はじめに
これまで使う機会がなかったAWSサービスを実際に使ってなんかしてみよう、ということで「キャプチャした音声をテキスト化してみよう!」と試してみました。
本記事では、FFmpeg × Kinesis × Transcribe を連携して、音声データをリアルタイムにAWSへストリーミングし、テキストへ変換する仕組みを構築します。
普段、AWSのKinesisやTranscribeを使う機会がない方でも、「こんな風に使えるんだ!」という発見があるかもしれません。
また、Kinesisのデータペイロードサイズ制約の仕様に直面しながら試行錯誤したポイントも紹介します。
本記事のポイント:
- FFmpegで音声をキャプチャし、Kinesisへストリーミング
- Lambdaでデータを受け取り、Transcribeに送信
- キャプチャした音声を文字起こしする流れを実装
- Kinesisのデータペイロードサイズに対応する方法
自分が「普段使わないAWSサービスを動かしてみる」という実験的な要素も含めつつ、実際に動く形で構築します。
こちらも参考にして下さい
アーキテクチャ
今回構築する音声解析のシステムは、以下の流れで処理されます。
1.音声の取得(FFmpeg)
- FFmpegを使用してマイクやシステム音声をキャプチャし、WAV形式のデータとしてリアルタイムに取得します。
2.Kinesisへのストリーミング(Kinesis Data Streams)
- キャプチャした音声データをKinesisにストリーミングします。
- ただし、Kinesisには 1MBのペイロード制限 があるため、大きな音声データは適切に分割する必要があります。
3.Lambdaでデータを受け取る
- Kinesisに送信されたデータをLambdaが処理し、一時的にS3へ保存します。
4.Transcribeで文字起こし
- S3にアップロードされた音声ファイルをTranscribeで解析し、テキストデータに変換します。
- Transcribeの結果はS3に保存されます。
全体構成図
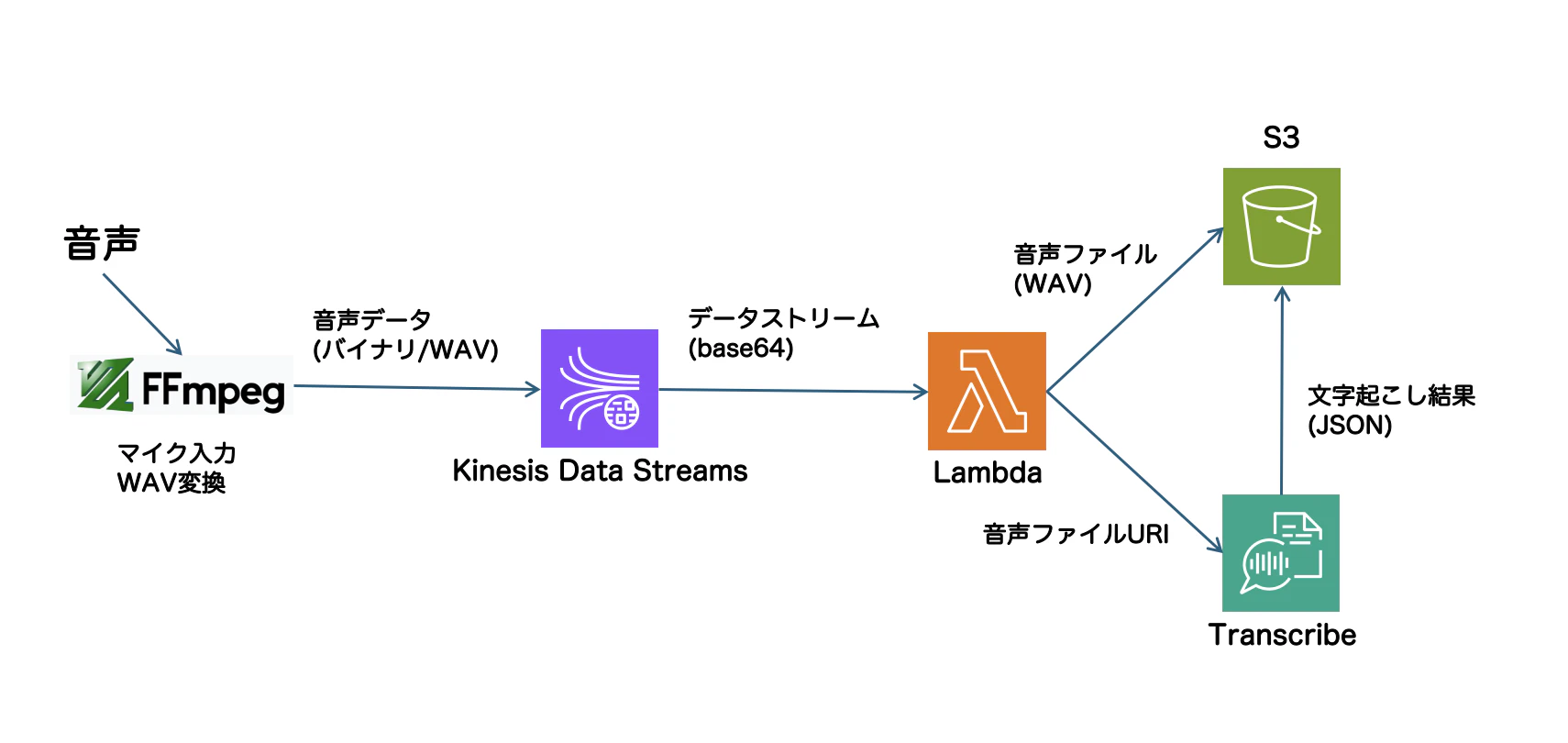
FFmpegで音声をキャプチャし、Kinesisへ送信
まずは、FFmpegを使用してリアルタイムに音声データを取得し、Kinesis Data Streamsに送信します。
FFmpegの準備
FFmpegがインストールされていない場合は、以下のコマンドでインストールします。
brew install ffmpeg
FFmpegで音声をキャプチャ
FFmpegを使用して、マイクまたはシステムの音声をキャプチャし、WAVフォーマットで標準出力に流します。
ffmpeg -f avfoundation -i ":1" -acodec pcm_s16le -ar 16000 -ac 1 -f wav -
-f avfoundation -i ":1":Macの音声入力デバイスを指定
-acodec pcm_s16le:16-bit PCMエンコーディング
-ar 16000:サンプルレート16kHz
-ac 1:モノラル
-f wav -:WAVフォーマットで標準出力へ
Kinesisの準備
音声データを送信するためのKinesis Data Streamを作成します。
aws kinesis create-stream --stream-name MyAudioStream --shard-count 1
このコマンドでMyAudioStreamという名前のストリームが作成されます。
Pythonで音声データをKinesisへ送信 その1
FFmpegで取得した音声データをKinesisに送信する基本的な実装を紹介します。
import subprocess
import boto3
STREAM_NAME = 'MyAudioStream'
REGION_NAME = 'us-east-1'
kinesis_client = boto3.client('kinesis', region_name=REGION_NAME)
def capture_and_send_audio():
ffmpeg_command = ['ffmpeg', '-f', 'avfoundation', '-i', ':1', '-acodec', 'pcm_s16le', '-ar', '16000', '-ac', '1', '-f', 'wav', '-']
process = subprocess.Popen(ffmpeg_command, stdout=subprocess.PIPE, stderr=subprocess.DEVNULL)
audio_data = process.stdout.read(1024 * 1024) # 1MB分のデータを読み取る
if audio_data:
response = kinesis_client.put_record(
StreamName=STREAM_NAME,
Data=audio_data,
PartitionKey='test'
)
print(f"✅ データ送信完了: SequenceNumber {response['SequenceNumber']}")
process.stdout.close()
process.wait()
capture_and_send_audio()
このコードでは、
- subprocess.Popen を使ってFFmpegを起動し、音声データを取得
- 1MB分のデータを読み取り、Kinesisに送信
- put_record メソッドを使い、データをKinesisストリームに送信
を行います。
Pythonで音声データをKinesisへ送信 その2
Kinesisには 1MBのペイロード制限 があるため、音声データは適切に分割する処理が必要です。
import subprocess
import boto3
import time
import struct
STREAM_NAME = 'MyAudioStream'
REGION_NAME = 'us-east-1'
SAMPLE_RATE = 16000
BITS_PER_SAMPLE = 16
CHANNELS = 1
MAX_RECORD_SIZE = 1048576 # 1MB制限
kinesis_client = boto3.client('kinesis', region_name=REGION_NAME)
def get_wav_header(data_size):
byte_rate = SAMPLE_RATE * CHANNELS * (BITS_PER_SAMPLE // 8)
chunk_size = 36 + data_size
return struct.pack('<4sI4s4sIHHIIHH4sI', b'RIFF', chunk_size, b'WAVE', b'fmt ', 16,
1, CHANNELS, SAMPLE_RATE, byte_rate, CHANNELS * (BITS_PER_SAMPLE // 8),
BITS_PER_SAMPLE, b'data', data_size)
def send_audio_to_kinesis():
partition_key = str(int(time.time()))
print("🔄 音声ストリーミング開始...")
ffmpeg_command = ['ffmpeg', '-f', 'avfoundation', '-i', ':1', '-acodec', 'pcm_s16le', '-ar', str(SAMPLE_RATE), '-ac', '1', '-f', 'wav', '-']
ffmpeg_process = subprocess.Popen(ffmpeg_command, stdout=subprocess.PIPE, stderr=subprocess.DEVNULL)
audio_data = b''
buffer_size = SAMPLE_RATE * 2
while True:
chunk = ffmpeg_process.stdout.read(buffer_size)
if not chunk:
break
audio_data += chunk
while len(audio_data) >= MAX_RECORD_SIZE:
data_chunk = audio_data[:MAX_RECORD_SIZE]
audio_data = audio_data[MAX_RECORD_SIZE:]
kinesis_client.put_record(StreamName=STREAM_NAME, Data=get_wav_header(len(data_chunk)) + data_chunk, PartitionKey=partition_key)
print("📤 データ送信...")
ffmpeg_process.stdout.close()
ffmpeg_process.wait()
if __name__ == "__main__":
send_audio_to_kinesis()
このコードでは、
- MAX_RECORD_SIZE (1MB) を超えないようにデータを分割
- 各チャンクに適切なWAVヘッダーを付与
- Kinesisに順次データを送信
といった処理を行い、大きな音声データでも適切に送信できるようにしています。
Kinesisで受信した音声データを処理する(Lambdaの実装)
Kinesisにストリーミングされた音声データを処理するために、AWS Lambdaを利用します。Lambdaの役割は以下の通りです。
- Kinesis Data Streams から音声データを取得する
- 取得したデータを一時的にS3に保存する
- 後続のTranscribe処理のためにS3のデータを整理する
Lambdaのセットアップ
Lambda関数を作成する前に、適切なIAMロールを設定する必要があります。
今回は以下の権限を設定しました。
- AWSLambdaBasicExecutionRole
- AmazonKinesisReadOnlyAccess
- AmazonTranscribeFullAccess
また、データを保存するS3バケットを作成し、そのS3にアクセスするための権限もカスタムポリシーで設定しました。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": "arn:aws:s3:::<保存するするバケット名>/*"
},
{
"Effect": "Allow",
"Action": [
"transcribe:StartTranscriptionJob"
],
"Resource": "*"
}
]
}
LambdaでKinesisのデータを処理し、S3へ保存
Kinesisに送信された音声データは、Lambdaを介してS3へ保存されます。
S3_BUCKET_NAMEとTRANSCRIBE_BUCKET_NAMEは、Lambdaの環境変数として設定し、あらかじめ作成しておいたバケット名を設定します。
import boto3
import logging
import os
import json
import base64
import time
# 設定
AWS_REGION = 'us-east-1'
S3_BUCKET_NAME = os.environ['S3_BUCKET_NAME']
TRANSCRIBE_BUCKET_NAME = os.environ['TRANSCRIBE_BUCKET_NAME']
# ログ設定
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger()
# クライアントの作成
s3_client = boto3.client('s3', region_name=AWS_REGION)
transcribe_client = boto3.client('transcribe', region_name=AWS_REGION)
def lambda_handler(event, context):
try:
for record in event['Records']:
# Kinesis から音声データ(Base64エンコードされたバイナリデータ)を取り出す
payload = base64.b64decode(record['kinesis']['data'])
# S3キーを作成(音声ファイルの一意な識別子として使用)
s3_key = f"audio/{context.aws_request_id}-{int(time.time())}.wav"
# S3に音声データをアップロード
s3_client.put_object(Bucket=S3_BUCKET_NAME, Key=s3_key, Body=payload)
# S3 URI 作成
audio_file_uri = f"s3://{S3_BUCKET_NAME}/{s3_key}"
# Transcribeジョブ名作成
job_name = s3_key.replace('/', '_')
logger.info(f"Starting transcription job for {job_name}")
try:
response = transcribe_client.start_transcription_job(
TranscriptionJobName=job_name,
LanguageCode='ja-JP',
MediaFormat='wav',
Media={'MediaFileUri': audio_file_uri},
OutputBucketName=TRANSCRIBE_BUCKET_NAME
)
logger.info(f"Transcription job {job_name} started successfully.")
except Exception as e:
logger.error(f"Error starting transcription job {job_name}: {str(e)}")
continue
return {
'statusCode': 200,
'body': json.dumps("Transcription job started successfully.")
}
except Exception as e:
logger.error(f"Error occurred: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps(f"Error occurred: {str(e)}")
}
処理の流れ
1. KinesisからBase64エンコードされた音声データを取得
2. デコードしてWAVデータとしてS3にアップロード
3. S3の音声データを元にAWS Transcribeのジョブを開始
4. 文字起こしの結果は指定したS3バケットに保存
Transcribeの処理結果を取得
音声データをAmazon Transcribeに送信した後、処理が完了すると文字起こしの結果がS3に保存されます。
Transcribeの処理状況を確認
Transcribeのジョブは非同期で実行されるため、ジョブの状態を確認する必要があります。
コンソールからAmazon Transcribeに移動し、トランスクリプションジョブのステータスが完了となっていることを確認します。
Transcribeの結果を確認
トランスクリプションジョブが完了すると、文字起こしの結果はJSON形式でS3に保存されます。
文字起こし結果の例
{"jobName":"audio_xxxx-xxxx-xxxx-xxxx-xxxx-xxxxx.wav","accountId":"12345678","status":"COMPLETED","results":{"transcripts":[{"transcript":"<文字起こし内容>"}],
・・・・
まとめ
今回、FFmpeg × Kinesis × Transcribe を組み合わせて、リアルタイム音声ストリーミングと文字起こしの仕組みを構築しました。
ポイントの振り返り
- FFmpegを活用して音声をキャプチャ
- マイクやシステム音声をリアルタイムに取得し、WAVフォーマットで出力
- Kinesis Data Streamsでストリーミング
- 1MBのペイロード制限を考慮しながら適切にデータを分割して送信
- Lambdaでデータを受け取りS3へ保存
- Kinesisのデータを処理し、一時的にS3へアップロード
- Transcribeを活用して文字起こし
- S3に保存した音声データをTranscribeに渡し、自動でテキスト化
AWSの普段使わないサービスを実際に動かしながら試行錯誤しました。特に Kinesisのデータ制約にどう対応するか という部分は実装上の工夫が求められるポイントでした。
リアルタイム音声解析や文字起こしをAWS上で実装したい方の参考になれば幸いです!