概要
- Azure AI Search のインデックスにインデクサーを使って、レイアウトスキル、チャンキング、ベクトル化、データ登録を行う方法のメモです
- 2024/12/01 時点で east us リージョンの AISearch を使って雛形を作成して、雛形を手本に japan リージョンへインデックス等を作成します
以下記事を参考にしています。
https://qiita.com/tmiyata25/items/13bf8321853e74f46c31
各種リソースの作成
- リソースグループは事前に作成済みです
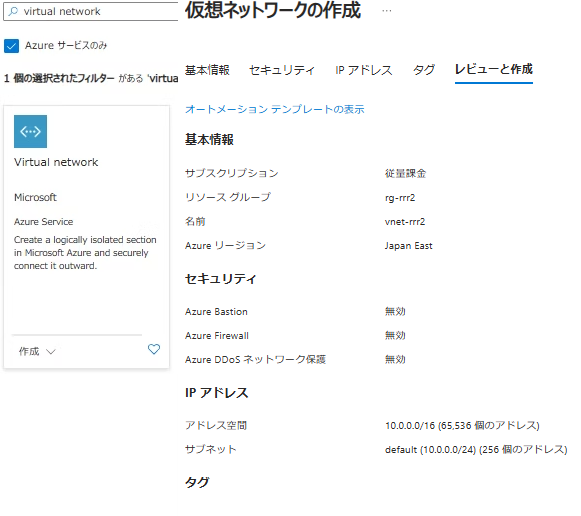
Virtual network の作成
- vnet を作成します
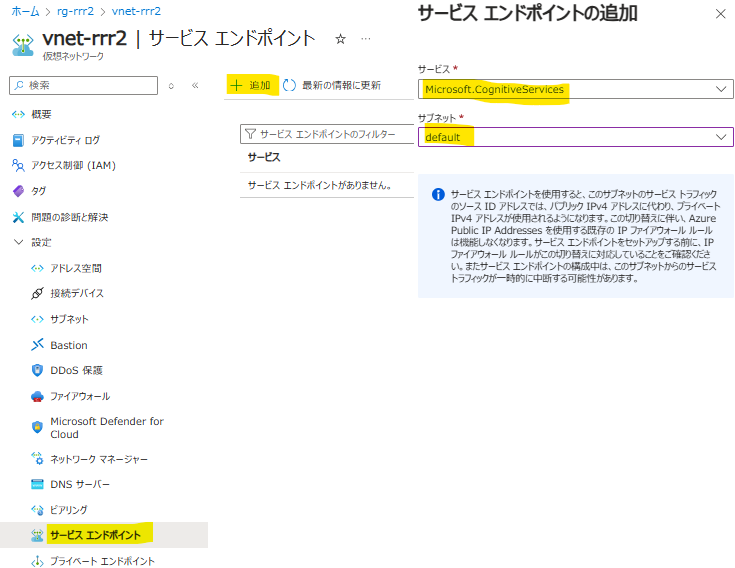
- デプロイ後にサービスエンドポイントを追加しておきます
(作成しておかないと AOAI 作成時エラーになります)
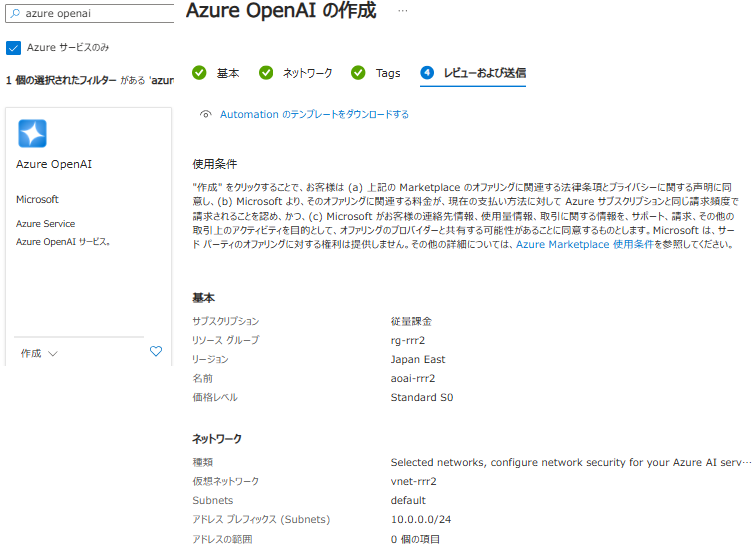
Azure OpenAI の作成
- ネットワークは「Selected networks...」を選択します
- 仮想ネットワークは上で作成したものを選択します
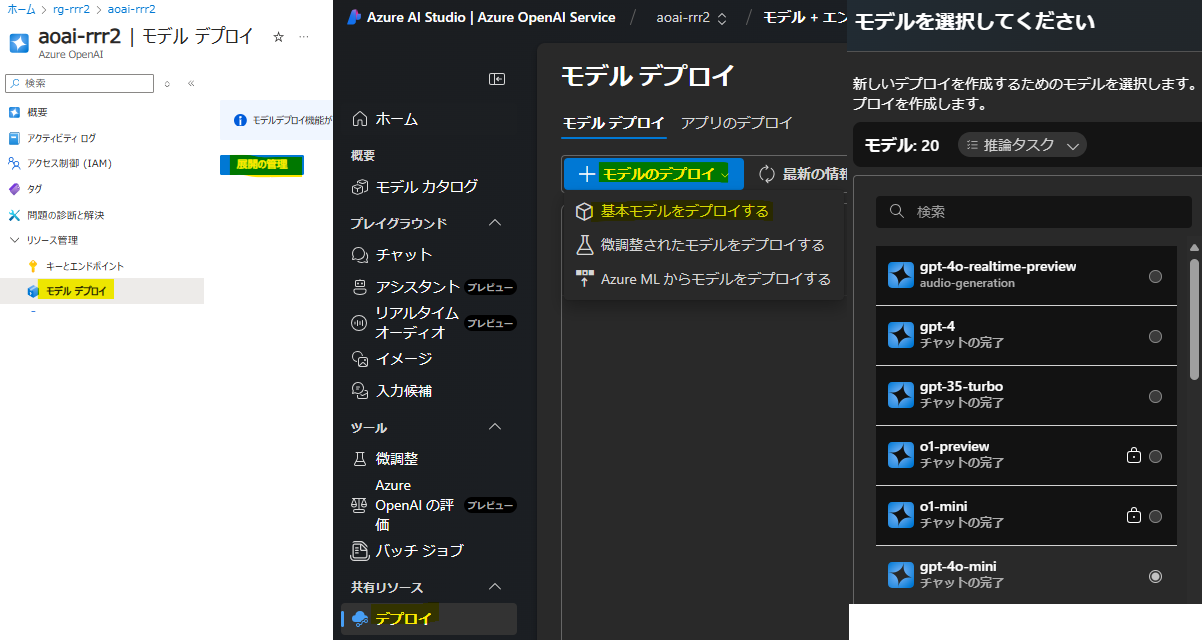
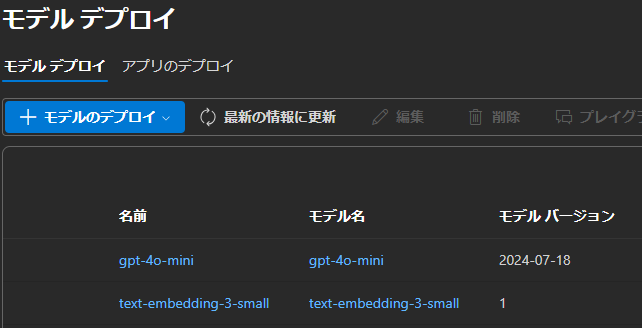
- デプロイ後に適当なモデルを追加しておきます。今回は以下のモデルをデプロイしていますが、この資料(インデクサーの作成)で使うのは text-embedding-3-small のみです
- gtp-4o-mini
- text-embedding-3-small
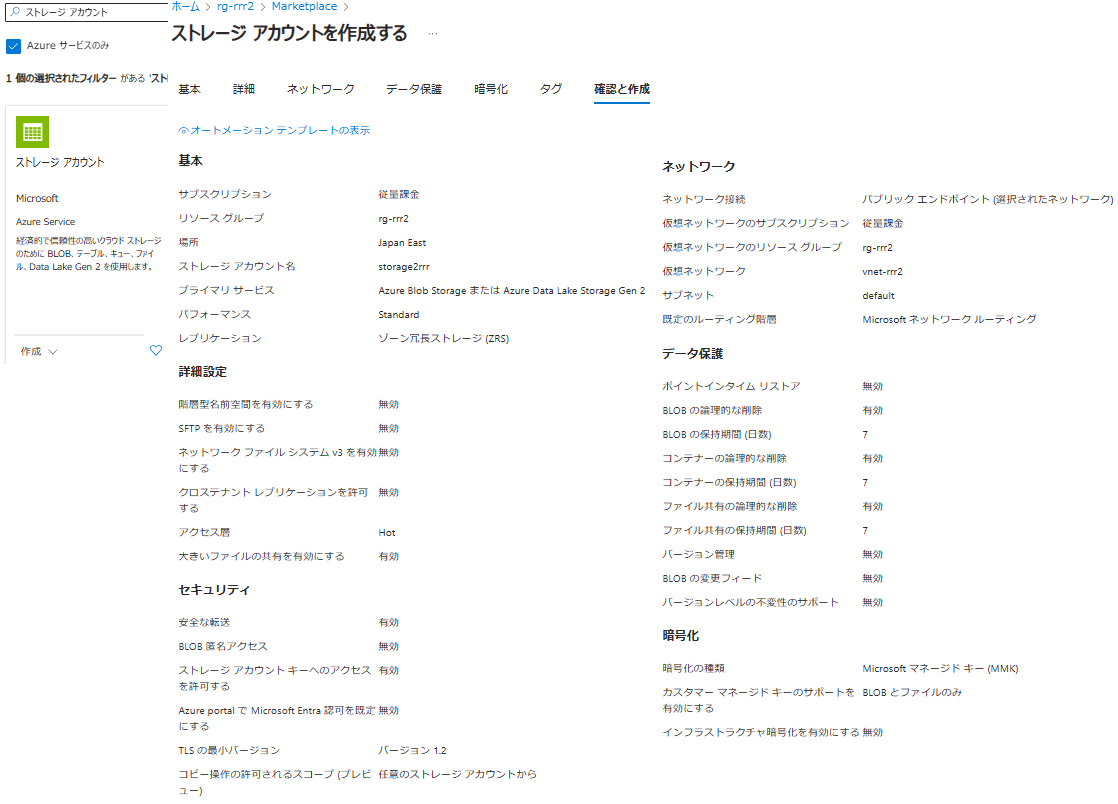
ストレージアカウントの作成
- プライマリサービスは「Azure Blob Storage または ...」を選択します
- ネットワークは「パブリックエンドポイント(選択されたネットワーク)」を選択します
- 仮想ネットワークは上で作成したものを選択します
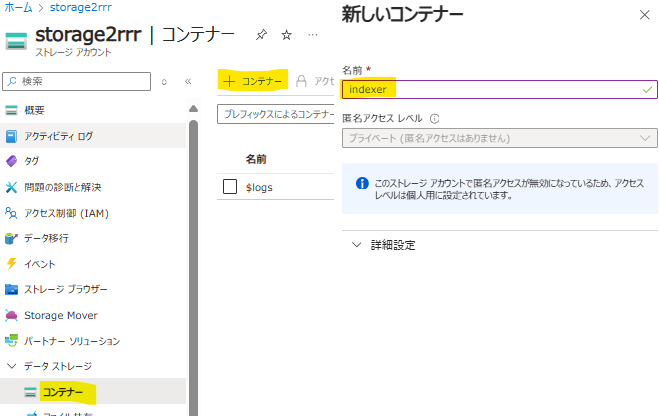
- デプロイ後に適当なコンテナを作成します
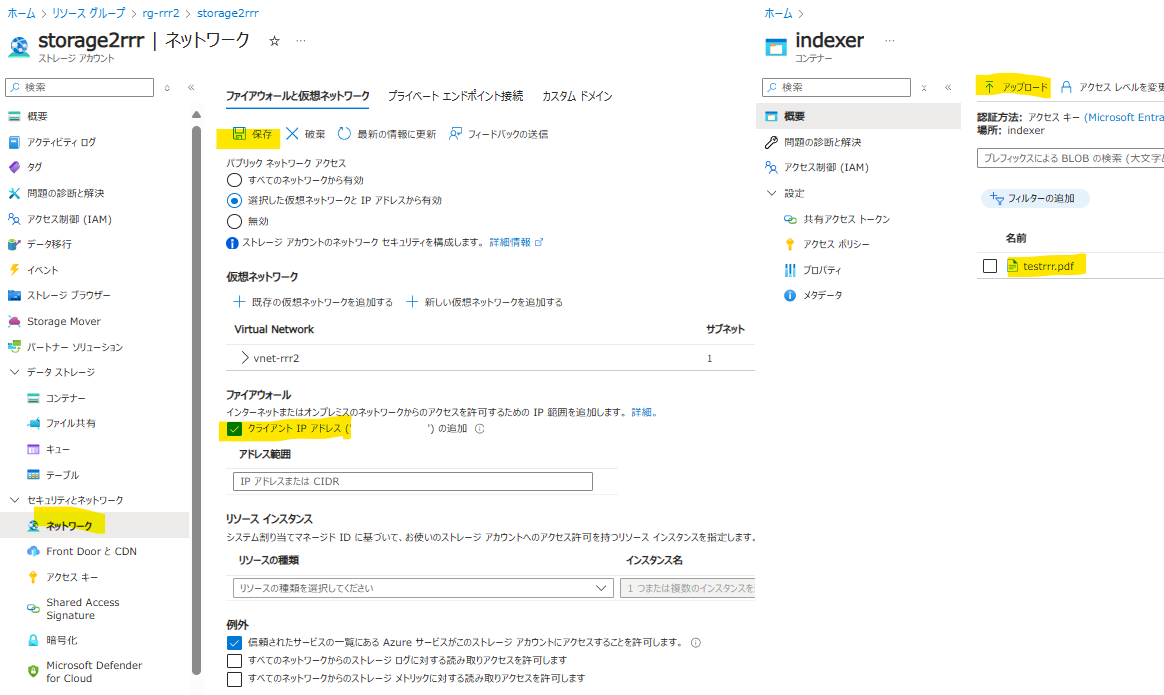
- ネットワーク設定で自身のIPアドレスを追加して、適当なドキュメントを追加します
Azure AI Search の作成
- 場所は「East US」とします
- DocumentIntelligenceLayoutSkill を画面から楽に作成して雛形を手に入れるため
- 価格レベル「basic」以上を選択します
- ネットワークは「プライベート」とします(特にエンドポイントは作成していません)
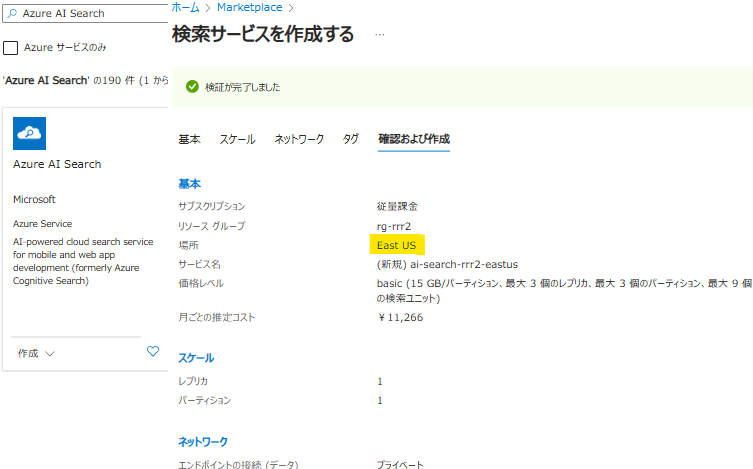
- ネットワーク設定で自身のIPアドレスを追加します
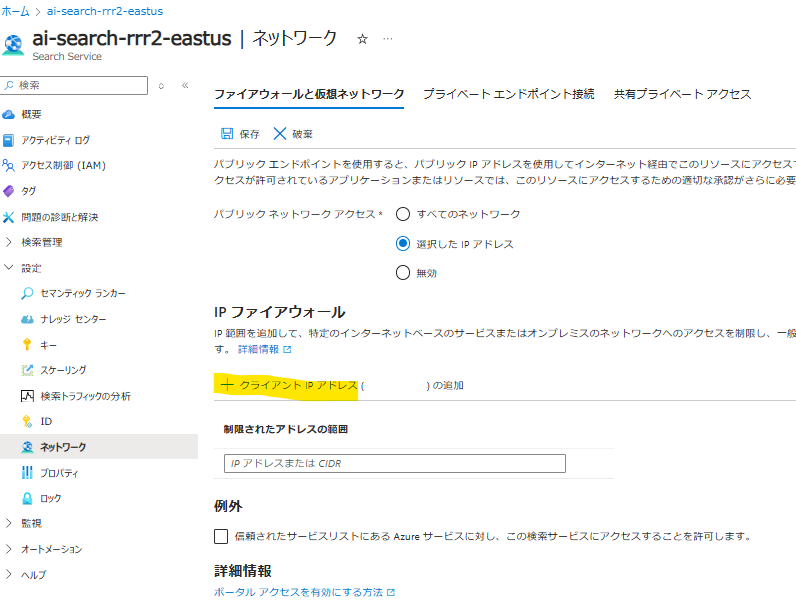
- 「システム割り当てマネージド ID」をオンにします
- 続いて以下のロールを割り当てます
- ストレージ BLOB データ共同作成者
- スコープ:ストレージ
- Cognitive Services OpenAI User
- スコープ:リソースグループ
- ストレージ BLOB データ共同作成者
Azure AI Document Intelligence の作成
- 「Document Intelligence パブリック プレビュー バージョン 2024-07-31-preview」に対応しているリージョンで作成します
https://learn.microsoft.com/ja-jp/azure/search/cognitive-search-skill-document-intelligence-layout - 価格レベルによって制限があります
https://learn.microsoft.com/ja-jp/azure/search/cognitive-search-skill-document-intelligence-layout#data-limits
インデックス、インデクサー、データソース、スキルセットの雛形を作成
雛形の作成
- 「データのインポートとベクター化」を選択

- 「Azure Blob Storage」を選択

- Blobコンテナ、削除の追跡、マネージドIDを~、Enable Document layout detection を選択する
- Enable Document layout ~~ が現在は日本リージョンで選択出来ない
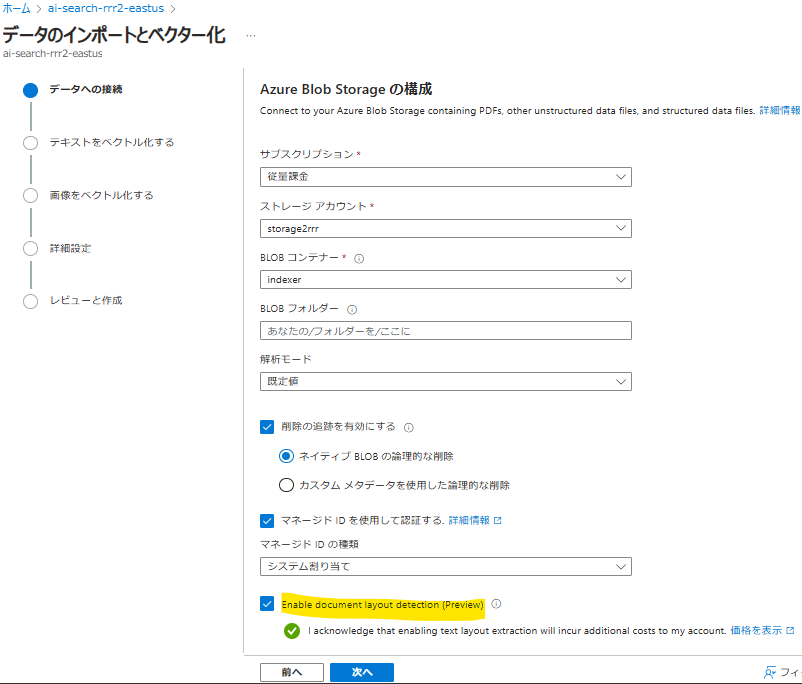
- Enable Document layout ~~ が現在は日本リージョンで選択出来ない
- ベクトル化に使用するモデルを選択する
- 登録時のベクトル化だけではなく、検索時のベクトル化も自動化してくれる
(以前はベクトル検索をしようとした時、プログラム内でベクトル化 → ベクトル検索のリクエストにベクトル化したデータを載せるという処理があったのですが、それが不要になり嬉しい。)
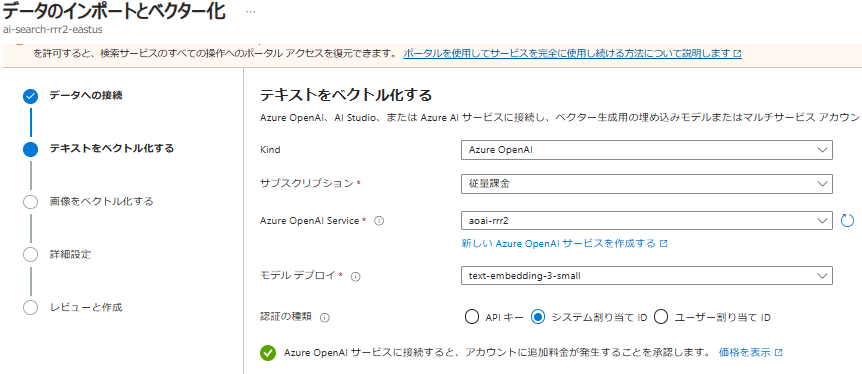
- 登録時のベクトル化だけではなく、検索時のベクトル化も自動化してくれる
- 画像のベクトル化は今回使わないので未チェックです

- 特に変更せず

- そのまま作成

雛形の取得
インデックス
- 作成されたインデックスを開いて、「JSONの編集」を選択して中身を全てコピーします
インデックス雛形
インデックス雛形
{
"name": "vector-1733068987676",
"fields": [
{
"name": "chunk_id",
"type": "Edm.String",
"key": true,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false,
"analyzer": "keyword",
"synonymMaps": []
},
{
"name": "parent_id",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": false,
"filterable": true,
"sortable": false,
"facetable": false,
"synonymMaps": []
},
{
"name": "chunk",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": []
},
{
"name": "title",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": []
},
{
"name": "header_1",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": []
},
{
"name": "header_2",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": []
},
{
"name": "header_3",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": []
},
{
"name": "text_vector",
"type": "Collection(Edm.Single)",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": [],
"dimensions": 1536,
"vectorSearchProfile": "vector-1733068987676-azureOpenAi-text-profile"
}
],
"scoringProfiles": [],
"suggesters": [],
"analyzers": [],
"tokenizers": [],
"tokenFilters": [],
"charFilters": [],
"normalizers": [],
"similarity": {
"@odata.type": "#Microsoft.Azure.Search.BM25Similarity"
},
"semantic": {
"defaultConfiguration": "vector-1733068987676-semantic-configuration",
"configurations": [
{
"name": "vector-1733068987676-semantic-configuration",
"prioritizedFields": {
"titleField": {
"fieldName": "title"
},
"prioritizedContentFields": [
{
"fieldName": "chunk"
}
],
"prioritizedKeywordsFields": []
}
}
]
},
"vectorSearch": {
"algorithms": [
{
"name": "vector-1733068987676-algorithm",
"kind": "hnsw",
"hnswParameters": {
"m": 4,
"efConstruction": 400,
"efSearch": 500,
"metric": "cosine"
}
}
],
"profiles": [
{
"name": "vector-1733068987676-azureOpenAi-text-profile",
"algorithm": "vector-1733068987676-algorithm",
"vectorizer": "vector-1733068987676-azureOpenAi-text-vectorizer"
}
],
"vectorizers": [
{
"name": "vector-1733068987676-azureOpenAi-text-vectorizer",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": "https://aoai-rrr2.openai.azure.com",
"deploymentId": "text-embedding-3-small",
"modelName": "text-embedding-3-small"
}
}
],
"compressions": []
},
"@odata.etag": "\"0x8DD122342A7D36D\""
}
インデクサー
- 作成されたインデクサーを開いて、インデックス対象ドキュメントを追記して保存します
- ドキュメント レイアウト スキルの対象ドキュメントを指定しておかないと、txt なども処理されてエラーとなります
ドキュメント レイアウト スキル - txt などは別途インデクサーを作成するイメージです
- ドキュメント レイアウト スキルの対象ドキュメントを指定しておかないと、txt なども処理されてエラーとなります
- 「JSONの編集」を選択して中身を全てコピーします
インデクサー雛形
インデクサー雛形
{
"@odata.context": "https://ai-search-rrr2-eastus.search.windows.net/$metadata#indexers/$entity",
"@odata.etag": "\"0x8DD12248E2D64B7\"",
"name": "vector-1733068987676-indexer",
"description": null,
"dataSourceName": "vector-1733068987676-datasource",
"skillsetName": "vector-1733068987676-skillset",
"targetIndexName": "vector-1733068987676",
"disabled": null,
"schedule": null,
"parameters": {
"batchSize": 1,
"maxFailedItems": null,
"maxFailedItemsPerBatch": null,
"base64EncodeKeys": null,
"configuration": {
"dataToExtract": "contentAndMetadata",
"parsingMode": "default",
"allowSkillsetToReadFileData": true,
"indexedFileNameExtensions": "\".pdf, .doc, .docx, .ppt, .pptx, .xls, .xlsx\""
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "title",
"mappingFunction": null
}
],
"outputFieldMappings": [],
"cache": null,
"encryptionKey": null
}
データソース
- データソースを開いて、「JSONの編集」を選択して中身を全てコピーします
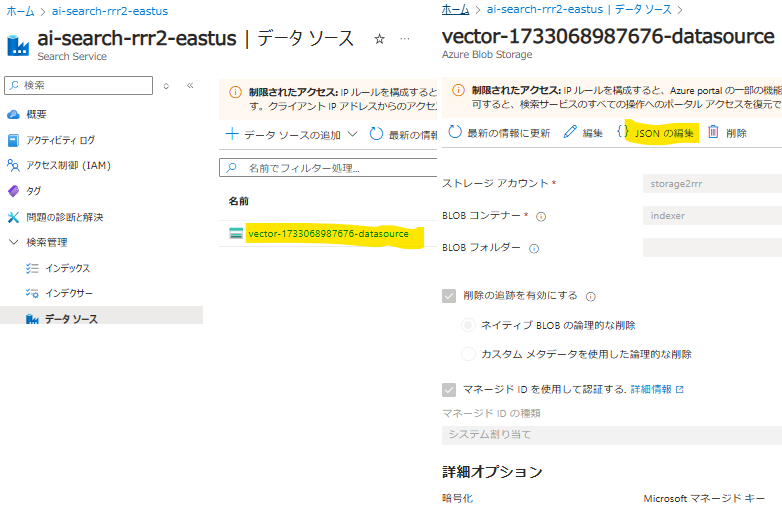
データソース雛形
データソース雛形
{
"@odata.context": "https://ai-search-rrr2-eastus.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DD12234BCEEB27\"",
"name": "vector-1733068987676-datasource",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "ResourceId=/subscriptions/[リソースID]/resourceGroups/rg-rrr2/providers/Microsoft.Storage/storageAccounts/storage2rrr;"
},
"container": {
"name": "indexer",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": {
"@odata.type": "#Microsoft.Azure.Search.NativeBlobSoftDeleteDeletionDetectionPolicy"
},
"encryptionKey": null,
"identity": null
}
スキルセット
- スキルセットを開いて、中身を全てコピーします
スキルセット雛形
スキルセット雛形
{
"name": "vector-1733068987676-skillset",
"description": "Skillset to chunk documents and generate embeddings",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Util.DocumentIntelligenceLayoutSkill",
"name": "#1",
"context": "/document",
"inputs": [
{
"name": "file_data",
"source": "/document/file_data",
"inputs": []
}
],
"outputs": [
{
"name": "markdown_document",
"targetName": "markdownDocument"
}
],
"outputMode": "oneToMany",
"markdownHeaderDepth": "h3"
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#2",
"description": "Split skill to chunk documents",
"context": "/document/markdownDocument/*",
"inputs": [
{
"name": "text",
"source": "/document/markdownDocument/*/content",
"inputs": []
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
],
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"unit": "characters"
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "#3",
"context": "/document/markdownDocument/*/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/markdownDocument/*/pages/*",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "text_vector"
}
],
"resourceUri": "https://aoai-rrr2.openai.azure.com",
"deploymentId": "text-embedding-3-small",
"modelName": "text-embedding-3-small",
"dimensions": 1536
}
],
"@odata.etag": "\"0x8DD1223439520C6\"",
"indexProjections": {
"selectors": [
{
"targetIndexName": "vector-1733068987676",
"parentKeyFieldName": "parent_id",
"sourceContext": "/document/markdownDocument/*/pages/*",
"mappings": [
{
"name": "text_vector",
"source": "/document/markdownDocument/*/pages/*/text_vector",
"inputs": []
},
{
"name": "chunk",
"source": "/document/markdownDocument/*/pages/*",
"inputs": []
},
{
"name": "title",
"source": "/document/title",
"inputs": []
},
{
"name": "header_1",
"source": "/document/markdownDocument/*/sections/h1",
"inputs": []
},
{
"name": "header_2",
"source": "/document/markdownDocument/*/sections/h2",
"inputs": []
},
{
"name": "header_3",
"source": "/document/markdownDocument/*/sections/h3",
"inputs": []
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
}
}
日本語向けに修正
- 雛形には下記の問題があるので修正する
- インデックスのアナライザ設定が Standard となっているので、日本語向けに "analyzer": "ja.lucene" とする
- スキルセットの SplitSkill が en となっているため ja に変更する
インデックスの修正
- Standard Lucene となっているフィールドについて、"analyzer": "ja.lucene" に変更する
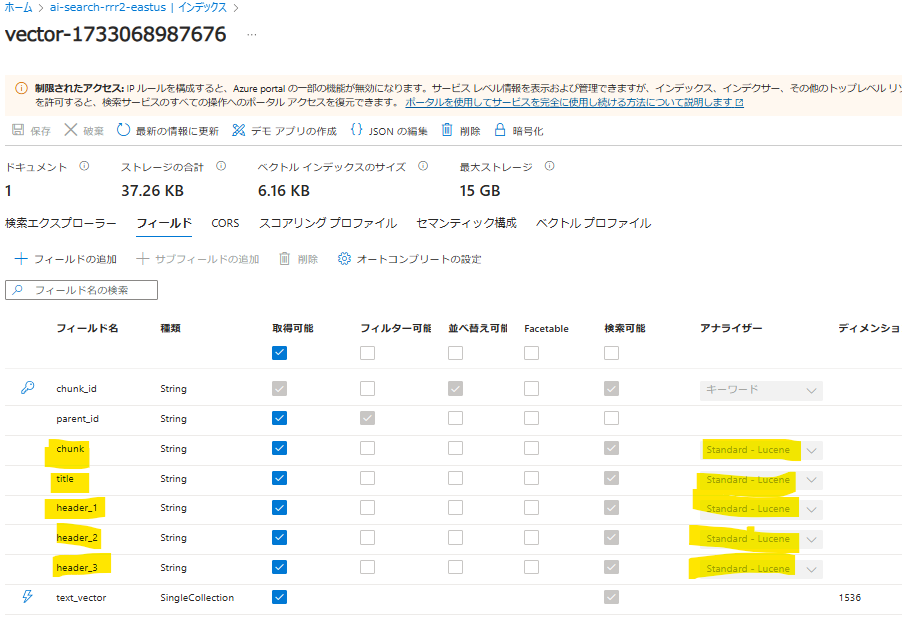
- その他プロファイル名等を任意の値に更新する
diff インデックス
diff インデックス
{
- "name": "vector-1733068987676",
+ "name": "index-1",
"fields": [
{
"name": "chunk_id",
"type": "Edm.String",
"key": true,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false,
"analyzer": "keyword",
"synonymMaps": []
},
{
"name": "parent_id",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": false,
"filterable": true,
"sortable": false,
"facetable": false,
"synonymMaps": []
},
{
"name": "chunk",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": [],
+ "analyzer": "ja.lucene"
},
{
"name": "title",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": [],
+ "analyzer": "ja.lucene"
},
{
"name": "header_1",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": [],
+ "analyzer": "ja.lucene"
},
{
"name": "header_2",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": [],
+ "analyzer": "ja.lucene"
},
{
"name": "header_3",
"type": "Edm.String",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": [],
+ "analyzer": "ja.lucene"
},
{
"name": "text_vector",
"type": "Collection(Edm.Single)",
"key": false,
"retrievable": true,
"stored": true,
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"synonymMaps": [],
"dimensions": 1536,
- "vectorSearchProfile": "vector-1733068987676-azureOpenAi-text-profile"
+ "vectorSearchProfile": "azureOpenAi-text-profile"
}
],
"scoringProfiles": [],
"suggesters": [],
"analyzers": [],
"tokenizers": [],
"tokenFilters": [],
"charFilters": [],
"normalizers": [],
"similarity": {
"@odata.type": "#Microsoft.Azure.Search.BM25Similarity"
},
"semantic": {
- "defaultConfiguration": "vector-1733068987676-semantic-configuration",
+ "defaultConfiguration": "semantic-configuration",
"configurations": [
{
- "name": "vector-1733068987676-semantic-configuration",
+ "name": "semantic-configuration",
"prioritizedFields": {
"titleField": {
"fieldName": "title"
},
"prioritizedContentFields": [
{
"fieldName": "chunk"
}
],
"prioritizedKeywordsFields": []
}
}
]
},
"vectorSearch": {
"algorithms": [
{
- "name": "vector-1733068987676-algorithm",
+ "name": "vector-algorithm",
"kind": "hnsw",
"hnswParameters": {
"m": 4,
"efConstruction": 400,
"efSearch": 500,
"metric": "cosine"
}
}
],
"profiles": [
{
- "name": "vector-1733068987676-azureOpenAi-text-profile",
+ "name": "azureOpenAi-text-profile",
- "algorithm": "vector-1733068987676-algorithm",
+ "algorithm": "vector-algorithm",
- "vectorizer": "vector-1733068987676-azureOpenAi-text-vectorizer"
+ "vectorizer": "azureOpenAi-text-vectorizer"
}
],
"vectorizers": [
{
- "name": "vector-1733068987676-azureOpenAi-text-vectorizer",
+ "name": "azureOpenAi-text-vectorizer",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": "https://aoai-rrr2.openai.azure.com",
"deploymentId": "text-embedding-3-small",
"modelName": "text-embedding-3-small"
}
}
],
"compressions": []
},
"@odata.etag": "\"0x8DD122342A7D36D\""
}
インデクサーの修正
- 任意の変更箇所を修正する
diff インデクサー
diff インデクサー
{
"@odata.context": "https://ai-search-rrr2-eastus.search.windows.net/$metadata#indexers/$entity",
"@odata.etag": "\"0x8DD12248E2D64B7\"",
- "name": "vector-1733068987676-indexer",
+ "name": "indexer",
"description": null,
- "dataSourceName": "vector-1733068987676-datasource",
+ "dataSourceName": "datasource",
- "skillsetName": "vector-1733068987676-skillset",
+ "skillsetName": "skillset",
- "targetIndexName": "vector-1733068987676",
+ "targetIndexName": "index-1",
"disabled": null,
"schedule": null,
"parameters": {
"batchSize": 1,
"maxFailedItems": null,
"maxFailedItemsPerBatch": null,
"base64EncodeKeys": null,
"configuration": {
"dataToExtract": "contentAndMetadata",
"parsingMode": "default",
"allowSkillsetToReadFileData": true,
"indexedFileNameExtensions": "\".pdf, .doc, .docx, .ppt, .pptx, .xls, .xlsx,\""
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "title",
"mappingFunction": null
}
],
"outputFieldMappings": [],
"cache": null,
"encryptionKey": null
}
データソースの修正
- 任意の変更箇所を修正する
diff データソース
diff データソース
{
"@odata.context": "https://ai-search-rrr2-eastus.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DD12234BCEEB27\"",
- "name": "vector-1733068987676-datasource",
+ "name": "datasource",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "ResourceId=/subscriptions/[リソースID]/resourceGroups/rg-rrr2/providers/Microsoft.Storage/storageAccounts/storage2rrr;"
},
"container": {
"name": "indexer",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": {
"@odata.type": "#Microsoft.Azure.Search.NativeBlobSoftDeleteDeletionDetectionPolicy"
},
"encryptionKey": null,
"identity": null
}
スキルセットの修正
- SplitSkill が en となっているため ja に変更する
- 任意の変更箇所を修正する
diff スキルセット
diff スキルセット
{
- "name": "vector-1733068987676-skillset",
+ "name": "skillset",
"description": "Skillset to chunk documents and generate embeddings",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Util.DocumentIntelligenceLayoutSkill",
"name": "#1",
"context": "/document",
"inputs": [
{
"name": "file_data",
"source": "/document/file_data",
"inputs": []
}
],
"outputs": [
{
"name": "markdown_document",
"targetName": "markdownDocument"
}
],
"outputMode": "oneToMany",
"markdownHeaderDepth": "h3"
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#2",
"description": "Split skill to chunk documents",
"context": "/document/markdownDocument/*",
"inputs": [
{
"name": "text",
"source": "/document/markdownDocument/*/content",
"inputs": []
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
],
- "defaultLanguageCode": "en",
+ "defaultLanguageCode": "ja",
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"unit": "characters"
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "#3",
"context": "/document/markdownDocument/*/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/markdownDocument/*/pages/*",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "text_vector"
}
],
"resourceUri": "https://aoai-rrr2.openai.azure.com",
"deploymentId": "text-embedding-3-small",
"modelName": "text-embedding-3-small",
"dimensions": 1536
}
],
"@odata.etag": "\"0x8DD1223439520C6\"",
"indexProjections": {
"selectors": [
{
- "targetIndexName": "vector-1733068987676",
+ "targetIndexName": "index-1",
"parentKeyFieldName": "parent_id",
"sourceContext": "/document/markdownDocument/*/pages/*",
"mappings": [
{
"name": "text_vector",
"source": "/document/markdownDocument/*/pages/*/text_vector",
"inputs": []
},
{
"name": "chunk",
"source": "/document/markdownDocument/*/pages/*",
"inputs": []
},
{
"name": "title",
"source": "/document/title",
"inputs": []
},
{
"name": "header_1",
"source": "/document/markdownDocument/*/sections/h1",
"inputs": []
},
{
"name": "header_2",
"source": "/document/markdownDocument/*/sections/h2",
"inputs": []
},
{
"name": "header_3",
"source": "/document/markdownDocument/*/sections/h3",
"inputs": []
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
}
}
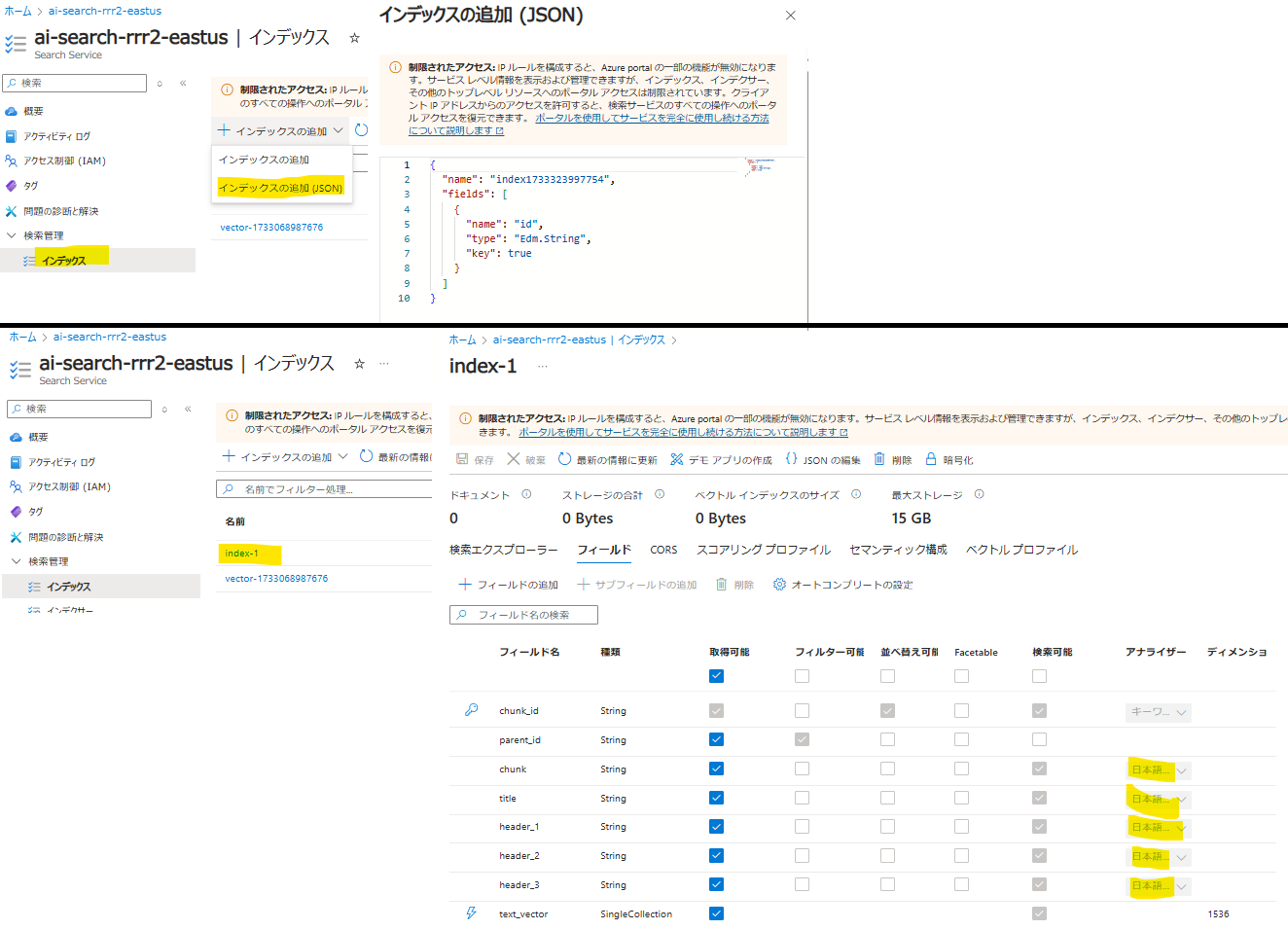
修正した JSON を使って各種作成
- 「インデックス」→「データソース」→「スキルセット」→「インデクサー」の順で作成します
- 修正した JSON の登録は japan リージョンの AISearch でも可能でした
- Document Intelligence は API の関係で特定リージョンのみかもしれません
インデックス
- 修正した JSON を登録します
データソース
- 修正した JSON を登録します
スキルセット
- 修正した JSON を登録します
インデクサー
- 修正した JSON を登録します
- 作成すると1回動きます(JSON の設定による)
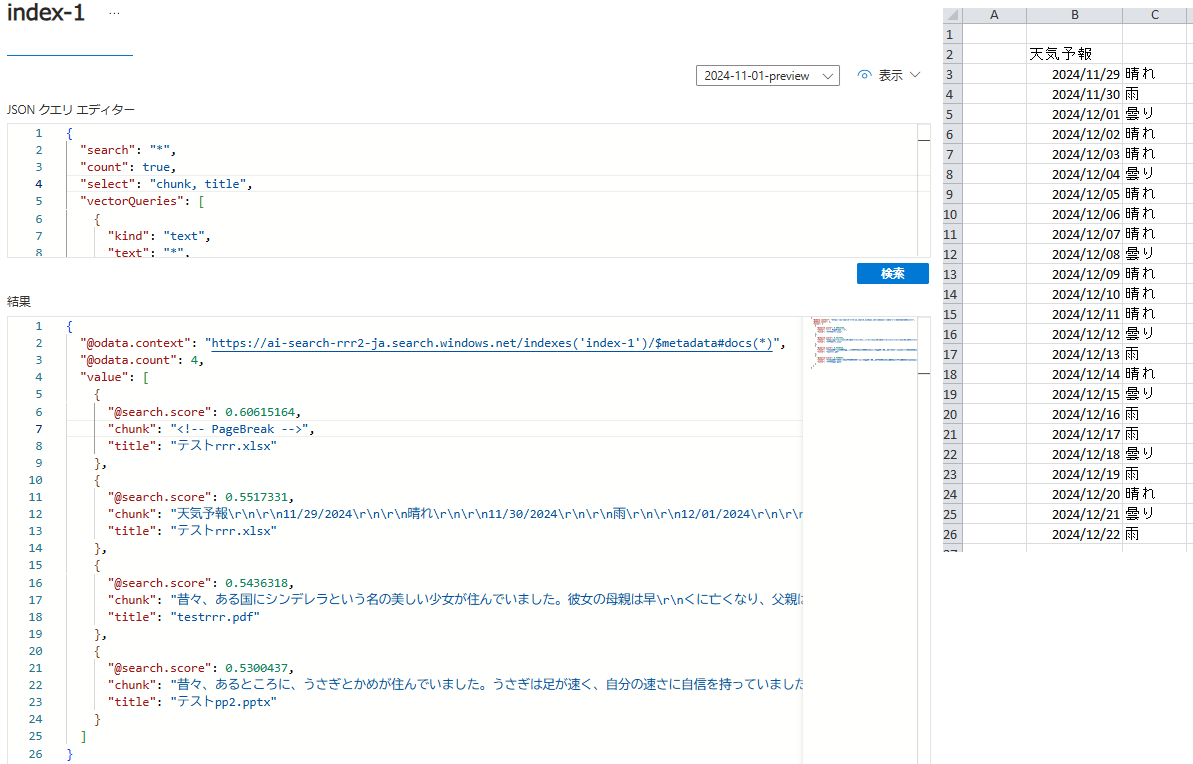
確認
- ストレージにある対象拡張子のデータが登録されます
- 画像にはないですが、ベクトルデータも登録されています
インデクサーを使う事の利点
- Blob や SharePoint のファイルを定期的に読み込む際は Azure Logic Apps などのリソースを作成し、追加・更新・削除などを追跡する手間があったがインデクサー機能を使えば不要となる(インデクサーが更新・削除まで追跡してくれるのですごく楽)
- pdf は別として、各種 office 系ファイルの読み込みは以外と面倒くさい(python だと libre office のライブラリを用いて読み込む必要がある)が、インデクサーを使えば勝手に読み込んでくれるのでかなり楽になる
- 今までコードを書いて実現していたインデックス登録処理の手間(レイアウトスキル、スプリットスキルなど)がかなり軽減されるので、その点もかなり良かった(新しい環境の度にインデックスを整備するのがかなり
面倒だったため)
デメリット
- 処理に5分以上かかるファイルはエラーとして落とされるらしい
そのため大容量ファイルをインデックス登録したい場合はファイル自体を分割してから登録するか、コードを書いて処理する事になりそうです
https://learn.microsoft.com/ja-jp/azure/search/cognitive-search-skill-document-intelligence-layout#limitations