はじめに
良質なデータをいかに大量に集めるかは、機械学習においてもっとも重要と言っても過言ではない。
質の高いデータを大量に得る方法の一つは、主成分分析を使った自作データセットの量産である。
本記事では、およそ1万体の3次元データセットに対し主成分分析を行い、その結果を用いて新たに10万体の3次元自作データセットを作ることを試みた。
先に結果を...!!(出来上がった10万体の3次元データの一部↓↓)

参考にした論文は以下の4つ。
-
SCAPE: Shape Completion and Animation of People
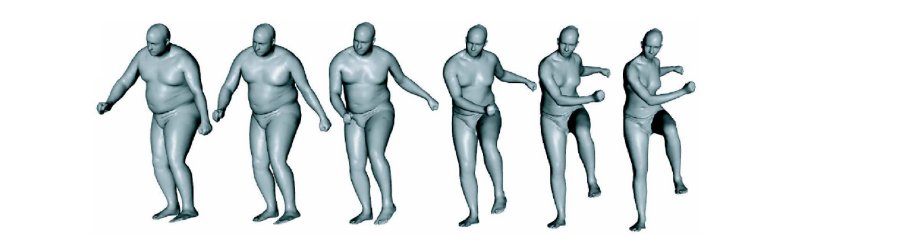
データ駆動法によって、様々な体型とポージングをしたアバターを作る手法を提案。ポーズ変形モデルを学習させるときも、体型変形モデルを学習させるときも、アバターを構成する三角形一つ一つの変形を追う。 -
Building Statistical Shape Spaces for 3D Human Modeling
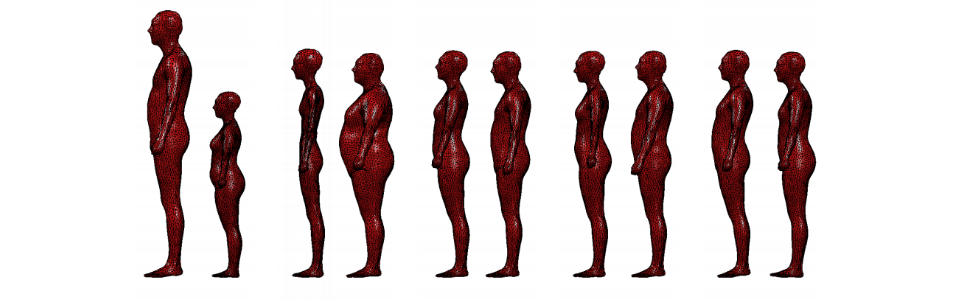
主成分分析によって、様々な体型のアバターを作る論文。データセットにはCAESERを使用し、効率的で表現力の高い3次元ボディーシェイプ空間を構築。きれいに主成分を取り出せててすごい。 -
Deformation Transfer for Triangle Meshes
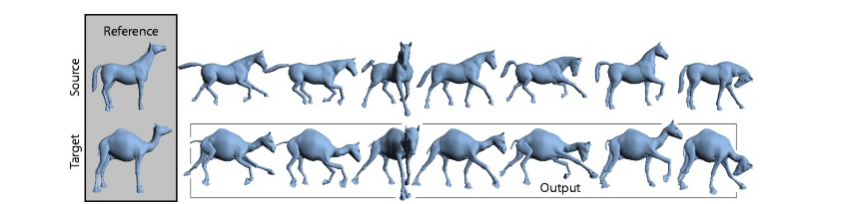
ソースメッシュ(例:馬)をターゲットメッシュ(例:ラクダ)に対応させ、ソースメッシュの動きに合わせて、ターゲットメッシュを動かそうとする論文。 -
MovieReshape: Tracking and Reshaping of Humans in Videos
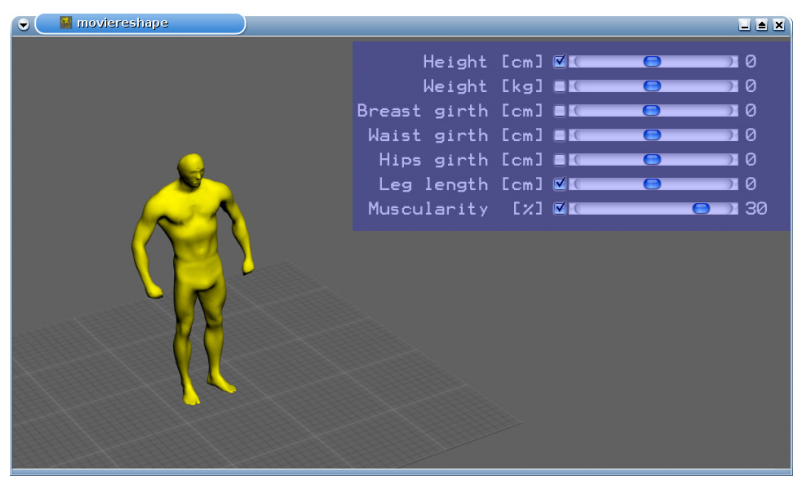
動画内の人を簡単かつ素早く体型変化させる論文。モーフィング可能な人体モデルを作成する際、SCAPEに似た手法を使っている。
前処理(Nonrigid-ICP)
今回扱ったデータセットは3種類のメッシュ構造に分かれているので、主成分分析を行う前に同じメッシュ構造にレジストレーションする必要がある。レジストレーションはOptimal Step Nonrigid ICP Algorithms for Surface Registrationで提案された手法を参考に行った。
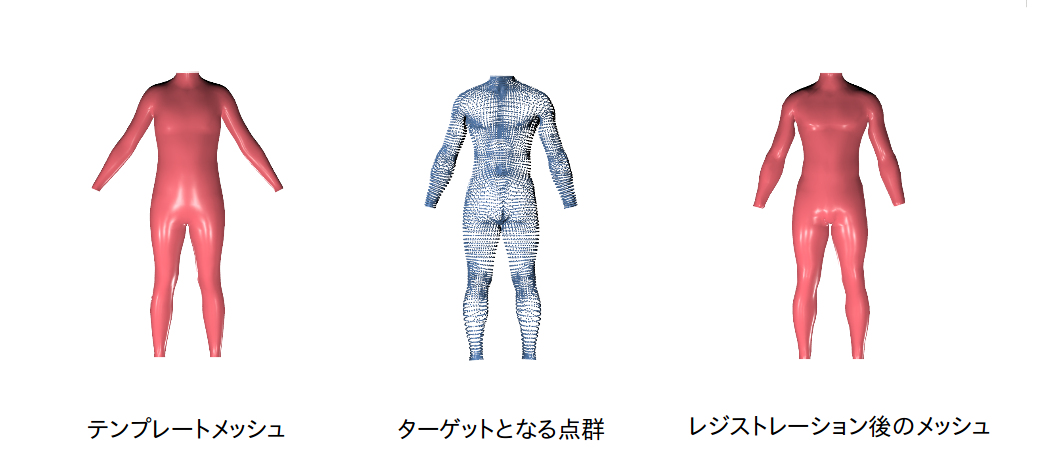
主成分分析(S-SCAPE)
主成分分析に用いる説明変数として、メッシュを構成する三角形ポリゴンに関するアフィン変換行列を使う手法がある(SCAPE)。この手法は、平行移動成分を除いたアフィン変換を考えているので、形状を局所的に抽出することが可能。しかし、分析結果を使ってメッシュを再構成する際、独立に動く三角形を統合する作業に大きな計算負荷がかかってしまう。これを解消する手法として、S-SCAPEという手法がある。頂点毎の移動量を説明変数とするので、メッシュ再構築時の統合作業が不要となる点が魅力的。本記事では、このS-SCAPEを使って主成分分析を行った。
説明変数(各頂点の3次元座標)
分析に用いる説明変数は、メッシュを構成する頂点一つ一つに関する$xyz$座標のセットである。テンプレートとなるアバターと、ターゲットとなるアバターを比較し、 各頂点がどれだけ移動したか を記録していく。つまり、$N$個の頂点からなるアバターの場合、$3N$次元のデータ空間を解析することになる。主成分分析によって、 このデータ空間を最もよく表す上位20個のベクトル を求める。
分析結果
S-SCAPEの論文では、データセットとして CAESER を使っていた。今回は、弊社が購入したデータセットを使って、分析を行った。
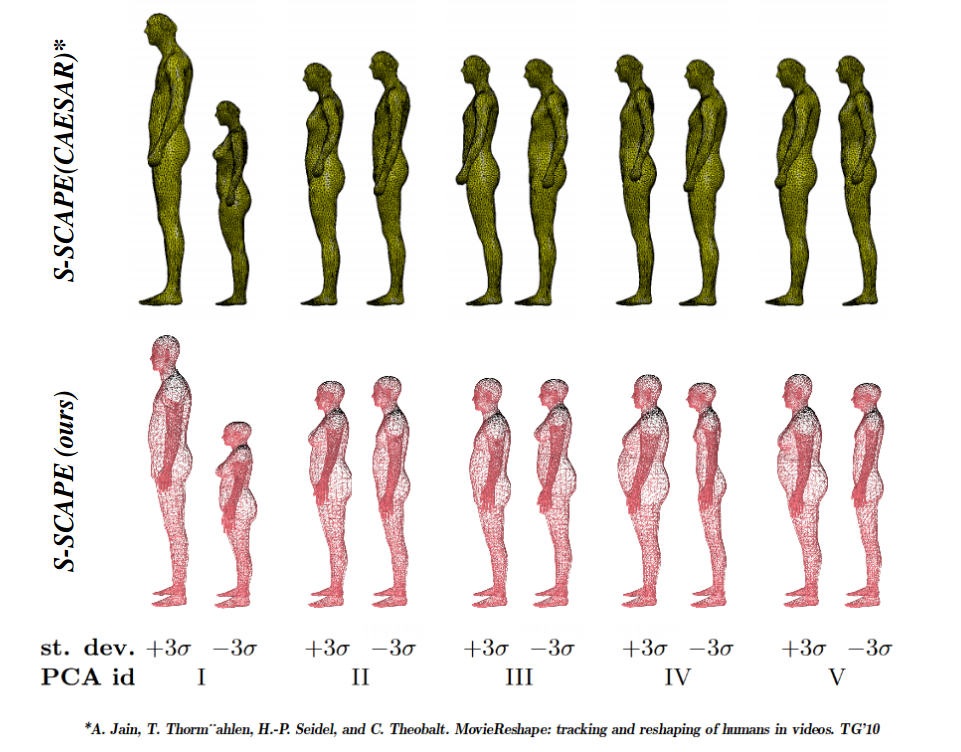
第1主成分は、元の論文と同じ傾向(背の高い男性から背の低い女性へと推移)が取得できた。第2主成分以降は、異なる傾向が得られた。
各主成分に関する詳細
寄与率とは、「この主成分軸一つで、データの何割を説明できるか」を表したもの。
(第k主成分までの)累積寄与率とは「第1主成分軸から第k主成分軸で、データの何割を説明できるか」を表したもの。
分析の結果、上位20個の主成分を使えば、データの99%以上を表現できることが分かった。

データセットの量産化
主成分分析によって得られた第1〜第20主成分($ \beta_i , i\in 1...20$)を用いて、自作データセットを10万体作成した。なお、非現実的な形をした3次元モデルができないよう、各パラメータの値は、 $|\beta_i| < 3 Std.Dev $ とした。
出来上がり!
おわりに
ヒトやモノをデータ化&解析してみたい、という方。
3D技術と深層学習を組み合わせて、何か面白いサービスを作ってみたい!、という方。
弊社では一緒に働いてくれる仲間を大募集しています。
ご興味がある方は下記リンクから是非ご応募ください!
https://about.sapeet.com/recruit/