はじめに
AWSのシステムのログを集めるのには、CloudWatchを使うのが便利です。私は仕事では、EC2インスタンスにCloudWatch Agentをインストールして、各種アプリケーション(NginxとかTomcatとか)のアクセスログやエラーログとかを、CloudWatch Logsに流すようにしています。
しかし、CloudWatch Logsにログを保管するのは料金が結構かかるので、定期的に古いログはS3に移したいです。そこでこの記事で、CloudWatchのログをLambdaを使って定期的にS3に移動させる方法をまとめておきます。
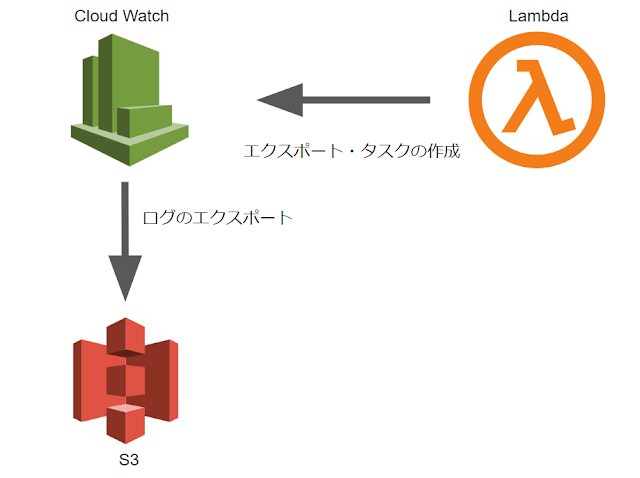
各種設定
Lambdaの設定
まずは、移動処理をするコードをデプロイするLambdaに適切な権限をつけます。以下のような権限を設定したIAM Roleを、Lambdaに設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "cloudwatch:*",
"Resource": "*"
},
{
"Action": [
"s3:Get*",
"s3:Put*",
"s3:List*",
],
"Resource": [
"*"
],
"Effect": "Allow"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:CreateExportTask",
"logs:DescribeLogGroups",
"logs:Get*"
],
"Resource": "*"
}
]
}
S3に読み込みと書き込みをする権限を、CloudWatchのログを読み込む権限とタスクを作成する権限を、つけておきます。
Lambdaにデプロイするコード(Python)
Pythonでコードを書くと、以下のような感じになります。標準ライブラリ以外では、boto3を使用しているので、デプロイする際は以下のコードと一緒にzipファイルにまとめてアップロードします。
import boto3
import datetime
import time
# ロググループを検索する際のクエリ―
PREFIX = 'test-'
# ログを保管するs3バケット
S3_BUCKET = 'test_bucket'
# ログを保管するs3のディレクトリ
S3_DIR = 'logs'
def main(event,context):
'''
メインで呼び出される関数
'''
# boto3のクライアント
client = boto3.client('logs')
# ロググループのリストを取得
log_groups = get_log_group_list(client)
# ログ内容をs3に保管
move_logs(client,log_groups)
def get_log_group_list(client):
'''
ロググループの情報のリストを取得
'''
should_continue = True
next_token = None
log_groups=[]
# 一度で全て取り切れない場合もあるので、繰り返し取得する
while should_continue:
if next_token == None:
# 初回のリクエストの場合
response = client.describe_log_groups(
logGroupNamePrefix=PREFIX,
limit=50
)
else:
# 二回目以降のリクエストの場合
response = client.describe_log_groups(
logGroupNamePrefix=PREFIX,
limit=50,
nextToken=next_token
)
# 取得した結果を、リストに追加
for log in response['logGroups']:
log_groups.append(log)
# またリクエストを投げるべきかどうかを判定
if 'nextToken' in response.keys():
next_token = response['nextToken']
else:
should_continue = False
return log_groups
def create_export_task(client,log_groups):
'''
ログ内容をs3に移動
'''
# 現在時刻を取得し、UNIX timeに変換
time_now = datetime.datetime.now()
unix_time_now = int(time_now.timestamp())
# ロググループの数だけ繰り返し
for log in log_groups:
for x in range(20):
try:
response = client.create_export_task(
fromTime=0,
to=unix_time_now,
logGroupName=log['logGroupName'],
destination=S3_BUCKET,
destinationPrefix=S3_DIR
)
except:
# 既にタスクがある場合は、ちょっと待ってから再実行
time.sleep(20)
continue
上の方で定義している変数PREFIXには、ログを移行したいロググループの先頭の文字列を指定します。ここでは"test-"で始まるロググループのログをS3に移すように設定しています。
main()関数が、実行時に呼び出されます。この関数は、以下の二つの関数を順番に呼び出します。
- **get_log_group_list()**関数で、内容をS3に移管したいロググループの情報を取得し、配列に格納します。注意したいのは、boto3の仕様上ロググループは一度に最大50個までしか取得できないことです。そのためここでは、一度にすべてのロググループ情報を取得できない場合は再度リクエストを投げるようにしています。
- **create_export_task()**関数では、実際にログ移動のタスクを作成のリクエストを投げています。注意したいのは、タスクは同時に二つ以上作成できないということです。そのためリクエストを連続して送るとboto3のExceptionが発生してしまうため、それをキャッチして数十秒後に再度リクエストを投げ直しています。
S3の設定
最後に、ログをエクスポートしたいS3のバケットの設定を行います。以下のjsonをポリシーとして設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "logs.ap-northeast-1.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "*"
},
{
"Effect": "Allow",
"Principal": {
"Service": "logs.ap-northeast-1.amazonaws.com"
},
"Action": "s3:GetBucketAcl",
"Resource": "*"
}
]
}
これを指定し忘れると、**"An error occurred (InvalidParameterException) when calling the CreateExportTask operation: GetBucketAcl call on the given bucket failed. Please check if CloudWatch Logs has been granted permission to perform this operation."**というエラーが、Lambdaの関数実行時に発生してしまいます。エラーメッセージ的には、CloudWatch Logsの設定の問題であるかのようなミスリーディングなものになっているので、戸惑いました。
最後に
CloudWatchのcronを用いて、作成したLambda関数を定期的に実行するように設定すれば、例えば毎日CloudWatchのログをS3に移動させることとかもできます。
ただし、一点注意があります。ログエクスポートのタスクは時間がかかるため、10個以上のロググループを一気にエクスポートしようとすると、Lambdaの最大の実行時間である15分を超えた処理時間がかかってしまうということです。不便です。
一気に大量のログをs3に移動させるなら、Lambdaを使うのではなくEC2の中でcronのジョブとして実行するのがいいのかもしれません。