_monthをColorにアサイン、さらにDateの単位をMonth(月)にすることによって、それぞれの月のリテンション率のカーブが可視化されます。

(上のチャートでは、見やすいようにするために信頼区間を非表示にしてあります。)
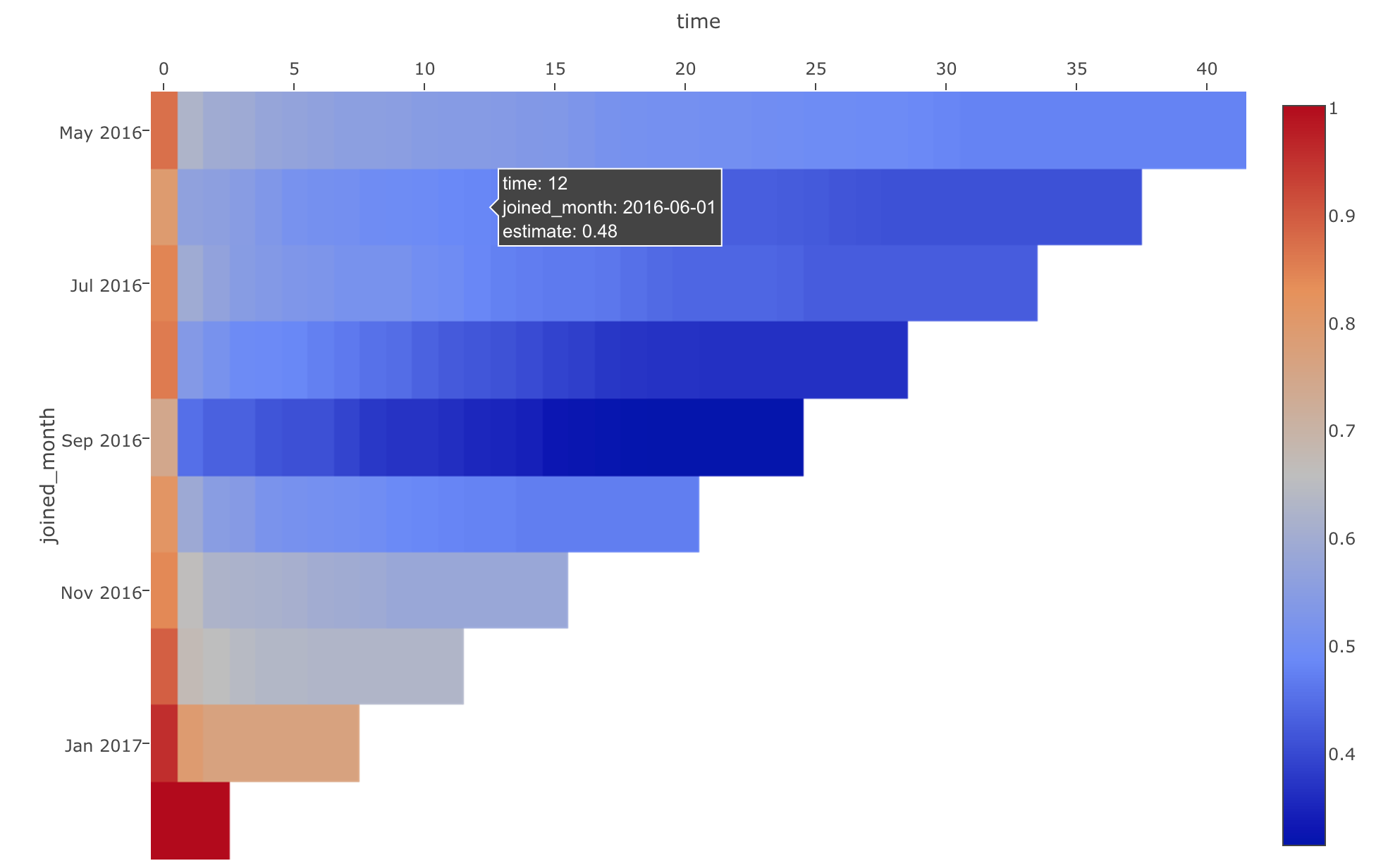
このようにしてみると、どの月のコホートのカーブも、一番最初の週での傾斜が急ですが、そのあとは比較的緩やかになるのが確認できると思います。さらには、緑の線である9月までは、リテンション率が落ち続けていますが、その後は改善し続けているのがわかります。
コホートのコホート
それではここで、上記の使い始めた月ごとのリテンション・カーブが、OSもしくは国というコホートごとにどのように差があるのかも見てみましょう。
OSごとのコホート
まずは、OSごとに見るために、単純に先ほどのGroup Byのステップで、osの列を付け加えます。

そして、このosの列をRepeat Byに割り当てます。
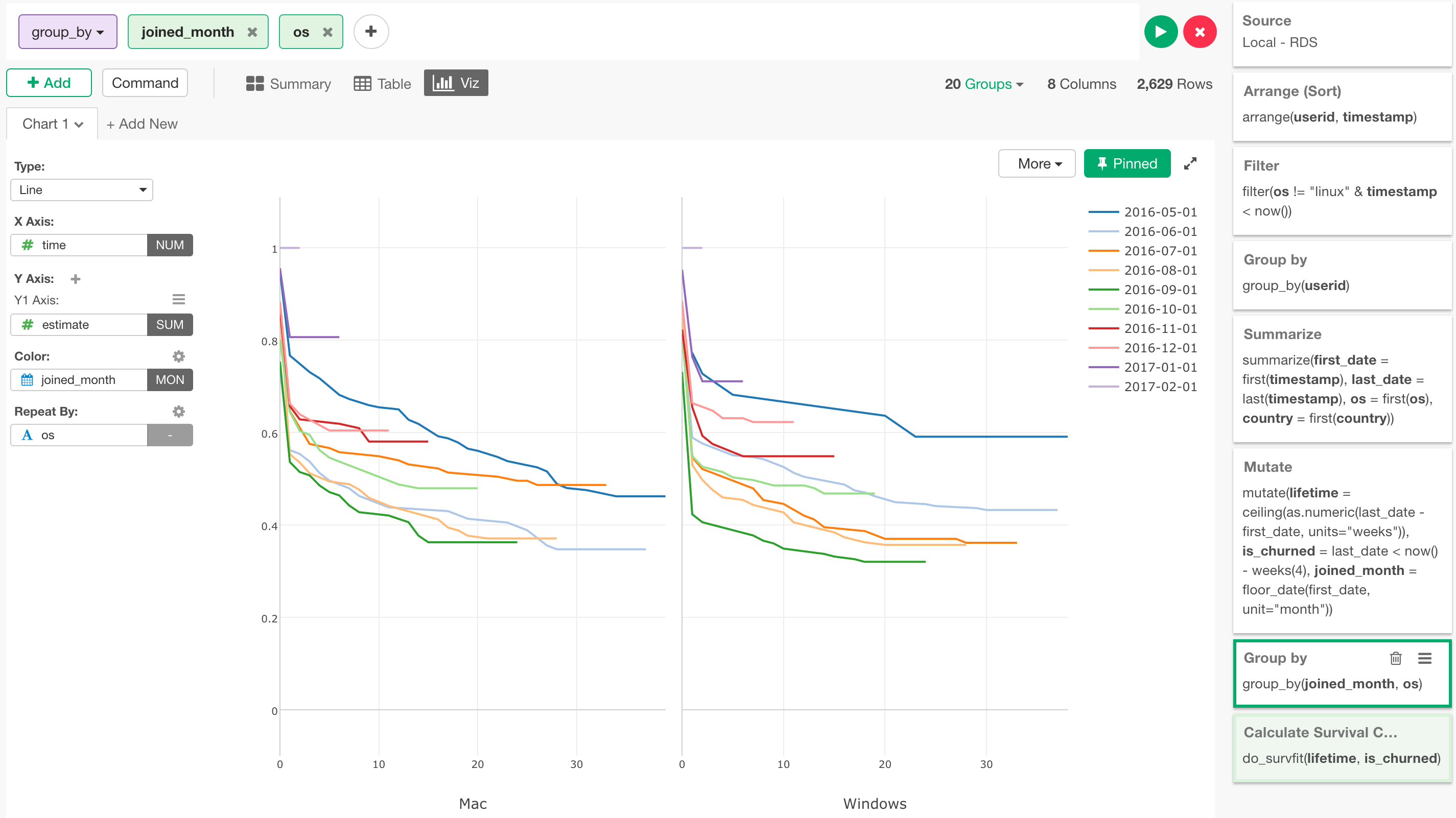
こうすることで、それぞれのosのタイプ (Mac / Windows) というコホートの中で、使い始めた月というコホートごとでのリテンション率の変化のトレンドを見て取ることができます。
上記のチャートを見ると、Windowsの5月に使い始めたグループはMacユーザーに比べてカーブが緩やか、つまりリテンション率が時間を経過してもいい、(リテンション率の落ち方が緩やか = Better)というのが見て取れます。ここで、先ほどにもありましたように、信頼区間を以下のように表示してみることができるのですが、

こうすると、このWindowsの5月のコホートは、信頼区間がものすごく大きいのがわかるかと思います。これは一般的に、そのグループに属するデータがあまりにも少ないためにアルゴリズムの方では推測しにくい時に起こります。100人のユーザーがいて60人が辞めたというのは偶然というよりも何か確固たる理由があるのではと思えますが、2人のユーザーがいて、そのうちの一人が辞めたというのでは、それはただの偶然かもしれません。それと同じだと思っていただけると理解しやすいかと思います。ですので、たとえ、このWindowsの5月使い始めたグループが良いリテンション・カーブを示しているからといっても、この場合はあまりあてにならないと言わざるを得ません。
国ごとのコホート
それでは、今度は、月ごとのコホートではなく、国ごとのコホートを見てみましょう。
先ほどのGroup Byのステップでjoined_dateであったものをcountryに切り替えます。
そして、countryをColorにアサインします。
そうすると全く意味のわからないチャートができました。

これは、サマリーの画面に行くとわかるのですが、実は国(country)の数が86もあるため86本の線を描こうとしてしまったがためによくわからないチャートになってしまったわけです。

このような時には、すべての国のデータを表示しようとするのではなく、頻度が高い、もしくはユーザー数の多い国にフォーカスするのが一つのやり方です。これはforcatsというパッケージにあるfct_lumpという関数を使って、いとも簡単に行うことができます。以下のようにcountryの列の頻度の高い順に最初の5つの値だけを残し、それ以外はOthersにまとめてしまうことができます。
fct_lump(country, n = 5)
これをMutateのステップに戻って、以下のように付け加えます。

こうすることによって、countryとos、countryとjoined_monthなどのコンビネーションでリテンション率のトレンドが比べやすくなります。
まずは、countryとosを見てましょう。

次に、countryとjoined_monthを見てみましょう。

もちろんここでも、リテンション・カーブの傾きの違いに一喜一憂せずに、信頼区間を表示してそれぞれの線が信頼に足るかをチェックする必要がありますが、こうやって、それぞれの国、オペレーティングシステムごとのトレンドをつかむことが素早くできます。
このように、一度サバイバル分析に必要なEventとTime to Eventのデータができてしまうと、あとはいとも簡単にリテンション・カーブを可視化することができる上に、さらにはいろいろなコホートを作り、それを組み合わせることによって、様々な角度からの分析が可能になります。ただ、ここまで見ていただいたように、どちらかというと実は、サバイバル分析の手法の理解と使いこなすのに必要な時間というよりも、その前提となるデータを加工することの方が実際は手間と時間がかかることが大いにあるかと思います。そしてこのデータの加工こそ、手前味噌になりますがExploratoryもしくはRの本領発揮ということになります。
次回はさらにもう一歩踏み入って、一体それでは何が、ユーザーが使い続けるかそれとも辞めてしまうのかに影響しているのかを、サバイバル分析の別の手法であるCox Regressionという予測モデルを使って調べてみたいと思います。
それでは、次回をお楽しみに!
最後に
もしよろしければ、興味のある方はこちらのサバイバル分析の手法を使ったコホート分析の方、是非試してみてください。こちらから、無料でトライアルを始めることができます。
Exploratoryで再現
こちらに、この分析で使ったデータをそのステップ込みでシェアしているので、こちらをダウンロードして、お手元のExploratoryにインポートしていただくと、ここで話したステップの方をワン・ステップづつ、再現していくことができます。
R Studioで再現
こちらに先ほどの分析のステップをR Scriptとしてエクスポートしておきました。RStudioなどで再現するのに便利かと思います。
# Load required packages.
library(lubridate)
library(forcats)
library(dplyr)
library(exploratory)
# Data Analysis Steps
exploratory::read_rds_file("/Users/kannishida/Downloads/activities.rds") %>%
exploratory::clean_data_frame() %>%
arrange(userid, timestamp) %>%
filter(os != "linux" & timestamp < now()) %>%
group_by(userid) %>%
summarize(first_date = first(timestamp), last_date = last(timestamp), os = first(os), country = first(country)) %>%
mutate(lifetime = ceiling(as.numeric(last_date - first_date, units="weeks")), is_churned = last_date < now() - weeks(4), joined_month = floor_date(first_date, unit="month"), country = fct_lump(country, n=5), country = fct_relevel(country, "United States", "Japan", "United Kingdom")) %>%
group_by(joined_month, country) %>%
do_survfit(lifetime, is_churned)
再現するには、exploratoryのパッケージのインストールが必要になりますが、こちらからダウンロードできます。
質問
もし個別に質問、要件などあればお気軽にこちら、kan@exploratory.ioの方にメールを送っていただければ、その日のうちに返事をいたします。