概要
ある言語を学び始めるとき、一番初めに作るプログラムはたいていの場合"Hello World"を出力するものだと思います。Javaの場合は以下のようなコードで出力します。
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
しかし、もっといい出力の方法があるのではないでしょうか。今回はいろいろ試してみたいと思います。
プログラム例
16進数で指定
Unicodeで一文字ずつ指定していきます。
public class HelloWorld {
public static void main(String[] args) {
String helloWorld = new String("\u0048" +
"\u0065" +
"\u006c" +
"\u006c" +
"\u006f" +
"\u0020" +
"\u0057" +
"\u006f" +
"\u0072" +
"\u006c" +
"\u0064");
System.out.println(helloWorld);
}
}
実行結果:Hello World
2進数で指定
まず2進数で文字を指定し、それらを16進数に変換、そして文字に変換し出力。
public class HelloWorld {
public static void main(String[] args) {
//二進数を保持
String[] helloWorldLetters = {"1001000",
"1100101",
"1101100",
"1101100",
"1101111",
"100000",
"1010111",
"1101111",
"1110010",
"1101100",
"1100100"};
//上記の配列を16進数に変換。変数「line」には変換結果を入れる
String line = "";
for (String helloWorldLetter:helloWorldLetters) {
int decimal = Integer.parseInt(helloWorldLetter, 2);
//2進数を16進数に変換
String hex = Integer.toHexString(decimal);
//16進数にしたものを、Unicodeに変換
char letter = (char)Integer.parseInt(hex,16);
line += letter;
}
String helloWorld = new String(line);
System.out.println(helloWorld);
}
}
実行結果:Hello World
"Hello"と"World"の作成処理をそれぞれスレッド化して並行に実行
HelloとWorldを、スレッド処理を用いて同時に作成し、両方の処理が完了するのを待って出力します。Runnableだと返り値を持てないので、Callableを用いて実装します。
まず、スレッドを呼び出す側のコードがこちら。
package HelloWorld;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class HelloWorld {
public static void main(String[] args) {
//結果を格納する変数
String helloWorld;
//スレッドの作成
ExecutorService service = Executors.newFixedThreadPool(2);
Future<String> future1 = service.submit(new HelloWorldCallable(0));
Future<String> future2 = service.submit(new HelloWorldCallable(1));
try {
//返ってきた値を一つにまとめる
helloWorld = future1.get() + future2.get();
System.out.println(helloWorld);
}catch(Exception e) {
System.out.println(e.getMessage());
}
}
}
呼び出される側のコードがこちら。
package HelloWorld;
import java.util.concurrent.Callable;
public class HelloWorldCallable implements Callable<String>{
//何番目に呼び出されたかを保持
private int num;
public HelloWorldCallable(int num) {
this.num = num;
}
public String call() {
if(this.num == 0) {
return "Hello ";
}else {
return "World";
}
}
}
実行結果Hello World
1文字ずつスレッド処理で作成
上の例だと"Hello"と"World"の二つだけに分けていますが、どうせだったら文字ごとにバラしてみます。
package HelloWorld;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class HelloWorld {
public static void main(String[] args) {
//結果を格納する変数
String helloWorld = "";
//スレッドからの結果を格納
List<Future<String>> futures = new ArrayList<Future<String>>();
//スレッドの作成
ExecutorService service = Executors.newFixedThreadPool(10);
for(int i = 0; i < 11; i++) {
futures.add(service.submit(new HelloWorldCallable(i)));
}
try {
for (Future<String> future:futures) {
if(future.isDone()) {
helloWorld += future.get();
}
}
System.out.println(helloWorld);
}catch(Exception e) {
System.out.println(e.getMessage());
}
}
}
package HelloWorld;
import java.util.concurrent.Callable;
public class HelloWorldCallable implements Callable<String>{
private static String[] message = {"H","e","l","l","o"," ","W","o","r","l","d"};
//何番目に呼び出されたかを保持
private int num;
public HelloWorldCallable(int num) {
this.num = num;
}
public String call() {
return message[num];
}
}
実行結果:Hello World
HelloWorldCallableクラスのStatic変数に、ほとんど"Hello World"に近しいものが書かれてしまっていますが、気にしないでください。
ウェブ上から"Hello World"をスクレイピングして出力
日本語版Wikipediaのこのページのタイトルから文字をとってきます。
import java.util.List;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class HelloWorld {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "chromedriverが置いてある場所");
WebDriver driver = new ChromeDriver();
//情報を取得するウェブサイト
String url = "https://ja.wikipedia.org/wiki/Hello_world";
//取得したい情報が書いてあるHTML要素(今回はWikipediaのタイトルのクラス名)
String target = "firstHeading";
driver.get(url);
//クラス名で指定しているため複数結果が得られる場合がある
List<WebElement> values = driver.findElements(By.className(target));
for (WebElement t : values){
String value = t.getText();
//そのままだと「Hello world」が出力されるため、「w」を大文字に変換
String str = value.substring(0, 6)
+ value.substring(6, 7).toUpperCase()
+ value.substring(7);
System.out.println(str);
}
}
}
実行結果:Hello World
ウェブ上から一文字ずつスクレイピングして出力
上の例だと文字列のすべて一つのサイトからとってきているが、そんな楽をせず一文字ずつ違う場所から取ってくる方法がこちら。文字の取得元はそれぞれ、英語版Wikipediaの以下のページのタイトル部分となる。
| 文字 | Wikiのタイトル | 日本語訳(カテゴリー) |
|---|---|---|
| H | Harry Potter | ハリーポッター(映画) |
| e | The Human Centipede | 人間ムカデ(伝説の映画) |
| l | Flying Spaghetti Monster | 空飛ぶスパゲッティモンスター教(宗教) |
| l | Lil Wayne | リル・ウェイン(ラッパー) |
| o | Konjac | こんにゃく(食べ物) |
| - | Null Pointer | ヌルポインターエクセプション(例外) |
| W | Wikipedia | Wikipedia (Wikipedia) |
| o | Morgan Freeman | モーガン・フリーマン(俳優) |
| r | Starbucks | スターバックス(企業) |
| l | Family guy | ファミリー・ガイ(アニメ) |
| d | Angry Birds | アングリーバーズ(ゲーム) |
import java.util.List;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class HelloWorld {
public static void main(String[] args) {
//Wikiのページを保持
String[] url = {"Harry_Potter",
"The_Human_Centipede_(First_Sequence)",
"Flying_Spaghetti_Monster",
"Lil_Wayne",
"Konjac",
"Null_pointer",
"Wikipedia",
"Morgan_Freeman",
"Starbucks",
"Family_Guy",
"Angry_Birds"};
//タイトルの何文字目にターゲットの文字があるかを保持
int[] location = {0,2,1,2,1,4,0,1,3,4,9};
String helloWorld = makeHelloWorld(url,location);
System.out.println(helloWorld);
}
private static String makeHelloWorld(String[] url, int[] location) {
System.setProperty("webdriver.chrome.driver", "chromedriverの置いてある場所");
WebDriver driver = new ChromeDriver();
//結果を保持する変数
String result = "";
//取得する文字列のあるHTML要素(今回はタイトル部分のクラス名)
String target = "firstHeading";
for (int i = 0; i < url.length; i++) {
driver.get("https://en.wikipedia.org/wiki/" + url[i]);
//HTML要素から文字を取得
List<WebElement> values = driver.findElements(By.className(target));
for (WebElement t : values){
String value = t.getText();
//取得した文字列から、一文字を切り出し
char letter = value.charAt(location[i]);
result += letter;
}
}
return result;
}
}
実行結果:Hello World
これまでのものよりだいぶ時間がかかりました。
「こんにちは 世界」をGoogleのAPIで翻訳して出力
そもそも英語で"Hello World"だなんて打ち込むのが嫌な人は、日本語で「こんにちは 世界」書いてそれをGoogleのAPIを用いて翻訳させましょう。
ここで用いるGoogleのCloud Translation APIですが、https://www.googleapis.com/language/translate/v2?key=あなたのキー&q=Hello&source=en&target=jaのようなリクエストを出すと、

のようなレスポンスが返ってきます。早速使ってみましょう
package HelloWorld;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.json.JSONArray;
import org.json.JSONObject;
public class HelloWorld {
public static void main(String[] args) {
//翻訳する前の日本語
String ja = "こんにちは 世界";
//GoogleのAPIを利用する際のキー
String key = "あなたのキー";
String baseUrl = "https://www.googleapis.com/language/translate/v2?key=";
//リクエストの送信先となるurlを作成
String urlText = baseUrl + key + "&q=" + ja + "&source=ja&target=en";
try {
//通信を行う
URL url = new URL(urlText);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
//GETメソッドを指定
conn.setRequestMethod("GET");
InputStream in = conn.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
StringBuilder output = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
output.append(line);
}
//返答内容をJSONObject型に変換
JSONObject json = new JSONObject(output.toString());
//結果が格納されている部分まで掘り下げる
JSONObject data = json.getJSONObject("data");
JSONArray translations = data.getJSONArray("translations");
JSONObject firstItem = (JSONObject)translations.get(0);
String result = firstItem.getString("translatedText");
System.out.println(result);
}catch(IOException e) {
System.out.println(e.getMessage());
}
}
}
実行結果:Hello World
英語を使わずにHello Worldが出力できましたね。
「Hello World」と返すだけのサーブレットを仮想サーバに作成する
今度は、"Hello World"というリスポンスを返すだけのサーブレットを作り仮想サーバにアップし、そこにアクセスすることで"Hello World"の文字列を取得するプログラムを作ります。
まずはサーブレットの部分。
package HelloWorld;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class HelloWorld extends HttpServlet{
//GETメソッドで呼ばれた時
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/plain");
PrintWriter out = response.getWriter();
out.println("Hello World");
}
}
これを、Virtual Boxを使って作った仮想サーバにアップをしていきます。ApacheとTomcatがインストールされていることを前提で軽く説明していきます。まず以下のようなディレクトリを作っていきます。
tomcat
┣ webapps
┣ HelloWorld (ここ以下を新しく追加)
┗ WEB-INF
┣ web.xml(後で説明)
┗ classes
┗ HelloWorld
┗ HelloWorld.java (上にソースコードをのせたやつです)
┣ docs
┣ examples
┣ host-manager
┗ manager
┗ work
web.xmlをいじることで、リクエストのurlとサーブレットのファイルをひもづけられます。web.xmlの記述は以下。
<?xml version="1.0" encoding="ISO-8859-1"?>
<web-app xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd"
version="2.4">
<servlet>
<servlet-name>HelloWorld</servlet-name>
<servlet-class>HelloWorld.HelloWorld</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>HelloWorld</servlet-name>
<url-pattern>/HelloWorldApi</url-pattern>
</servlet-mapping>
</web-app>
さらに、Apacheの設定もいじっていきます。httpd.conf(CentOSであれば/etc/httpd/conf/にあると思います)の一番下に、以下の記述を追加します。
ProxyPass /HelloWorld/ ajp://localhost:8009/HelloWorld/
これで、/HelloWorld以下へのリクエストはApacheからTomcatへ渡されます。
javacコマンドでコンパイルすると、サーブレット部分は完成です。
試しにブラウザからurlを叩いて見ると、以下のようにちゃんと情報が取れていることがわかります。
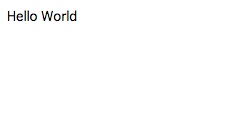
最後に、このサーブレットを利用するクラスを作ります。
package HelloWorld;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class HelloWorld{
public static void main(String[] args) {
try {
//サーブレットへ要求を出すためのurl
URL url = new URL("http://192.168.33.10/HelloWorld/HelloWorldApi");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
InputStream in = conn.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
StringBuilder output = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
output.append(line);
}
System.out.println(output.toString());
}catch(IOException e) {
System.out.println(e.getMessage());
}
}
}
実行結果:Hello World
ちゃんと情報が取れてます。
仮想サーバではなくdockerにサーブレットを配置
上の例では仮想サーバにサーブレットを置いていましたが、dockerでApacheとTomcatの環境を作り、そこにサーブレットを置くことにします。@shintaro123さんの記事を参考にしました。
まずは以下のようなディレクトリを作ります。
docker
┣ httpd
┣ Dockerfile (※1)
┣ httpd-proxy.conf
┗ run-httpd.sh
┗ tomcat
┣ Dockerfile (※2)
┣ HelloWorld (ここ以下は、上と同じです)
┗ WEB-INF
┗ web.xml
┗ classes
┗ HelloWorld
┗ HelloWorld.java
┗ docker-compose.yml (※3)
※1のファイル
FROM centos:7
RUN yum -y update && yum clean all
RUN yum -y install httpd httpd-devel gcc* make && yum clean all
ADD httpd-proxy.conf /etc/httpd/conf.d/
ADD run-httpd.sh /run-httpd.sh
RUN chmod -v +x /run-httpd.sh
CMD ["/run-httpd.sh"]
※2のファイル
FROM tomcat:9.0.1-alpine
COPY HelloWorld /usr/local/tomcat/webapps/HelloWorld/
RUN rm -rf /usr/local/tomcat/webapps/ROOT
CMD ["catalina.sh","run"]
※3のファイル
version: '3'
services:
httpd:
container_name: httpd-container
build: ./httpd
ports:
- "80:80"
tomcat:
container_name: tomcat-container
build: ./tomcat
expose:
- "8009"
volumes:
data: {}
/docker/にcdして、
docker-compose build --no-cache
docker-compose up -d
のコマンドを打てば、サーブレットから情報が取れるようになります。Hello Worldを出力するファイルは、仮想サーバにサーブレットを置いた時のものと同じになります。
ランダムな文字列を発生させて、"Hello World"となるのを待って出力
Kilisameさんのアイディアです。ランダムに文字列をつくり、それが"Hello World"となったら出力するというもの。完全にランダムに文字列を発生させていると永遠に終わらないので、「H」「e」「l」「o」「 」「W」「r」「d」の8種類の文字からランダムで文字列を作ります。
package HelloWorld;
import java.util.Random;
public class HelloWorld{
public static void main(String[] args) {
final String[] letters = {"H","e","l","o"," ","W","r","d"};
Random random = new Random();
//ランダムに生成された文字列を保持
String helloWorld = "";
//trueであれば、下のwhile文を抜ける
boolean done = false;
//せっかくなので、何回目のループで成功したのかを保持
double count = 0;
while (done == false) {
count += 1;
helloWorld = "";
for (int i = 0; i < 11; i++) {
int randomNum = random.nextInt(8);
String helloChar = letters[randomNum];
helloWorld += helloChar;
}
if(helloWorld.equals("Hello World")) {
done = true;
}
System.out.println(helloWorld);
}
System.out.println(helloWorld);
System.out.println("At " + count + "th Time");
}
}
実行結果:Hello World At 7.98865771E8th Time
7億9886万5771回目に成功しました
まとめ
Hello Worldは普通に出力するのが良さそうです。
もしもより複雑なHello Worldの出力方法を思いついたら、コメントに書き込んでください。