
データ・リテラシーと言う言葉を聞いたことありますか?
簡単に言うと、「データを読むことができて、データを理解でき、データを使って議論でき、データから得られた情報を使って意思決定ができる」能力のことです。
ダレル・ハフによって今から70年前になる1950年代に書かれた「統計でウソをつく方法 (How to Lie with Statistics) 」というこの世界では古典となる本があります。この本ほどデータリテラシーがいかに重要かをわかりやすく簡潔に説いた本はないと思うのですが、その教えは70年経った今でもまるで昨日書かれたかのように新鮮です。
むしろ、私達市民のデータリテラシーは当時と比べてあまり変わっていないかのようで残念です。
さらに、今日のようにデータがいよいよ簡単に手に入るようになり、簡単に分析できるようなツールも出てくるようになると、情報の消費者としてだけでなく、むしろ情報の供給者としても、最低限のデータリテラシーを持ちあわせた上で、データと向き合っていく責任があるのではないかと思います。
ということで今回は、この古典とも言える「統計でウソをつく方法 (How to Lie with Statistics) 」を「統計を使ってウソをつく方法からの学び」として簡単にまとめてあった記事があったので、そちらをもとに紹介します。
以下、要約。
表やチャートを作成することに携わっているものとして、私達は信頼に足るデータのサマリー情報を効果的に伝える必要があります。
そして、情報の消費者として、私達を間違った方向へ誘導したり、誇張しようとする統計値やデータには気をつけなければいけません。というものこうしたデータは誰か他の人間にとって都合のいいアクションを私達が取るように私達を操作しようとしていることが多いからです。
こうしたスキルは一般にデータ・リテラシーと言われます。データを読むことができて、データを理解でき、データを使って議論でき、データから得られた情報を使って意思決定ができるという能力のことです。
アルゴリズムやビッグデータに比べると、データリテラシーはそんなに興奮するものではないかもしれません。しかしどんなデータサイエンスの教育であれその基本となるべきものなのです。
1. 相関関係に気をつける
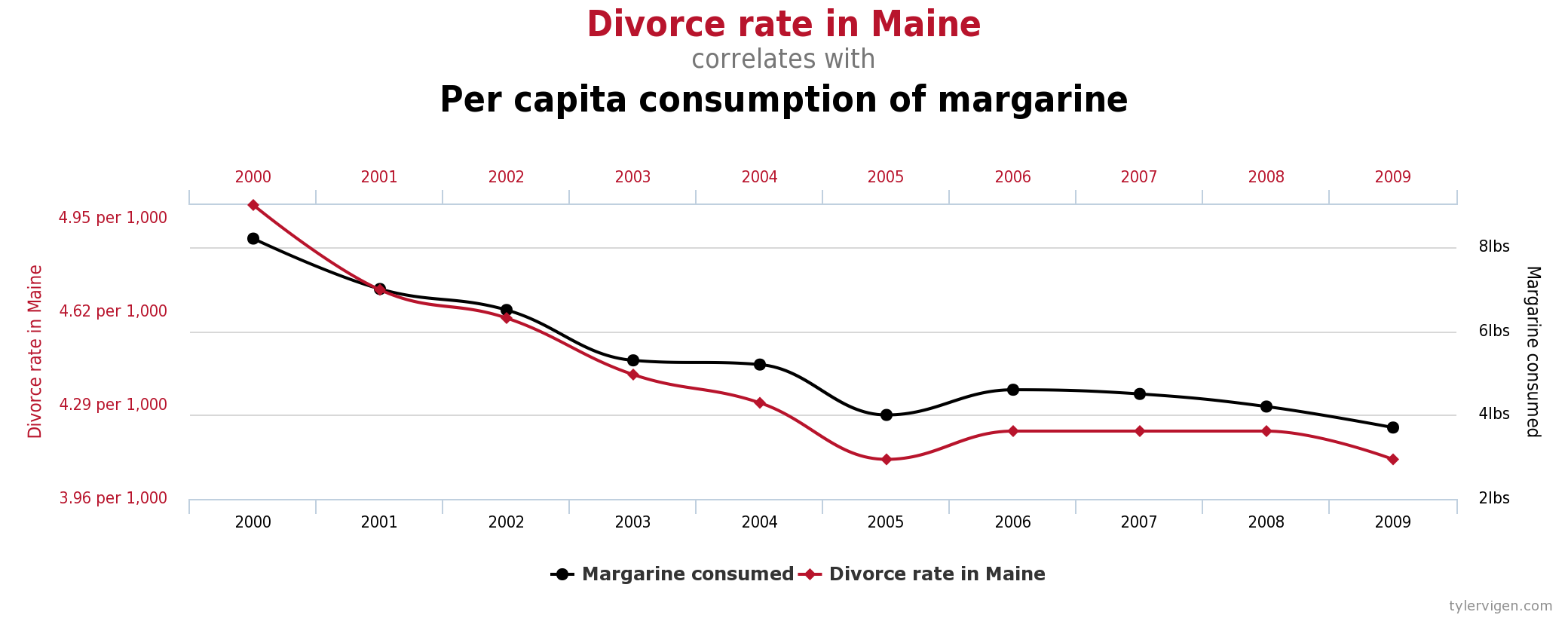
2つの変数、XとYが相関しているとき、つまり「一つの変数の値が上がればもう一つも上がる、もしくは下がる」といった関係があるとき、4つの説明が可能です。
- Xが原因でYが起きている
- Yが原因でXが起きている
- 第3の変数、ZがXとYに影響を与えている
- XとYはまったく関係がないけど、たまたまあるように見える。
しかし私達はすぐに「Xが原因でYが起きている」もしくは「Yが原因でXが起きている」のどちらかだと思ってしまいがちです。実際は「第3の変数、ZがXとYに影響を与えている」であったり、「 XとYはまったく関係がないけど、たまたまあるように見える。」であったりすることが多いのにも関わらずです。
例えば、大学で教育の年数が大きければより所得は高くると聞いた時、大学に在籍している年数が長くなるほど裕福になると結論づけてしまいます。
しかし、第3の要素として、勤勉で一生懸命に働く意思を持っているからかもしれませんし、親が金持ちだからかもしれません。そしてこうしたことが、教育をうける年数を多くしていて、さらに所得も増やしている理由なのかもしれません。
こうした第3の隠れた要因のせいで、私達は間違った結論を導き出してしまうことはよくあることです。
相関は因果関係を意味しないというアドバイスはおそらくみんな聞いたことがあるでしょう。しかし、例え因果関係による影響があるときでさえ、その関係がどっちを向いているのかは多くの場合分かっていないものなのです。
先生からの褒め言葉は生徒が高い成績を取ることに貢献しているのか。それとも高い成績を取るからより多くの褒め言葉をもらっているだけなのか。
それとも、第3の要因があって、例えばクラスのサイズがより小さい、または自然の光がクラスルームにより多く入ってくるということが両方の変数に影響しているのか。
こうした因果に関する質問は「ランダム化比較試験(A/Bテスト)」をすることで答えることが出来るのであって、私達が普段手にする、観察データと呼ばれる過去のデータでは、他の要因がないかどうかを調べきることができず、因果に関した質問に答えるには十分ではありません。
騙されないためには、相関関係を見たときには、第3の要因がないか疑い深く慎重に考えることです。人間はきれいに説明できる因果関係を好みますが、たいていの場合それはデータが私達に言おうとしていることではないのです。
2. 関係というのはいつまでも続くものではない
データの中に相関関係を見つけることができたとしましょう。しかしだからと言って、たとえそれが正の方向または負の方向に向かっていたとしても、そうした関係がずっと続くものであると想定するべきではありません。
大抵の場合、2つの変数間の直線的な関係はそれぞれの変数がとりうる値の範囲内のさらに限定された部分でのみ直線的であるだけなのです。その範囲の外に行くと、その2つの変数間の関係は指数的(角度がどんどんと鋭くなっていく)になるか、消えてなくなるか、もしくは逆の方向に向かっていくということはよくあることなのです。
多くの人は手元にあるデータで推定できる以上の領域について推定(extrapolations)しようとします。例えば企業の成長率、人口、株価、国家の支出、などに関してです。
ある関係性が見つかった範囲を超えて推定(Extrapolating)すると、それは「一般化するときのエラー」という罠にハマってしまうことになります。ローカル(一部)で起きている現象をもってそれをグローバル(一般)でも適用できるはずと想定しているからです。
貧困から抜け出した人々は、収入が増えるほどより人生に満足することができるようになるのは確かかもしれません。しかしこうした収入と「幸福」の間にある関係も、ある一定の範囲(おそらく年収800万円くらいまで)を超えると、より多くの収入によって「幸福」は向上するどころかむしろ減少すると言われています。
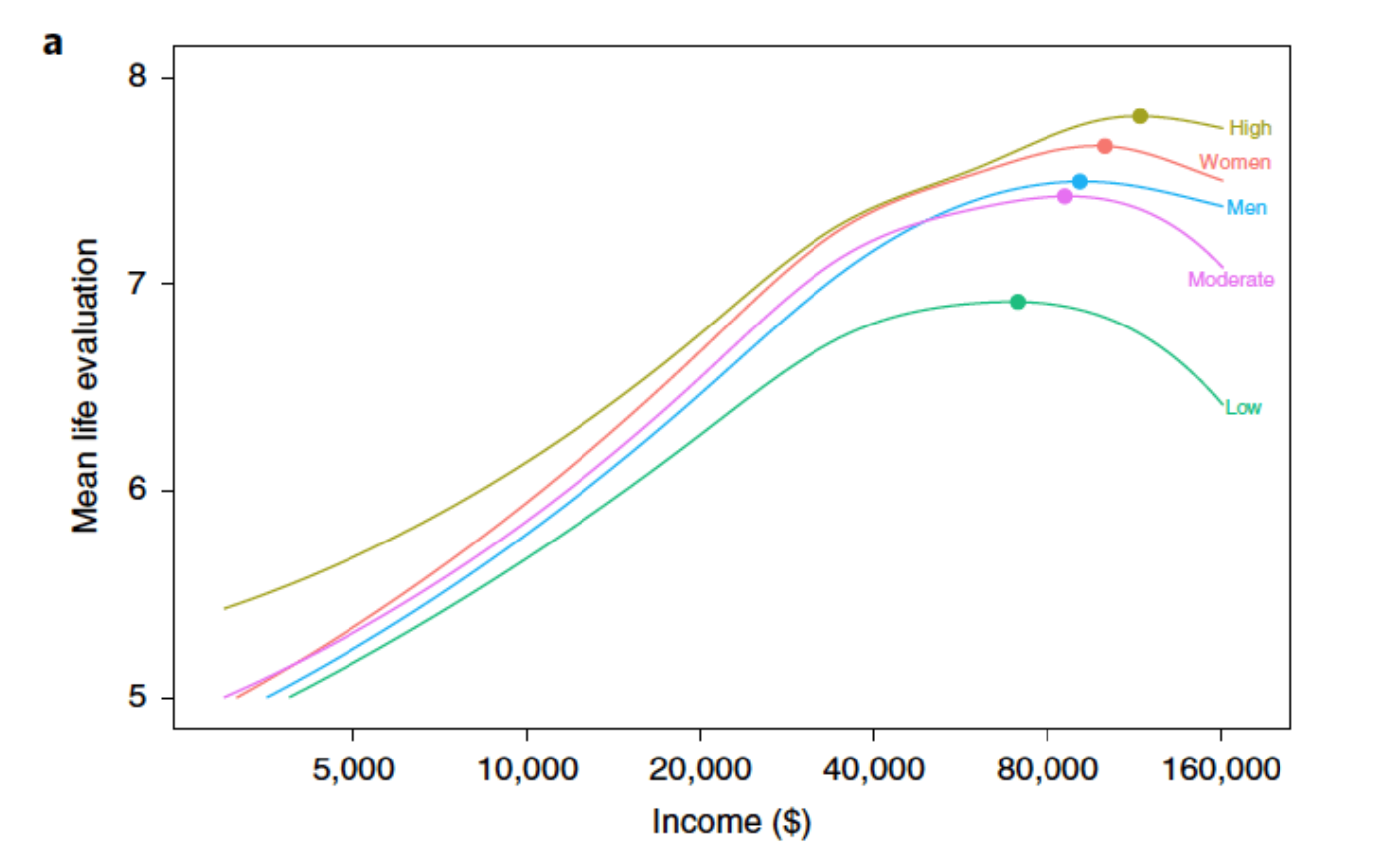
例え、相関関係や因果関係が確認されたとしても、現在わかっているデータの範囲を超えた部分に関しては「よくわかっていないのだ」ということを受け入れ、認識しましょう。
3. いつもチャートの軸のスケールを確認する
自分の主張をより効果的に伝えるためにチャートの軸のスケールを調整するのは、昔からよく使われるチャート操作のテクニックです。
基本的な原則として、バーチャートのY軸はいつも0から始まるべきです。そうでなければ、ちょっとした増加をあたかもかなり大きな増加であるかのように見せることができるので、そのことによって自分の主張がいかにも正しいかのように見せることができます。
左側はY軸は3.14%から始まっているのに対して、右側のチャートは0%から始まっています。
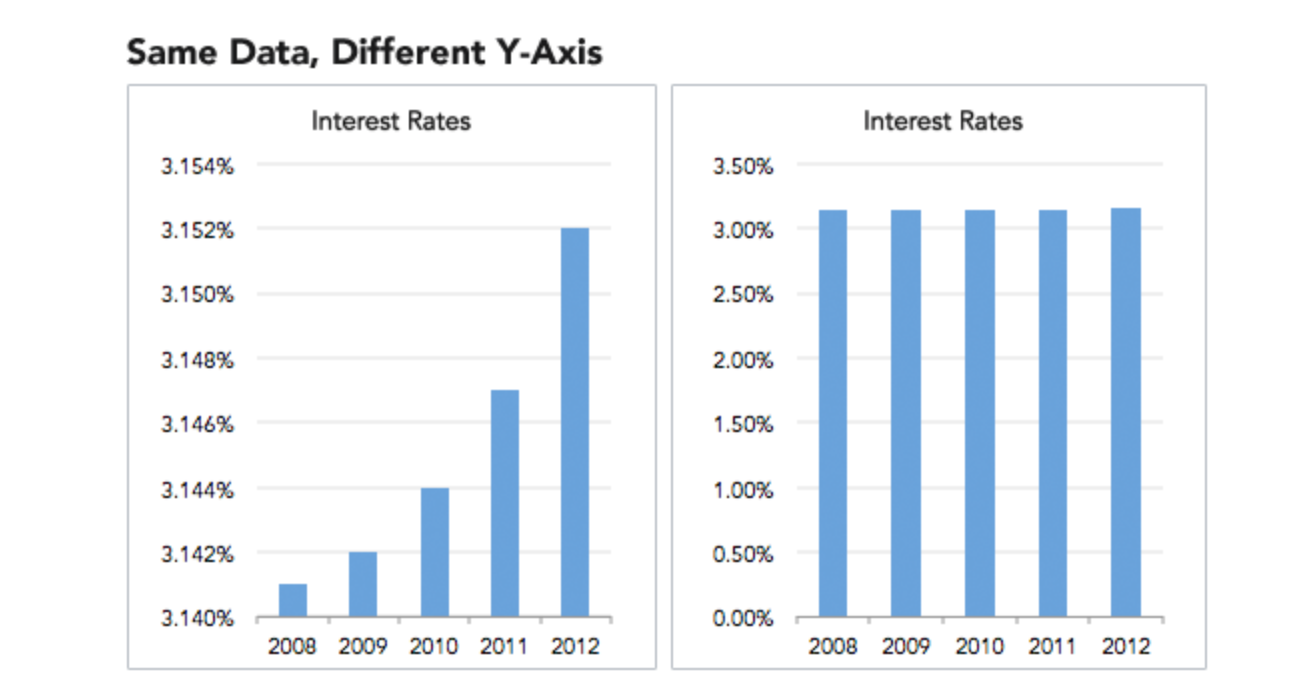
両方とも銀行の利子率を表していますが、左のチャートを見るとものすごく上がっていっているかのように見えます。
4. 小さなサンプルからは驚くような結果を導き出すことができる
もし私が、「発がん率が最も高いのは人口が最も少ない町であることが多い」といったらあなたは驚きますか?
ひょっとしたら、そんなに驚かないかもしれません。
それでは今度は、「発がん率が最も低いのも人口が最も少ない町である」と言ったらどうでしょう。
実はこれはサンプルのサイズ(データの量)が小さい時に起きる現象で、それは統計理論的に確証されているものなのです。
サンプルサイズが十分に大きく、より大きな母集団の分布と同じであれば問題ないのですが、研究に与えられた予算が限られていたり、アンケートに対する回答率が低かったりといった理由で、心理学、行動科学、医療科学分野の研究は少ないサンプルサイズでデータの分析を行わざるを得ないことが多いというのが現実です。しかしその結果、そうした研究の結果には疑問の余地が残るものであったり、再現できないものであったりということがよく起きています。
サイエンティスト(科学者)は、大抵の場合、正統な理由で小さいサンプルサイズを使わざるを得ない場合が多いのですが、広告業界の人たちは、自分たちに都合の良い結果を得るために、あえて少数の人達を集めたテストをたくさん行うということをよくやります。
私達人間はサンプルサイズの大小に対しての感覚を調整するのが得意ではありません。1000人を対象とした検証であれ、10人を対象とした検証であれ同じような感覚でその結果を受け入れてしまうのです。
少人数を対象にした調査を何回も行えば、それぞれのグループから得られる結果は大きく変わってきます。
例えば、歯医者を何人か集めてこの歯ブラシを推奨するかどうかという質問を行ったとしましょう。一つのグループでは90%の人が推奨するかもしれませんし、別のグループでは10%の人しか推奨しないかもしれません。こうした聞き取り調査を少数のグループを何回も別々に集めて行えば、このようにデータが大きくばらつくということは統計理論的にはよくあることです。
この時あなたが、この歯ブラシを売りたいマーケターだとすれば、都合のいい調査結果だけをレポートし、他の結果は捨ててしまえばいいのです。そうすれば、「この歯ブラシは90%の歯医者に支持されている」という広告を打つことができます。
こうした、小さいサンプルサイズによって起こされる現象に騙されないようにするには、いつもその研究結果に使われたデータのサイズがどれくらいなのかに注意を払いましょう。もしそれを公表していないというのであれば、その研究や調査を行った人たちは、何か隠したいことがあるのだと想定し、そこで出てきた数値は価値のないものとして切り捨てるべきです。
5. データを説明する全ての数値を見る
例えば、ある町の平均気温が16度だと分かったとします。しかし、最高気温と最低気温を知ることなしには、その情報はあまり役に立ちません。この町は寒い時はマイナス30度まで下がり、暑い時は50度まで上がるのかもしれません。しかしそれでも年間の平均気温を出すと過ごしやすいレベルの16度となるかもしれないのです。
これは、一つの数値で目の前のデータを理解しようとするには限界があるという例です。
もう一つのよくある例を見てみましょう。
あなたに2人の子供がいると仮定して下さい。一人はIQが99、もう一人は102だったとします。この場合、あなたはこのことを子供たちに伝えるべきではありません。というのも子供たちは自分たちを比較してしまいますが、それは意味がないからです。
なぜなら、IQテストというのは3ポイントほどの標準誤差があるからです。つまり、IQが99の子はおそらく100回受けたら68回くらい(約68%ほど)は96から102の間のスコアを取るであろうということなのです。
すると、今回102のスコアを取っているもう一人の子供との差は有意であるとは言えません。というのも、二人が何回もIQテストを受けたとすると、彼女たちのスコアの順位がひっくり返るということは大いに有り得ることなのです。彼女たちの頭の良さが急に変わったわけではないにも関わらずです。
つまり、標準誤差を考慮することなく、一つの数値だけを見て比較してしまうと、手元にあるデータから導き出せる以上のドラマチックな結論を導き出してしまうことができるのです。
研究や分析の結果で一つの数値しかレポートされていないものはたいてい、何かその研究を行っている人が隠したいものがあると思ってよいでしょう。
同じように、チャートを見た時に、一部のデータを省いているようなものは信用しないほうがよいでしょう。一部のデータを隠すことで、自分にとって都合のいいストーリーをあまりにも簡単に作れてしまうのです。
さらに別の例でこのことを考えてみましょう。
平均で2年ほど寿命を長くするという薬があったとします。あなたはその薬を服用しますか?
その時、もしこの薬は実は最悪の場合12年ほど寿命が短くなることもあり、逆に最高の場合には14年ほど寿命が長くなることもあると分かったら、あなたは考えを変えますか?
たいていの場合、データの要約だけではなく、データの詳細というのが重要で、一つの要約された統計値(平均など)だけで全体の姿を捉えるには限界があるのです。
6. どの「平均」が使われているのかに注意する
- 平均:すべての値を合計して、総数で割る。
- 中央値:小さい値から大きい値へと順番に並べた時に真ん中にある値。
- 最頻値:もっともよく出てくる値。
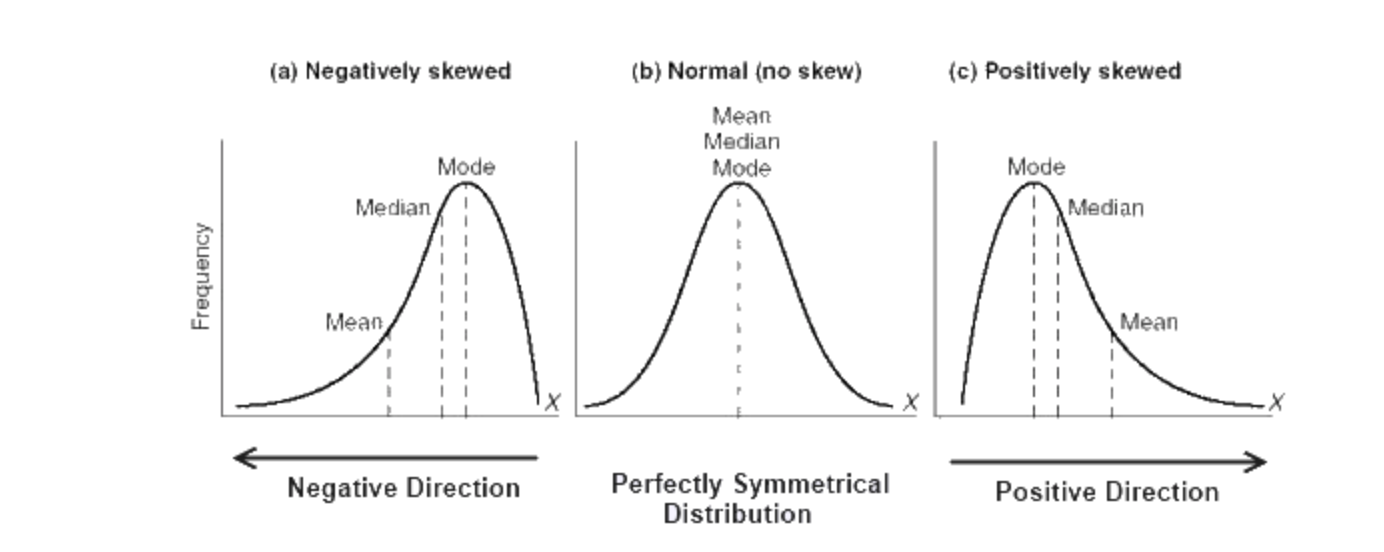
例えば、USの個人所得の平均値と中央値の差は16,000ドル(約175万円)ほどもあります。政治家、マーケター、そしてCEOは、そのうちの一つの数値を「平均」として使うことで、同じデータを使っているにも関わらず異なる結論を導き出すことができるようになります。
このような問題を避けるためには、平均、中央値、最頻値のすべてを見る必要があります。そしてどの数値が最も適切なのかをデータによって見極める必要があります。一般的には、所得、人口、寿命、不動産価格などのような、かなり偏ったデータの場合には中央値がより適切です。
もし可能であればヒストグラムを使ってデータの分布を見るとよいでしょう。
1つの数値で理解しようとするのではなく、複数の数値から理解するように努めましょう。
7. 共通のベースラインと比べる
統計値を見る時、重要な質問は多くの場合、その値が「何か」ではなく、その値が「他の何かに比べて相対的にどう違うのか」です。
もし私が、「2017年のUSのGDPは$19.39 トリリオンであった」と言ったなら、それはものすごく大きなものに聞こえるでしょう。というのも無意識のうちに自分が普段買い物などに支払っている額と比べてしまうからです。
しかし、それを前年のUSのGDPである$18.62トリリオンと比べればどうでしょうか。急にそんなにたいしたことないと思えてくるのではないでしょうか。
ニューヨークでは2018年に289件もの殺人事件があったとして人々を怖がらせることができます。しかし、この数値を1990年の殺人事件の数である2245件と比べると、ニューヨークはかなり安全になったと言うこともできます。
たいていの場合、相対的に比べることが重要なのです。
また他にも重要なことがあります。
それは、その統計値を出す計算方法や定義が変わっているかどうかにも注意を払わなくてはいけません。
例えば1930年から1935年の間にUSの農家の数は500,000も増えました。しかし、それは国勢調査局による「農家」の定義がこの期間の間に変わったからです。
失業率を下げるための最も簡単な方法は、「失業」の定義を変え、例えば仕事を探すのを止めてしまった人を失業者の数に含めないとすることです。
データの収集の仕方や統計値の定義の変更により極端な結果が出ることがよくありますが、実際にそういったトレンドがあるのだと勘違いしてしまうことになってしまいます。
これを防ぐにはまず最初にあらゆる角度から全ての統計値を見ていく必要があります。そして次に、その統計値の定義が時間とともに変わっていないかどうかを確認することです。それらができてはじめて、データから結論を導き出していくことができるようになるのです。
8. サンプルの選択過程にあるバイアスに気をつけろ
データの収集の仕方によって、データの中にバイアスが入ってしまうことがよくあります。
家の固定電話(携帯電話でなく)の電話番号を使った世論調査の回答者は裕福で歳をとった人たちに偏りがちです。
また「住んでいる場所」のせいでバイアスが起きることもよくあります。簡単にできるからということで都市に住んでいる人たちだけを対象にした調査は、進歩的な意見を持つ人にバイアスがかかってくるでしょう。
サンプルすることによるバイアスは政治に関する世論調査でより顕著となります。アメリカの2016年の大統領選挙に関する世論調査は、アメリカ国民の一般的な傾向を代表していなかったということが後になって分かりました。
調査結果が信頼できるかどうかを評価する時、サンプルされたデータにはどういった人たちが含まれているのか、逆に含まれていないのかということを質問しなくてはいけません。
何十年もの間、心理学、社会学における研究は「WEIRD」バイアスによって汚されてきました。こうした研究で使われるサンプル(多くの場合大学の生徒)は西洋(Western)、教育レベルが高い(Educated)、産業化されていて(Industrialized)、裕福で(Rich)、民主的(Democratic)な国からの人々だけを含んでいました。このような限られた人たちを対象にした研究が世界中全ての人間を代表しているとはとてもいいきれないのは明らかでしょう。
私達が情報を得る元を選択する時におこる「サンプリング・バイアス」にも気をつけるべきです。多くの人たちは自分と意見を同じにする人たちやメディアからの情報のみを選んで受け入れてしまうことで、「情報の選択バイアス」を自分たちにかけてしまっているのです。
これは危険な状況を生み出します。
意見の違う人達と出会うことがなくなり、自分たちの持っている考えにより固執してしまうことになります。この解決方法は単純ですが実際にやるのは難しいものです。様々なニュース元から情報を得るべきで、特に自分と意見の違う人たちやメディアからも情報を積極的に得ていくべきです。
9. 有名人には気をつけろ、そして権威を疑え
「OK name(オッケーな名前)」と言われたりしますが、威厳を与えるために研究成果のレポートに入れられる名前のことです。有名な医療の専門家や医者、大学、研究機関、大企業などの名前を見ると私達は自動的に彼らの出すレポートの結果を信用しがちです。
しかし多くの場合、こうした専門家がそこにある研究を行ったのではなく、実際は意味のない程度にしか関わってなく、ただ人々を説得するためだけに名前が付け加えられているに過ぎないことが多いのです。
タバコ会社が人に死をもたらす彼らの製品を売るために「医者」を使ってきたのは一つの有名な例です。こうしたケースでは、そういった専門家はウソを付くことで直接お金をもらっていたのです。
権威のある名前によって説得されてしまうことを防ぐには、名前が出ている本人が実際に研究に関わっているのかどうかを確認することです。組織や機関の名前を見てすぐに「その研究が間違っているはずはない」と想定してしまうことのないように気をつけましょう。
私達が自分たちに課している無意識のバイアスを避けるためには、その研究成果のレポートの中で出されている統計値を自分で分析するまでは、そのレポートの著者の名前や大学の名前を見るべきではないと思います。
例え、その業界では権威のある専門家による研究成果だとしても、疑問に思うことなくその成果をそのまま受け入れてしまうのはよくありません。これでは、より大きなパワーを持っている人はより正しいのだと思ってしまう、「権威を借りた議論」という罠にはまってしまいます。
過去の成功は、今回の研究や分析の結果が正しいということに対しては何の重みも与えないはずなのです。
カール・セーガンの言葉を借りると、「権威を持ったものでも、他の者と同じように自分たちの議論を証明しなくてはいけない。」ということです。
10. 一つの統計値を信じすぎてはいけない
どんな統計値であってもいつも疑いの目をもって見るべきです。
どんな数値も、間違いを犯しがちな人間が、完全でないツールを使って、絶えず変わり続ける環境の中で、ある時点で得られた1つのサンプルデータの中から精製した成果物に過ぎないのです。
データはある組織のために働く一人の人間によって分析されるのであり、その人間はある特別の動機を持つ外部の人たちからの資金の提供を受けているかもしれません。
さらに、そうしたレポートに出てくる統計値やチャートは、自分たちがみんなに信じてほしいと思っているアイデアをあなたに売り込むことにしか興味のない出版社によってあなたのもとに届けられているという事実も忘れてはいけません。
1つの数字を信じすぎるということは、その数字が得られたある特定の状況に対して過学習しすぎているということでもあります。
統計やデータが、純粋に客観的であるということはありません。統計とは不確実なデータの一つの解釈に過ぎないのです。
人間はばらつき、世界もばらつきます。それは私達がこの世界に生きていることが素晴らしいという理由の一つでもあるのです。それゆえ、もし誰かが統計値を1つのチャートやテーブルで表現してそれが確実であるようなことを言っていたなら、その時は注意したほうがいいでしょう。
1つの値ではなく、値の範囲を見るべきです。数値だけでなく、その信頼区間を求めるべきです。
結論を下す前により多くのデータを集めるべきです。複数の分析結果を比べるべきです。そしてデータはどのように収集されたのかを聞くべきです。
否定することのできないエビデンス(データによる証明)が提示されたら、私達は間違っていたと認め、考えを改める必要があります。この宇宙全体を完全に説明することができるような客観的な真実はないかもしれません。しかし、時間とともに私達の間違いはより少なくなっていくものなのです。これこそがサイエンスのゴールです。それぞれの研究の成果によって、暗闇に少しずつ明かりを与えていくようなものです。
これはデータサイエンスにとってのゴールでもあるべきです。得られた新しいデータによって、この世界の構造を少しずつ明らかにしていくのです。
同時に、データの限界を受け入れるべきで、一般化のしすぎには気をつけるべきです。「より多くのデータ」というのは万能薬ではありませんが、より多くの議論、複数の分析、精密な調査を行うことで、「より多くのデータ」は私達人間が現実世界でより良い意思決定を行っていく手助けとなります。そしてこれこそがデータリテラシーのある市民として私達が望むべきものなのです。
データ・リテラシー
データ・リテラシーとは、チャートや統計値を解釈し、行動を起こすことが出きる結論を導き出せるするスキルを持っているということです。
データの消費者として、自分に都合のいいようにデータを操作するのは実はいかに簡単かということを理解しておく必要があります。
統計値やデータを可視化するチャートをたくさん見たり読んだりすることはスキルを上げるために役立ちます。そしてさらにいいのは、そういったチャートを自分でたくさん作ってみることです。最高の手法を使う練習をし、他の人達をわざと勘違いさせないように努めるべきです。
この世界は悪い所ではありません。しかし、なかにはあなたが心の中で願うほど純粋な意図を持っていない人もいるのです。彼らは自分たちにとって都合のいい方向へあなたを導くためのツールとしてデータを使います。
こうした戦法に対する最も効果的な防御策は、基本的なレベルのデータ・リテラシーを身につけることです。
データを操作する方法を理解し、データを使ったごまかしを見破る方法を身につけるべきです。ある一定の疑い深い態度を持つということはあなた自身にとって役立つことであり、さらにデータサイエンス世界全般にとっても役立つことなのです。
こうしたことを念頭に置いて、責任のあるデータの生産者、そして消費者となって下さい。
以上、要訳終わり。
あとがき
今のようにデータを集めやすい時代には、そうしたデータを使いこなすことの出来るデータリテラシーが高い人間や企業と、データリテラシーが低い人間や企業との間の経済的な格差がどんどんと大きくなっていきます。
ここで、一つ問題なのはデータのリテラシーが低い場合には、自分たちのデータの使い方が間違っていることや、他人によって騙されていることにすら気づきにくいということです。
そして、さらにややこしくするのが、騙す方も、実は騙す気があって騙している者と、自分ではそのことにも気づかずに、ただデータリテラシーが低いために結果的に他人を騙してしまっているという状況がよくあるということです。
データリテラシーが低いと3度痛い
例えば、チームの誰かにデータの分析を頼んだとしましょう。その人はバー・チャートを使って、店舗によって売り上げに違いがあることを見つけました。すると、彼女はその違いをあたかも真実で、さらに今後もそういう違いがずっと起こるであろうと無意識のうちに想定した上で、あなたにその違いを伝えようとするかもしれません。
この時に、どれくらいのデータを元にした分析なのか、どれくらいの信頼区間を持っているのか、どのくらい信頼できるのか、他にその違いに影響している可能性のあるものはないのか、何が分かっていないのか、などと言ったことを質問することができればいいのですが、それができない場合には、そこで目の前のバーチャートでたまたま見えている「違い」に基づいて、何らかの意思決定をしてしまうかもしれません。
このことによって、ビジネスに余計な支障をきたすことになるかもしれませんし、最悪の場合は取り返しのつかないダメージを与えることにもなるでしょう。
そして、このようないい加減なデータに踊らされる、いわゆる私達がデータ・ドリブンと呼んでいるものですが、こうした形で意思決定をしたり、アクションを起こしたりしていると、データ分析そのものに対する信用が失われていきます。
それではせっかくのデータを使ってビジネスを改善させていこうという取り組みに対する熱気が一気に冷めてしまいかねません。
そして、このことがさらなる問題に繋がるのですが、世界には(もちろん日本にも)データを使って実際にビジネスを成長させていっている企業やスタートアップがあるという事実です。シリコンバレーであればGoogle、Facebook、Netflix、Slack、Airbnbなどときりがありません。
こうしたデータリテラシーの高い企業は、データの活用に失敗している会社を横目にさらにデータを使ってより最適な成長を遂げていきます。
これが「データリテラシーが低いと3度痛い」と言うやつです。
- 1度目はデータドリブンに意思決定してしまうことで火傷する。もしくは全く成果が出ないので投資に対するリターンが生まれない。
- 2度目は「データを使ってビジネスを改善する文化」を作り損なってしまったことでビジネスの改善のチャンスを失う。
- 3度目は自分たちのデータリテラシーは低いままなので、データリテラシーの高い競争相手に負けてしまう。
データに踊らされるデータ・ドリブンな意思決定でなく、データから得られたインサイトをその背景や限界を理解した上で活用するデータ・インフォームドな意思決定を行っていくには、最低限のデータリテラシーが要求されます。
これが例えば、Netflixなどではプロダクトやサービスを作る部門でリーダーとなるポジションにつくには統計学の修士レベルの知識が要求されると言う理由です。
データリテラシーを武器にしてフェイクニュースを打ち破る
現在のようにインターネットやソーシャルネットワークの上で個人が情報を得ていく世界では、私達個人がその情報の信頼性を見抜くことを求められています。
昔のように新聞に書かれてある字を読んで理解していればよかったという時代から、現在のように数多くのニュースソースから正しい情報をつかむためにその中で使われているデータを理解し正しい質問を行うことでさらに自分で情報を追い求めていくことが求めらる時代へと変化していっています。
このことがこれまで以上にわれわれ市民は誰であれ最低限のデータリテラシーを持つことが求められていると思う理由です。
より良い社会を作っていくための責任ある市民として、もはやデータリテラシーは「読み書き」と並んで全ての人にとって最低限欠かせない教養であると強く思います。
データサイエンス・ブートキャンプ、1月開催!

次回のデータサイエンス・ブートキャンプは来年1月末です!
データサイエンスやデータ分析の手法を1から体系的に学び、現場で使えるレベルのスキルを身につけていただくためのトレーニングです。
またデータやデータサイエンスの手法を使ってビジネスの問題を解決していくための、質問や仮説の構築の仕方などを含めたデータリテラシーも基礎から身につけていただくものとなっております。
ぜひこの機会に参加をご検討ください!
詳細はこちらのページにあります。