これまでに挑戦したKaggleコンペと予測に使ったモデル・精度向上に役立った手法や参考書書籍を挙げてみることにしました。随時更新します。
Titanic - Machine Learning from Disaster
教師あり分類。乗客の情報を元に生き残ったかどうかを予測するデータセットです。
Kaggleスタートブック
予測には「Kaggleスタートブック」で行われている 特徴量エンジニアリングとSVM を使いました。今のところ平均的な予測値をちょこっと上回るというレベル。学習して身についたのはこんなところです。
- 説明変数の分析と特徴エンジニアリングに
pandas_profilingを使う- 目的変数への寄与率の可視化に
plot_feature_importancesを使う- 質的変数はラベルエンコーディング・ワンホットエンコーディングする。性別はラベルエンコーディング、順序なしの質的変数はワンホットエンコーディングする
House Prices - Advanced Regression Techniques
教師あり回帰。アイオワ州エイムズ市の住宅価格を回帰予測する学習用コンペです。目的変数は連続値になります。 説明変数が79列、学習データが1460行、テストデータが1459行 というスケールのデータです。評価は平均2乗誤差(Root mean Squared Error)で算出されます。
Kaggleデータ分析入門
質的変数をラベルエンコーディング、 LightGBMと交差検証 を使うことで上位25%にランクイン。次回はEDA・特徴量エンジニアリングを駆使して精度向上を目指します。

Kaggleで学んでハイスコアをたたき出す
歪度が0.75以上の量的な説明変数は値をネイピア数を底とする対数とする 、XGBoostとラッソ回帰をアンサンブル学習する という手法で上位10%にランクイン。Kaggleを始めて以来初の快挙です!住宅価格の予想をする問題ではこの手法をセオリーにして見ようと思います。


歪度の高い値を対数化するとRMSEを求めるのに適した前処理となる
Home Credit Default Risk
教師あり分類。銀行口座の利用者が債務不履行者か否かを予測するコンペです。データが複数に分かれていてキー結合を要する場合の前処理、 説明変数が100次元以上ある場合の教師あり分類 の手法を学習できます。
"Introduction to Manual Feature Engineering"
"Home Credit Default Risk"の特徴量エンジニアリングの指南コードです。現在学習中。
House Prices - Advanced Regression Techniques
Digit RecognizerはMINISTデータを教師あり分類する学習用コンペです。0~9の手書き文字の数字を28x28ピクセルのグレースケール画像にし分類するタスクで、60,000枚の訓練用画像と10,000枚の評価用画像が含まれます。
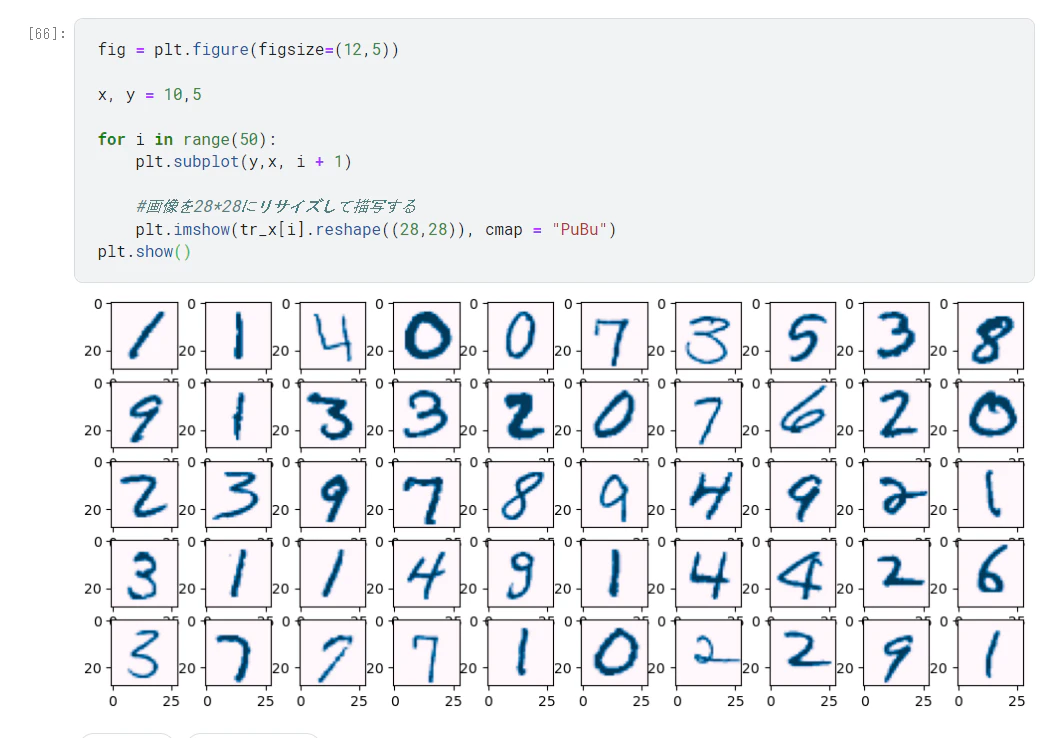
Digit Recognizerの分類に使ったモデルは初歩的なニューラルネットワークです。 入力が784、隠れ層が128、出力が数値の可能性を表す10個の値、パラメータ数は約10万 と尻すぼみな形状のニューラルネットですね。これで汎用精度は 0.97389 を出せました。
今のところスコアは 1113 / 1627位 と下位のほうに(笑)入っています。PCAを使った前処理やハイパーパラメータの調整などを使って精度を向上させる方法を学ぶほか、「Kaggleで学んでハイスコアをたたき出す」のCNNを使う方法を試す予定です。(2023/07/17)
→HyperOptを使ったハイパーパラメータのチューニングで精度は 0.98114、順位は 939 / 1627位 にランクイン。次回は前処理やCNNを使った手法に挑戦します。(2023/07/17)