背景
生成AI周りの技術は急速に進歩しており、数ヶ月後には陳腐化してしまう情報が多く、追うのが大変だなあと感じてます。
ChatGPTを始めとするLLM(大規模言語モデル)は、テキストのみならず音声・画像等のインプット・アウトプットが可能であり、それを利用したサービスも急速に開発され続けていることから、技術の発展と並行して ”活用方法” についても日々試行錯誤されているように思います。
そんな中、レイトマジョリティになりがちな私が簡単なLLMアプリを開発したいと思い、GWを活用して 「RAGを利用した、NotionにLLMとの会話履歴を保存できるLLMアプリ」 を開発してみました。
あくまで、多くの方の記事を参考に、所々オリジナリティを持たせてやってみた的な温度感ですが、興味があれば手元で動かしていただきたいと思い、ハンズオン形式としました。
気軽に読んで下さい。
対象読者
「初学者の方向け」です。
- RAGって何?
- LangChainってなんだ?
という方向けの記事となります。
また、特定のクラウドAIサービスを利用することも検討しましたが、その場合、利用したサービスに特化したコードを記述するため、まずはRAGのコア部分を理解したいなと思い、特定のクラウドAIサービスを敢えて利用しない方針で開発しました。
私と同じ初学者の方に向けての投稿ですが、是非有識者の方には、記載内容に誤りがございましたら遠慮なくご指摘いただけますと幸いです。
私も未だ学習中のため、より深い理解に繋げられればと思います。
前提知識
本アプリで実装されている機能を理解するために、必要な前提知識は以下3つとなります。既にご存知の方は、この後のRAGアプリケーション全体像から読んでいただければと思います。
1. RAG
RAG(Retrieval-Augmented Generation, 検索拡張生成)という言葉は、Meta社のFAIR(Facebook AI Research)が2020年の論文で発表しました。
RAGを簡単に説明すると、LLMが回答を生成する際、ユーザの質問に加えて、その質問に関連する特定の知識や最新の情報源(例えば、最新の情報が記載されたPDFやWebページなど)から検索し、ユーザの質問と検索された関連情報を組み合わせてLLMに質問し回答を生成させる技術です。
より分かり易くするために、本アプリを例に説明します。
このアプリのデモ動画では、特に何も情報を与えていないChatGPTに対して2024年6月から開始する「定額減税」について質問しています。
gpt-3.5の学習データは、投稿時点で2021年9月までのデータであるため、GPTに定額減税について質問しても、彼は正しそうなウソ(Hallucination)をつくか、分からないと回答します。
ですが、事前に定額減税に関する政府のガイドラインが記載されたPDF等をデータセットとして用意しておき、その上で「定額減税はいつから開始する?」と質問すると、その質問に関連するドキュメントをデータセットから検索し、ユーザの質問と関連ドキュメントを合わせてGPTに質問し、回答を生成させます。
これにより、LLMが学習していないリアルタイムで更新される情報源から回答を生成させるといったことが可能になります。
最新情報から回答を生成させること以外にも、社外秘の文書や社内のアセットをデータセットとして用意し、コールセンターなどの自動化に活用したユースケースもあり、実務でも利用されています。
ちなみに、私は当初RAGとファインチューニングの違いが分かりませんでした。もし同じ疑問を持たれた方は、こちらの記事がとても参考になるかと思います。
LLMアプリケーション構築における2つのアプローチ「RAG」と「Fine-tuning」を比較した論文(RAG VS FINE-TUNING: PIPELINES, TRADEOFFS, AND A CASE
STUDY ON AGRICULTURE)を分かりやすく解説している記事です。
2. LangChain
LangChainとは、LLMの機能拡張を効率的に実装するためのライブラリです。
PythonとJavaScript、TypeScriptで利用可能ですが、以下の画像の通りPythonで利用すると全ての機能を利用できるため、本アプリでもPythonを使用しました。(とはいえ機能が多すぎるので、本アプリでは一部の機能を利用してます)

3. FAISS (Facebook AI Similarity Search)
RAGの説明でもありましたが、検索させたいデータセットを事前に用意しておく必要があるのですが、そのデータセットは基本的にベクターデータベース(VectorDB)というデータベースに格納しておきます。
VectorDBは数多くの種類があり、例としてPinecorn、Qdrantなどがありますが、FAISSはOSSであり機能が豊富なため、本アプリで利用しました(正確には、FAISSはデータベースではなくライブラリです)。
アップロードしたPDFのテキストをOpenAI社のEmbeddingモデル等でベクトル化し(Embeddingと言います)、VectorDBに格納しておきます。その後ユーザからの質問もベクトル化し、質問と格納されたドキュメントの類似度を計算し、関連情報を抜き出します。
この「データの格納」、「類似度の計算」部分をFAISSが担います。
以下は多数の図解を元にEmbedding、VectorDBについて整理された参考記事です。初学者の私にとって、分かり易い図解によってイメージをつかめたオススメ記事でしたので載せておきます。
RAGアプリケーション全体像
本題です。ハンズオンの前に、本アプリの全体像を説明します。
まず、ローカルPCで動かすと以下のような挙動になります。UI部分は、Streamlitを利用しております。Streamlitとは、Pythonで実装されたオープンソースのWebアプリケーションフレームワークです。
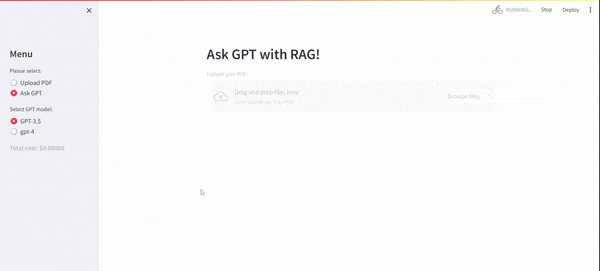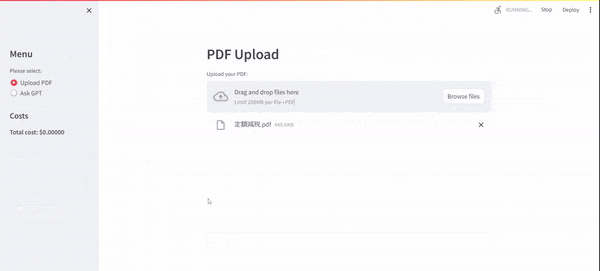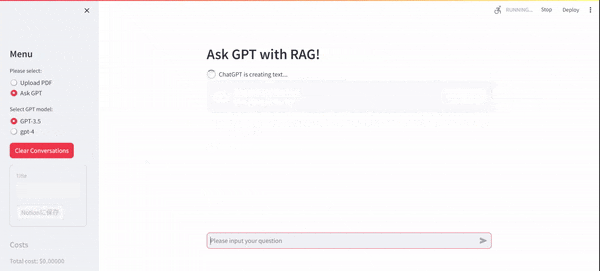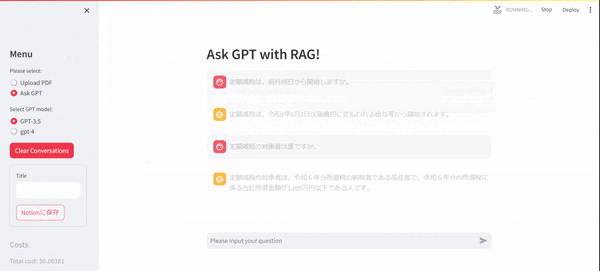
ソースコードも先に載せておきます。コメントで説明を加えたつもりですが、本投稿の後半でもゆるく説明します。
ソースコード
import os
from dotenv import load_dotenv
import requests
import datetime
import streamlit as st
from langchain_openai import ChatOpenAI
from langchain.callbacks import get_openai_callback
from langchain_core.prompts import PromptTemplate
import pprint
from pypdf import PdfReader
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chains.retrieval_qa.base import RetrievalQA
from langchain.schema import ( SystemMessage, HumanMessage, AIMessage)
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
NOTION_API_TOKEN = os.getenv("NOTION_API_TOKEN")
os.environ["LANGCHAIN_TRACING_V2"] = "True"
embedding_model = OpenAIEmbeddings(model="text-embedding-3-large")
# ページ全体の初期設定
def page_init_settings():
st.set_page_config(
# ページのタイトル
page_title="RAG Application",
)
# サイドバーのタイトル
st.sidebar.title("Menu")
# サイドバーにLLM利用に掛かったコストを表示するためのリスト
st.session_state.costs = []
# pdfアップロード画面の定義
def pdf_to_vector():
st.header("PDF Upload")
# アップローダー設定
with st.container():
pdf_text = get_pdf_contexts()
if pdf_text:
with st.spinner("Loading PDF ..."):
# PDFのテキストをEmbeddingしFAISSに格納
create_faiss(pdf_text)
# LLMに質問する画面
def page_query_gpt():
st.header("Ask GPT with RAG!")
# GPTモデルを指定する
llm = select_gpt_model()
# "Clear Conversations"ボタンが押されたら、会話履歴をリセットする
if st.sidebar.button("Clear Conversations", type="primary"):
st.session_state.messages = []
# ユーザーの入力を監視
if query:=st.chat_input("Please input your question"):
# 会話履歴のステートが存在しない、もしくはNoneの場合にSystemMessageを加える
if "messages" not in st.session_state or not st.session_state.messages:
st.session_state.messages = [
SystemMessage(content="You are a helpful assistant.")
]
qa = qa_model(llm)
if qa:
with st.spinner("ChatGPT is creating text..."):
answer, cost = ask_by_user(qa, query)
st.session_state.costs.append(cost)
# ユーザの入力を監視
st.session_state.messages.append(HumanMessage(content=query))
st.session_state.messages.append(AIMessage(content=answer["result"]))
# 会話履歴をコンソールに出力
pprint.pprint(st.session_state.messages)
# ソースとなったドキュメントをコンソールに出力
pprint.pprint(answer["source_documents"])
# 会話履歴を画面に表示
messages = st.session_state.get('messages', [])
for message in messages:
if isinstance(message, AIMessage):
with st.chat_message('assistant'):
st.markdown(message.content)
elif isinstance(message, HumanMessage):
with st.chat_message('user'):
st.markdown(message.content)
else:
answer = None
# Notionページを追加するサイドバー内のフォーム
with st.sidebar.form("notion_add", clear_on_submit=True):
title = st.text_input('Title')
submitted = st.form_submit_button("Notionに保存")
# Notionページに入力する会話履歴の取得
if submitted:
messages = st.session_state.get('messages', [])
# 会話履歴をリストに格納する
notion_contents = []
for message in messages:
if isinstance(message, HumanMessage):
human_message=message.content
notion_contents.append(f"あなた: {human_message}")
elif isinstance(message, AIMessage):
ai_message=message.content
notion_contents.append(f"GPT: {ai_message}")
notion_add(notion_contents, title)
# 利用するGPTモデルを指定し、最大トークン数をチェックする関数
def select_gpt_model():
with st.sidebar:
selection = st.radio(
"Select GPT model:",
("gpt-3.5", "gpt-4")
)
if selection == "GPT-3.5":
st.session_state.model_name = "gpt-3.5-turbo"
elif selection == "gpt-4":
st.session_state.model_name = "gpt-4"
return ChatOpenAI(temperature=0, openai_api_key=OPENAI_API_KEY, model=st.session_state.model_name)
# PDFファイルの内容を分割する関数
def get_pdf_contexts():
# streamlitのファイルアップローダー設定
uploaded_files = st.file_uploader(
label="Upload your PDF:",
type="pdf",
accept_multiple_files=True
)
# PDFがアップロードされた時、PDFのテキストを処理する
if uploaded_files:
# PdfReaderでUploadしたPDFのテキストを読み取る
for f in uploaded_files:
pdf_reader = PdfReader(f)
# テキストを改行文字で連結し、一つの文字列にする
texts = '\n\n'.join([page.extract_text() for page in pdf_reader.pages])
# テキストをチャンクに分割する定義
# chunk_size=500 は、各チャンクのサイズが500文字になるようにテキストを分割する
# chunk_overlap=0 は、各チャンク同士で重複する部分を持たないことを意味する
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=500,
chunk_overlap=0
)
# 読み取ったテキストをチャンクに分割する
text = text_splitter.split_text(texts)
return text
# PDFがアップロードされていない場合は何も返さない
else:
return None
# FAISSにEmbeddingしたテキストを保存、Index化しローカルストレージに格納する
def create_faiss(texts):
# FAISSにOpenAIのembedding modelを使ってEmbeddingする
db = FAISS.from_texts(texts=texts, embedding=embedding_model)
# ローカルストレージにfaiss_dbというディレクトリを作成し、Embeddingデータ(index.faiss, index.pkl)を格納する
db.save_local("./faiss_db", index_name="index")
# RetrievalQAにより、ユーザの質問とアップロードしたPDFの内容を組み合わせてLLMに質問する
def qa_model(llm):
prompt_template = """あなたは分からないことは分からないと伝え、分かることは初心者でも分かるように分かりやすく回答してくれるアシスタントです。
丁寧に日本語で答えてください。
もし以下の情報が、探している情報に関連していない場合、そのトピックに関する自身の知識を元に回答してください。
{context}
質問: {question}
回答(日本語): """
prompt_qa = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": prompt_qa}
load_db = FAISS.load_local(
"./faiss_db",
allow_dangerous_deserialization=True,
index_name="index",
embeddings=embedding_model
)
retriever = load_db.as_retriever(
# indexから検索結果を何個取得するか指定
search_kwargs = {"k":4}
)
#
return RetrievalQA.from_chain_type(
llm = llm,
chain_type = "stuff",
retriever = retriever,
# RetrievalQAがどのチャンクデータを取ってきたのかを確認するために、return_source_documentをTrueにする。
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs,
verbose = True
)
# ユーザの質問に対する回答を返す
def ask_by_user(qa, query):
try:
with get_openai_callback() as cb:
answer = qa({"query": query})
return answer, cb.total_cost
except Exception as e:
print(f"An error occured: {e}")
return None, 0
# Notionにテキストとタイトルが記載されたページを作成する
def notion_add(contents, title):
today = datetime.date.today()
title = title
created_iso_format = today.isoformat()
NOTION_API_TOKEN = os.getenv('NOTION_API_TOKEN')
# ページを作成するNotionデータベースを指定する
data_base_id = '84b10ff627df419d9c5083b914d90eb9'
content = "\n".join(contents)
url = 'https://api.notion.com/v1/pages'
headers = {
"Accept": "application/json",
"Notion-Version": "2022-06-28",
"Content-Type": "application/json",
"Authorization": f"Bearer {NOTION_API_TOKEN}"
}
payload = {
"parent": {
"database_id": data_base_id
},
"properties": {
"Name": {
"title": [
{
"text": {
"content": title
}
}
],
},
"Created at": {
"type": "date",
"date": {
"start": created_iso_format
}
},
},
"children": [
{
"type": "paragraph",
"paragraph": {
"rich_text": [
{
"type": "text",
"text": {
"content": content,
}
}
],
"color": "default"
}
},
],
}
response = requests.post(url, json=payload, headers=headers)
response.json()
#result_dict = response.json()
#print(result_dict)
def main():
page_init_settings()
with st.sidebar:
selection = st.radio(
"Please select:",
("Upload PDF", "Ask GPT")
)
if selection == "Upload PDF":
pdf_to_vector()
else:
page_query_gpt()
costs = st.session_state.get('costs', [])
st.sidebar.markdown("## Costs")
# st.session_state.costsリスト内の全てのコストを計算し、小数点以下5桁までの浮動小数点数で表示
st.sidebar.markdown(f"**Total cost: ${sum(costs):.5f}**")
# st.session_state.costsリスト内の各コストに対してループを行い、各コストを表示する。小数点以下5桁までの浮動小数点数で表示
for cost in costs:
st.sidebar.markdown(f"- ${cost:.5f}")
if __name__ == "__main__":
main()
サイドバーに2つラジオボタンがあり、それぞれ選択することで画面遷移します。各ラジオボタンは、
- Upload PDF → GPTに検索させたい情報が記載されたPDFをアップロードする画面
- Ask GPT → GPTと会話する画面
となっております。
Ask GPTの画面でGPTと会話をした後、会話履歴を保存しておきたい場合、サイドバーのフォームにタイトルを入力し「Notionに保存」ボタンを押すと、以下のように会話履歴が記載されたNotionページが出来上がります。

 処理フロー図
処理フロー図
全体のフローを図示したものが以下となります。

フローは、全12ステップとなります。
- 最新情報や社内文書等、GPTが学習していないデータが記載されたPDFをアップロードする
- PDFのテキストをチャンクに分割する(TextSplitter)
- 分割したテキストをOpenAI EmbeddingモデルによってEmbeddingする
- EmbeddingしたデータをFAISSを利用してインデックス化し保存する
- ユーザが質問する
- RetrievalQAが、ユーザの質問をOpenAI EmbeddingモデルにEmbeddingのリクエストを送る
- Embeddingしたデータを受け取る
- 受け取ったデータを元に、FAISSでベクトル化されたデータと類似度を計算し類似ドキュメントを検索する(Similarity Search)
- ユーザの質問とFAISSから受け取ったデータを組み合わせ、GPTに質問するプロンプトを作成する
- GPTにプロンプトを投げる
- GPTから回答を受け取り、UIに表示させる
- 会話履歴を保存したければ、会話のタイトルを入力し、Notionに保存する
それではハンズオンを開始します。ハンズオンの流れは、
1. 事前準備
2. GitHubからリポジトリをclone
3. .envファイル作成
4. requirements.txtを利用してパッケージインストール
5. ソースコード内のNotion Database IDの設定
6. 稼働確認
です。よろしくお願いいたします。
1. 事前準備 (OpenAI API/Notion APIの準備)
OpenAI API、Notion APIのAPI Keyを既にお持ちの方は、事前準備はスキップ可能です。
※NotionAPIをお持ちの方でも、会話履歴の保存先となるNotionデータベースを作成する必要があります。このデータベースとNotionAPIを連携させる必要がありますので、②は実施ください。
OpenAI APIを利用すると、数ドル程度の利用料金が掛かります。
(ちなみに私はテストのために沢山利用したつもりですが、$0.5程度でした。ご利用は計画的に。)
① 【OpenAI API】API Key作成
OpenAI APIのAPI Keyの作成方法については、以下記事の前半部分をご参照ください。
② 【Notion API】API Key作成、Notionデータベース作成
NotionAPIの事前準備は、以下の記事が参考になるかと思います。Notion自体が初めての方は、Notionのアカウント作成をした後、こちらの手順を実施いただければと思います。
本アプリの会話履歴を保存するボタン「Notionに保存」を押下すると、Notionの「データベース」に「ページ」が追加されるようになっております。そのために、データベースのプロパティ(カラム)は以下の画像を参考に作成頂けますと幸いです。

2. GitHubからリポジトリをClone
ローカルPCの適当な場所で、以下コマンドを実行しリポジトリをクローンしてください。
git clone https://github.com/Kamy-dev/llm_app_basics.git
3. .envファイル作成
正常にcloneできましたら、フォルダ内に「.env」という名前のファイルを作成してください。.envファイルに事前準備で作成したAPI Keyを設定することで、ソースコード内で正常に呼び出されます。
以下のように設定してください。
OPENAI_API_KEY=あなたのOpenAI API Key
NOTION_API_TOKEN=あなたのNotion API Key
4. requirements.txtを利用してパッケージインストール
requirements.txtにアプリで利用するパッケージが記載されておりますので、こちらを利用してパッケージのインストールをします。
以下の手順で実施ください。
① プロジェクト直下にpython仮想環境作成
ローカルPCの環境要因でのエラーを避けるために、仮想環境を作成してください。ターミナルでプロジェクト直下に移動し、以下コマンドを実行します。
python -m venv .venv
プロジェクトのフォルダに「.venv」というディレクトリが作成されましたらOKです。次にActivateします。
.\.venv\Scripts\activate
実行後、以下のようにプロンプトの左側に「(.venv)」と表示されればOKです。この状態でパッケージのインストールを行います。
(.venv) \path\to\llm_app_basics>
② requirements.txtを利用してパッケージのインストール
プロンプトの左側に「(.venv)」と表示されている状態で、以下コマンドを実行ください。
pip install -r requirements.txt
ちょっと時間が掛かるかと思います。正常に完了すれば環境準備完了です。
5. ソースコード内のNotion Database IDの設定
あと一息です。
ソースコードのnotion_add関数にて、data_base_idという変数があります。こちらにご自身で作成したNotionデータベースのIDを指定します。
データベースIDは、作成したNotionデータベースのページを開くと、URLがhttps://www.notion.so/{userName}/{databaseID}?v={viewID}となっておりますので、このdatabaseIDをコピーしてコードを修正してください。

お疲れ様でした。
全ての準備が完了した後のディレクトリ構成は以下となります。ご確認ください。
llm_app_basics/
├ .venv/
├ rag_app/
│ └ rag_app.py
│
└ .env
6. 稼働確認
ターミナルを開き、プロジェクトのディレクトリに移動し、以下コマンドを実行するとアプリが立ち上がります。
streamlit run <rag_app.pyのパス>
ブラウザが立ち上がりましたら、試しにPDFをアップロードしてみてください。FAISSによって、「faiss_db」というディレクトリが作成され、index.faiss、index.pklというファイルが作成されると思います。
index.faissはEmbeddingのベクトルの情報、index.pklはdocstoreとEmbeddingのベクトルとdocstoreのidの対応を管理する情報(index_to_docstore_id)が保存されていることがわかります。
アップロード後、Ask GPT画面で質問をすると関連する情報について検索した結果を踏まえて回答してくれます。コンソール上でもドキュメントのどの部分を参照して回答を作成したのかが分かるのでぜひ確認してみてください。
各コードの説明
ここからは、処理フロー図で説明したステップに沿って、対応するソースコードと照らし合わせながら説明いたします。
【1~4】 PDFアップロード → FAISSでベクトルデータをローカルに保存
アップロード画面はpdf_to_vector関数で定義されております。PDFをアップロードすると、get_pdf_contexts関数が実行され、LangChainのtext_splitterの一つ、RecursiveCharacterTextSplitterメソッドを使い、PDFのドキュメントをチャンクに分割します。
from_tiktoken_encoderメソッドでchunk_sizeを500に設定しましたが、目的によって適切な数値を指定することで検索性能を向上させることに繋がります。こちらの記事では「チャンキング戦略」と題して、チャンクサイズの決定方法について分かりやすく説明しています。
# pdfアップロード画面の定義
def pdf_to_vector():
st.header("PDF Upload")
# アップローダー設定
with st.container():
pdf_text = get_pdf_contexts()
if pdf_text:
with st.spinner("Loading PDF ..."):
# PDFのテキストをEmbeddingしFAISSに格納
create_faiss(pdf_text)
(中略)
# PDFファイルの内容を分割する関数
def get_pdf_contexts():
# streamlitのファイルアップローダー設定
uploaded_files = st.file_uploader(
label="Upload your PDF:",
type="pdf",
accept_multiple_files=True
)
# PDFがアップロードされた時、PDFのテキストを処理する
if uploaded_files:
# PdfReaderでUploadしたPDFのテキストを読み取る
for f in uploaded_files:
pdf_reader = PdfReader(f)
# テキストを改行文字で連結し、一つの文字列にする
texts = '\n\n'.join([page.extract_text() for page in pdf_reader.pages])
# テキストをチャンクに分割する定義
# chunk_size=500 は、各チャンクのサイズが500文字になるようにテキストを分割する
# chunk_overlap=0 は、各チャンク同士で重複する部分を持たないことを意味する
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=500,
chunk_overlap=0
)
# 読み取ったテキストをチャンクに分割する
text = text_splitter.split_text(texts)
return text
# PDFがアップロードされていない場合は何も返さない
else:
return None
分割したチャンクをOpenAI Embeddingモデルでベクトル化する処理が、create_faissです。
# FAISSにEmbeddingしたテキストを保存、Index化しローカルストレージに格納する
def create_faiss(texts):
# FAISSにOpenAIのembedding modelを使ってEmbeddingする
db = FAISS.from_texts(texts=texts, embedding=embedding_model)
# ローカルストレージにfaiss_dbというディレクトリを作成し、Embeddingデータ(index.faiss, index.pkl)を格納する
db.save_local("./faiss_db", index_name="index")
ここまでで、RAGの事前準備とも言える、LLMが学習していない最新情報をベクトル化し保存するところまで完了しました。
【5~11】ユーザが質問 → Similarity Search(類似性検索) → RetrievalQAがGPTに質問
GPTに質問する画面は、page_query_gpt関数で定義されております。select_gpt_model関数にて、gpt-3.5かgpt-4を使うか、サイドバーのラジオボタンで設定するようになってます。
# LLMに質問する画面
def page_query_gpt():
st.header("Ask GPT with RAG!")
# GPTモデルを指定する
llm = select_gpt_model()
(中略)
# 利用するGPTモデルを指定し、最大トークン数をチェックする関数
def select_gpt_model():
with st.sidebar:
selection = st.radio(
"Select GPT model:",
("gpt-3.5", "gpt-4")
)
if selection == "GPT-3.5":
st.session_state.model_name = "gpt-3.5-turbo"
elif selection == "gpt-4":
st.session_state.model_name = "gpt-4"
return ChatOpenAI(temperature=0, openai_api_key=OPENAI_API_KEY, model=st.session_state.model_name)
以下のst.chat_inputメソッドで、ユーザからの質問の入力を監視しています。入力を受け取った場合、st.session_stateメソッドが実行されますが、これはセッション内で辞書形式でステートを保存することができる機能で、本アプリでの会話履歴はこのステート機能で保持しております。
OpenAIのAPIはステートレスであるため、リクエストに含まれるテキスト以外の情報は持ちません。そのため、毎回リクエストの度に過去の全履歴を送信する必要があります。
def page_query_gpt():
---(中略)---
# ユーザーの入力を監視
if query:=st.chat_input("Please input your question"):
# 会話履歴のステートが存在しない、もしくはNoneの場合にSystemMessageを加える
if "messages" not in st.session_state or not st.session_state.messages:
st.session_state.messages = [
SystemMessage(content="You are a helpful assistant.")
]
ユーザの質問を受け取り、qa_model関数が実行されます。
qa_model関数では、最終的にGPTに送るプロンプトをLangChainのPromptTemplateメソッドを使用して設定しています。これにより、自分の目的に合わせて最適なプロンプトを設定することが可能です。プロンプトエンジニアリングの一端を体感できます。
私の場合、分からないことは分からないと言ってもらうようにしました。これにより、「定額減税」について情報を持っていないGPTに質問しても、「分かりません」と言ってもらいます。
qa_model関数によって、LangChainのRetrievalQAが動きます。再掲ですが、RetrievalQAは以下の処理を行ってます。

最後にask_by_user関数にて、ユーザからの質問(query)に対する回答をanswerとして返します。
ユーザからの質問(query)をsession_state.messagesのHumanMessageとして格納し、GPTの回答(answer["result"])をAIMessageとして格納することで、会話履歴を保存しています。
def page_query_gpt():
---(中略)---
qa = qa_model(llm)
if qa:
with st.spinner("ChatGPT is creating text..."):
answer, cost = ask_by_user(qa, query)
st.session_state.costs.append(cost)
# ユーザの入力を監視
st.session_state.messages.append(HumanMessage(content=query))
st.session_state.messages.append(AIMessage(content=answer["result"]))
# 会話履歴をコンソールに出力
pprint.pprint(st.session_state.messages)
# ソースとなったドキュメントをコンソールに出力
pprint.pprint(answer["source_documents"])
# 会話履歴を画面に表示
messages = st.session_state.get('messages', [])
for message in messages:
if isinstance(message, AIMessage):
with st.chat_message('assistant'):
st.markdown(message.content)
elif isinstance(message, HumanMessage):
with st.chat_message('user'):
st.markdown(message.content)
else:
answer = None
# RetrievalQAにより、ユーザの質問とアップロードしたPDFの内容を組み合わせてLLMに質問する
def qa_model(llm):
prompt_template = """あなたは分からないことは分からないと伝え、分かることは初心者でも分かるように分かりやすく回答してくれるアシスタントです。
丁寧に日本語で答えてください。
もし以下の情報が、探している情報に関連していない場合、そのトピックに関する自身の知識を元に回答してください。
{context}
質問: {question}
回答(日本語): """
prompt_qa = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": prompt_qa}
load_db = FAISS.load_local(
"./faiss_db",
allow_dangerous_deserialization=True,
index_name="index",
embeddings=embedding_model
)
retriever = load_db.as_retriever(
# indexから検索結果を何個取得するか指定
search_kwargs = {"k":4}
)
return RetrievalQA.from_chain_type(
llm = llm,
chain_type = "stuff",
retriever = retriever,
# RetrievalQAがどのチャンクデータを取ってきたのかを確認するために、return_source_documentをTrueにする。
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs,
verbose = True
)
# ユーザの質問に対する回答を返す
def ask_by_user(qa, query):
try:
with get_openai_callback() as cb:
answer = qa({"query": query})
return answer, cb.total_cost
except Exception as e:
print(f"An error occured: {e}")
return None, 0
【12】会話履歴をNotionに保存
会話履歴をNotionに保存する処理は、以下の部分となります。
サイドバーにst.sidebar.formメソッドで、Notionに保存するページのタイトルを入力するフォームを作成してます。
「Notionに保存」ボタンが実行されると、st.session_state.messagesのHumanMessageとAIMessageのそれぞれに対してHumanMessageには「あなた:」、AIMessageには「GPT:」を行頭に付与します。
そうして取得した会話履歴をnotion_contentsリストに格納し、最終的にnotion_add関数でNotion APIのエンドポイントにPOSTリクエストを送信することで、Notionに会話履歴が記載されたページが作成されます。
def page_query_gpt():
---(中略)---
# Notionページを追加するサイドバー内のフォーム
with st.sidebar.form("notion_add", clear_on_submit=True):
title = st.text_input('Title')
submitted = st.form_submit_button("Notionに保存")
# Notionページに入力する会話履歴の取得
if submitted:
messages = st.session_state.get('messages', [])
# 会話履歴をリストに格納する
notion_contents = []
for message in messages:
if isinstance(message, HumanMessage):
human_message=message.content
notion_contents.append(f"あなた: {human_message}")
elif isinstance(message, AIMessage):
ai_message=message.content
notion_contents.append(f"GPT: {ai_message}")
notion_add(notion_contents, title)
(中略)
# Notionにテキストとタイトルが記載されたページを作成する
def notion_add(contents, title):
today = datetime.date.today()
title = title
created_iso_format = today.isoformat()
NOTION_API_TOKEN = os.getenv('NOTION_API_TOKEN')
# ページを作成するNotionデータベースを指定する
data_base_id = 'Your Notion Database ID'
content = "\n".join(contents)
url = 'https://api.notion.com/v1/pages'
headers = {
"Accept": "application/json",
"Notion-Version": "2022-06-28",
"Content-Type": "application/json",
"Authorization": f"Bearer {NOTION_API_TOKEN}"
}
payload = {
"parent": {
"database_id": data_base_id
},
"properties": {
"Name": {
"title": [
{
"text": {
"content": title
}
}
],
},
"Created at": {
"type": "date",
"date": {
"start": created_iso_format
}
},
},
"children": [
{
"type": "paragraph",
"paragraph": {
"rich_text": [
{
"type": "text",
"text": {
"content": content,
}
}
],
"color": "default"
}
},
],
}
response = requests.post(url, json=payload, headers=headers)
response.json()
まとめ
いかがでしたでしょうか。初学者向けでしたが、動かしながらRAGの全体像を少し理解できたという方がいらっしゃいましたら大変うれしく思います。
個人的には、学習目的でサラッと概要を把握したいドキュメントなどをアップロードして、GPTとの会話をしてNotionに保存しておき、後で見返したりして活用してます。
後学としては、本アプリに実装されていないLangChainの機能を追加いただいたり、会話履歴をStreamlitのsession_stateではなく、DynamoDB等を使って会話履歴を保存したりするなど、自分なりにカスタマイズして遊んでいただけますと幸いです。
今度は、クラウドAIサービスを利用したLLMアプリを開発していきたいと思います。