Webスクレイピングの学習が進みました。今回は画像ファイルをWEBサイトからスクレイピングする方法を学びました。
画像のスクレイピング
まずは画像を処理するためのライブラリ:Pillowをインストールします。
pip install Pillow
Pillowを使うと、Image形式でローカルフォルダーやカーネルに読み込んだ画像を扱えるようになります。
from PIL import Image
img = Image.open("Sample.JPG")
img
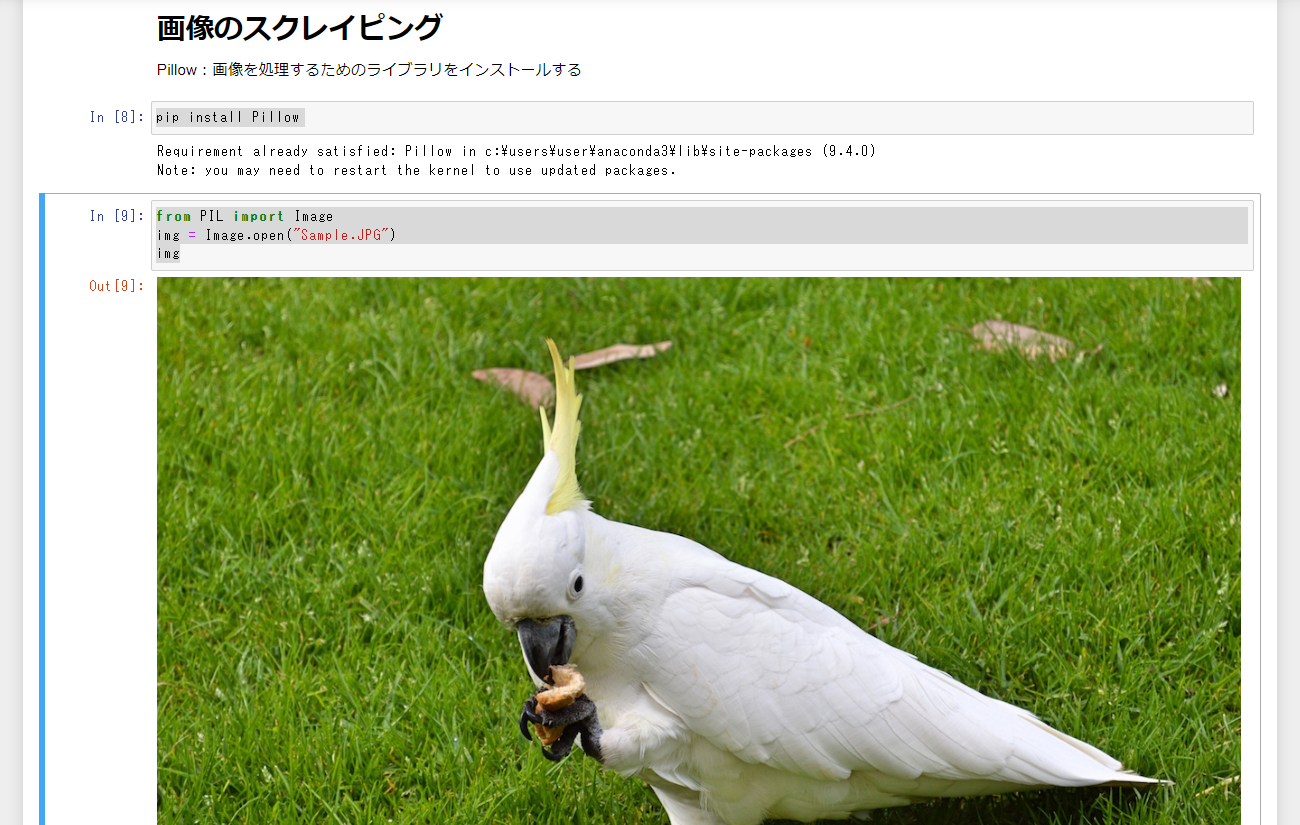
Pillowを使えば簡単な画像の表示の他、サイズの確認・リサイズ・リネームして保存といったことができます。
#画像のサイズを確認
img.size
(1200, 798)
画像をリサイズ・リネームして保存
img = img.resize((1024, 768))
img.save("sample_resize.jpg")
Selenium・Pillowを使って画像をスクレイピング
Selenium・Pillowを使えばWEB上から画像をスクレイピングすることができます。他にも出入力・URL処理用のライブラリが必要です。
#必須 - 出入力・URL処理のライブラリ、Pillow
import io
from urllib import request
from PIL import Image
#Chrome
from selenium import webdriver
browser = webdriver.Chrome()
#URLにアクセスする
browser.get("https://scraping-for-beginner.herokuapp.com/image")
#imageタグとその親要素を取得する
elem_parent = browser.find_element_by_class_name("material-placeholder")
elem_img = elem_parent.find_element_by_tag_name("img")
#srcのリンク先を取得する
url = elem_img.get_attribute("src")
print(url)
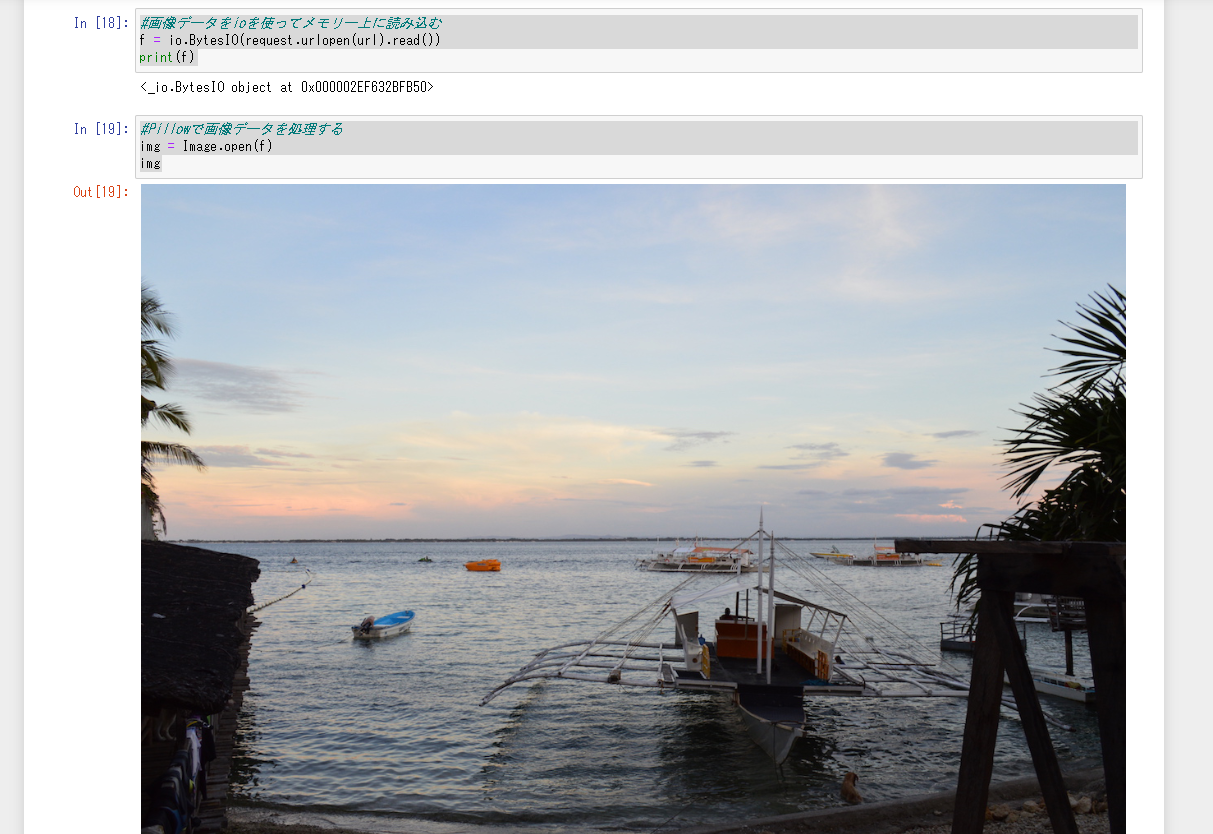
#画像データをioを使ってメモリー上に読み込む
f = io.BytesIO(request.urlopen(url).read())
print(f)
#Pillowで画像データを処理する
img = Image.open(f)
img
#画像を保存
img.save("img01.jpg")
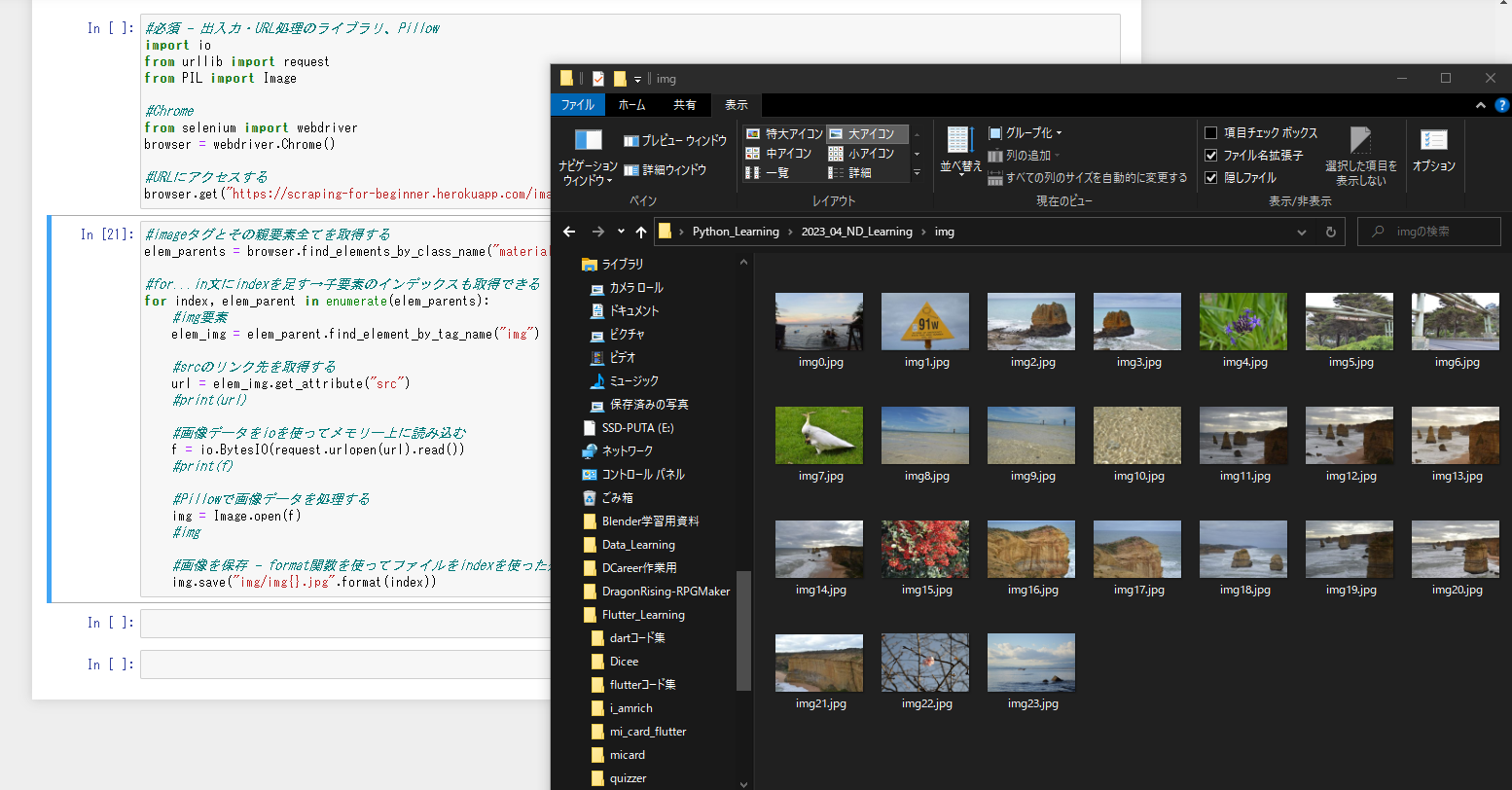
すべての画像を収集
#必須 - 出入力・URL処理のライブラリ、Pillow
import io
from urllib import request
from PIL import Image
#Chrome
from selenium import webdriver
browser = webdriver.Chrome()
#URLにアクセスする
browser.get("https://scraping-for-beginner.herokuapp.com/image")
#imageタグとその親要素全てを取得する
elem_parents = browser.find_elements_by_class_name("material-placeholder")
#for...in文にindexを足す→子要素のインデックスも取得できる
for index, elem_parent in enumerate(elem_parents):
#img要素
elem_img = elem_parent.find_element_by_tag_name("img")
#srcのリンク先を取得する
url = elem_img.get_attribute("src")
#print(url)
#画像データをioを使ってメモリー上に読み込む
f = io.BytesIO(request.urlopen(url).read())
#print(f)
#Pillowで画像データを処理する
img = Image.open(f)
#img
#画像を保存 - format関数を使ってファイルをindexを使った連番にする
img.save("img/img{}.jpg".format(index))
これでWebスクレイピング-入門編の学習が完了しました。次はスクレイピングを開発向けに応用するのを目指します。