概要
Googleの画像認識のAPIであるCloud Vision APIを用いて、ユーザがアップロードした画像の①ラベル認識、②テキスト解析、③表情分析を行うウェブページを作ります。作成にはGoogle Cloud Visionのキーが必要になります(基本的に無料)。必要となる知識は、初歩的なHTMLとJavaScriptの知識のみです。
Google Cloud Visionとは
APIを通してGoogleの画像認識の技術を利用できるサービスです。公式のウェブサイトの文章を借りると、このAPIの特徴は以下の通りになります。
Google Cloud Vision API は、膨大な数のカテゴリ(「ヨット」や「ライオン」、「エッフェル塔」など)に各画像を素早く分類する機能や、画像内の個々の物体や人の顔を検出する機能、画像内に含まれているテキストを検出して読み取る機能を備えています。また、画像カタログのメタデータ作成、不適切なコンテンツの管理、画像の感情分析を通じた新しいマーケティング手法の導入が可能になります。
(引用元: Cloud Vision API )
今回は「膨大なカテゴリ(中略)に各画像を素早く分類する機能」、「個々の物体や人の顔を検出する機能」、そして「画像内に含まれているテキストを検出して読み取る機能」を試しに使ってみます。
このAPIへリクエストを送る際は、JSON形式のリクエストを送ることになります。以下にリクエストの例を記します。
{
"requests": [
{
"image": {
"content": "base-64にエンコードされた画像ファイル"
},
"features": [
{
"type": "TEXT_DETECTION"
},
{
"type": "FACE_DETECTION"
}
]
}
]
}
"image"の中に画像ファイルを、"features"の中に呼び出したい機能を記述していきます。各項目の詳細な説明は、公式サイトのサンプルを参考にしてください。
レスポンス内容もJSON形式で返ってきますが、その一例を以下に記します(公式サイトからとってきました)。
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/0bt9lr",
"description": "dog",
"score": 0.97346616
},
{
"mid": "/m/09686",
"description": "vertebrate",
"score": 0.85700572
},
{
"mid": "/m/01pm38",
"description": "clumber spaniel",
"score": 0.84881884
},
{
"mid": "/m/04rky",
"description": "mammal",
"score": 0.847575
},
{
"mid": "/m/02wbgd",
"description": "english cocker spaniel",
"score": 0.75829375
}
]
}
]
}
この例では犬の画像をリクエストで送りラベル検出機能を呼び出した際の返答例となりますが、"labelAnnotations"内の各項目の"description"の値は、確かに犬関連の文字となっていることが見て取れると思います。
キーの取得
キーの取得にはGoogleアカウントを持っていることが前提となります。Google Cloud Platformのダッシュボードにアクセスし、ご自身のGoogleアカウントでログインをします。以下の画像で赤線に囲われている検索ボックスで「Cloud Vision API」と検索した後は、基本的に道なりに進んでキーが取得できると思います。
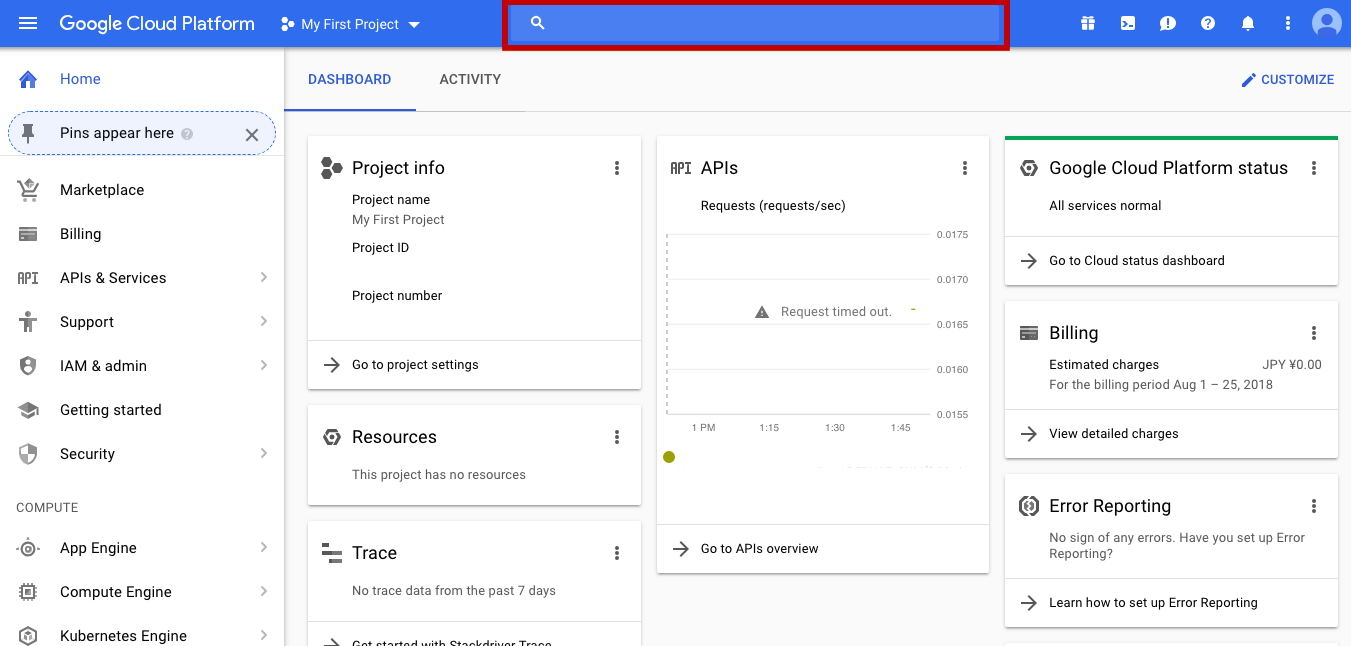
もし万が一つまずいた場合、以下のWebサイトが助けになると思います。
まずはHTMLでページ作成
キーの取得ができたところで、コードを書き始めたいと思います。今回は簡単なWebページを作るため、APIを呼び出す部分を実装する前に、HTMLとCSSでページのレイアウトを作成したいと思います。
初期状態のページの画面を、以下の通りとします。
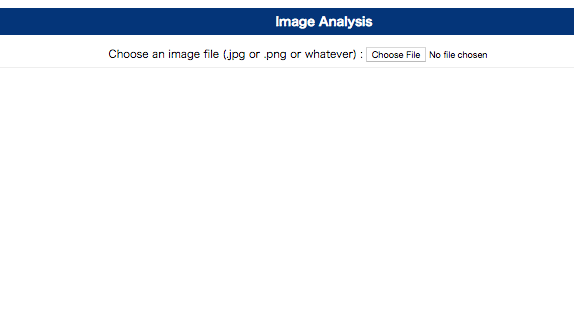
「Choose File」ボタンを押下して画像がアップロードされた場合は、以下の画面を表示するようにします。
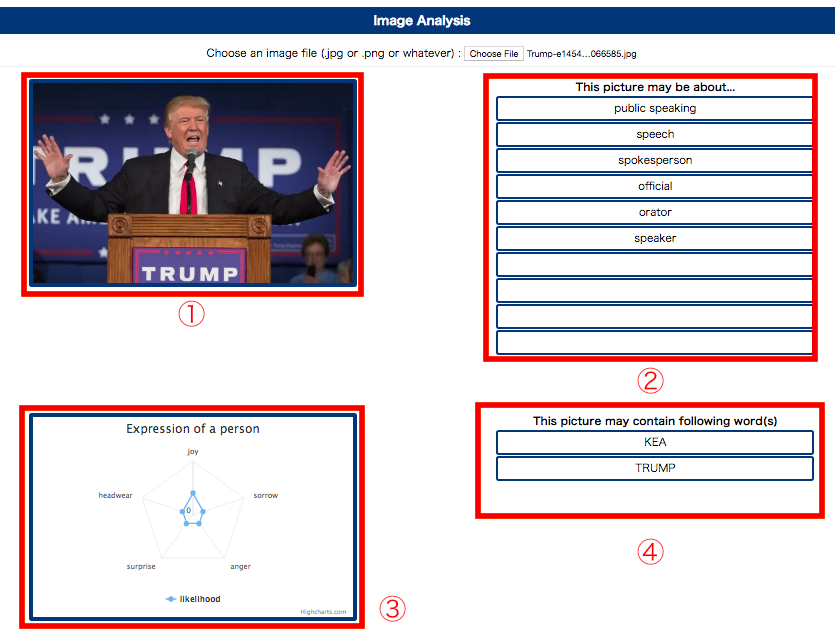
上の画像内の各要素について説明します。
- ユーザがアップロードした画像
- 画像のラベル検出
- 画像内の人物の表情分析
- 画像内のテキストの解読
以下がhtmlファイルとcssファイルになります。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<title>Image Analysis</title>
<link rel="stylesheet" type="text/css" href="CloudVision.css">
</head>
<body>
<h3 id='title'>Image Analysis</h3>
<!--- 画像をアップロードさせるためのボタンのあるエリア --->
<div id="uploadArea"><l>Choose an image file (.jpg or .png or whatever) : </l><input type="file" id="uploader"></div>
<hr>
<!--- Google Cloud Vision APIに画像ファイルを送り、得られた結果を表示するエリア --->
<!--- 初期状態ではクラス"hidden"を付与し、CSSでhiddenクラスは表示されないよう記述します --->
<div class="resultArea hidden">
<!--- アップロードされた画像を表示 --->
<div id="showPic"></div>
<!--- ラベル検出の結果を表示 --->
<table id="resultTable">
<thead><tr><td><b>This picture may be about...</b></td></tr></thead>
<tbody id="resultBox"></tbody>
</table>
</div>
<div class="resultArea hidden">
<!--- 人物の表情に関する結果をレーダーチャートで表示 --->
<div id="chartArea"></div>
<!--- テキスト解読の結果を表示 --->
<table id="textTable">
<thead><tr><td><b>This picture may contain following word(s)</b></td></tr></thead>
<tbody id="textBox"></tbody>
</table>
</div>
<script src="http://code.jquery.com/jquery-1.10.1.min.js"></script>
<!--- 表情分析の結果をレーダーチャートで表すために以下の二つを用います --->
<script src="http://code.highcharts.com/highcharts.js"></script>
<script src="http://code.highcharts.com/highcharts-more.js"></script>
<script type="text/javascript" src=“CloudVision.js"></script>
</body>
</html>
body{
text-align: center;
}
/* ユーザのアップロードした画像に関する記述 */
img{
max-height:300px;
max-width:480px;
height:auto;
width:auto;
}
.resultTableContent{
height:30px;
border: 3px solid #003A76;
border-radius: 4px;
}
# title{
height: 40px;
text-align: center;
background-color: #003A76;
font-weight: bold;
font-size: 18px;
color: white;
line-height: 40px;
}
.resultArea{
width:1200px;
height:500px;
margin:0px auto;
text-align: center;
}
# showPic{
border: 6px solid #003A76;
border-radius: 4px;
width:40%;
height:300px;
margin: 10px;
float:left;
}
# resultTable{
width:40%;
float:right;
margin: 10px;
}
# chartArea{
border: 6px solid #003A76;
border-radius: 4px;
width:40%;
height:300px;
margin: 10px;
float:left;
}
# textTable{
width:40%;
float:right;
margin: 10px;
}
/* 初期状態では結果部分が表示されないようにするための記述 */
.hidden{
display: none;
}
JavaScriptでAPIを呼び出し
画面の表示ができたところで、JavaScriptのコードを書いていきます。一旦コードの全体像をお見せしてから、細部の説明をしていきます。
//section 1
//APIを利用する際のURLになります
var KEY = 'あなたのGoogle Cloud Vision APIのキーをここに書いてください'
var url = 'https://vision.googleapis.com/v1/images:annotate?key='
var api_url = url + KEY
//section 2
//ページを読み込む際に動的にラベル検出結果表示用のテーブルを作成
$(function(){
for (var i =0; i < 10; i++){
$("#resultBox").append("<tr><td class='resultTableContent'></td></tr>")
}
})
//section 3
//画面の表示内容をクリアする処理
function clear(){
if($("#textBox tr").length){
$("#textBox tr").remove();
}
if($("#chartArea div").length){
$("#chartArea div").remove();
}
$("#resultBox tr td").text("")
}
//section 4
//画像がアップロードされた時点で呼び出される処理
$("#uploader").change(function(evt){
getImageInfo(evt);
clear();
$(".resultArea").removeClass("hidden")
})
//section 5
//画像ファイルを読み込み、APIを利用するためのURLを組み立てる
function getImageInfo(evt){
var file = evt.target.files;
var reader = new FileReader();
var dataUrl = "";
reader.readAsDataURL(file[0]);
reader.onload = function(){
dataUrl = reader.result;
$("#showPic").html("<img src='" + dataUrl + "'>");
makeRequest(dataUrl,getAPIInfo);
}
}
//section 6
//APIへのリクエストに組み込むJsonの組み立て
function makeRequest(dataUrl,callback){
var end = dataUrl.indexOf(",")
var request = "{'requests': [{'image': {'content': '" + dataUrl.slice(end + 1) + "'},'features': [{'type': 'LABEL_DETECTION','maxResults': 10,},{'type': 'FACE_DETECTION',},{'type':'TEXT_DETECTION','maxResults': 20,}]}]}"
callback(request)
}
//section 7
//通信を行う
function getAPIInfo(request){
$.ajax({
url : api_url,
type : 'POST',
async : true,
cashe : false,
data: request,
dataType : 'json',
contentType: 'application/json',
}).done(function(result){
showResult(result);
}).fail(function(result){
alert('failed to load the info');
});
}
//section 8
//得られた結果を画面に表示する
function showResult(result){
//ラベル検出結果の表示
for (var i = 0; i < result.responses[0].labelAnnotations.length;i++){
$("#resultBox tr:eq(" + i + ") td").text(result.responses[0].labelAnnotations[i].description)
}
//表情分析の結果の表示
if(result.responses[0].faceAnnotations){
//この変数に、表情のlikelihoodの値を配列として保持する
var facialExpression = [];
facialExpression.push(result.responses[0].faceAnnotations[0].joyLikelihood);
facialExpression.push(result.responses[0].faceAnnotations[0].sorrowLikelihood);
facialExpression.push(result.responses[0].faceAnnotations[0].angerLikelihood);
facialExpression.push(result.responses[0].faceAnnotations[0].surpriseLikelihood);
facialExpression.push(result.responses[0].faceAnnotations[0].headwearLikelihood);
for (var k = 0; k < facialExpression.length; k++){
if (facialExpression[k] == 'UNKNOWN'){
facialExpression[k] = 0;
}else if (facialExpression[k] == 'VERY_UNLIKELY'){
facialExpression[k] = 2;
}else if (facialExpression[k] == 'UNLIKELY'){
facialExpression[k] = 4;
}else if (facialExpression[k] == 'POSSIBLE'){
facialExpression[k] = 6;
}else if (facialExpression[k] == 'LIKELY'){
facialExpression[k] = 8;
}else if (facialExpression[k] == 'VERY_LIKELY'){
facialExpression[k] = 10;
}
}
//チャート描画の処理
$("#chartArea").highcharts({
chart: {
polar: true,
type: 'line'
},
title: {
text: 'Expression of a person',
},
pane: {
size: '80%'
},
xAxis: {
categories: ['joy', 'sorrow', 'anger', 'surprise','headwear'],
tickmarkPlacement: 'on',
lineWidth: 0
},
yAxis: {
gridLineInterpolation: 'polygon',
lineWidth: 0,
max:10,
min: 0
},
tooltip: {
shared: true,
pointFormat: '<span style="color:{series.color}">{series.name}: <b>{point.y:,.0f}</b><br/>'
},
series: [{
name: 'likelihood',
data: facialExpression,
pointPlacement: 'on'
}]
})
}else{
//表情に関する結果が得られなかった場合、表示欄にはその旨を記す文字列を表示
$("#chartArea").append("<div><b>No person can be found in the picture</b></div>");
}
//テキスト解読の結果を表示
if(result.responses[0].textAnnotations){
for (var j = 1; j < result.responses[0].textAnnotations.length; j++){
if(j < 16){
$("#textBox").append("<tr><td class='resultTableContent'>" + result.responses[0].textAnnotations[j].description + "</td></tr>")
}
}
}else{
//テキストに関する結果が得られなかった場合、表示欄にはその旨を記す文字列を表示
$("#textBox").append("<tr><td class='resultTableContent'><b>No text can be found in the picture</b></td></tr>")
}
}
以下に、各セクションの詳細について記します。
section 1
APIを利用するためのURLを組み立てる処理を行います。
//APIを利用する際のURLになります
var KEY = 'あなたのGoogle Cloud Vision APIのキーをここに書いてください'
var url = 'https://vision.googleapis.com/v1/images:annotate?key='
var api_url = url + KEY
APIを利用する際のキーは、パラメータとしてURLの中に組み込まれます。
section 2
ページの読み込みと同時に実行される処理です。
//ページを読み込む際に動的にラベル検出結果表示用のテーブルを作成
$(function(){
for (var i =0; i < 10; i++){
$("#resultBox").append("<tr><td class='resultTableContent'></td></tr>")
}
})
HTMLでテーブルを表示するための記述をするのが面倒だったので、JavaScriptで動的に作成するようにしました。
section 3
次のセクションで呼び出されることになる、画面の表示内容をクリアするための処理です。
//画面の表示内容をクリアする処理
function clear(){
if($("#textBox tr").length){
$("#textBox tr").remove();
}
if($("#chartArea div").length){
$("#chartArea div").remove();
}
$("#resultBox tr td").text("")
}
if($("#textBox tr").length)では、ラベル検出の結果表示欄にtr要素が一つでも存在すればそれらが削除されます。
同様にif($("#chartArea div").length)は表情分析の結果のチャートもしくは文字列が存在すればそれが削除されます。
そして$("#resultBox tr td")においては、td要素自体を消さずに、表示されている文字列を空白に置き換えます。
section 4
$("#uploader")とは、画像をアップロードするためのボタンを指すため、以下は画像がアップロードされた際に呼び出される処理になります。
//画像がアップロードされた時点で呼び出される処理
$("#uploader").change(function(evt){
getImageInfo(evt);
clear();
$(".resultArea").removeClass("hidden")
})
後述するgetImageInfo関数(引数はアップロードされた画像ファイル)及び先述したclear関数を呼び出し、そして結果表示エリアからクラス"hidden"を取り去り、表示するようにします。
section 5
section 4で説明した処理から、画像ファイルの情報を引数として呼び出される処理です。
//画像ファイルを読み込み、APIを利用するためのURLを組み立てる
function getImageInfo(evt){
//アップロードされた画像をFileListオブジェクトとして読み込む
var file = evt.target.files;
var reader = new FileReader();
//読み込んだ結果を保持する変数
var dataUrl = "";
reader.readAsDataURL(file[0]);
//読み込みが終わったら、次の処理を呼び出す
reader.onload = function(){
dataUrl = reader.result;
$("#showPic").html("<img src='" + dataUrl + "'>");
makeRequest(dataUrl,getAPIInfo);
}
}
FileReaderオブジェクトのインスタンスを用いて、画像ファイルの情報を読み込みます。変数fileはFileList型となっており、アップロードしされた画像を取得するには変数fileの0番目の要素を取得するよう記述します(reader.readAsDataURL(file[0]))。これらの処理が終わったら、section 6で説明する関数に、画像ファイルの情報と、callback関数として呼び出されるgetAPIInfo関数(section 7で説明)を引数として渡して、呼び出します。
section 6
以下がJSON形式のリクエストを組み立てるコードになります。
//APIへのリクエストに組み込むJsonの組み立て
function makeRequest(dataUrl,callback){
var end = dataUrl.indexOf(",")
var request = "{'requests': [{'image': {'content': '" + dataUrl.slice(end + 1) + "'},'features': [{'type': 'LABEL_DETECTION','maxResults': 10,},{'type': 'FACE_DETECTION',},{'type':'TEXT_DETECTION','maxResults': 20,}]}]}"
callback(request)
}
読み込んだファイル情報そのままにはdata:image/jpeg;base64,が先頭についてしまうので、それを取り除く処理をしてから、引数として渡されたcallback関数を呼び出しています。
section 7
Ajax通信を行い、APIにリクエストを投げます。
//通信を行う
function getAPIInfo(request){
$.ajax({
url : api_url,
type : 'POST',
async : true,
cashe : false,
data: request,
dataType : 'json',
contentType: 'application/json',
}).done(function(result){
showResult(result);
}).fail(function(result){
alert('failed to load the info');
});
}
通信に成功した場合は、得られた結果を引数としてshowResult関数を呼び出します。
section 8
section 7の処理の結果を引数として受け取り、呼び出されます。得られた結果を①表形式と、②レーダーチャート形式で表示する処理を行います。ラベル検出とテキスト解読は①表形式で、表情分析は②レーダーチャート形式で表示します。
//得られた結果を画面に表示する
function showResult(result){
//ラベル検出結果の表示
for (var i = 0; i < result.responses[0].labelAnnotations.length;i++){
$("#resultBox tr:eq(" + i + ") td").text(result.responses[0].labelAnnotations[i].description)
}
//表情分析の結果の表示
if(result.responses[0].faceAnnotations){
//この変数に、表情のlikelihoodの値を配列として保持する
var facialExpression = [];
facialExpression.push(result.responses[0].faceAnnotations[0].joyLikelihood);
facialExpression.push(result.responses[0].faceAnnotations[0].sorrowLikelihood);
facialExpression.push(result.responses[0].faceAnnotations[0].angerLikelihood);
facialExpression.push(result.responses[0].faceAnnotations[0].surpriseLikelihood);
facialExpression.push(result.responses[0].faceAnnotations[0].headwearLikelihood);
for (var k = 0; k < facialExpression.length; k++){
if (facialExpression[k] == 'UNKNOWN'){
facialExpression[k] = 0;
}else if (facialExpression[k] == 'VERY_UNLIKELY'){
facialExpression[k] = 2;
}else if (facialExpression[k] == 'UNLIKELY'){
facialExpression[k] = 4;
}else if (facialExpression[k] == 'POSSIBLE'){
facialExpression[k] = 6;
}else if (facialExpression[k] == 'LIKELY'){
facialExpression[k] = 8;
}else if (facialExpression[k] == 'VERY_LIKELY'){
facialExpression[k] = 10;
}
}
//チャート描画の処理
$("#chartArea").highcharts({
chart: {
polar: true,
type: 'line'
},
title: {
text: 'Expression of a person',
},
pane: {
size: '80%'
},
xAxis: {
categories: ['joy', 'sorrow', 'anger', 'surprise','headwear'],
tickmarkPlacement: 'on',
lineWidth: 0
},
yAxis: {
gridLineInterpolation: 'polygon',
lineWidth: 0,
max:10,
min: 0
},
tooltip: {
shared: true,
pointFormat: '<span style="color:{series.color}">{series.name}: <b>{point.y:,.0f}</b><br/>'
},
series: [{
name: 'likelihood',
data: facialExpression,
pointPlacement: 'on'
}]
})
}else{
//表情に関する結果が得られなかった場合、表示欄にはその旨を記す文字列を表示
$("#chartArea").append("<div><b>No person can be found in the picture</b></div>");
}
//テキスト解読の結果を表示
if(result.responses[0].textAnnotations){
for (var j = 1; j < result.responses[0].textAnnotations.length; j++){
if(j < 16){
$("#textBox").append("<tr><td class='resultTableContent'>" + result.responses[0].textAnnotations[j].description + "</td></tr>")
}
}
}else{
//テキストに関する結果が得られなかった場合、表示欄にはその旨を記す文字列を表示
$("#textBox").append("<tr><td class='resultTableContent'><b>No text can be found in the picture</b></td></tr>")
}
}
チャートに関しては、Highchartsを用いています。細かな仕様については公式サイトをご覧になってください。今回はレーダーチャートの機能を用いています。APIから返ってくるテキストデータ(e.g. "VERY_UNLIKELY")を数値に置き換え、それらを配列型の変数に入れ、それをチャートに表示しています。
使ってみる
コードが書き終わったところで、試しに使ってみます。文字列と人間の顔両方が写っている写真がいいでしょう。
Donald TrumpのTwitterからとってきた、以下の画像で試してみます。
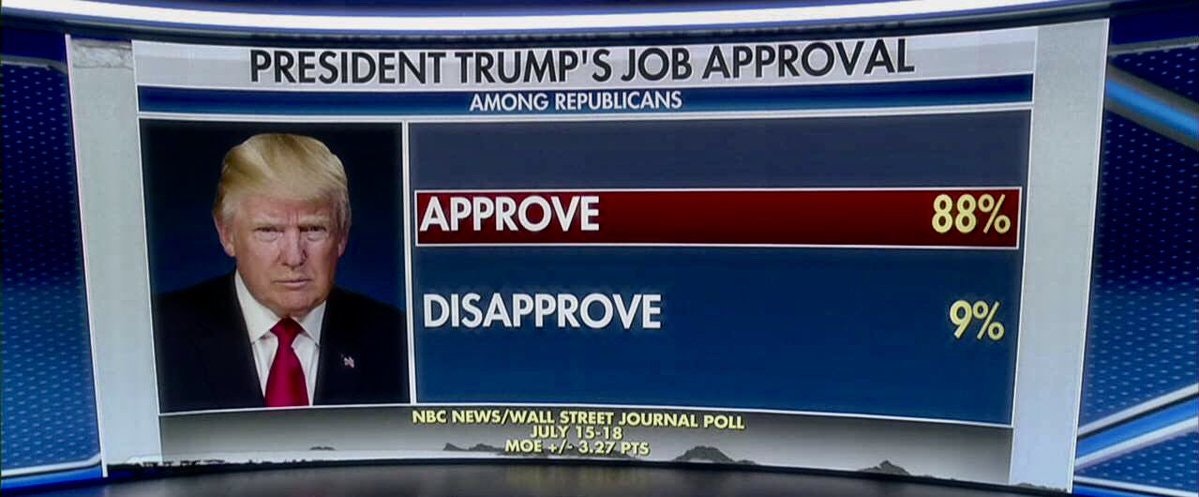
実行結果は以下の通りです。
ラベル検出:

spokespersonやnewsといった間違っていない情報もありますが、vehicle registration plateのような明らかな誤りも含まれています。
表情分析:

sorrowなのか微妙ですが、あながち間違っていない気もします。
テキスト検出:

ちゃんと読み取れています。ちなみに、日本語の解読もできます。ぜひ試してみてください。