はじめに
はじめまして。エンジニア転職を目指してAidemyさんのAI開発講座を受講している元サラリーマンです。
趣味で映像編集をしていて、所属するサッカーチームの振り返り映像を作ることがあります。たくさん撮ったサッカーのプレーの写真の中から、映像制作に使うことの多い「ボールを持つ人が全身写っている写真」だけを選び出すアプリがあれば、映像制作にかかる時間も短縮できるのではと思い、その作成した過程について書こうと思います。

目次
実行環境
データの準備
モデルの構築・学習・評価
Webページの作成(HTML・CSS・FLASK)
Renderへのデプロイ
今後の活用
おわりに
実行環境
iMac (Retina 5K, 2017)
Google Colaboratory
Visual Studio Code
データの準備
講師の方から勧めてもらったFlickrというデーターセットのサイトを使用することにしました。
Flickr画像取得の最終コード
!pip install flickrapi
from google.colab import drive
drive.mount('/content/drive')
import flickrapi
import requests
import os
from urllib.parse import urlparse
# ①Google Driveの任意のディレクトリパスを指定
#(例: '/content/drive/MyDrive/')
os.chdir("任意のディレクトリパス")
# FlickrのAPI_KEYとAPI_SECRET
api_key = "API_KEY" # ②Flickrで取得したAPI_KEY
api_secret = "API_SECRET" # ③Flickrで取得したAPI_SECRET
# FlickrAPIオブジェクトの作成
flickr = flickrapi.FlickrAPI(api_key, api_secret, format='parsed-json')
#取得画像を保存するフォルダを用意
#(①で移動したディレクトリ直下にこのフォルダが作成される)
save_dir = 'soccer_images'
os.makedirs(save_dir, exist_ok=True)
# 画像検索クエリの設定
search_query = 'soccer players' # ④任意の検索ワードを入力
extras = 'url_c' # ⑤中サイズ(800px)の画像を取得
safe_search = 1 # 安全な検索を有効にする
per_page = 20 # ⑥1回のAPI呼び出しで取得する画像の数
pages = 10 # ⑦取得するページ数
# 画像を取得してsoccer_imagesフォルダに保存する
for page in range(1, pages + 1):
photos = flickr.photos.search(text=search_query, per_page=per_page, page=page, extras=extras)
for photo in photos['photos']['photo']:
url = photo.get('url_c')
if url:
response = requests.get(url)
if response.status_code == 200:
photo_id = photo['id']
file_path = os.path.join(save_dir, f"{photo_id}.jpg")
with open(file_path, 'wb') as file:
file.write(response.content)
print(f'Downloaded {file_path}')
print('Done')
一度に多くの画像をダウンロードするとドライブが止まってしまうことがあったので、
per_page = 20 # ⑥1回のAPI呼び出しで取得する画像の数
pages = 10 # ⑦取得するページ数
この二つのコードの値は変えずに、
# 画像を取得してsoccer_imagesフォルダに保存する
for page in range(1, pages + 1):
このコードを、
# 画像を取得してsoccer_imagesフォルダに保存する
for page in range(11, 21):
や、
# 画像を取得してsoccer_imagesフォルダに保存する
for page in range(21, 31):
にしたりして、10ページずつ画像をダウンロードし、
合計で1,000枚ほど入手しました。
このデーターセットには、ドリブルしている選手、シュートを防ぐキーパーなどプレーの写真以外に、表彰式の様子や応援に来ている観客の写真なども含まれていました。
実際に自分が所属するサッカーチームの試合で撮影する時もそのような写真を撮るので、サッカー場で撮られた写真はすべて学習用にダウンロードすることにしました。
その中から手作業で、正解と不正解フォルダに分けていき、
正解ラベルの写真は700枚くらいになりました。
モデルの構築・学習・評価
学習済みモデルVGG16を使った転移学習を用いて、Google Colaboratory上でモデルを構築しました。
Aidemyさんの講座「男女識別(深層学習)」のコードと、こちらの記事を参考にさせて頂きました。
VGG16を使った転移学習とは?
大量のデータですでに学習され公開されているモデルを用いて、新たなモデルの学習を行うことを「 転移学習 」といいます。 VGGモデルは、2014年のILSVRCという大規模な画像認識のコンペティションで2位になった、オックスフォード大学VGG(Visual Geometry Group)チームが作成したネットワークモデルです。 小さいフィルターを使った畳み込みを2〜4回連続で行いさらにプーリングする、というのを繰り返し、当時としてはかなり層を深くしてあるのが特徴です。VGGモデルには、重みがある層(畳み込み層と全結合層)を16層重ねたものと19層重ねたものがあり、それぞれVGG16やVGG19と呼ばれます。VGG16は、畳み込み13層+全結合層3層=16層のニューラルネットワークになっています。モデルの最終的なコードはこちら
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# 仮想環境のディレクトリ構造等によってファイルパスは異なります。
path_0 = os.listdir("./6100_ballman_recognition_data/0/")
path_1 = os.listdir("./6100_ballman_recognition_data/1/")
img_other = []
img_ballman = []
for i in range(len(path_0)):
img = cv2.imread('./6100_ballman_recognition_data/0/' + path_0[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_other.append(img)
for i in range(len(path_1)):
img = cv2.imread('./6100_ballman_recognition_data/1/' + path_1[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_ballman.append(img)
X = np.array(img_no + img_ballman)
y = np.array([0]*len(img_other) + [1]*len(img_ballman))
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# 正解ラベルをone-hotの形にします
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデルにvggを使います
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、2クラス分類する層を定義します
# その際中間層を下のようにいくつか入れると精度が上がります
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# vggと、top_modelを連結します
model = Model(vgg16.inputs, top_model(vgg16.output))
# vggの層の重みを変更不能にします
for layer in model.layers[:19]:
layer.trainable = False
# コンパイルします
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# 学習を行います
# historyは後ほど正解率の可視化でも使用
history = model.fit(X_train, y_train, batch_size=100, epochs=40, validation_data=(X_test, y_test))
# 画像を一枚受け取り、ballmanかどうかを判定する関数
def pred_ballman(img):
img = cv2.resize(img, (50, 50))
pred = np.argmax(model.predict(np.array([img])))
if pred == 0:
return 'other'
else:
return 'ball-man-full'
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# pred_ballman関数に写真を渡してballmanかどうかを予測します
for i in range(5):
img = cv2.imread('./6100_ballman_recognition_data/0/' + path_0[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
print(pred_ballman(img))
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 学習モデルを保存
model.save(os.path.join(result_dir, "f_vmodel.h5"))
from google.colab import files
files.download( '/任意のディレクトリ/f_vmodel.h5' )
# 以下、評価指標を可視化するコード
# 正解率の可視化
plt.plot(history.history['accuracy'], label='acc', ls='-')
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# 仮想環境のディレクトリ構造等によってファイルパスは異なります。
path_0 = os.listdir("./6100_ballman_recognition_data/0/")
path_1 = os.listdir("./6100_ballman_recognition_data/1/")
img_other = []
img_ballman = []
for i in range(len(path_0)):
img = cv2.imread('./6100_ballman_recognition_data/0/' + path_0[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_other.append(img)
for i in range(len(path_1)):
img = cv2.imread('./6100_ballman_recognition_data/1/' + path_1[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_ballman.append(img)
X = np.array(img_no + img_ballman)
y = np.array([0]*len(img_other) + [1]*len(img_ballman))
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# 正解ラベルをone-hotの形にします
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデルにvggを使います
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、2クラス分類する層を定義します
# その際中間層を下のようにいくつか入れると精度が上がります
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# vggと、top_modelを連結します
model = Model(vgg16.inputs, top_model(vgg16.output))
# vggの層の重みを変更不能にします
for layer in model.layers[:19]:
layer.trainable = False
# コンパイルします
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# 学習を行います
# historyは後ほど正解率の可視化でも使用
history = model.fit(X_train, y_train, batch_size=100, epochs=40, validation_data=(X_test, y_test))
# 画像を一枚受け取り、ballmanかどうかを判定する関数
def pred_ballman(img):
img = cv2.resize(img, (50, 50))
pred = np.argmax(model.predict(np.array([img])))
if pred == 0:
return 'other'
else:
return 'ball-man-full'
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# pred_ballman関数に写真を渡してballmanかどうかを予測します
for i in range(5):
img = cv2.imread('./6100_ballman_recognition_data/0/' + path_0[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
print(pred_ballman(img))
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 学習モデルを保存
model.save(os.path.join(result_dir, "f_vmodel.h5"))
from google.colab import files
files.download( '/任意のディレクトリ/f_vmodel.h5' )
# 以下、評価指標を可視化するコード
# 正解率の可視化
plt.plot(history.history['accuracy'], label='acc', ls='-')
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
2クラス分類する層を定義する箇所で、初めは下記のコードで実行していました。
top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(256, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(2, activation='softmax'))
しかし、グラフのように、訓練データの精度(acc)と検証データの精度(val_acc)が乖離してしまった(=過学習を起こしてしまった)ので、Denseの数、Dropout rate、層の数をチューニングすることにしました。
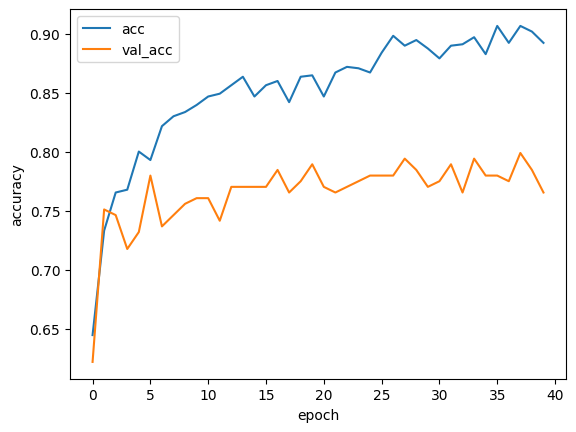
まず、Denseの数を128、Dropout rateは0.7にして、同じ層をひとつ増やしました。
top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(128, activation='relu')) top_model.add(Dropout(0.7)) top_model.add(Dense(128, activation='relu')) top_model.add(Dropout(0.7)) top_model.add(Dense(2, activation='softmax'))
結果はこのように、むしろ悪化。

次は、Dropout rateは当初のまま0.5、他の二つの要素だけ調整しました。
top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(128, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(128, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(2, activation='softmax'))
結果は、少し改善。

まだまだ精度は高められるだろうと思い、
今度はDropout rateと層の数は当初のまま、Denseの数を128に調整しました。
top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(128, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(2, activation='softmax'))
すると、精度が80~85%にアップ!

過学習も起こしていないようなので、この数値にすることにしました。
ちなみに、この状態でepoch数を50にしたところ、

50に近づくにつれて精度が下がり始めたため、epoch数は40としました。
Webページの作成①(FLASK)
Google Colaboratory上で構築・保存したモデルを基に、Visual Studio CodeにてWebページの作成に取り掛かりました。
Flaskサイドの制作は、AidemyさんのFlask入門講座のコードを参考にしました。
Flaskの最終コード
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import load_model
import cv2
import numpy as np
classes = ["other","ballman"]
image_size = 50
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./f_vmodel.h5')#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込む
img = cv2.imread(filepath)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (image_size, image_size))
img = img.astype('float32') / 255.0 # 正規化
img = np.expand_dims(img, axis=0) #カラーを明示
print("画像サイズチェック")
print(img.shape)
#変換したデータをモデルに渡して予測する
result = model.predict(img)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
AidemyさんのFlask入門講座では、以下のように白黒画像を読み込む仕様になっていました。
img = image.load_img(filepath, grayscale=True, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
今回のアプリはカラー画像を読み込む想定だったので、以下のようにコードを変更しました。
img = cv2.imread(filepath)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (image_size, image_size))
img = img.astype('float32') / 255.0 # 正規化
img = np.expand_dims(img, axis=0) #カラーを明示
print("画像サイズチェック")
print(img.shape)
#変換したデータをモデルに渡して予測する
result = model.predict(img)[0]
Webページの作成②(HTML・CSS)
HTMLはこちらの記事を、
CSSはAidemyさんの講座「Flask入門のためのHTML&CSS」のコードを参考にし、
画像はcanvaというサイトからダウンロードしました。
画像を挿入すると、なぜかフッターがメイン画像の真ん中に来てしまいました。どうやらCSS内のmainのheightが370pxで指定されていたため、挿入した画像のサイズが大き過ぎて収まり切らなかったようです。
講師の方の助言もあり、CSS内にあった以下のmainは消すことにしました。
.main { height: 370px; }
それ以外にも、headerなど、必要のない箇所は削除しました。
HTMLの最終コード
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<header>
<h1>Ball-Man-Full Classifier</h1>
</header>
<body>
<div class="main">
<img class="title" src="./static/ballmanfulltop.jpg">
<h2> ボールを持った人が全身写っていればball-man-full<br>
それ以外はotherと表示されます</h2>
<p>画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
</body>
<footer>
<small>© 2019 Aidemy, inc.</small>
</footer>
</html>
CSSの最終コード
header {
background-color: #76B55B;
height: 60px;
margin: -8px;
text-align:left;
}
h1{
color: #fff;
}
img{
width: 100%;
height: auto;
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #F7F7F7;
height: 30px;
margin: -2px;
text-align: right;
}
small {
color: #444444;
}
Renderへのデプロイ
GitHubアカウントを作り、Renderへのデプロイをしました。
Aidemyさんの講座「Flask入門Renderの設定とデプロイ」を参考にしながら進めました。
デプロイをするための事前準備として、requirements.txtというファイルを新たに作成しました。requirements.txt に必要なライブラリを記述することでRenderの自分のアプリ内にそのライブラリがインストールされます。
requirements.txtの中身
absl-py==0.9.0
astor==0.8.1
bleach==3.1.5
bottle==0.12.18
click==7.1.2
certifi==2020.6.20
chardet==3.0.4
flask==2.0.1
future==0.18.2
gast==0.3.3
grpcio==1.31.0
gunicorn==20.0.4
h5py==2.10.0
html5lib==1.1
itsdangerous==2.0
idna==2.10
Jinja2==3.0.1
line-bot-sdk==1.16.0
Markdown==3.2.2
MarkupSafe==2.0
numpy==1.18.0
oauthlib==3.1.0
pillow==7.2.0
protobuf==3.12.4
PyYAML==5.4.1
python-dotenv==0.14.0
requests==2.25.1
scipy==1.4.1
six==1.15.0
tensorboard==2.3.0
tensorflow-cpu==2.3.0
termcolor==1.1.0
urllib3==1.26.5
Werkzeug==2.0.0
tensorflowでは容量をオーバーしてしまう恐れがありますので、tensorflow-cpuを用います。
実際にデプロイをしようとしましたが、requirements.txt内に書かれたライブラリのバージョンが何個か合わないものがあったので、講師の方の助言もあり、以下のように「==」以降をすべて削除しました。
最終的なrequirements.txtの中身
absl-py
astor
bleach
bottle
click
certifi
chardet
flask
future
gast
grpcio
gunicorn
h5py
html5lib
itsdangerous
idna
Jinja2
line-bot-sdk
Markdown
MarkupSafe
numpy
oauthlib
pillow
protobuf
PyYAML
python-dotenv
requests
scipy
six
tensorboard
tensorflow-cpu==2.15.0
termcolor
urllib3
Werkzeug
opencv-python-headless
今後の活用
本来なら、何枚もの写真の中から「ボールを持つ人が全身写っている写真」だけを選び出すようにしたかったのですが、もう少し高度な設定が必要そうでした。ひとまずは、アップロードされた写真が「ボールを持つ人が全身写っている写真」かどうかを識別する機能までに留めておきました。
将来的には、アップロードした写真の中から目当ての写真だけをダウンロードしてフォルダ分けできるようにしたいなと思っています。また、もう少し精度を上げたいので、サッカー以外のバスケットボールやバレーボールのデーターセットも学習させてみたら面白いかなと思います。
おわりに
トラブル続きでしたが講師の方々のたくさんの助言により完成することができました。自分でできることが増えるとプログラミングがもっと面白くなるだろうなと思うので、引き続き、データサイエンスや自然言語処理なども学んでいきたいと思います。
なお、このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。