はじめに
- 本記事では、Document Understanding の抽出器で取得したデータの操作テクニックなどを紹介します。読者の方は Studio 開発の中級者以上を想定しています。前提知識の補足等は記載しないため、初学者の方にはわかりにくいかもしれませんがご容赦ください。
- 記事の内容は、個人の見解または確認結果であり、UiPath の公式見解ではありません。
- 製品仕様や参考画像は 23.4 バージョンで構成しています。
DU開発Tips ~ 抽出・データ操作編 ~
# 1)半角スペースの除去
# 2)ズーム率の違いは元画像をサイズ変更
# 3)表示位置の誤差はアンカーで対処
# 4)OCR信頼度の確認
# 5) 特定条件下でのテンプレート分け
半角スペースの除去

OCRの日本語読み取りは、CJK-OCRも単語認識がまだできません。漢字・ひらがな・カタカナ、いずれも1文字ずつ認識して、半角スペース込みで返してきます。
UiPath ではワークフローの処理の中で値操作が簡単にできるので、アウトプットに対して半角スペースを除去するのは朝飯前なのですが、この除去するタイミングは人間が確認する前がいいですよね。
なので、以下に検証バリデーションを表示する前に抽出データを操作するテクニックを記載します↓↓
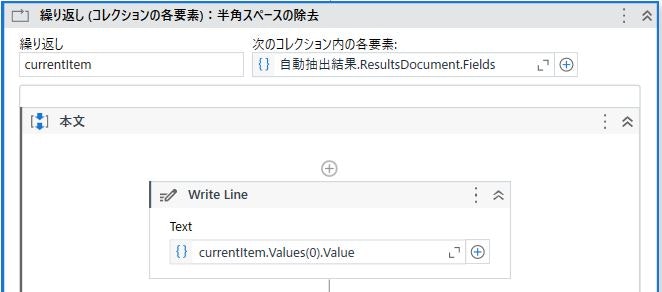

繰り返し(コレクションの各要素)を配置し、入力に 「自動抽出結果.ResultsDocument.Fields」 を指定、データ型に 「UiPath.DocumentProcessing.Contracts.Results.ResultsDataPoint」 を指定します。
代入を配置し、左辺に 「currentItem.Values(0).Value」 、右辺に 「currentItem.Values(0).Value.ToString.Replace(" ","")」 を指定します。
なお、キャプチャの例では 「currentItem.FieldName = "自由記述欄"」 と記述することで半角スペースを除去する項目を絞っています。
こうするだけで、検証バリデーションに半角スペース除去済みの値を表示することができます。↓↓↓


ズーム率の違いは元画像をサイズ変更

同じドキュメントも、異なるズーム倍率で画像化された場合、画像データの縦横の Pixel(ピクセル)が変わります。(上のキャプチャは、「はい」「いいえ」のチェック欄の左斜め下に読み取り領域がズレているのを示す例です。)
フォーム抽出器でカスタム領域を指定した場合、 Pixel ベースの座標データで設定を保持するため、 サイズが異なると読み取る位置も変わってしまいます。
単純にキャプチャする位置が少し違うだけであれば後述のアンカーを指定してあげれば値抽出できますが、表示倍率が違うので、読み取り範囲が大きすぎたり小さすぎるなどの問題が発生します。
そこで、前処理として画像データの縮尺を整えるサンプルコードを以下に↓↓

引数は「pathImage(文字列型の入力引数)」「thumbnailWidth(整数型の入力引数)」「returnImage(Image型の出力引数)」の3つ用意し、「コードを呼び出し」アクティビティでVBのコードを記述します。

'画像ファイルを読み込んで、Bitmapオブジェクトを作成
Dim bmp As New Bitmap(pathImage)
'画像の縮尺率を計算
Dim scale = CType(thumbnailWidth / bmp.Width, Double)
Dim w = thumbnailWidth
Dim h = CType(bmp.Height * scale, Integer)
'bmpを任意幅に縮小したBitmapオブジェクトを作成
Dim small As New Bitmap(bmp,w,h)
'出力引数に small を代入
returnImage = small
表示位置の誤差はアンカーで対処
画像データの場合、起点が上下左右で多少ズレることがありますよね。
カスタム領域でクリッピング領域を指定する場合、画像サイズや表示位置のズレは考慮されません。
このため、PDFではない画像データからの読み取りをフォーム抽出器でおこなう場合などは アンカー
で設定することをお勧めします。


最初に選択する青枠の領域がターゲットで、次に指定する緑枠の領域がアンカー項目です。Ctrlキーを押しながら複数の文字を選択できます。アンカーが一意となるよう指定しましょう。
OCR信頼度の確認

「自動抽出結果.Serialize」 と記述することで、抽出結果から信頼度の情報を出力することができます。
(自動抽出結果.ResultsDocument.Field で繰り返し(コレクションの各要素)> item.Value(0).Confidence からも出力可)
この信頼度(抽出結果の信頼度)は、設定したルールや、UiPath の各抽出器のロジック(公式ガイドで説明がない)が影響するため、どうしても 信頼度と結果がミスマッチするケース は発生します。
このため、抽出器の信頼度(Confidence)をもとにし自動処理は組みにくいのが実情かとおもいますが、 「OCRの信頼度」 についてはルールがシンプルなため利用しやすいのでは?とおもいます。
フィールド名は 「OcrConfidence」 です。
「OcrConfidence」 は事前定義された文字と光学認識文字のマッチング度合いでしかないため、読みやすい一般的な文字であれば信頼度はおよそ 98% を超えてきます。つぶれた文字や特殊文字などで、人間でも読み間違える可能性のある文字だと相応に信頼度が低くなるため、確認対象を選り分ける際の参考値としては有効ではないかと考えます。
抽出結果の ResultsTableValue クラスの仕様は以下で確認できます。
https://docs.uipath.com/ja/activities/other/latest/document-understanding/229-resultstablevalue-class

特定条件下でのテンプレート分け
署名フィールドのオプションをつけても、マシンラーニングでも、何故か期待結果を得られないケースもあるかとおもいます。
期待結果を得られないのが、特定項目やとある条件下だけといったケースであれば、前述の半角スペース除去と同様に 取得値を確認して抽出方法を変える のもご検討ください。
例えば、とある項目だけ☑の結果が毎回期待値と異なる場合、あえて文字列として抽出するフォームを利用しワークフロー内で独自で判定する等。

抽出対象のドキュメント種類は直接指定が可能です。(黄色でマーカーした「ドキュメントの種類のID」を指定)

「ドキュメントの種類のID」は タクソノミーマネジャーのドキュメントの種類名の右隣に表示されている値 です。

おわりに
いかがでしたでしょうか。読んでいただいた方が少しでも使えそうなネタであったなら幸いです。
最新の 23.4 バージョンでは、 タクソノミーマネジャーで項目ベースの値チェックも設定できる ようになりました(∩´∀`)∩
下は、OCRが認識した文字は「☑」で、チェック内容が「☒を含む」の例です。


また役に立つかもしれないテクニックをみつけた際は記事書きます。
最後までお読みいただきありがとうございます!