概要
pythonでDTW(詳細は以下)を実装し,それを実行した場合は速度の問題が生じる.そのためDTWの部分をコンパイラ言語のGo言語で実装し,それをpython3から呼びだせるようにした話.
1. はじめに
IoTの普及により時系列データが集まりやすくなりました.そこでシステムの中で時系列データ同士の距離や類似度を計算するという機会も多くなるはずです.時系列データにも利用できるデータ同士の距離や類似度算出法としては,ユークリッド距離やコサイン類似度,相関係数などが挙げられます.しかし,これらは時系列のデータ長(ベクトルにすると次元)が揃っていないと計算できませんし,位相がズレている場合や周波数が異なる場合はシステム全体にかなり影響してしまいます.
そこで,これらを解決できる距離指標が動的時間伸縮法(Dynamic-Time-Warping,以下DTW)です.これは時系列のデータ長が揃っていなくても,位相がズレていても,周波数が異なる場合でもDTW距離が算出可能です.しかも人間が時系列の形状を見たときに直感的に似ていると判断したものは,DTW距離の値が小さくなるようになっているアルゴリズムです.
データを解析するにあたって最近はpythonを使うことが多いですね.機械学習も簡単に実装できますし扱いやすいです.だからといってpythonでDTWを実装するなんてことはオススメできません.計算するデータが多くなればなるほどインタプリタ言語のため時間がかかってしまいます.これはコンパイラ言語で実装し、実行ファイルを呼び出せば解決です.
本記事では,2.DTWについてと欠点,3.go言語で実装したDTWについて,4.pythonからの呼び出しについて,5.バッチ処理的な計算について,6.課題,7.最後に という流れで紹介します.
2. 動的時間伸縮法(Dynamic-Time-Warping,DTW)とその欠点
DTW
DTWについては歴史が古く様々な記事でわかりやすく説明されています.簡単に説明すると,以下のステップで構成されるアルゴリズムである.
1. 2つの時系列データ$X = \{x_0, x_1, .., x_m\}$,と$Y = \{y_0, y_1, .., y_n\}$を用意する.
2. 各点について総当たりで距離(2乗誤差や絶対誤差など)を計算し、行が$X$,列が$Y$,要素が点同士の距離となる行列$D$を作成する.
3. $ D[0][0]$から$D[m][n]$までのパスの内,通る行列の要素の合計が最小となるパス(=Warping Path)を探索する.その最小となるパスの要素の合計がDTW距離である.
これを実現するために動的計画法を用いて計算すると効率が良いアルゴリズムである.この場合この場合**$D[m][n]$の要素がDTW距離**である.以下にこちらの記事から参照したわかりやすいアニメーションを示す,
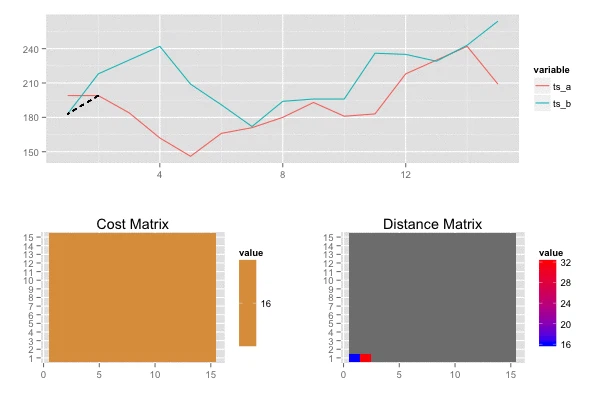
上部のアニメーションが各点について総当たりで計算している様子を示している.右下のアニメーションはそのときに計算している点同士の距離を要素とした行列を生成している.左下の図が点同士の距離を計算すると同時に動的計画法を用いながら行列の要素を埋めている.
こちらの記事にも一目瞭然な図があったので紹介します.
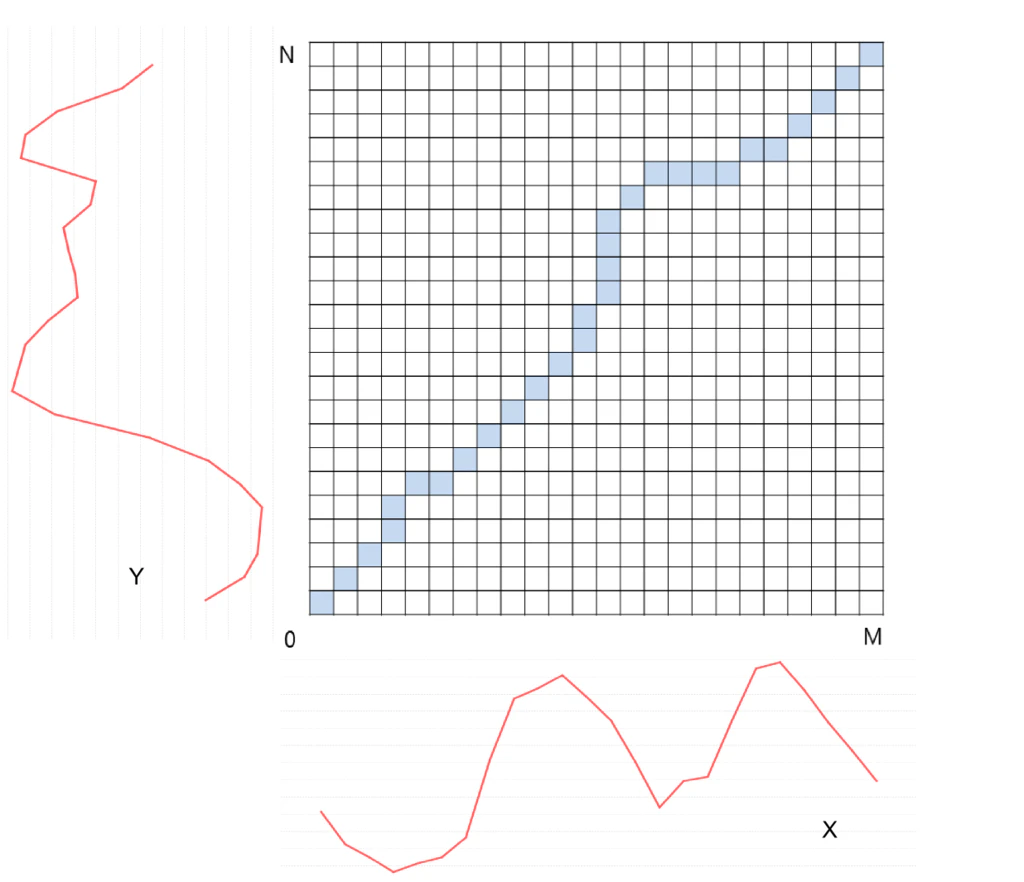
青い線がWarping Pathですね.
欠点
2つの時系列の各時間点を総当たりで計算するため,計算量は$O(mn)$である.これをコンパイラ言語で実装するにはまだしも,インタプリタ言語で実装すると少々時間がかかる.膨大なデータ量であればなおさらである.
3. go言語で実装したDTWについて
ということでDTWをgo言語で実装しましたので以下に示します.一応今回の仕様としては,時系列$x$と時系列$y$はcsvファイルとして保存さてれおり,ファイル読み込みしてから計算するという形になっております.なぜgo言語なのかっというのはC言語に近いくらい高速であり,書きやすいからである.
package main
import (
"encoding/csv"
"flag"
"fmt"
"log"
"math"
"os"
"strconv"
)
//-----------------コマンドラインオプション-----------------------------------
var (
XrfOpt = flag.String("Xrf", "default", "help message for \"s\" option")
YrfOpt = flag.String("Yrf", "default", "help message for \"s\" option")
wfpOpt = flag.String("wfp", "default", "help message for \"s\" option")
distOpt = flag.String("d", "default", "help message for \"s\" option")
)
//-------------------------- エラー処理-----------------------------------
func failOnError(err error) {
if err != nil {
log.Fatal("Error:", err)
}
}
//----------------スライスにおける実数・文字列変換-----------------------------------
func strToFloat64_1d(i []string) []float64 {
// 1次元スライスに対して、文字列型から実数型に変換
// 引数:文字列型の1次元スライス
// 返り値:実数型の1次元スライス
f := make([]float64, len(i))
for n := range i {
f[n], _ = strconv.ParseFloat(i[n], 64)
}
return f
}
func float64ToStr(x float64) string {
// 実数型から文字列型に変換
// 引数:実数型の1変数
// 返り値:文字列型の変数
f := strconv.FormatFloat(x, 'f', 8, 64)
return f
}
//-------------------------- ファイル 入出力関係-----------------------------------
func csvReader_1d(readFilename string) []string {
// csv読み込み
// 引数:ファイル名(ファイルパス含む)
// 返り値:csvファイルから読み込んだ1次元スライス
// 読み込み
fr, err := os.Open(readFilename)
failOnError(err)
defer fr.Close()
r := csv.NewReader(fr)
rows, err := r.ReadAll() // rowsのshapeは(len(rows),1)と2次元となってしまっている
failOnError(err)
// 1次元へflatten
str_data := make([]string, len(rows))
for i := 0; i < len(rows); i++ {
str_data[i] = rows[i][0]
}
return str_data
}
func csvWriter(str string, writeFilename string) {
// csv 書き込み
// 引数:csvファイルに書き込む変数.ファイル名(ファイルパス含む)
// 返り値:なし
strCSV := str
// 以下txtファイル出力の要領でcsvファイルを出力
// ファイルを書き込み用にオープン (mode=0666)
file, err := os.Create(writeFilename)
if err != nil {
panic(err)
}
defer file.Close()
// テキストを書き込む
_, err = file.WriteString(strCSV)
if err != nil {
panic(err)
}
}
//------------------------- 要素同士の距離------------------------
func dist(a float64, b float64, selectDist string) float64 {
// 距離計算方法の選択
// 引数:実数a, 実数b, 距離計算方法
// 返り値:距離
if selectDist == "se" {
return squareError(a, b)
} else {
return squareError(a, b)
}
}
func squareError(a float64, b float64) float64 {
// 2乗誤差
// 引数:実数a, 実数b
// 返り値:2乗誤差
return math.Pow(a-b, 2)
}
//--------------要素が3のスライスの中から最小値を探索------------------
func selectMin(List []float64) float64 {
// 動的計画法を行う上ですでに計算された3値より最小の値を選択
// 引数:3値が要素となるスライス
// 返り値:最小値
min := 99999.9
for _, v := range List {
if min > v {
min = v
}
}
return min
}
func dtw(x []float64, y []float64, selectDist string) ([][]float64, [][]float64) {
// DTWを動的計画法で計算する
// 引数:距離を計算する時系列x,y 距離計算方法
// 返り値:動的計画法で計算された2重スライス, 全組み合わせの距離が計算された2重スライス
// 要素が空の2重スライスを生成
dtwArray := make([][]float64, len(x))
for i := range dtwArray {
dtwArray[i] = make([]float64, len(y))
}
distArray := make([][]float64, len(x))
for i := range distArray {
distArray[i] = make([]float64, len(y))
}
dtwArray[0][0] = dist(x[0], y[0], selectDist)
distArray[0][0] = dist(x[0], y[0], selectDist)
for i := 1; i < len(x); i++ {
dtwArray[i][0] = dist(x[i], y[0], selectDist) + dtwArray[i-1][0]
distArray[i][0] = dist(x[i], y[0], selectDist) + distArray[i-1][0]
}
for j := 1; j < len(y); j++ {
dtwArray[0][j] = dist(x[0], y[j], selectDist) + dtwArray[0][j-1]
distArray[0][j] = dist(x[0], y[j], selectDist) + distArray[0][j-1]
}
for i := 1; i < len(x); i++ {
for j := 1; j < len(y); j++ {
candMin := []float64{dtwArray[i-1][j], dtwArray[i][j-1], dtwArray[i-1][j-1]}
dtwArray[i][j] = dist(x[i], y[j], selectDist) + selectMin(candMin)
distArray[i][j] = dist(x[i], y[j], selectDist)
}
}
return dtwArray, distArray
}
//------------------------------ Main -----------------------------------
func main() {
// コマンドライン引数の確認
flag.Parse()
XreadFilename := *XrfOpt // 読み込みxファイル名
YreadFilename := *YrfOpt // 読み込みyファイル名
writeFilePath := *wfpOpt // 書き出しファイル名
selectDist := *distOpt
if XreadFilename == "default" || YreadFilename == "default" || selectDist == "default" {
fmt.Print("コマンドライン引数エラー")
return
}
// 配列Xのcsvファイル読み込み
Xstr_data := csvReader_1d(XreadFilename)
Ystr_data := csvReader_1d(YreadFilename)
// 各要素を文字列型から実数値型へ変換
x := strToFloat64_1d(Xstr_data)
y := strToFloat64_1d(Ystr_data)
// DTWを計算
dtwArray, _ := dtw(x, y, selectDist)
if writeFilePath == "default" {
// DTW距離を標準出力する
fmt.Print(dtwArray[len(x)-1][len(y)-1])
} else {
// 実数値型から文字列型へ変換
dtwDistance := float64ToStr(dtwArray[len(x)-1][len(y)-1])
// DTW距離をファイル書き出し
csvWriter(dtwDistance, writeFilePath)
}
}
細かい実行方法はgithubのreadmeを参照ください.
4. pythonから呼び出す(実行ファイルを実行)
上述のgo言語で計算された値をpythonで呼び出し値を受け取るには以下のような手順を踏むと良いと思います.
# coding:utf-8
# !/usr/bin/env python
import os
import subprocess
import numpy as np
# 時系列データ(1次元配列)x,yを用意
tmpDir = "./tmp/" # 一時保存用のディレクトリ
os.makedirs(tmpDir, exist_ok=True)
# 時系列を保存
np.savetxt(tmpDir + "x.csv", x, delimiter=",")
np.savetxt(tmpDir + "y.csv", y, delimiter=",")
# 実行ファイル実行
dtwGo = subprocess.run(["./dtw1d", "-Xrf", tmpDir + "x.csv", "-Yrf", tmpDir + "y.csv", "-d", "se"], check=True, stdout=subprocess.PIPE).stdout
# dtwGo = subprocess.run(["./dtw1d", "-Xrf", tmpDir + "x.csv", "-Yrf", tmpDir + "y.csv", "-wfp", tmpDir + "dtw.csv", "-d", "se"], check=True, stdout=subprocess.PIPE).stdout
if dtwGo.decode() == "コマンドライン引数エラー":
print("実行ファイルへの引数エラー")
else:
print(float(dtwGo.decode()))
# print(np.loadtxt(tmpDir+"dtw.csv", delimiter=","))
このまま実行すると実行ファイルからの標準出力を取り込むことでDTWの結果を得られる.一方,コメントアウトを入れ替え出力ファイル名を指定し実行ファイルを呼び出すと,上術の通り標準出力されずにcsvファイルとして出力される.その場合pythonでcsvファイルを読み込むことでDTWの結果を得られる.
5. バッチ処理的な計算について
大量の計算するべきデータ対が存在したときに1組みのDTWの計算を何回も呼び出すのは,これもまた時間がかかるのは明白である.ループがご法度と言われるpythonならなおさらである.そこで行列を渡すことで一度に計算するnumpyのようなモデルを目指す.つまりバッチ処理的な考えで一度呼び出してそこで全て完結し,DTW距離の値を配列として返してくれれば大量のデータに対しては効率が良い.
すなわち,
2種類のベクトル群X,Y(それぞれ行がデータ,列が次元に対応する2次元配列)同士のDTW距離を計算する.ただし,計算するのは同じ行同士の距離である.つまりデータ数分のDTW距離が出力される(データ数次元のベクトル).
というコードを以下に示す.
とおもったが,長いのでこれもまたgithubのdtw2d.goを参照してください.
どれほど速度に違いが出るのかを以下のコードで確かめた.
# coding:utf-8
# !/usr/bin/env python
import os
import time
import subprocess
import numpy as np
# 一時保存用のディレクトリ
tmpDir = "./tmp/"
os.makedirs(tmpDir, exist_ok=True)
def dtw1d(x,y):
np.savetxt(tmpDir + "x.csv", x, delimiter=",")
np.savetxt(tmpDir + "y.csv", y, delimiter=",")
dtwGo = subprocess.run(["./dtw1d", "-Xrf", tmpDir + "x.csv", "-Yrf", tmpDir + "y.csv", "-d", "se"], check=True, stdout=subprocess.PIPE).stdout
# dtwGo = subprocess.run(["./dtw1d", "-Xrf", tmpDir + "x.csv", "-Yrf", tmpDir + "y.csv", "-wfp", tmpDir + "dtw.csv", "-d", "se"], check=True, stdout=subprocess.PIPE).stdout
if dtwGo.decode() == "コマンドライン引数エラー":
print("実行ファイルへの引数エラー")
else:
return float(dtwGo.decode())
# return np.loadtxt(tmpDir+"dtw.csv", delimiter=",")
def dtw2d(X,Y):
np.savetxt(tmpDir + "X.csv", X, delimiter=",")
np.savetxt(tmpDir + "Y.csv", Y, delimiter=",")
dtwGo = subprocess.run(["./dtw2d", "-Xrf", tmpDir + "X.csv", "-Yrf", tmpDir + "Y.csv", "-d", "se"], check=True, stdout=subprocess.PIPE).stdout
# dtwGo = subprocess.run(["./dtw2d", "-Xrf", tmpDir + "X.csv", "-Yrf", tmpDir + "Y.csv", "-wfp", tmpDir + "dtw.csv", "-d", "se"], check=True, stdout=subprocess.PIPE).stdout
if dtwGo.decode() == "コマンドライン引数エラー":
print("実行ファイルへの引数エラー")
else:
return [float(i) for i in dtwGo.decode().replace("[","").replace("]","").split()]
# return np.loadtxt(tmpDir+"dtw.csv", delimiter=",")
def main():
NumOfData = 500 # データの数
#乱数を用いて配列Xを生成
X = np.random.rand(NumOfData,500) # 500次元ベクトルのデータ
#乱数を用いて配列Yを生成
Y= np.random.rand(NumOfData,300) # 300次元ベクトルのデータ
# 1次元配列ずつ実行ファイルに渡し計算する
dtw1 = []
start = time.time()
for x,y in zip(X,Y):
dtw1.append(dtw1d(x,y))
print("time of loop by dtw1d: ", time.time() - start)
# print("result of dtw1d", np.array(dtw1))
# 2次元配列全体を実行ファイル全体に渡し計算する
start = time.time()
dtw2 = dtw2d(X,Y)
print("time of loop by dtw2d: ", time.time() - start)
# print("result of dtw2d", np.array(dtw2))
if __name__ == "__main__":
main()
これを実行した結果は以下である.
$ time of loop by dtw1d: 12.996145248413086
$ time of loop by dtw2d: 7.628435850143433
$X$側の次元を500,$Y$側の次元数を300,データ数を500にするとこの様な結果になりました.もちろん
次元数を増やすと計算時間がかかるだろう.データ数に関しても10倍になれば実行時間も10倍になる.こう考えるとバッチ処理的な手法は効果的だと言えます.
これでpythonで時系列データをいじっている途中にもDTWを比較的速く計算することが可能になります.
これらの内容はgithubにありますので,readmeなどを参考にしてください.
6. 課題
コンパイラ言語を使用することで高速になりましたと言っても,絶対的に考えると多少の時間はかかってしまいます.DTWを高速化する手法はいくつか論文がありますので,それを参考に実装するのもありですね.
あと,実行ファイルにデータを渡すのに一度ファイルに書き出してっとなんかダサいので,こちらの記事の様なイケてる方法を採用するのがベストですね.
7. 最後に
なにか,ご指摘事項がありましたらフィードバックいただけると幸いです.