はじめに
- 本記事は、UiPath Studio の基礎知識をお持ちで、これから Document Understanding を利用したい方向けの内容となっています。
- 記事の内容は、個人の見解または確認結果であり、UiPath の公式見解ではありません。
- 製品仕様や参考画像は 23.4 バージョンで構成しています。
- Automation Cloud のアカウントおよび Pro Trial を申請するなどして DU のアクセス権限を取得している必要があります。
Document Understanding をミニマム構成で試してみたい
Document Understanding(以降、DUと略す)は、ドキュメントから情報を抽出・解釈する機能群です。
請求書やINVOICE、領収書、源泉徴収票等々、様々な文書からデータの読み取り、操作をおこなうための魅力な機能が多く搭載されているものの、機能が多い故のわかりづらさがあります。
マシンラーニングを利用した本格的なDUの実装ですと、
DocumentManager(Automation Cloud のDUのサービスの一画面)での何十ページにも及ぶアノテーション作業から、AI Center でのモデルの追加学習、デプロイ作業 等も必要となります。
『そこまで本格的じゃなくていいんだけど、どうやって文書データ読み取って、データ操作するのかをミニマムで試したい』
そんな方向けに、アンケート を題材にした記事を書きます!!(以下、今回の記事用に用意した架空のアンケートの雛)

- 入力済みのアンケートのサンプルは画像ファイル(962*785 ピクセルの「.JPG」データ)です。自由記述欄の文字には手書きフォントなどを利用しています。
- 文書のフォーマットは1つのため分類は設定しますが、検証はおこないません。
- 文書からのデータ抽出には「フォーム抽出器」のみもちいます。
STEP1. 文書の項目定義(タクソノミーの設定)(1/6)
チェックボックス(計9つ)と自由記述欄、部署名、お名前のフィールドを作成します。

次に、入力済みのアンケートデータを用意します。(記事の末尾にサンプル画像データあり)
STEP2. 前処理の実装(2/6)
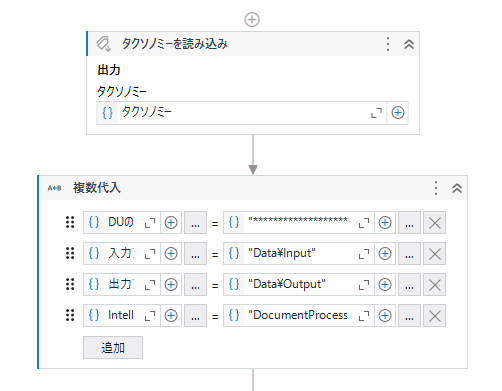
- 「タクソノミーの読み込み」を配置 ← STEP1 で設定したタクソノミーをロードします。
- 「複数代入」を設置し、「APIキー」「入/出力のフォルダパス」「インテリジェントキーワード分類用の学習ファイルパス(※1)」を指定
※1:DocumentProcessing\IntelligentKeywordClassifierLearningFile.json ← 最初は在りません。空のテキストファイルで結構ですので同名にて作成・配置お願いします。 分類器のスコープで学習することで内容は更新されます。
STEP3. 文書の分類アクティビティの設定(3/6)
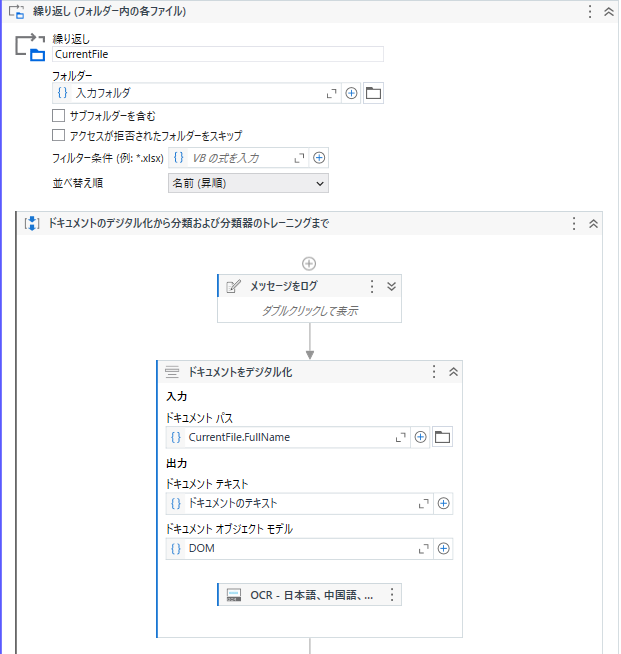
「繰り返し(フォルダ内の各ファイル)」アクティビティなどを配置し、取得した画像ファイル毎にデジタル化・分類・抽出の処理にかけていきます。
OCRのエンジンは既定では「UiPath ドキュメント OCR」が設定されていますが、日本語の文書を読み取る場合は「CJK-OCR」に変更しましょう。(CJKは Chinese Japan Korea の略)
エンドポイント:https://du-jp.uipath.com/cjk-ocr
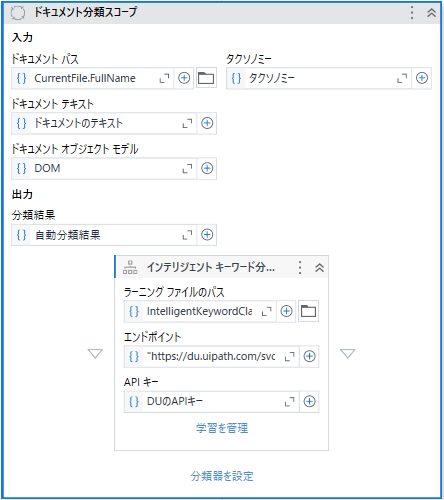

- 「ドキュメント分類スコープ」「インテリジェントキーワード分類器」を配置します。
- 「学習を管理」より、空のアンケートフォーマットを学習させます。(以下のメッセージを確認した際は、「{プロジェクトフォルダ}\DocumentProcessing\IntelligentKeywordClassifierLearningFile.json」を指定してください。)

- 「分類器を設定」のリンクをクリックし、表示された画面でタクソノミーを設定した文書のチェックをONにします。

STEP4. 文書の抽出アクティビティの設定(4/6)

- 「繰り返し(コレクションの各要素)」アクティビティを配置し、自動分類結果をもとにデータの抽出・出力処理をかけていきます。
- 「フォーム抽出器」を配置し、テンプレートを作成します。(※2)なお、今回アンケートで利用するチェックボックス(Boolean のフィールド)などは「署名フィールド」や「はい/いいえ」の類義語を設定しないと期待動作は得られません。

- 「抽出器を設定」のリンクをクリックし、表示された画面でタクソノミーを設定した文書のチェックをONにします。
※2:チェックボックスのカスタム領域は「□」の内側を指定します。外側で指定する場合は「□」を「いいえ」の類義語で設定する必要あり。「自由記述欄」や「部署名」、「お名前」は余分な文字等が入らない範囲で余裕をもって指定しましょう。
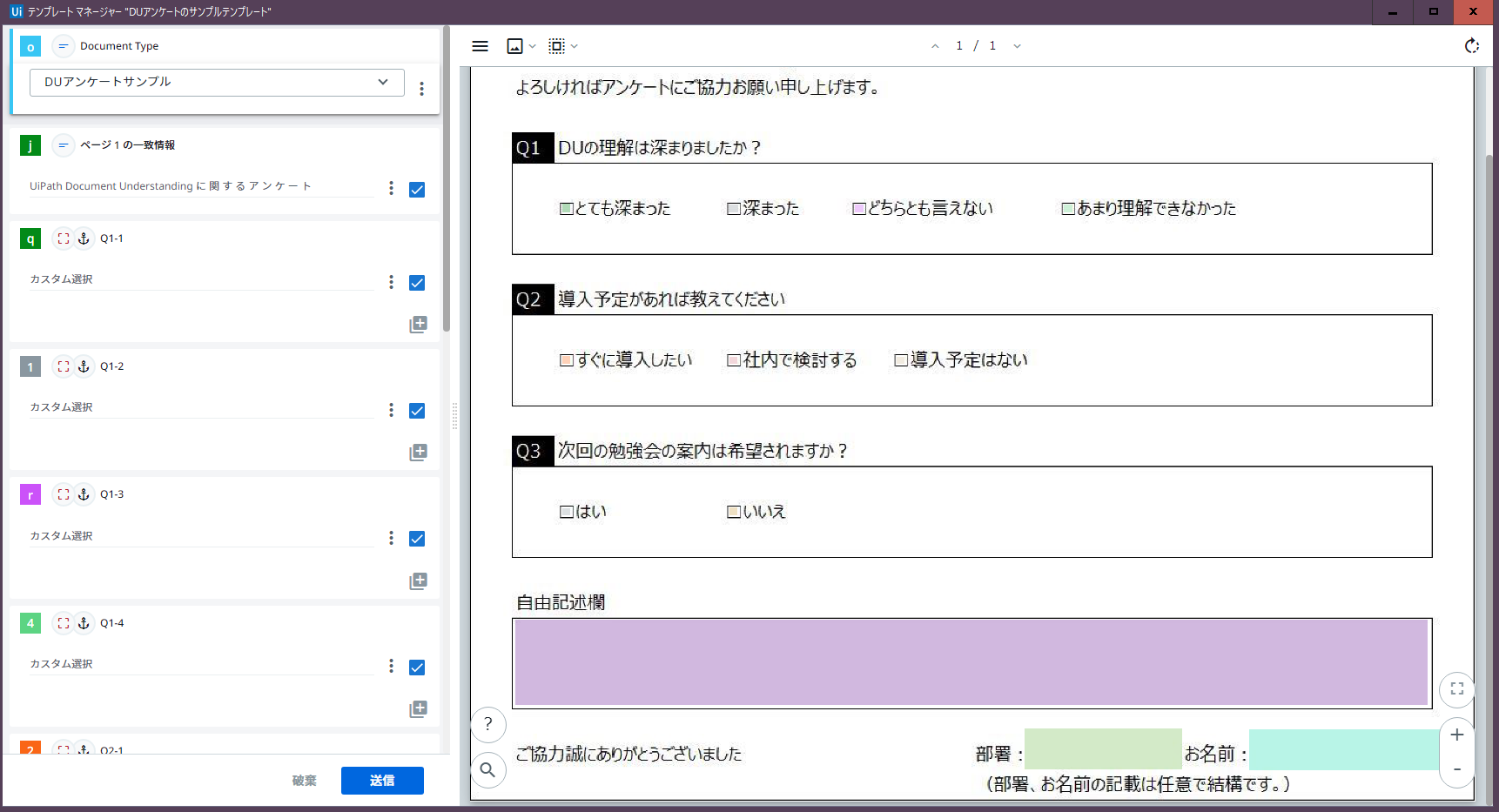
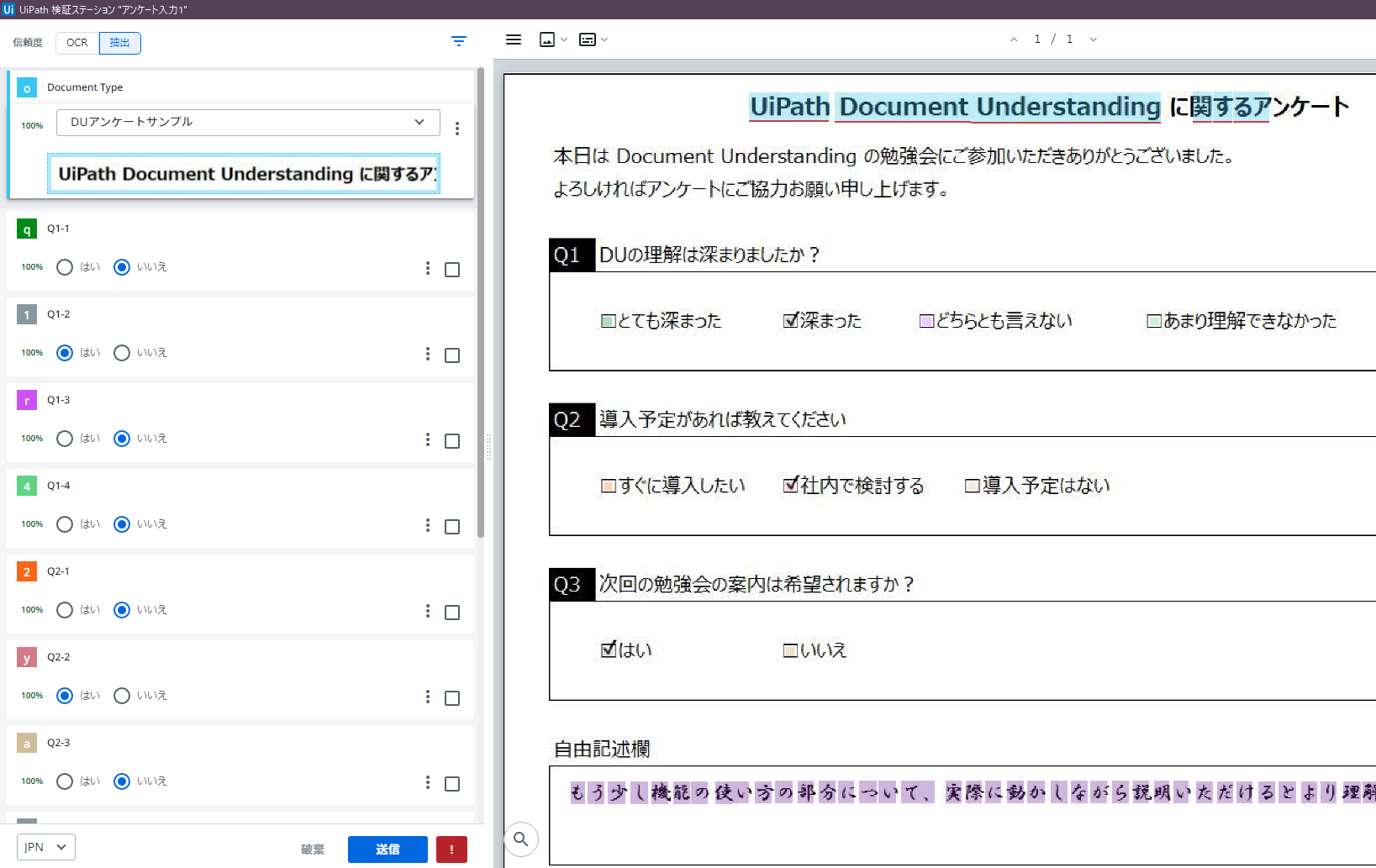
STEP5. 抽出結果の確認(5/6)

表示された抽出結果の正しさを確かめながら、確認済みのチェックをONにし、「送信」ボタンを押下します。
STEP6. 抽出結果の出力(6/6)

「抽出結果をエクスポート」アクティビティを使うことでデータセット型(※)の情報を出力できます。
※:複数のデータテーブルを保持できます。データテーブルを単一の「テーブル」とした場合、データセットは「データベース」のイメージです。
「繰り返し(コレクションの各要素)」「範囲に書き込み(ワークブック)」等のアクティビティをもちいて抽出データを出力します。
(出力サンプル)

実行結果
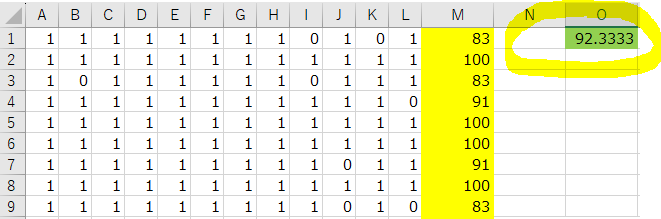
■自動抽出結果と検証結果の比較 => 適合率:92%以上 (一致しなかっケースは後述します。)
■創出効果 自動抽出:1分 > 自動抽出(検証あり):6分 > 手動:12分

(期待通りに抽出されなかったケースのサンプル)

↓↓↓


↓↓↓

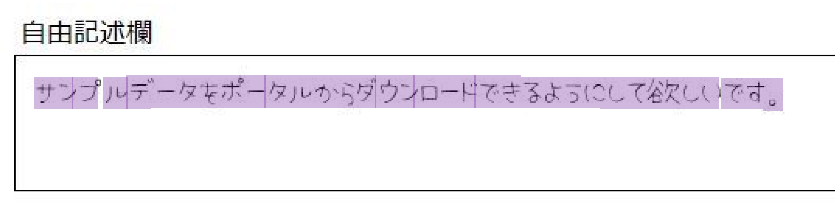
↓↓↓

(予想外に完璧に抽出されたケースのサンプル)

↓↓↓

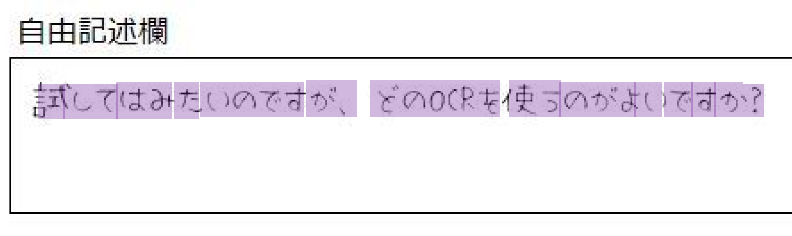
↓↓↓

最後に
いかがでしたでしょうか?
Document Understanding = AI製品 = AIわからないと使えない? とおもわれがちですが、
ルールを設定してあげるだけでこれだけ利用できます!
個社のフォーマットからデータを読み取って操作するだけであれば「CJK-OCR」×「フォーム抽出器」で十分力を発揮できます!!
ご自身の業務で力を発揮しそうなものがあるなーとおもっていただいた方は、是非以下の記事もお読みいただけますと幸いです。
おまけ - 入力済みのアンケートのサンプル








