パターン認識のパーセプトロンの学習規則について説明します。
まずは人工知能における機械学習の分類から説明します。
機械学習の学習方法は教師あり学習、教師なし学習、強化学習に分けられます。
一つずつ見ていきましょう。
教師あり学習とは学習データに正解を与えて学習を与える方法です。
例えば犬の画像を見せて、これは犬の画像だよと教えます。
何枚も教える事で人工知能は犬の画像を見分けられるようになります。
これが教師あり学習です。
教師なし学習とは学習データに正解を与えないで学習をさせる方法です。
教師なし学習が得意とするのはクラスタリングです。
これはデータの類似度に基づいてデータをグループ分けする方法です。
強化学習は学習データに正解は無いが、望ましい行動をした時に報酬を与えて報酬を最大化するような行動を取るような人工知能です。
将棋AIや囲碁AIといったゲームAIが打ち手を学習する際の手法として用います。
今回は教師あり学習であるパターン認識をやりたいと思います。
その一つがパターン認識におけるパーセプトロンの学習規則です。
最近ですと機械学習はライブラリを使いますが今回はゼロから人工知能を作ります。
言語にPythonを選んだのはグラフ表示がやりやすいからだけです。
人工知能や機械学習における根本的な仕組みは言語による依存はありません。
基本的に通常の言語であればどのプログラミング言語でもAIは作れます。
まずは実際にPythonで動かしてみましょう。
こちらのコードをご覧ください。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('input.xlsx', sheet_name=0)
# 欠損値が一つでも含まれる行を削除
df = df.dropna(how='any')
x1 = df['x1']
y1 = df['y1']
x2 = df['x2']
y2 = df['y2']
w0 = -54
w1 = 13
w2 = -15
count = 0
p = 1
i = 1
j = 1
xx0 = 1
data_len = len(df)
print("データ行は",data_len,"行",sep='')
while count < data_len*2:
j = 1
for zz in range(2):
for yy in range(data_len):
xx1 = df.iat[yy,0+zz*2]
xx2 = df.iat[yy,1+zz*2]
if zz == 0 and w0 + w1*xx1 + w2*xx2 <= 0:
w0 = w0 + p*xx0
w1 = w1 + p*xx1
w2 = w2 + p*xx2
count = 0
elif zz == 1 and w0 + w1*xx1 + w2*xx2 >= 0:
w0 = w0 - p*xx0
w1 = w1 - p*xx1
w2 = w2 - p*xx2
count = 0
else:
count = count + 1
j = j + 1
if count >= data_len*2:
break
if count >= data_len*2:
break
if count >= data_len*2:
break
i = i + 1
print("学習完了")
print("")
height = int(input("身長を入力してください:"))
weight = int(input("体重を入力してください:"))
if w0 + w1*height + w2*weight >= 0:
print("その人はグループ1です")
else:
print("その人はグループ2です")
xmin = np.min(x1) if np.min(x1) < np.min(x2) else np.min(x2)
ymin = np.min(y1) if np.min(y1) < np.min(y2) else np.min(y2)
xmax = np.max(x1) if np.max(x1) > np.max(x2) else np.max(x2)
ymax = np.max(y1) if np.max(y1) > np.max(y2) else np.max(y2)
x = np.arange(xmin-1, xmax+1, 0.1)
y = -w1/w2*x - w0/w2
plt.xlim(xmin-1, xmax+1)
plt.ylim(ymin-1, ymax+1)
plt.plot(x, y)
# 散布図を描画
plt.scatter(x1, y1, c='red')
plt.scatter(x2, y2, c='green')
plt.scatter(height, weight, c='yellow')
plt.show()
このコードをPythonコードとして保存してください。
プログラム実行に必要なimportは各自インストールをお願いします。
次にこのPythonコードと同じフォルダに次のExcelファイルを作成してください。
ファイル名はinput.xlsxでお願いします。
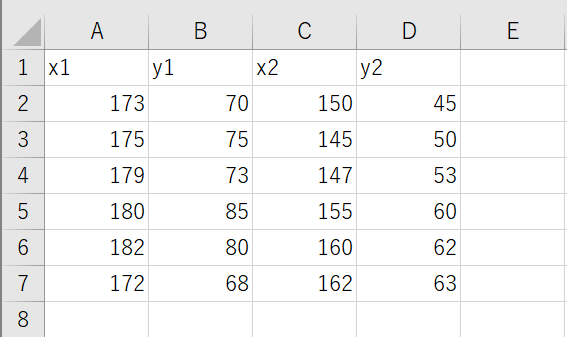
x1が1つ目のグループの身長、y1が1つ目のグループの体重、
x2が2つ目のグループの身長、y2が2つ目のグループの体重を表しています。
身長と体重1セットで1人分のデータです。
コマンドラインの実行はこのようになります。
身長、体重の入力は整数値なら何でもいいです。

するとこのようなグラフ結果が得られます。
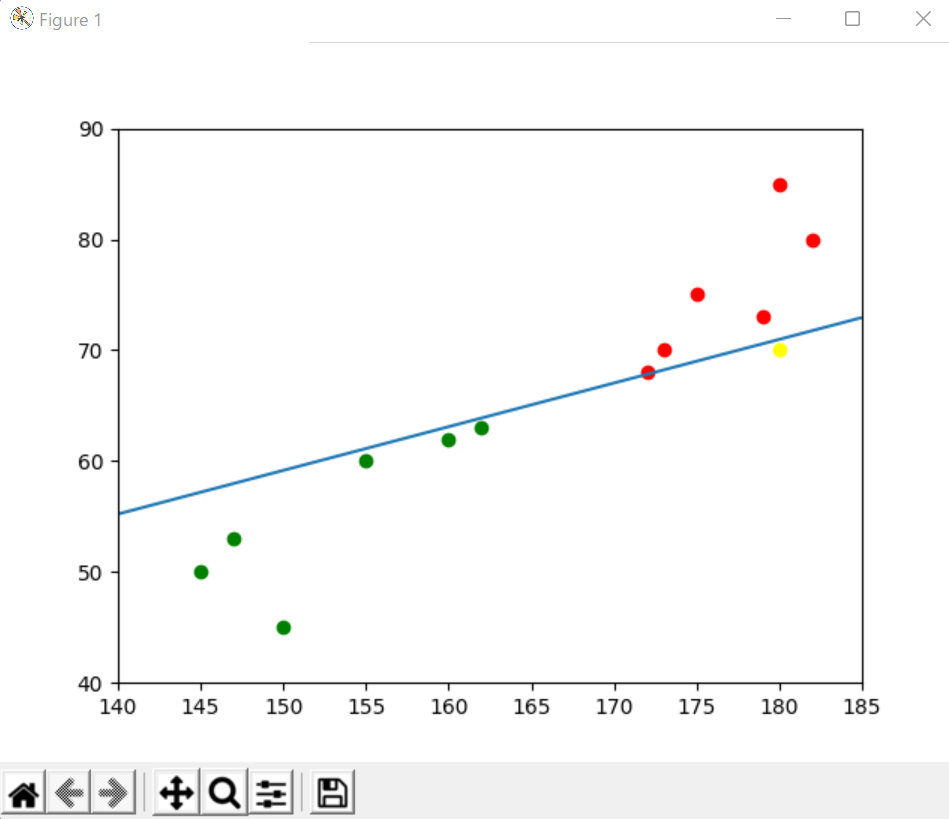
赤いプロットのx軸がエクセルデータのx1列、
赤いプロットのy軸がエクセルデータのy1列、
緑のプロットのx軸がエクセルデータのx2列、
緑のプロットのy軸がエクセルデータのy2列、を表しています。
黄色いプロットは入力したデータです。
グラフに表示されている直線グラフが学習によって得られた直線であり、グループを分類する為の直線です。
この直線を境に赤いプロットの方に入力されたプロットがあれば、1つ目のグループ、緑のプロットの方に入力されたプロットがあれば、2つ目のグループと認識します。
エクセルのデータは好きなように変えてOKです。
エクセルデータは例えばこのように変えます。
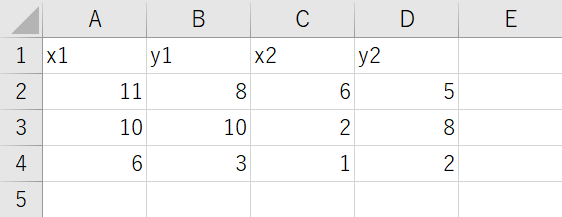
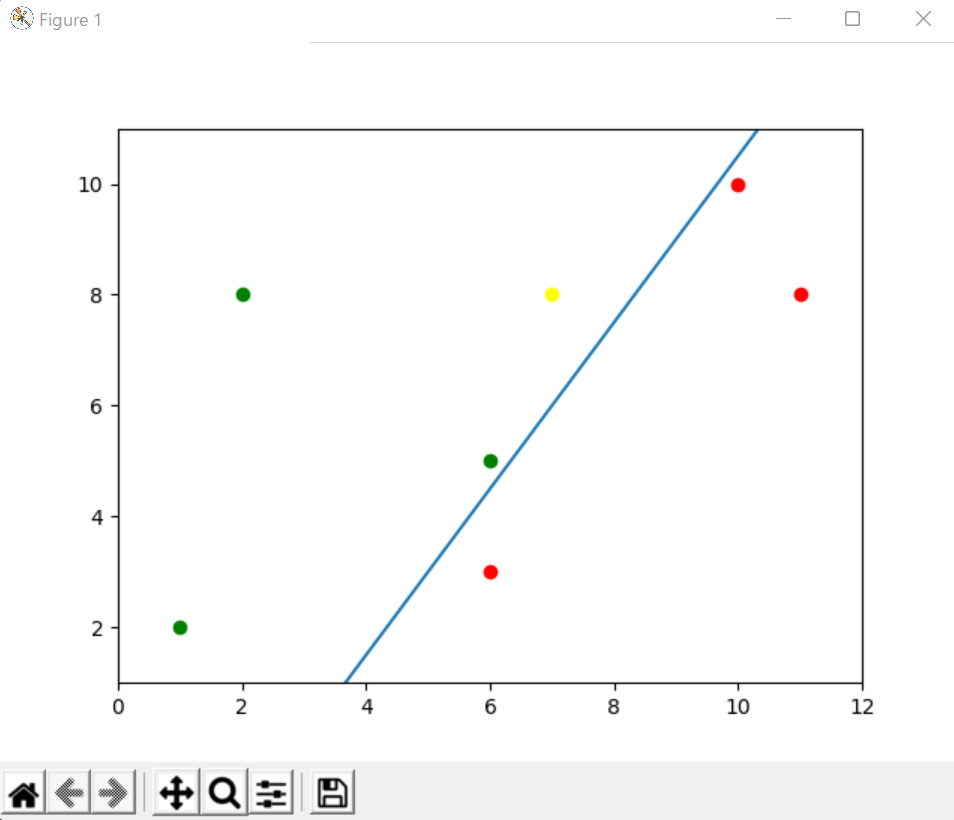
実行結果はこんな感じです。
身長、体重の入力はそのままなので気になる方はその表示も変えるといいでしょう。
今回は身長と体重の2つの項目の入力によるデータ分類なので2種類の数値データのセットがあれば学習出来ます。

学習結果はこうなります。
これが教師あり学習における手法の一つ、パターン認識のパーセプトロンの学習規則です。
以降、パターン認識の詳しい内容について、以下に記載します。
上記の説明では、2次元の特徴空間のグラフで説明しましたが、わかりやすく説明する為に、1次元の特徴空間のグラフで説明します。
なぜなら、d次元の特徴空間のグラフをパーセプトロンの学習規則でパターン認識を行う時には、d + 1 次元空間とした重み空間を考える必要があるからです。
まず、特徴空間の境界線を決める線形識別関数は以下の式で表されます。
g(x)=\omega_{0}+\sum_{j=1}^d \omega_{j} x_{j}
特徴空間が1次元なら、
g(x) = \omega_{0}+\omega_{1} x_{1}
特徴空間が2次元なら、
g(x) = \omega_{0}+\omega_{1} x_{1}+\omega_{2} x_{2}
特徴空間が3次元なら、
g(x) = \omega_{0}+\omega_{1} x_{1}+\omega_{2} x_{2}+\omega_{3} x_{3}
$ \omega $ は重みベクトルと呼ばれるものです。
この定義を説明したいと思います。
実例をあげましょう。
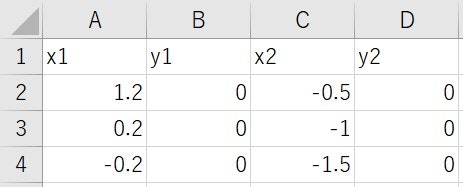
以下の1次元特徴を持つデータ群があったとします。
Excelのファイルに記述しています。
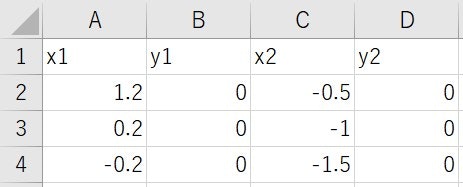
x1は1つ目のグループのデータ数値、y1は1次元なので無し。
x2は2つ目のグループのデータ数値、y2は1次元なので無し。
これをグラフで表すと、こうなります。
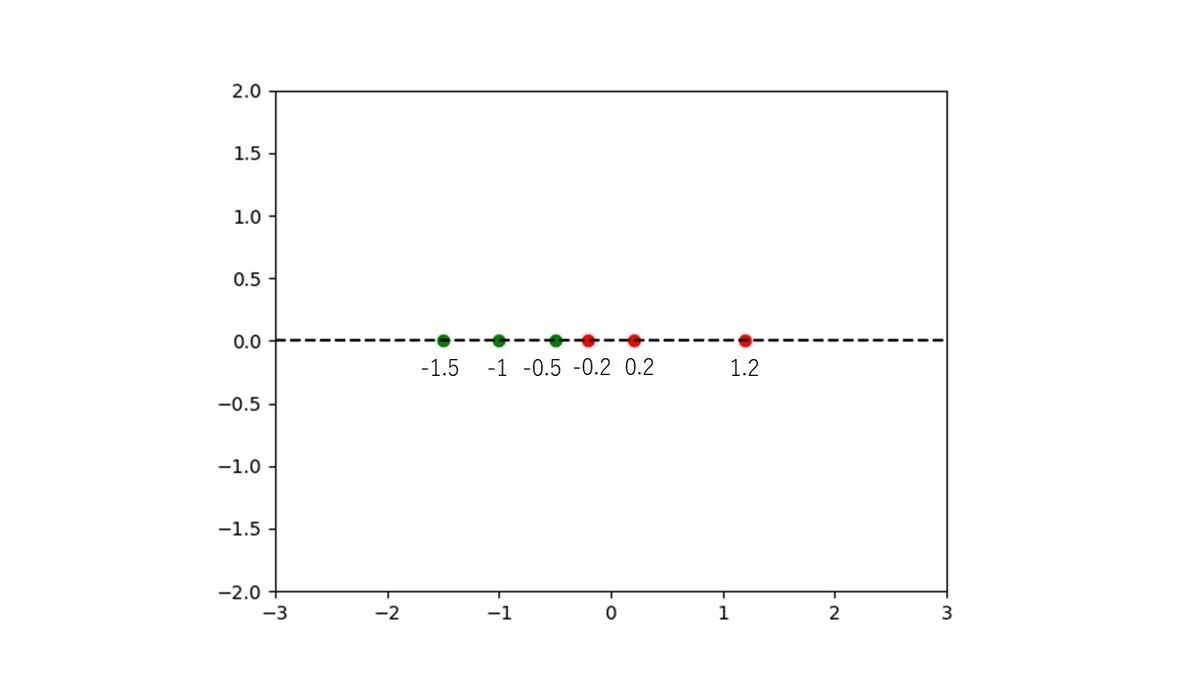
この時、プロットを以下の式で考えます。
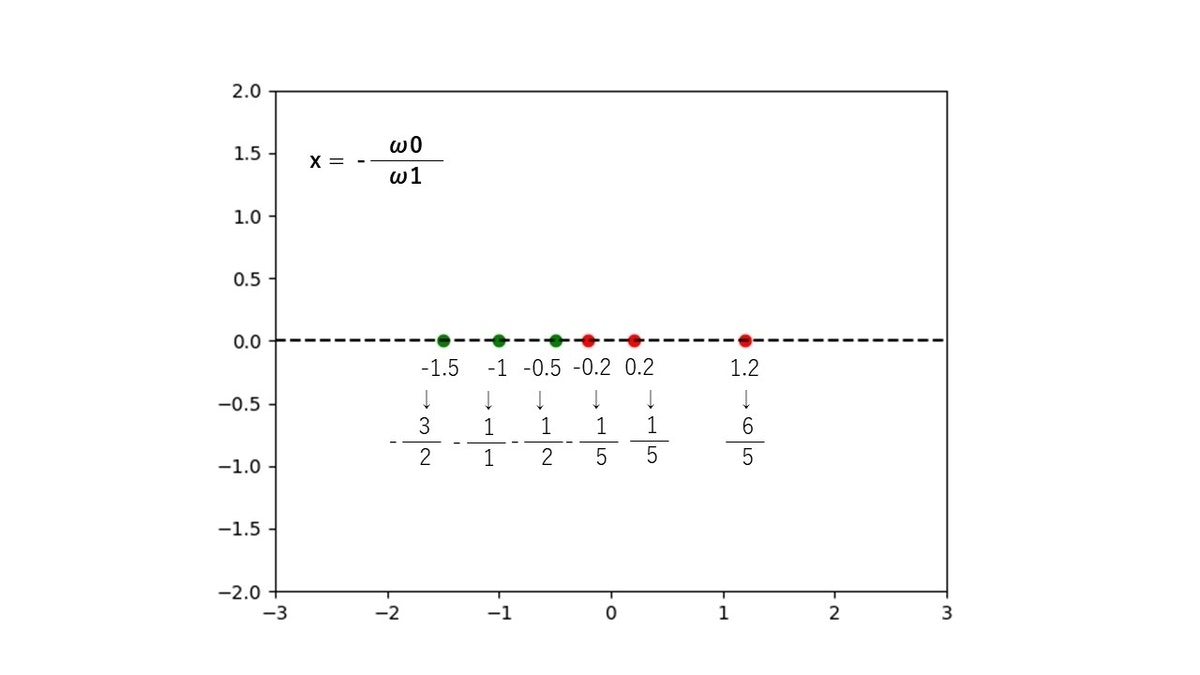
x = - \frac{\omega_{0}}{\omega_{1}}
式変形した図が以下です。
この時、上記の1次元の特徴空間のグラフから2次元の重み空間を見てみましょう。
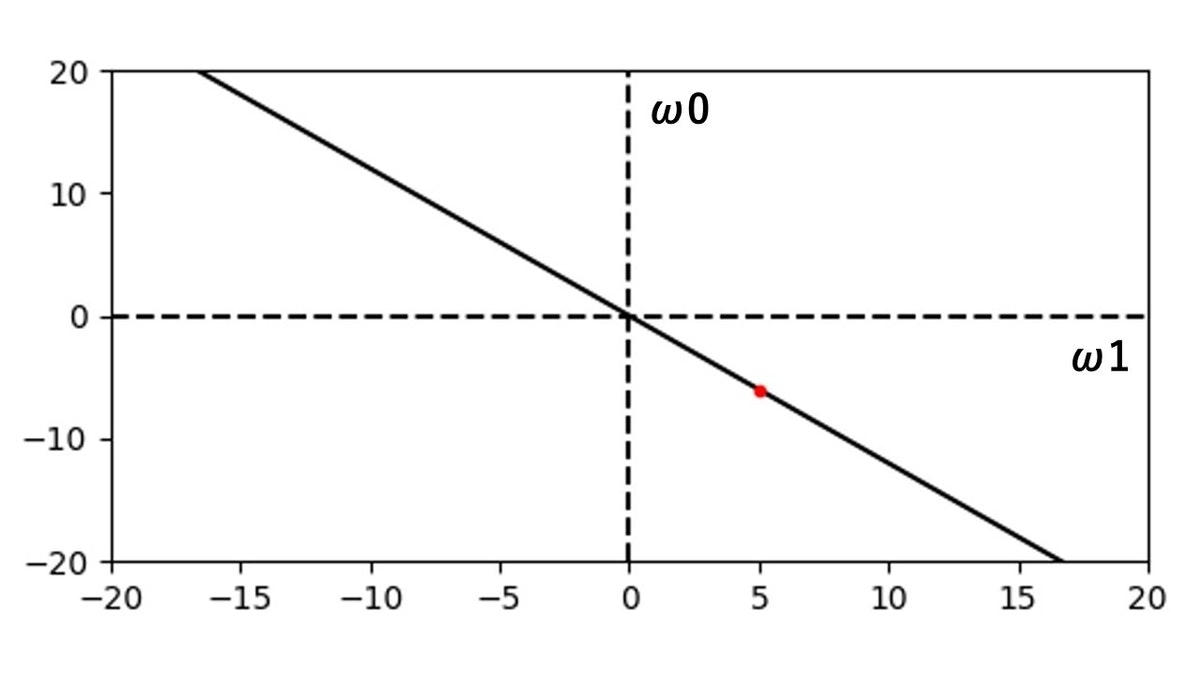
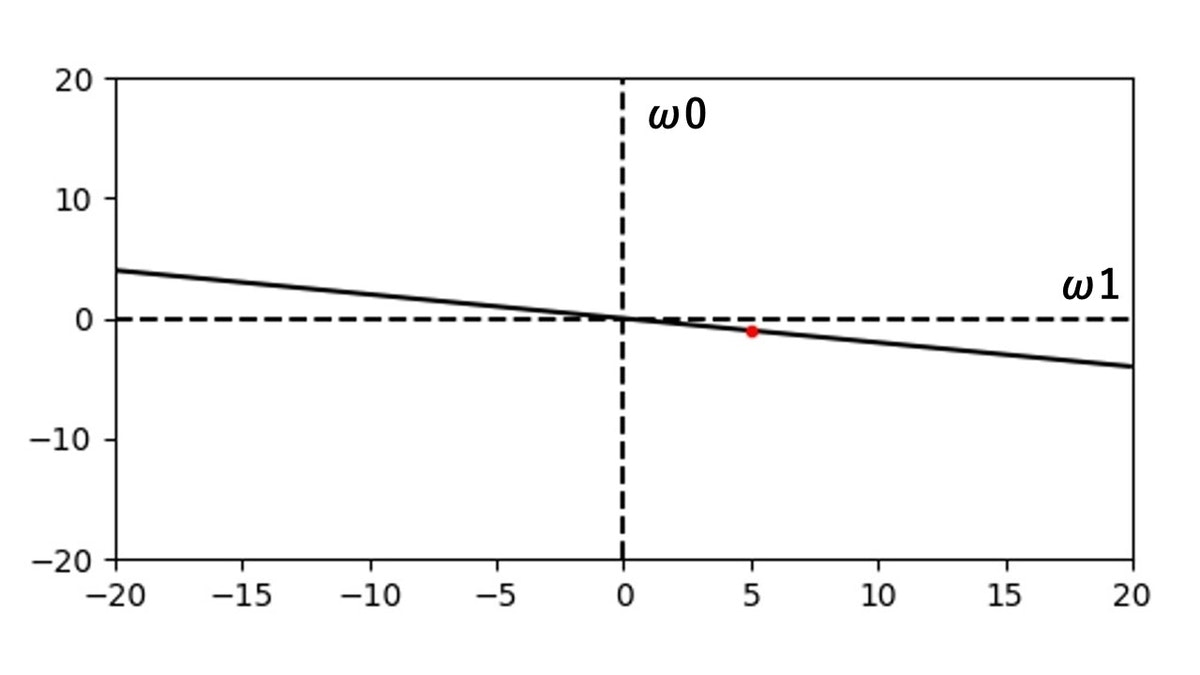
まず、特徴空間の一番右端の赤いプロットの $1.2$ の数値のプロットを見てみます。
このプロットを、$x = - \frac{\omega_{0}}{\omega_{1}}$ の形に変えてみます。
この時、$\omega_{1}$ は正の値の時だけを考えてみます。
すると、$\omega_{0} = -6$ , $\omega_{1} = 5$ となり、$\omega_{1}$ を横軸、 $\omega_{0}$ を縦軸とした2次元グラフを考えてみます。
すると、$\omega_{1} = 5$ , $\omega_{0} = -6$ の点をグラフ上に書けます。
また、この座標点と原点を結ぶ直線を引いてみましょう。
座標点を赤色、直線を黒色で表した図が以下です。
次のプロットの数値 $0.2$ も考えてみましょう。
$\omega_{0}$ , $\omega_{1}$ の数値はそれぞれ、 $\omega_{1} = 5$ , $\omega_{0} = -1$ となります。
こうやって、プロット6つ全ての直線を引いた図が以下になります。
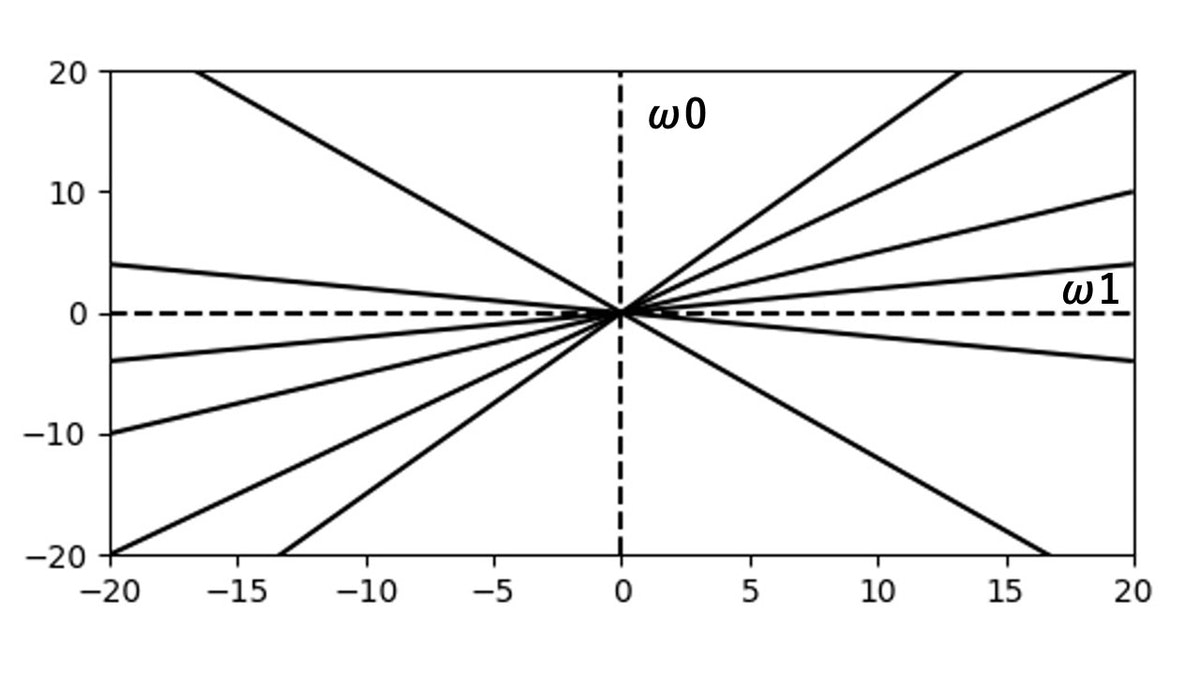
この2次元グラフが、1次元特徴空間における重み空間になります。
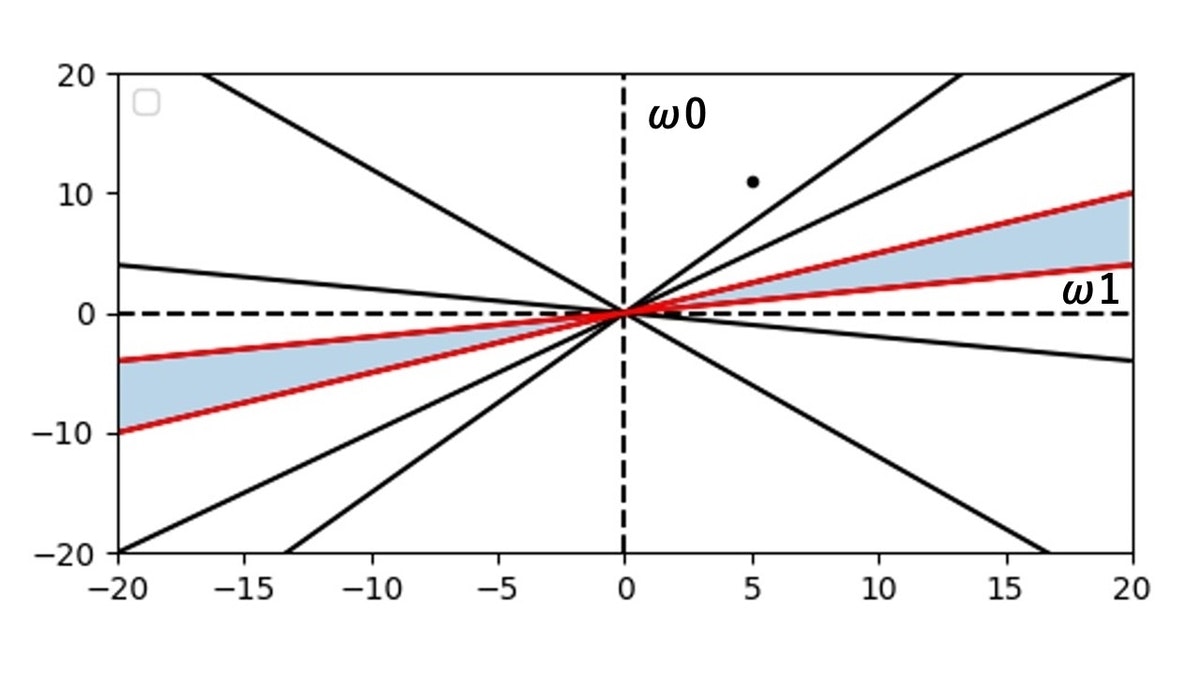
さて、この重み空間のグラフを使って何をするのかと言うと、まずパーセプトロンの学習規則では、 $\omega$ の値をランダムに設定します。
ここでは、 $\omega_{1} = 5$ , $\omega_{0} = 11$ としましょう。
それを図示すると以下になります。
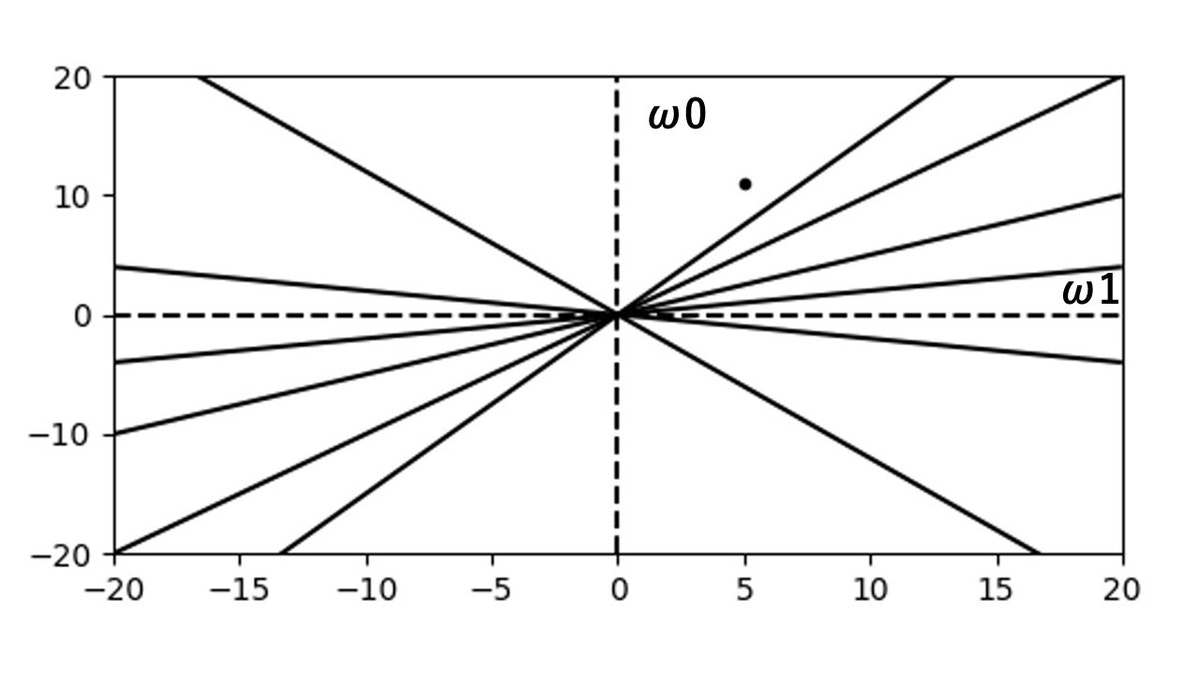
さて、パーセプトロンの学習規則では図の点を以下の暗い水色で塗っている部分に移動させたいと考えています。
そうすると、学習完了になります。
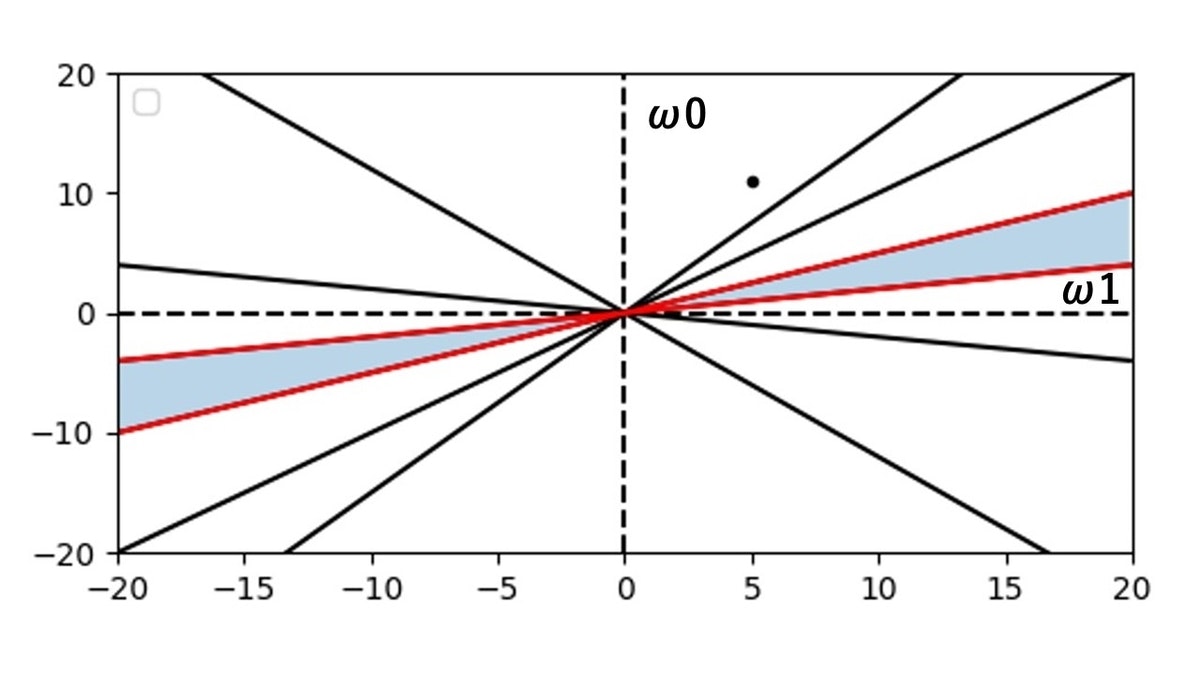
特徴空間の緑色のプロット3つと赤色のプロット3つが、重み空間のグラフにおいて直線で表されていて、その合計6つの直線の境目、つまり $\omega_{1}$ が正の時にグラフ上から上から3つ目の直線と下から3つ目の直線の間の部分が学習完了場所となります。
赤色の直線2本で囲っている暗い水色の面の所です。
この時の、 $\omega_{1}$ , $\omega_{0}$ の値を $ax + by + c = 0$ の公式に則って当てはめます。
なので、 $\omega_{1}x + \omega_{0} = 0$ となります。
ここで、気をつけて欲しいのが、 $ax + by + c = 0$ の公式の $x$ が $\omega_{1}$ に対応し、 $y$ が $\omega_{0}$に対応するという事です。
$\omega_{1}$と $\omega_{0}$ の横軸と縦軸で表したグラフですので、そうなります。
$b = 1$ , $c = 0$ となります。
$c = 0$ なのは原点を通るためです。
$c$ は直線の方程式の切片です。
式変形すれば、 $x = - \frac{\omega_{0}}{\omega_{1}}$ になりますね。
これは、 $x =$ の直線になるので、一次元を線形分離出来ます。
線形分離については後述します。
特徴空間が二次元の場合は重み空間は三次元ですので、 $ax + by + cz + d = 0$ の公式に則って、 $\omega_{1}x + \omega_{2}y + \omega_{0} = 0$ になりますね。
$c = 1$ , $d = 0$ となります。
同じく原点を通るので、 $d$ は $0$ です。
これは平面の方程式です。
三次元空間については後述します。
式変形して、 $y =$ の式に直せば、 $y = - \frac{\omega_{1}}{\omega_{2}}x - \frac{\omega_{0}}{\omega_{2}}$ の式になります。
これは直線の方程式ですので、二次元の特徴空間の場合は直線で線形分離を行います。
同じく線形分離については後述します。
では、どうやって座標点を移動するかというと、ここで直線の方程式の性質を使います。
それは以下の事です。
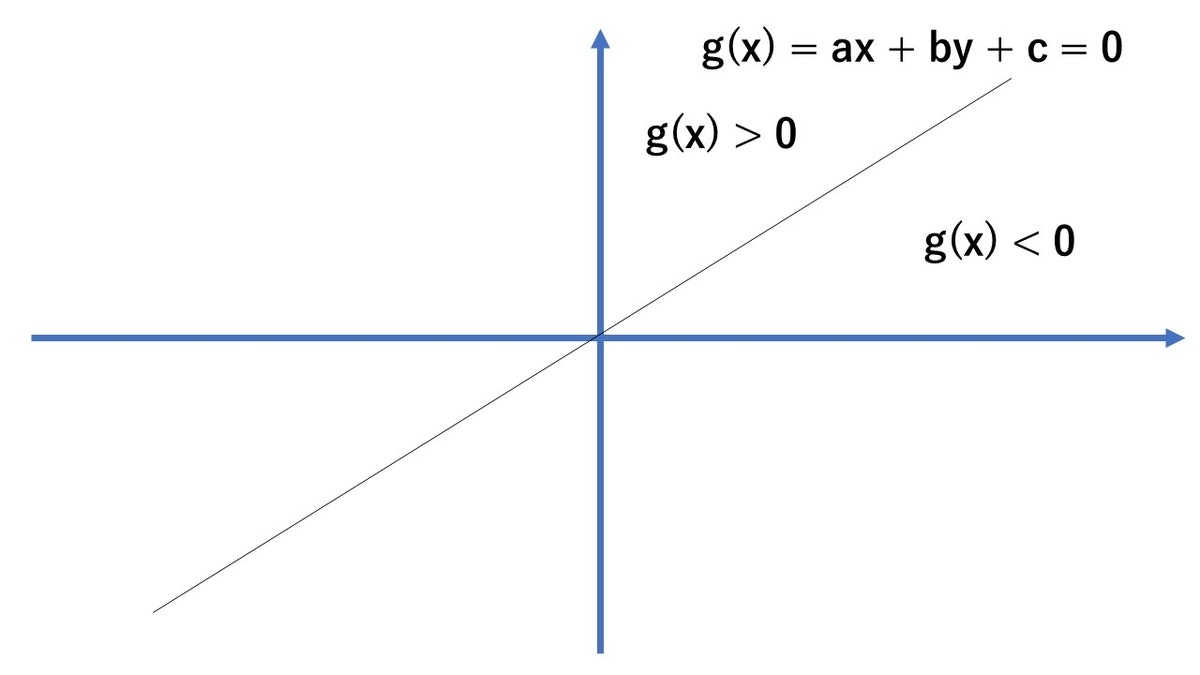
$g(x) = ax + by + c = 0$ が $g(x) > 0$ の時は、その座標点は直線の左側にあり、 $g(x) < 0$ の時は、その座標点は直線の右側にあるというものです。
この性質を使います。
するとどうでしょう。
先ほどのこちらのグラフ、それぞれの直線毎に座標点の $\omega_{1}$ , $\omega_{0}$ の値を代入すれば、 $g(x)$ の値が正か負かを判断して、座標点が直線の左側にあるか右側にあるか、わかりそうですね。
なので、直線1つ毎に対して、座標点が、その直線の左側にあるか右側にあるか判定して、反対側に来て欲しい時は座標点の更新を行えば、暗い水色の面積の所まで、座標点を移動出来ます。
その座標点の更新の公式が以下です。
\begin{cases}\omega_{i} = \omega_{i} + \rho\cdot x \\ \omega_{j} = \omega_{j} - \rho\cdot x \end{cases}
$i$ , $j$ は多クラス( $c > 2$ ) を表しています。
今回は、赤色のクラスのプロットと緑色のクラスのプロットの2クラスです。
パーセプトロンの学習規則は、パターンが正しく識別できなかった時に限って重みの修正を行う事から、誤り訂正法と呼ばれています。
また、 $\rho$ は任意の固定された値であり、固定増分法と言われています。
座標点の更新は、どのタイミングで行うかというと、プロット6つの直線の方程式 $g(x)$ に順番に座標点の座標を代入し、正負を判断して、間違っていればカウンタをリセットして、6回連続で正負の判定が正しくなるまで無限ループします。
6回連続で、 $g(x)$ の正負が正解すればパターン認識の学習完了になります。
では、 $\omega$ の初期値、 $\omega_{1} = 5$ , $\omega_{0} = 11$ と $\rho$ の初期値、 $\rho = 2.0$ と設定した時のパターン認識の学習の推移を見ていきましょう。
初期座標点から青い矢印の推移を移動して、最終到達点に到着している事がわかります。
これで学習完了です。
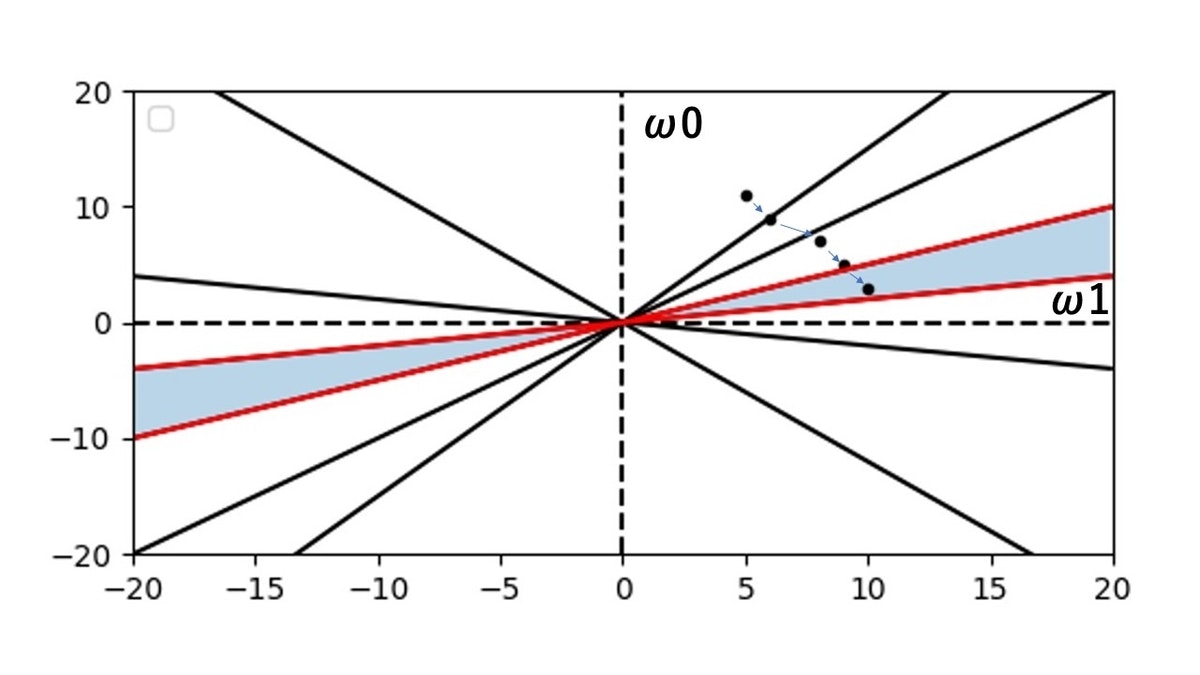
学習パターンが、線形分離可能ならば、このアルゴリズムは有限回の繰り返しで解領域内の重みベクトルに到達します。
これを、パーセプトロンの収束定理と言います。
線形分離可能とは二次元の場合、二つのプロットの集合を直線で分離出来る事を言います。
また、パーセプトロンの収束定理は数学的に証明されており、特徴空間を2次元、3次元、4次元と特徴の数を増やしていっても、線形分離可能であれば同じ定理が成り立ちます。
特徴空間が2次元の場合は、重み空間は3次元になりますが、その場合、重み空間の線形識別関数は直線ではなくて、平面で表されます。
原点を通る複数の平面の表側と裏側の位置判定で座標点の位置を判断し、パターン認識を行います。
また、このような重み空間における直線や平面は自動的に任意の直線や平面が定義されます。
最後に、今回解説に使った1次元特徴空間におけるパーセプトロンの学習規則のパターン認識のプログラムのソースコードを掲載しておきます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_excel('input_one.xlsx', sheet_name=0)
# 欠損値が一つでも含まれる行を削除
df = df.dropna(how='any')
x1 = df['x1']
y1 = df['y1']
x2 = df['x2']
y2 = df['y2']
w0 = 11
w1 = 5
mylist_w0 = []
mylist_w1 = []
mylist_w0.append(w0)
mylist_w1.append(w1)
x = -w0/w1
ymin, ymax = -2, 2
xmin, xmax = -3, 3
plt.ylim(ymin,ymax)
plt.xlim(xmin,xmax)
plt.vlines(x,ymin,ymax)
plt.hlines(0, xmin, xmax, colors='black', linestyle='dashed')
# 散布図を描画
plt.scatter(x1, y1, c='red')
plt.scatter(x2, y2, c='green')
plt.show()
count = 0
p = 2.0
i = 1
j = 1
xx0 = 1
while count < 6:
j = 1
for zz in range(2):
for yy in range(3):
xx1 = df.iat[yy,zz*2]
print("a = ",xx1,sep="")
if zz == 0 and w0 + w1*xx1 <= 0:
w0 = w0 + p*xx0
w1 = w1 + p*xx1
print("学習",i,"周目 ","クラス",zz+1," パターンx",j," w0 = ",w0,"!",sep='')
print("学習",i,"周目 ","クラス",zz+1," パターンx",j," w1 = ",w1,"!",sep='')
count = 0
x = -w0/w1
plt.ylim(ymin,ymax)
plt.xlim(xmin,xmax)
plt.vlines(x,ymin,ymax)
plt.hlines(0, xmin, xmax, colors='black', linestyle='dashed')
# 散布図を描画
plt.scatter(x1, y1, c='red')
plt.scatter(x2, y2, c='green')
plt.show()
mylist_w0.append(w0)
mylist_w1.append(w1)
elif zz == 1 and w0 + w1*xx1 >= 0:
w0 = w0 - p*xx0
w1 = w1 - p*xx1
print("学習",i,"周目 ","クラス",zz+1," パターンx",j," w0 = ",w0,"!",sep='')
print("学習",i,"周目 ","クラス",zz+1," パターンx",j," w1 = ",w1,"!",sep='')
count = 0
x = -w0/w1
plt.ylim(ymin,ymax)
plt.xlim(xmin,xmax)
plt.vlines(x,ymin,ymax)
plt.hlines(0, xmin, xmax, colors='black', linestyle='dashed')
# 散布図を描画
plt.scatter(x1, y1, c='red')
plt.scatter(x2, y2, c='green')
plt.show()
mylist_w0.append(w0)
mylist_w1.append(w1)
else:
print("学習",i,"周目 ","クラス",zz+1," パターンx",j," w0 = ",w0,sep='')
print("学習",i,"周目 ","クラス",zz+1," パターンx",j," w1 = ",w1,sep='')
count = count + 1
j = j + 1
print("count ",count,sep='')
if count >= 6:
break
if count >= 6:
break
if count >= 6:
break
i = i + 1
fig = plt.figure(figsize=(12, 8), facecolor="w")
ax = fig.add_subplot(2, 2, 1, title="")
url = "input_one.xlsx"
data1 = pd.read_excel(url, usecols=[0])
data2 = pd.read_excel(url, usecols=[2])
mydata1 = data1.values
mydata2 = data2.values
x = np.arange(-20, 20, 0.1)
plt.xlim(-20,20)
plt.ylim(-20,20)
for index in range(len(mydata1)):
tmp = mydata1[index]
y = -tmp*x
ax.plot(x, y, c='black')
if index == 2:
under = tmp
for index in range(len(mydata2)):
tmp = mydata2[index]
y = -tmp*x
ax.plot(x, y, c='black')
if index == 0:
over = tmp
for index in range(len(mylist_w0)):
ax.plot(mylist_w1[index], mylist_w0[index],marker='.',c='black')
ymin, ymax = -20, 20
ax.vlines(0, ymin, ymax, colors='black', linestyle='dashed')
ax.hlines(0, ymin, ymax, colors='black', linestyle='dashed')
y1 = -under*x
y2 = -over*x
ax.plot(x, y1, label="",c='red')
ax.plot(x, y2, label="",c='red')
ax.fill_between(
x,
y1,
y2,
alpha=0.3,
interpolate=True,
)
ax.legend()
plt.show()
それと入力ファイルに使用したExcelデータのスクリーンショットも再度貼っておきます。
input_one.xlsxという名前で保存してプログラムファイルと同じディレクトリに置いて実行してください。
以上、パターン認識、パーセプトロンの学習規則の解説でした。
読んで頂きありがとうございます。