Webスクレイピングの学習が進みました。今回はランキングサイトの情報をfor...in文などを駆使して階層的にスクレイピングする方法を学びました。
ランキングサイトからスクレイピング
#Chrome
from selenium import webdriver
browser = webdriver.Chrome()
#URLにアクセスする
browser.get("https://scraping-for-beginner.herokuapp.com/ranking/")
https://scraping-for-beginner.herokuapp.com/ranking/
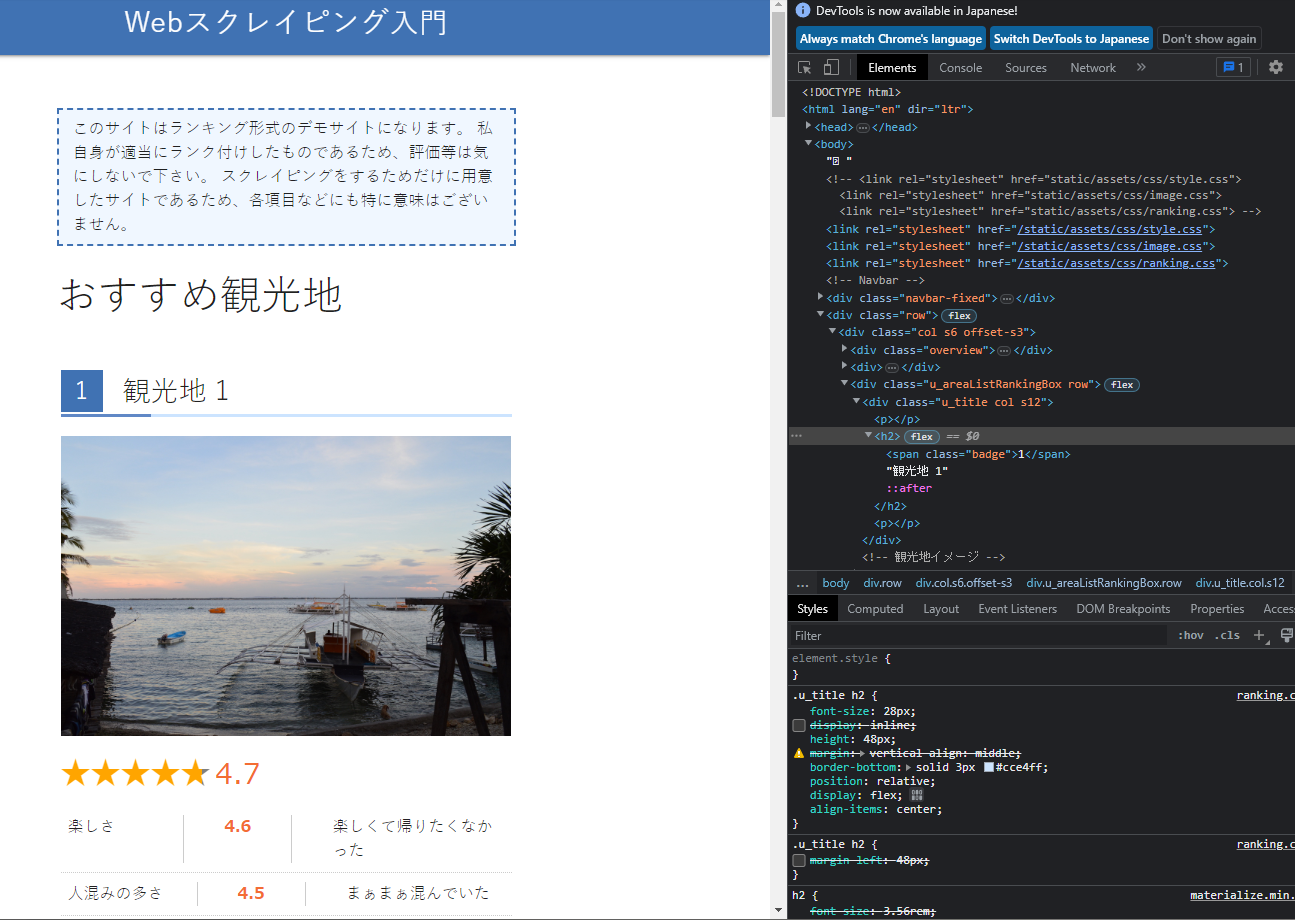
一番最初の観光地情報 → 複数の情報へのステップアップ
今回はfind_elementでまず1つのタグを取得し、次にfind_elementsで複数のランキング情報を一括取得しfor...in文で抽出する、という方法でサイト全体の情報を取得するのを目指します。また、ページが複数に分かれている場合のページを跨いだ処理も行います。
h2タグ(観光地名)を取得
# 1つの情報を取得→複数の情報、といった感じでステップアップする
# h2の要素を取得 -
elem_h2 = browser.find_element_by_tag_name("h2")
elem_h2.text
'1\n観光地 1'
# 複数要素を一括取得(list型)
elem_h2s = browser.find_elements_by_tag_name("h2")
# 取得した要素
for i in range(0, len(elem_h2s)):
print(elem_h2s[i].text)
1
観光地 1
2
観光地 2
3
観光地 3
4
観光地 4
5
観光地 5
6
観光地 6
7
観光地 7
8
観光地 8
9
観光地 9
10
観光地 10
ランキングボックス要素を所得("u_areaListRankingBox")
# ランキングボックス1つ単位の要素全てを所得→その中から必要なタグのみを探す
elem_rankingBox = browser.find_element_by_class_name("u_areaListRankingBox")
elem_rankingBox.text
'1\n観光地 1\n4.7\n楽しさ\n4.6\nとてもエンジョイした\n人混みの多さ\n4.5\nお昼の時間はかなり混んでいた\n景色\n4.9\n大自然を感じることができた\nアクセス\n4.2\n船で1時間ほどであった'
elem_title = elem_rankingBox.find_element_by_class_name("u_title")
elem_title.text
# 空白・不必要な文字などを削除→split関数を使う
title = elem_title.text
title.split("\n")
'1\n観光地 1'
['1', '観光地 1']
総合評価を所得("evaluateNumber")
# 総合評価
elem_evaluate = elem_rankingBox.find_element_by_class_name("evaluateNumber")
print(elem_evaluate.text)
4.7
# その他4つの評価
elem_values = browser.find_element_by_class_name("u_categoryTipsItem")
# u_categoryTipsItemから複数のランキング情報を取得
elem01 = elem_values.find_elements_by_class_name("is_rank")[0]
elem_fun = elem01.find_element_by_class_name("evaluateNumber")
print(elem_fun.text)
elem02 = elem_values.find_elements_by_class_name("is_rank")[1]
elem_clowded = elem02.find_element_by_class_name("evaluateNumber")
print(elem_clowded.text)
elem03 = elem_values.find_elements_by_class_name("is_rank")[2]
elem_scenery = elem02.find_element_by_class_name("evaluateNumber")
print(elem_scenery.text)
elem04 = elem_values.find_elements_by_class_name("is_rank")[3]
elem_access = elem04.find_element_by_class_name("evaluateNumber")
print(elem_access.text)
4.6
4.5
4.5
4.2
全ての最初の観光地情報を取得("u_areaListRankingBox")
# ランキングボックス1つ単位の要素全てを所得→その中から必要なタグのみを探す
elems_rankingBox = browser.find_elements_by_class_name("u_areaListRankingBox")
elems_rankingBox
[<selenium.webdriver.remote.webelement.WebElement (session="da97c8c7657eeac972fd4db4acaa37ba", element="7f3d7bcd-9196-4dc3-a0fb-f929df135613")>,
<selenium.webdriver.remote.webelement.WebElement (session="da97c8c7657eeac972fd4db4acaa37ba", element="c94a101a-50a5-4e33-a39a-228da91befd0")>,
<selenium.webdriver.remote.webelement.WebElement (session="da97c8c7657eeac972fd4db4acaa37ba", element="78f35a80-a211-494f-91e5-92dd90d801fa")>,
<selenium.webdriver.remote.webelement.WebElement (session="da97c8c7657eeac972fd4db4acaa37ba", element="c346c0d1-4cd8-4bad-ac0b-b9fe8114a63e")>,
<selenium.webdriver.remote.webelement.WebElement (session="da97c8c7657eeac972fd4db4acaa37ba", element="0c2a2299-8b95-4d9e-b490-09ca99beea7f")>,
<selenium.webdriver.remote.webelement.WebElement (session="da97c8c7657eeac972fd4db4acaa37ba", element="0e54a3a5-4a39-444a-a036-59e14b90ac5a")>,
<selenium.webdriver.remote.webelement.WebElement (session="da97c8c7657eeac972fd4db4acaa37ba", element="48e1a07a-0d50-4447-9515-d37764fe57d3")>,
<selenium.webdriver.remote.webelement.WebElement (session="da97c8c7657eeac972fd4db4acaa37ba", element="b73afe43-5ad8-4898-9f61-5701445509ca")>,
<selenium.webdriver.remote.webelement.WebElement (session="da97c8c7657eeac972fd4db4acaa37ba", element="aec32314-3b37-4e83-8028-db0160eddeac")>,
<selenium.webdriver.remote.webelement.WebElement (session="da97c8c7657eeac972fd4db4acaa37ba", element="3e7c2fa5-b3d0-4e15-a687-71204a47c88a")>]
# 取得した要素をfor文で表示
for i in range(0, len(elems_rankingBox)):
print(elems_rankingBox[i].text)
1
観光地 1
4.7
楽しさ
4.6
とてもエンジョイした
人混みの多さ
4.5
お昼の時間はかなり混んでいた
景色
4.9
大自然を感じることができた
アクセス
4.2
船で1時間ほどであった
2
観光地 2
4.7
楽しさ
4.6
楽しくて帰りたくなかった
人混みの多さ
4.5
時間帯によって混雑具合は違った
景色
4.9
時を忘れるような壮大さであった
アクセス
4.2
渋滞に巻き込まれて3時間以上かかった
3
観光地 3
4.6
楽しさ
4.5
満喫できた
人混みの多さ
4.4
非常に空いていた
景色
4.8
景色に魅了された
アクセス
4.1
船で1時間ほどであった
4
観光地 4
4.5
楽しさ
4.4
一人旅には最適でした
人混みの多さ
4.4
空いていた
景色
4.8
自然の素晴らしさを味わった
アクセス
4.0
市内から車で2時間ほどであった
5
観光地 5
4.5
楽しさ
4.4
満喫できた
人混みの多さ
4.3
非常に混んでいた
景色
4.7
自然の素晴らしさを味わった
アクセス
4.0
交通の便が悪かった
6
観光地 6
4.4
楽しさ
4.3
とてもエンジョイした
人混みの多さ
4.3
まぁまぁ混んでいた
景色
4.7
海が非常に綺麗であった
アクセス
3.9
交通の便が悪かった
7
観光地 7
4.3
楽しさ
4.2
また行きたいと思える場所でした!!
人混みの多さ
4.2
時間帯によって混雑具合は違った
景色
4.6
時を忘れるような壮大さであった
アクセス
3.8
船で2時間ほどであった
8
観光地 8
4.3
楽しさ
4.2
THE非日常
人混みの多さ
4.2
空いていた
景色
4.6
目を疑う超絶景であった
アクセス
3.8
飛行機で1時間ほどで着きました
9
観光地 9
4.2
楽しさ
4.1
楽しくて帰りたくなかった
人混みの多さ
4.1
非常に混んでいた
景色
4.5
目を疑う超絶景であった
アクセス
3.7
渋滞に巻き込まれて3時間以上かかった
10
観光地 10
4.1
楽しさ
4.0
1日中飽きることなく遊び続けられた
人混みの多さ
4.1
お昼の時間はかなり混んでいた
景色
4.4
信じられないような絶景であった
アクセス
3.6
アクセスはあまり良くなかった
WEB情報のリスト・データフレーム化
WEB情報をデータにするには、for...in文を使ってスクレイピングした情報を抽出する他、データをリスト・Pandasのデータフレームにする等の前処理を行う必要があります。
観光地名
# 取得した要素をfor文で表示 - 観光地のタイトルを抽出する
# テキストの分割といった前処理も行う
titles = []
for i in range(0, len(elems_rankingBox)):
elem_title = elems_rankingBox[i].find_element_by_class_name("u_title").text
elem_title = elem_title.split("\n")
titles.append(elem_title[1])
print(elem_title[1])
print(titles)
観光地 1
観光地 2
観光地 3
観光地 4
観光地 5
観光地 6
観光地 7
観光地 8
観光地 9
観光地 10
['観光地 1', '観光地 2', '観光地 3', '観光地 4', '観光地 5', '観光地 6', '観光地 7', '観光地 8', '観光地 9', '観光地 10']
総合評価
# Chrome
from selenium import webdriver
browser = webdriver.Chrome()
# URLにアクセスする
browser.get("https://scraping-for-beginner.herokuapp.com/ranking/")
ranks = []
elems_rank = browser.find_elements_by_class_name("u_rankBox")
for i in range(0, len(elems_rank)):
elem_rank = elems_rank[i].find_element_by_class_name("evaluateNumber").text
ranks.append(elem_rank)
print(elem_rank)
print(ranks)
4.7
4.7
4.6
4.5
4.5
4.4
4.3
4.3
4.2
4.1
['4.7', '4.7', '4.6', '4.5', '4.5', '4.4', '4.3', '4.3', '4.2', '4.1']
各評価
# 入れ子for文で観光地の各評価を全て取得する(2次元配列の形にする)
# is_rankクラスの要素を全て取得→evaluateNumberクラスの要素全てを所得、という繰り返しで上下下達式に目的の要素を取得する
elems_tipsItem = browser.find_elements_by_class_name("u_categoryTipsItem")
print(len(elems_tipsItem))
dt_ranks = []
for elem in elems_tipsItem:
elems_isRank = elem.find_elements_by_class_name("is_rank")
span_ranks = []
for elem_value in elems_isRank:
rank = elem_value.find_element_by_class_name("evaluateNumber").text
span_ranks.append(float(rank))
dt_ranks.append(span_ranks)
print(dt_ranks)
10
[[4.6, 4.5, 4.9, 4.2], [4.6, 4.5, 4.9, 4.2], [4.5, 4.4, 4.8, 4.1], [4.4, 4.4, 4.8, 4.0], [4.4, 4.3, 4.7, 4.0], [4.3, 4.3, 4.7, 3.9], [4.2, 4.2, 4.6, 3.8], [4.2, 4.2, 4.6, 3.8], [4.1, 4.1, 4.5, 3.7], [4.0, 4.1, 4.4, 3.6]]
観光地名
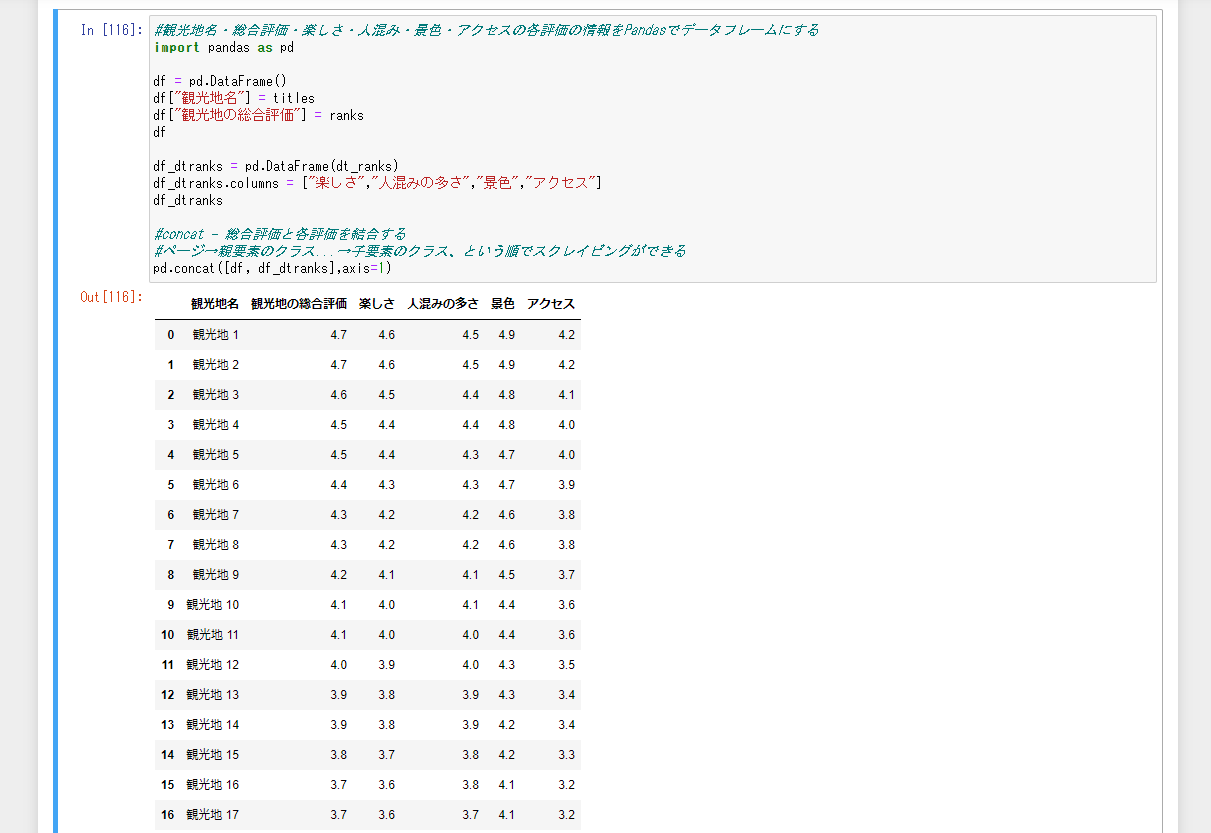
観光地名・総合評価・楽しさ・人混み・景色・アクセスの各評価の情報をPandasでデータフレームにします。作成したデータフレームはcsv形式などにして分析・評価などに使えるデータ形式にできます。
# 観光地名・総合評価・楽しさ・人混み・景色・アクセスの各評価の情報をPandasでデータフレームにする
import pandas as pd
df = pd.DataFrame()
df["観光地名"] = titles
df["観光地の総合評価"] = ranks
df
観光地名 観光地の総合評価
0 観光地 1 4.7
1 観光地 2 4.7
2 観光地 3 4.6
3 観光地 4 4.5
4 観光地 5 4.5
5 観光地 6 4.4
6 観光地 7 4.3
7 観光地 8 4.3
8 観光地 9 4.2
9 観光地 10 4.1
df_dtranks = pd.DataFrame(dt_ranks)
df_dtranks.columns = ["楽しさ","人混みの多さ","景色","アクセス"]
df_dtranks
楽しさ 人混みの多さ 景色 アクセス
0 4.6 4.5 4.9 4.2
1 4.6 4.5 4.9 4.2
2 4.5 4.4 4.8 4.1
3 4.4 4.4 4.8 4.0
4 4.4 4.3 4.7 4.0
5 4.3 4.3 4.7 3.9
6 4.2 4.2 4.6 3.8
7 4.2 4.2 4.6 3.8
8 4.1 4.1 4.5 3.7
9 4.0 4.1 4.4 3.6
# concat - 総合評価と各評価を結合する
pd.concat([df, df_dtranks],axis=1)
観光地名 観光地の総合評価 楽しさ 人混みの多さ 景色 アクセス
0 観光地 1 4.7 4.6 4.5 4.9 4.2
1 観光地 2 4.7 4.6 4.5 4.9 4.2
2 観光地 3 4.6 4.5 4.4 4.8 4.1
3 観光地 4 4.5 4.4 4.4 4.8 4.0
4 観光地 5 4.5 4.4 4.3 4.7 4.0
5 観光地 6 4.4 4.3 4.3 4.7 3.9
6 観光地 7 4.3 4.2 4.2 4.6 3.8
7 観光地 8 4.3 4.2 4.2 4.6 3.8
8 観光地 9 4.2 4.1 4.1 4.5 3.7
9 観光地 10 4.1 4.0 4.1 4.4 3.6
# csvに出力(インデックス無し)
df.to_csv("観光情報.csv", index = False)
全ページの情報を取得する
観光地のページが全3ページあるので、それらのページ全てからスクレイピングする方法を考えます。for文とformat関数を組み合わせて全ページにアクセスします。
https://scraping-for-beginner.herokuapp.com/ranking/?page=1
https://scraping-for-beginner.herokuapp.com/ranking/?page=2
https://scraping-for-beginner.herokuapp.com/ranking/?page=
str型をリストの様に数値を変えるにはformat関数を使います。
i=3
"https://scraping-for-beginner.herokuapp.com/ranking/?page={}".format(i)
'https://scraping-for-beginner.herokuapp.com/ranking/?page=3'
# 観光地の総合評価を全て取得する
# Chrome
from selenium import webdriver
browser = webdriver.Chrome()
# 観光地名、総合評価、各評価
titles=[]
ranks=[]
dt_ranks=[]
# URLにアクセスする
# for文を3回入れ子にする
for page in range(1,4):
url = "https://scraping-for-beginner.herokuapp.com/ranking/?page={}".format(page)
browser.get(url)
# 観光地名
elems_rankingBox = browser.find_elements_by_class_name("u_areaListRankingBox")
# elems_rankingBox
for i in range(0, len(elems_rankingBox)):
elem_title = elems_rankingBox[i].find_element_by_class_name("u_title").text
elem_title = elem_title.split("\n")
titles.append(elem_title[1])
# print(elem_title[1])
# print(titles)
# 総合評価
elems_rank = browser.find_elements_by_class_name("u_rankBox")
# print(len(elems_rank))
for i in range(0, len(elems_rank)):
elem_rank = elems_rank[i].find_element_by_class_name("evaluateNumber").text
ranks.append(elem_rank)
# print(elem_rank)
# print(ranks)
# 各評価
elems_tipsItem = browser.find_elements_by_class_name("u_categoryTipsItem")
# print(len(elems_tipsItem))
for elem in elems_tipsItem:
elems_isRank = elem.find_elements_by_class_name("is_rank")
span_ranks = []
for elem_value in elems_isRank:
rank = elem_value.find_element_by_class_name("evaluateNumber").text
span_ranks.append(float(rank))
dt_ranks.append(span_ranks)
# 観光地名
print(titles)
# 総合評価
print(ranks)
# 各評価
print(dt_ranks)
['観光地 1', '観光地 2', '観光地 3', '観光地 4', '観光地 5', '観光地 6', '観光地 7', '観光地 8', '観光地 9', '観光地 10', '観光地 11', '観光地 12', '観光地 13', '観光地 14', '観光地 15', '観光地 16', '観光地 17', '観光地 18', '観光地 19', '観光地 20', '観光地 21', '観光地 22', '観光地 23', '観光地 24', '観光地 25', '観光地 26', '観光地 27', '観光地 28', '観光地 29', '観光地 30']
['4.7', '4.7', '4.6', '4.5', '4.5', '4.4', '4.3', '4.3', '4.2', '4.1', '4.1', '4.0', '3.9', '3.9', '3.8', '3.7', '3.7', '3.6', '3.5', '3.5', '3.4', '3.3', '3.3', '3.2', '3.1', '3.1', '3.0', '2.9', '2.9', '2.8']
[[4.6, 4.5, 4.9, 4.2], [4.6, 4.5, 4.9, 4.2], [4.5, 4.4, 4.8, 4.1], [4.4, 4.4, 4.8, 4.0], [4.4, 4.3, 4.7, 4.0], [4.3, 4.3, 4.7, 3.9], [4.2, 4.2, 4.6, 3.8], [4.2, 4.2, 4.6, 3.8], [4.1, 4.1, 4.5, 3.7], [4.0, 4.1, 4.4, 3.6], [4.0, 4.0, 4.4, 3.6], [3.9, 4.0, 4.3, 3.5], [3.8, 3.9, 4.3, 3.4], [3.8, 3.9, 4.2, 3.4], [3.7, 3.8, 4.2, 3.3], [3.6, 3.8, 4.1, 3.2], [3.6, 3.7, 4.1, 3.2], [3.5, 3.7, 4.0, 3.1], [3.4, 3.6, 3.9, 3.0], [3.4, 3.6, 3.9, 3.0], [3.3, 3.5, 3.8, 2.9], [3.2, 3.5, 3.8, 2.8], [3.2, 3.4, 3.7, 2.8], [3.1, 3.4, 3.7, 2.7], [3.0, 3.3, 3.6, 2.6], [3.0, 3.3, 3.6, 2.6], [2.9, 3.2, 3.5, 2.5], [2.8, 3.2, 3.4, 2.4], [2.8, 3.1, 3.4, 2.4], [2.7, 3.1, 3.3, 2.3]]
# 観光地名・総合評価・楽しさ・人混み・景色・アクセスの各評価の情報をPandasでデータフレームにする
import pandas as pd
df = pd.DataFrame()
df["観光地名"] = titles
df["観光地の総合評価"] = ranks
df
df_dtranks = pd.DataFrame(dt_ranks)
df_dtranks.columns = ["楽しさ","人混みの多さ","景色","アクセス"]
df_dtranks
# concat - 総合評価と各評価を結合する
# ページ→親要素のクラス...→子要素のクラス、という順でスクレイピングができる
pd.concat([df, df_dtranks],axis=1)
これでランキングサイトからのスクレイピングができるようになりました。
次は画像のスクレイピングを目指します。