はじめに
Transcribeを使うことで、音声データの文字起こしを簡単に行うことができます。しかし、Transcribeの処理は非同期で行われ、完了後にS3へ結果が格納されるため、適切に処理するためにはイベントドリブンの仕組みを用意する必要があります。
また、Transcribeの出力データはJSON形式であり、文字起こしの全文を取得するにはデータの構造を理解する必要があります。本記事では、Transcribeの文字起こし結果を取得し、DynamoDBに格納する方法を詳しく解説します。
本記事のポイント:
- Transcribeの非同期実行ジョブの完了をEventBridgeで検知し、Lambdaを実行
- Lambda関数でTranscribeの文字起こし結果を取得
- 文字起こしデータを解析し、DynamoDBへ格納
こちらも参考にして下さい
アーキテクチャ
処理の流れは以下の通りです。
1.Transcribeのジョブが完了すると、S3に結果が保存され、EventBridgeがイベントを検知
2.EventBridgeがLambda関数をトリガーし、文字起こし結果を取得
3.Lambda関数がS3から文字起こしデータを取得し、DynamoDBに格納
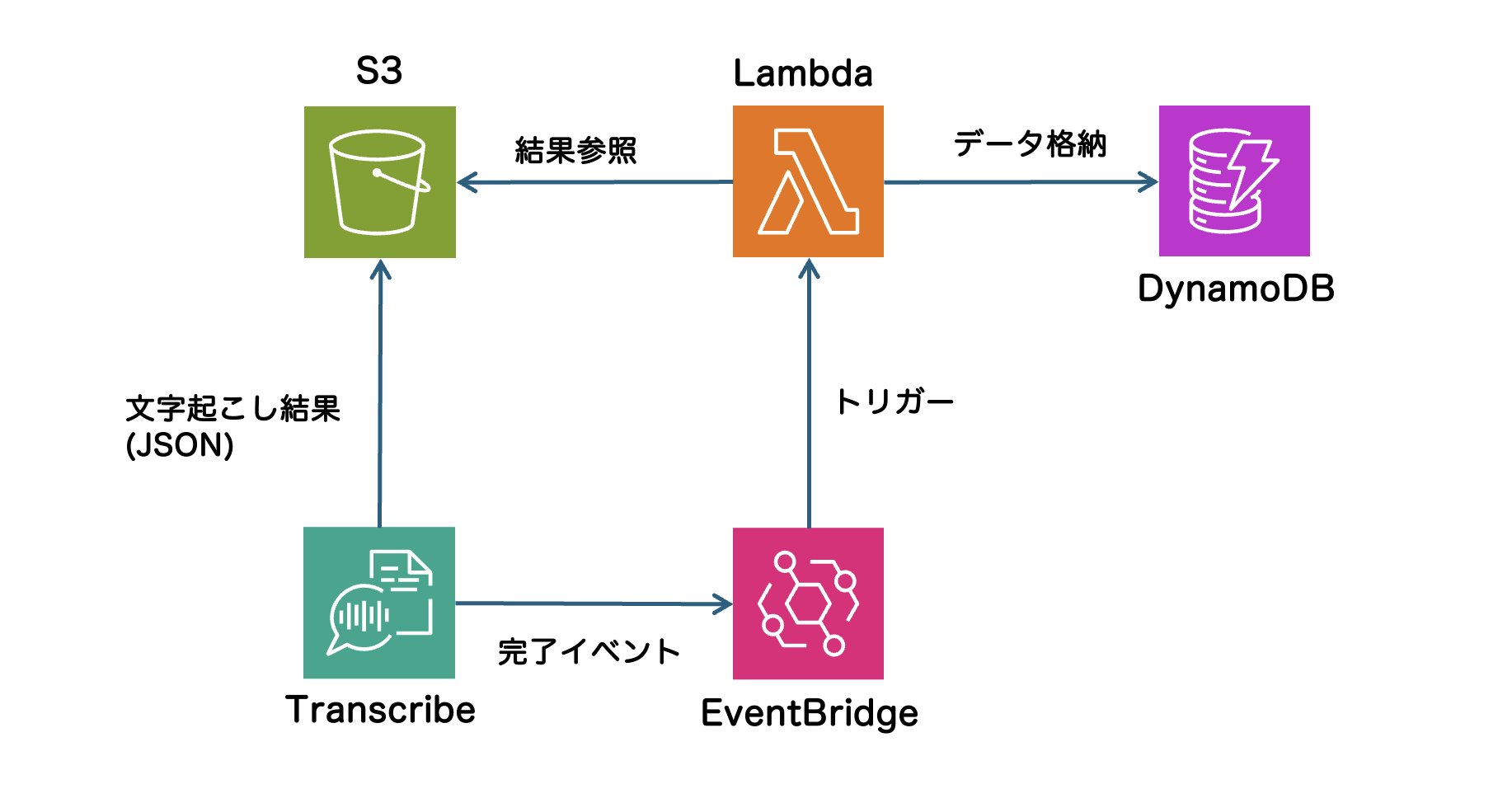
Transcribeの完了をEventBridgeで検知し、Lambdaをトリガー
(1) EventBridge ルールの作成(Transcribeの完了を検知)
以下の設定でルールを作成し、Transcribeのジョブが完了(COMPLETED)した際に、イベントを発火させます。
- ルールタイプ:イベントパターンを持つルール
- イベントソース:AWSサービス
- サービス名:Transcribe
- イベントタイプ: Transcribe Job State Change
- 特定のステータス:COMPLETED
カスタムイベントパターンに、次のJSONを入力してもOKです。
{
"source": ["aws.transcribe"],
"detail-type": ["Transcribe Job State Change"],
"detail": {
"TranscriptionJobStatus": ["COMPLETED"]
}
}
(2) ターゲットの設定(Lambda関数をトリガー)
- ターゲットタイプ:AWSのサービス
- ターゲットの選択:Lambda関数
- 関数:Transcribeの結果を処理するLambda関数(※後述)
- 実行ロール:Lambdaを実行するためのロールを設定
Lambda関数でTranscribeの結果を取得し、DynamoDBに格納
(1) Transcribeの結果項目説明
基本情報
| 項目 | 型 | 説明 |
|---|---|---|
| jobName | string | Transcribeのジョブ名 |
| accountId | string | ジョブを実行したAWSアカウントID |
| status | string | ジョブのステータス (COMPLETED, FAILED など) |
結果データ (results 内部)
全文の文字起こし
| 項目 | 型 | 説明 |
|---|---|---|
| results.transcripts | array | 文字起こし結果の配列(通常1つの要素を持つ) |
| results.transcripts[0].transcript | string | 文字起こしされた全文 |
単語ごとの詳細情報
| 項目 | 型 | 説明 |
|---|---|---|
| results.items | array | 単語や区切り記号ごとの詳細情報 |
| results.items[].id | integer | 単語ごとのインデックスID |
| results.items[].type | string | pronunciation(発音)または punctuation(句読点) |
| results.items[].alternatives | array | 認識候補の配列 |
| results.items[].alternatives[0].confidence | string | 認識の信頼度(0.0〜1.0) |
| results.items[].alternatives[0].content | string | 認識された単語や記号 |
| results.items[].start_time | string | 単語の開始時間(秒) |
| results.items[].end_time | string | 単語の終了時間(秒) |
出力例
{
"jobName": "<ジョブ名>",
"accountId": "<AWSアカウントID>",
"status": "COMPLETED",
"results": {
"transcripts": [
{
"transcript": "<文字起こしの全文>"
}
],
"items": [
{
"id": 0,
"type": "pronunciation",
"alternatives": [
{
"confidence": "0.813",
"content": "<単語>"
}
],
"start_time": "3.509",
"end_time": "3.63"
}
]
}
}
(2) Lamnda関数の作成
Lambdaの処理のポイント
- ジョブの結果からS3バケット名とオブジェクトキーを取得
- 全文の文字起こしを抽出
- 開始時間と終了時間を計算
- DynamoDB(※後述)にデータを格納
import json
import boto3
from urllib.parse import urlparse
from datetime import datetime, timedelta
s3 = boto3.client('s3')
transcribe = boto3.client('transcribe')
dynamodb = boto3.resource('dynamodb')
DYNAMODB_TABLE_NAME = "<DynamoDBテーブル名>"
table = dynamodb.Table(DYNAMODB_TABLE_NAME)
def lambda_handler(event, context):
print("Received event: ", json.dumps(event, indent=2))
# EventBridge のイベントからジョブ名を取得
job_name = event['detail']['TranscriptionJobName']
# Transcribe の結果を取得
response = transcribe.get_transcription_job(TranscriptionJobName=job_name)
transcript_uri = response['TranscriptionJob']['Transcript']['TranscriptFileUri']
# transcript_uri からバケット名とキーを取得
parsed_uri = urlparse(transcript_uri)
s3_path_parts = parsed_uri.path.lstrip('/').split('/')
s3_bucket = s3_path_parts[0] # バケット名
s3_key = '/'.join(s3_path_parts[1:]) # オブジェクトキー
# S3 から文字起こしデータを取得
try:
transcript_file = s3.get_object(Bucket=s3_bucket, Key=s3_key)
transcript_data = json.loads(transcript_file['Body'].read().decode('utf-8'))
# **全文の文字起こしを取得**
transcript_text = transcript_data['results']['transcripts'][0]['transcript']
# **全文の開始時間と終了時間を取得**
start_time = None
end_time = None
# 各単語ごとの時間情報をスキャン
for item in transcript_data['results']['items']:
if item['type'] == 'pronunciation': # 発音(単語)のみ対象
if start_time is None and 'start_time' in item:
start_time = float(item['start_time'])
if 'end_time' in item:
end_time = float(item['end_time'])
# **Transcribeの開始基準時刻(エンコード時刻)を取得**
creation_time = response['TranscriptionJob']['CreationTime'] # UTCのdatetimeオブジェクト
# **取得した秒数を UTC 時刻に変換**
if start_time is not None:
start_datetime = creation_time + timedelta(seconds=start_time)
else:
start_datetime = creation_time
if end_time is not None:
end_datetime = creation_time + timedelta(seconds=end_time)
else:
end_datetime = creation_time
# **年月日時分秒のフォーマットに変換**
start_time_str = start_datetime.strftime('%Y-%m-%d %H:%M:%S')
end_time_str = end_datetime.strftime('%Y-%m-%d %H:%M:%S')
# **DynamoDB に保存**
table.put_item(
Item={
"job_name": job_name,
"start_time": start_time_str,
"end_time": end_time_str,
"transcript": transcript_text
}
)
print("Data successfully saved to DynamoDB")
return {"statusCode": 200, "body": "Transcription processed and saved to DynamoDB"}
except Exception as e:
print(f"Error: {e}")
return {"statusCode": 500, "body": f"Error processing transcription: {str(e)}"}
(3) Lamnda関数に付与するロール
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "transcribe:GetTranscriptionJob",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::<Transcribe結果のバケット名>//*"
},
{
"Effect": "Allow",
"Action": "dynamodb:PutItem",
"Resource": "arn:aws:dynamodb:us-east-1:<AWSアカウントID>/:table/<DynamoDBテーブル名>/"
}
]
}
(4) DynamoDBテーブルの作成
以下でテーブルを準備します。
- パーティションキー:job_name
- ソートキー:start_time
実行結果
DynamoDBにデータが格納されることを確認します。
DynamoDBのデータ例:
{
"job_name": "<ジョブ名>",
"start_time": "2025-03-16 03:45:56",
"end_time": "2025-03-16 03:46:28",
"transcript": "<文字起こし全文>"
}
まとめ
イベントドリブンの仕組みにより、Transcribeの実行結果をDynamoDBに格納しました。
- Transcribeは非同期で音声データを処理し、結果をS3に格納する
- EventBridgeを使用することで、Transcribeのジョブ完了を検知し、Lambdaをトリガーできる
- Lambda関数はS3からTranscribeの結果を取得し、DynamoDBに格納
DynamoDBを使用することで、後続のデータ分析や検索が容易になると考えています。