目的
本ページの目的は交差検証におけるランダム性の違いを確認する。そのために、以下の内容で話を進める。
- 説明を簡単にするために iris データを利用
- Kfold 検定のランダム性ありとランダム性なしを比較
- Kfold 検定とStratifiledKFoldを比較する
背景
以前までは機械学習技術を利用して作成されたモデルはブラックボックスとされてきた。しかし、近年では機械学習を利用して作成されたモデルはいくつかの方法で説明できるようになりつつある。その中の一つとして、学習データを振り分ける際のランダム性によってモデルが如何に妥当であるか、という議論もなされるようになってきた。
学術的な背景 (間違ってたらご指摘願います。学者以外はスキップ)
- Kohavi さんの論文 (被引用数 9000 オーバー)では ten-fold-Stratified-cross-validation がモデル選択にベストな方法であると述べている(ただ手法が古いけど)。データや現在の手法では異なるかもしれないが、利用する価値はありそうである。
- 恐らく、Kohavi さんの論文によると、Weiss, S. M. (1991)がStratified-cross-validationを初めに比較したように読める。
本ページを読み終えて理解すること
- 交差検証による分類対象(クラス)の振り分けを均等にするためには、StratifiledKFoldを利用する必要がある。
データの読み込み
データ読み込みと変換の趣旨
- sklearn では様々なパッケージを利用する際に pandas が便利である。
- numpy 形式の iris データを pandas 形式に変換する。
- 重要変数
- data_setは機械学習の用語である特徴量(もしくは特徴変数) を表す
- target_setは機械学習の用語であるクラス (分類対象, setosa などはクラスラベル)を表す
- all_dataは data_set と target_set を結合させたもの
from sklearn.datasets import load_iris
import seaborn as sns
# データ読み込み
iris = load_iris()
# データの確認
pd.set_option('display.max_rows', 5)
display(pd.DataFrame(iris.data,
columns = iris.feature_names))
# データタイプの確認
print(type(iris.data), type(iris.target))
# pandas のデータフレーム に変換 (特徴量
data_set = pd.DataFrame(iris.data,
columns=iris.feature_names)
# クラスラベルを pandas の seriesに変換
target_set = pd.Series(iris.target)
for i, val in enumerate(iris.target_names):
target_set = target_set.replace(i,val)
display(target_set)
# これまでのデータを一つの変数にまとめる
all_data = data_set.copy()
all_data["target"] = target_set.copy()
all_data.describe()
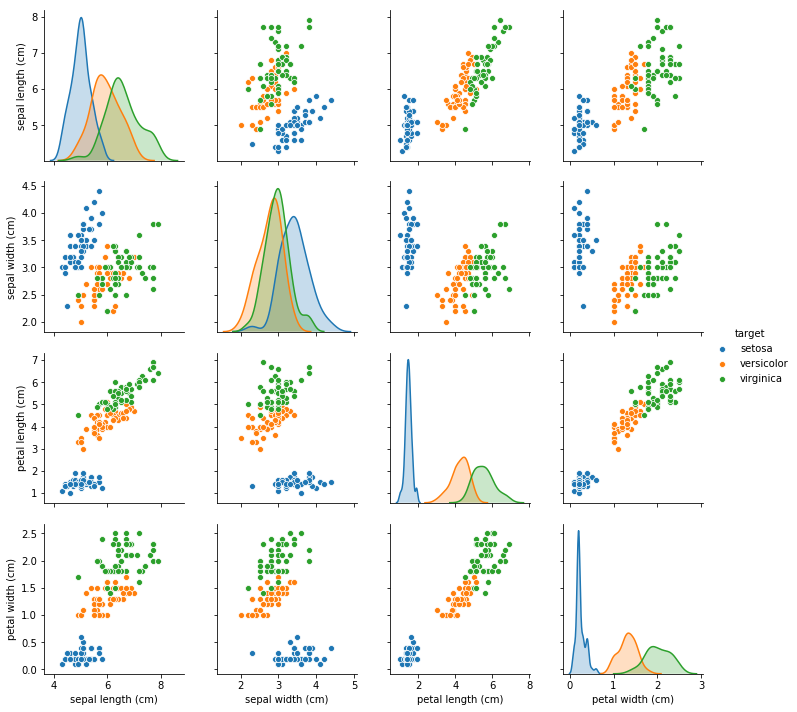
# それぞれのクラスラベルをx軸にとり、各クラスラベルのデータを表示する
sns.pairplot(data = all_data,hue="target")
# 分割の仕方のメモ
# X_train, X_test, y_train, y_test = train_test_split(iris.data,
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| ... | ... | ... | ... | ... |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 |
150 rows × 4 columns
<class 'numpy.ndarray'> <class 'numpy.ndarray'>
0 setosa
1 setosa
...
148 virginica
149 virginica
Length: 150, dtype: object
交差検証
- 交差検証はクロスバリデーション(Cross-validation)とも呼ばれる。
- 交差検証には様々な種類がある。
- 最も代表的な K-分割交差検証 (k-fold cross-validation) と StratifiedKFold の違いを確認する。
Kfold shuffle=True
- プログラムの実行結果、クラスラベルの種類別個数の実行例は以下の通りである。
- クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([8, 5, 2]))
- クラスラベルの種類別個数(array(['versicolor', 'virginica'], dtype=object), array([ 5, 10]))
- 以上の内容から、KFold ではクラスラベルの種類別個数が一致していない。
from sklearn.model_selection import StratifiedKFold, cross_validate, KFold
# データを 10 分割させる。
# 分割する際には、分割させる前のデータからシャッフルする。
k = KFold(n_splits=10,
shuffle=True,
random_state=0)
for train_index, test_index in k.split(data_set, target_set):
print("分割されたデータセットの大きさ:{}".format(target_set[test_index].shape))
print("分割される以前のデータセットのどこを抽出したのか?:{}".format(test_index))
print("クラスラベル:{}".format(target_set[test_index]))
print("クラスラベルの種類別個数{}".format(
np.unique(target_set[test_index],return_counts=True)))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 7 33 40 51 54 62 63 71 73 76 86 100 107 114 134]
クラスラベル:7 setosa
33 setosa
...
114 virginica
134 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([3, 8, 4]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 8 16 22 24 26 37 44 45 66 78 90 93 97 121 126]
クラスラベル:8 setosa
16 setosa
...
121 virginica
126 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([8, 5, 2]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 2 10 18 27 43 59 61 83 84 92 112 127 132 137 141]
クラスラベル:2 setosa
10 setosa
...
137 virginica
141 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 50 56 60 69 80 106 108 116 119 123 133 135 144 146 147]
クラスラベル:50 versicolor
56 versicolor
...
146 virginica
147 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['versicolor', 'virginica'], dtype=object), array([ 5, 10]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 13 15 20 30 48 52 64 85 89 91 94 95 101 111 125]
クラスラベル:13 setosa
15 setosa
...
111 virginica
125 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 7, 3]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 3 6 11 12 46 68 96 98 102 104 109 110 120 128 149]
クラスラベル:3 setosa
6 setosa
...
128 virginica
149 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 3, 7]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 1 4 5 17 38 41 42 53 105 113 124 129 139 143 148]
クラスラベル:1 setosa
4 setosa
...
143 virginica
148 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([7, 1, 7]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 0 23 28 31 32 34 35 55 57 65 74 75 118 131 138]
クラスラベル:0 setosa
23 setosa
...
131 virginica
138 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([7, 5, 3]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 14 19 25 29 49 72 77 79 82 99 115 122 130 136 145]
クラスラベル:14 setosa
19 setosa
...
136 virginica
145 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 9 21 36 39 47 58 67 70 81 87 88 103 117 140 142]
クラスラベル:9 setosa
21 setosa
...
140 virginica
142 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 6, 4]))
Kfold shuffle=False
KFold の 引数 shuffle = False を利用すると、下記のようにシャッフルされない。
- 実行結果は例えば次の通りである。
- 分割される以前のデータセットのどこを抽出したのか?:[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
- 分割される以前のデータセットのどこを抽出したのか?:[15 16 17 18 19 20 21 22 23 24 25 26 27 28 29]
- 以上よりデータの並び順で交差検証用のデータを作成していることがわかる。
このまま利用すると学習時に大きな問題を抱えそう。
そのため、shuffle は 基本的に Trueが推奨されると考えられる。
k = KFold(n_splits=10,
shuffle=False,
random_state=0)
for train_index, test_index in k.split(data_set, target_set):
print("分割されたデータセットの大きさ:{}".format(target_set[test_index].shape))
print("分割される以前のデータセットのどこを抽出したのか?:{}".format(test_index))
print("クラスラベル:{}".format(target_set[test_index]))
print("クラスラベルの種類別個数{}".format(
np.unique(target_set[test_index],return_counts=True)))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
クラスラベル:0 setosa
1 setosa
...
13 setosa
14 setosa
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa'], dtype=object), array([15]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[15 16 17 18 19 20 21 22 23 24 25 26 27 28 29]
クラスラベル:15 setosa
16 setosa
...
28 setosa
29 setosa
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa'], dtype=object), array([15]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[30 31 32 33 34 35 36 37 38 39 40 41 42 43 44]
クラスラベル:30 setosa
31 setosa
...
43 setosa
44 setosa
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa'], dtype=object), array([15]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[45 46 47 48 49 50 51 52 53 54 55 56 57 58 59]
クラスラベル:45 setosa
46 setosa
...
58 versicolor
59 versicolor
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor'], dtype=object), array([ 5, 10]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[60 61 62 63 64 65 66 67 68 69 70 71 72 73 74]
クラスラベル:60 versicolor
61 versicolor
...
73 versicolor
74 versicolor
Length: 15, dtype: object
クラスラベルの種類別個数(array(['versicolor'], dtype=object), array([15]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[75 76 77 78 79 80 81 82 83 84 85 86 87 88 89]
クラスラベル:75 versicolor
76 versicolor
...
88 versicolor
89 versicolor
Length: 15, dtype: object
クラスラベルの種類別個数(array(['versicolor'], dtype=object), array([15]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104]
クラスラベル:90 versicolor
91 versicolor
...
103 virginica
104 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['versicolor', 'virginica'], dtype=object), array([10, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[105 106 107 108 109 110 111 112 113 114 115 116 117 118 119]
クラスラベル:105 virginica
106 virginica
...
118 virginica
119 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['virginica'], dtype=object), array([15]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[120 121 122 123 124 125 126 127 128 129 130 131 132 133 134]
クラスラベル:120 virginica
121 virginica
...
133 virginica
134 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['virginica'], dtype=object), array([15]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[135 136 137 138 139 140 141 142 143 144 145 146 147 148 149]
クラスラベル:135 virginica
136 virginica
...
148 virginica
149 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['virginica'], dtype=object), array([15]))
StratifiedKFold の検証
StratifiledKFold 関数は Kfold 関数とクラスラベルの扱いが異なる。
StratifiledKFold 関数は なるべくクラスラベルが均等に割り振られるように交差検証を行う。
引用: StratifiedKFold
- 実行結果は例えば次のようなものが挙げられる。
- クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
以上からクラスラベルが均等に分けられた上で交差検証用のデータが作成されていることがわかる。
skf = StratifiedKFold(n_splits=10,
shuffle=True,
random_state=0)
for train_index, test_index in skf.split(data_set, target_set):
print("分割されたデータセットの大きさ:{}".format(target_set[test_index].shape))
print("分割される以前のデータセットのどこを抽出したのか?:{}".format(test_index))
print("クラスラベル:{}".format(target_set[test_index]))
print("クラスラベルの種類別個数{}".format(
np.unique(target_set[test_index],return_counts=True)))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 2 10 11 28 41 52 60 61 78 91 102 110 111 128 141]
クラスラベル:2 setosa
10 setosa
...
128 virginica
141 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 4 22 27 31 38 54 72 77 81 88 104 122 127 131 138]
クラスラベル:4 setosa
22 setosa
...
131 virginica
138 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 18 26 33 34 35 68 76 83 84 85 118 126 133 134 135]
クラスラベル:18 setosa
26 setosa
...
134 virginica
135 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 7 14 29 45 48 57 64 79 95 98 107 114 129 145 148]
クラスラベル:7 setosa
14 setosa
...
145 virginica
148 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 15 16 30 32 42 65 66 80 82 92 115 116 130 132 142]
クラスラベル:15 setosa
16 setosa
...
132 virginica
142 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 8 13 20 25 43 58 63 70 75 93 108 113 120 125 143]
クラスラベル:8 setosa
13 setosa
...
125 virginica
143 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 1 5 17 40 49 51 55 67 90 99 101 105 117 140 149]
クラスラベル:1 setosa
5 setosa
...
140 virginica
149 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 6 12 23 24 37 56 62 73 74 87 106 112 123 124 137]
クラスラベル:6 setosa
12 setosa
...
124 virginica
137 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 9 19 21 36 39 59 69 71 86 89 109 119 121 136 139]
クラスラベル:9 setosa
19 setosa
...
136 virginica
139 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))
分割されたデータセットの大きさ:(15,)
分割される以前のデータセットのどこを抽出したのか?:[ 0 3 44 46 47 50 53 94 96 97 100 103 144 146 147]
クラスラベル:0 setosa
3 setosa
...
146 virginica
147 virginica
Length: 15, dtype: object
クラスラベルの種類別個数(array(['setosa', 'versicolor', 'virginica'], dtype=object), array([5, 5, 5]))