概要
この記事は以下のサイトのPDFの個人的な翻訳となります。
雑感
Hyperledger Fabricはざっくり言うと、トランザクションを投げたい人がPeerにトランザクションを発行していいか署名を集め、一定条件を満たした段階でOrdererに集めた署名付きでトランザクションを投げると、Ordererがブロックを生成してくれる、という流れになっています。
ある種、PBFTにおける合意投票フェーズを先にやるようなイメージですね。(暴論)
だいたいのPBFT実装でそうであったように、合意を形成するための投票フェーズは往々にして性能上のボトルネックになりえます。実際に、一部のブロックチェーンプロダクトでは、投票フェーズに参加できるノードを別の合意形成アルゴリズムで絞って応答を早くするような試みが行われています。
ましてやブロック単位ではなく、トランザクション単位で投票(に近い)ことをやれば、中央集権、閉鎖NWを前提とするFabricでも、そこがボトルネックになるのはある種必然ではあります。この傾向はPeerがネットワーク的に離れる(コンソーシアムモデルなど)につれて、さらに顕著になるはずです。
また、「同一変数(ワールドステート)の更新は同一ブロック内で共存できない(=トランザクションが失敗扱いになる)」というFabricの仕様からすると、以下に変数への更新をかぶらせないようにOrdererにクエリを投げるかはアプリ開発者を悩ませる問題でもありました。
Nexledger AcceleratorはOrdererへ投げるトランザクションをいったんプールし、効率的にトランザクションを投げる(数を減らす、順番を制御する)ことで効率化を図るタイプのプロダクトです。性質上、ワールドステートへの書き込みがKV的に分散しやすいようなOLTP型のトランザクションでより有効に働いてくるものと思われます。(実際、ホワイトペーパーでも効果のあるもの、ないものの例示にあげられている)
細かいトランザクションがバラバラ来ることで性能が落ちるならある程度まとめればいいじゃん、という思想はGoogle APIなんかでも行われていますし、ある種セオリー通りの対処を行っているような認識です。
以下、翻訳。
和訳
EXECUTIVE SUMMARY
AcceleratorはSamsung SDSによって開発されたソフトウェアコンポーネントで、トランザクションのスループットに関してブロックチェーンネットワークのパフォーマンスを向上させるように設計されています。 マルチレベルキュースケジューリング[1]にヒントを得たAcceleratorは、ブロックチェーンネットワークがアプリケーションからの大量のトランザクション要求を処理できるようにします。 Samsung SDSとIBMは、Hyperledger FabricネットワークへのAcceleratorの適用性を検証し、AcceleratorをHyperledger Fabricオープンソースプロジェクトに統合するためのロードマップを定義しました。 チームは、IBMクラウドのベアメタルシステムで実行されているHyperledger CaliperとFabricに関するテストハーネスを定義しました。
当社の努力の結果、レイテンシへの影響を最小限に抑えながらトランザクションのスループットが大幅に向上したことを示す、消耗品および再現性のある結果をHyperledger Fabricコミュニティに公開することができます。 結果は最大10倍の性能向上を示しています。 この最初のドラフトは、AcceleratorのソースコードとCaliperベンチマークの公開前に達成された結果に焦点を当てています。 これらの成果物は、アクセラレータ機能をHyperledger Fabricオープンソースプロジェクトに組み込むためのHyperledger Fabricコミュニティでのサポートを構築するために、2019年初頭に公開される予定です。
THE CHALLENGE
ブロックチェーンソリューションの実装者にとっての一貫した課題は、ブロックチェーンテクノロジが現在提供している比較的低いトランザクションレートです。 例えば、ビットコインネットワークは毎秒7トランザクション(TPS)のレートを達成すると推定される。 ブロックチェーンのユースケースの種類が増えるにつれて、TPSの向上によるパフォーマンスの向上の必要性はますます高まっています。 より具体的には、リアルタイムで毎秒数千を超えるトランザクションの処理を必要とするブロックチェーンのユースケースがあります。
事例の例としては、多数のセンサーからのデータの処理やID /認証サービスのプロビジョニングなどがあります。
Hyperledger Fabricなどのエンタープライズブロックチェーンテクノロジは、パブリックブロックチェーンの実装よりもはるかに高いレートを達成できることが証明されていますが、実際の使用例からさらに高いレベルのパフォーマンスを達成するというプレッシャーは一定です。 このホワイトペーパーでは、Hyperledger Fabricの実装を変更することなく、許可されたブロックチェーンネットワークのトランザクションスループットを大幅に向上させる方法について説明します。 適用可能な実装パターンと禁忌のユースケースについても説明します。
ACCELERATOR APPROACH
コンセンサスとは、ノードのネットワークがトランザクションの保証された順序付けを行い、トランザクションのブロックを検証するプロセスのことです[2]。 ブロックチェーンプレイヤーに信頼を提供することは、ブロックチェーンシステムにおける無条件のプロセスであり、一般に、署名、交換、注文、トランザクションの検証などで構成されています。 [3]そしてトランザクションやブロックの検証のようなプロセスのいくつかは連続して実行されるべきです[4]、そのようなシステムではパフォーマンスのボトルネックがある可能性があります。 したがって、一般的にブロックチェーンのトランザクションスループットはレガシーシステムのそれよりも低いと考えられています。なぜなら、それらはトランザクション決済にコンセンサスを一般的に使用しないからです。
Acceleratorの重要な概念は、互いに相関のないいくつかのトランザクションを収集することから始まります。無相関とは、ここでは、元帳更新のために同じキーまたはアドレスにアクセスしないトランザクションを意味します。これは、合意フェーズの間に[5]で説明されている元帳マルチバージョン同時実行制御(MVCC)衝突を起こしそうにないということです。次のステップは、グループ化されたトランザクションを個別にではなく一緒に承認することです。トランザクションは互いのコミットメント結果に影響を与えないため、これは実行可能なソリューションです。これを達成するための最も簡単な方法は、相関のないトランザクションを新しいトランザクションに結合し、新しいトランザクションを合意のためにブロックチェーンネットワークに送信することです。このアプローチでは、単一の合意フェーズでより多くのトランザクションを処理することができ、その結果、読み取りと書き込みの両方のトランザクションスループット、つまりRPS(Reads Per Seconds)とTPS(Transactions Per Seconds)のそれぞれのパフォーマンスが向上します。[6]。
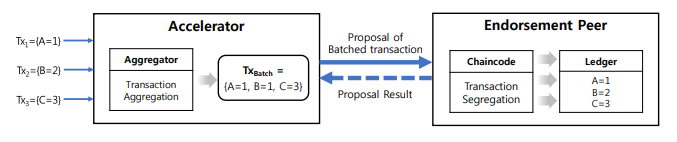 !
!
図1は、上述したトランザクション加速のシナリオ例を示している。 Tx1、Tx2、およびTx3という名前の3つのトランザクションがあり、それぞれ個別に異なるキーA、B、およびCを使用して元帳状態を更新しようとします。これらのトランザクションは異なるキーで値を更新しようとするため相関しません。 検証中に衝突が予想されます。
Acceleratorは、指定された期間、たとえば1秒間にこれらのトランザクションを受信すると、A、B、およびCを含む新しいトランザクションを作成します。その後、推奨のためにトランザクション提案をブロックチェーンピアに送信します。 保証ピアでは、バッチ処理されたトランザクションの元のトランザクションがトランザクションシミュレーションのために分離され[5]、提案された結果がアクセラレータに返されます。
Accelerator機能は、クライアントアプリケーションまたはAPIゲートウェイサーバーなどのサーバーのどちらにも実装できます。これらは、ユーザーがネットワークをブロックチェーン化するための便利な接続方法を提供するために使用されます。 サーバー側の高速化は、サーバー側の高速化と呼ばれ、高速化のために多くのクライアントからのトランザクションを利用できるため、スループットの向上に有利です。 一方、クライアント側の高速化は、ブロックチェーンネットワーク内にこのようなプロキシやゲートウェイサーバーが存在しない場合に役立ちます。 代わりに、クライアントアプリケーションではアクセラレーション機能の追加の実装が必要です。
IMPLEMENTATION
現在の形では、Acceleratorはサーバーサイドアクセラレーション用のスタンドアロンサーバーとして存在します。 図2に示すように、ブロックチェーンアプリケーションとHyperledger Fabricネットワークの間に挿入されます。アクセラレータは、Goプログラミング言語で書かれ、Hyperledger Fabric Go SDKを使用するClassifier、Aggregator、およびRouterの3つの主要コンポーネントで構成されます。
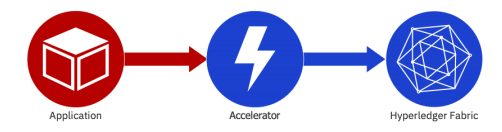
図2.アプリケーションとHyperleger Fabric間のスタンドアロンサーバーとしてのアクセラレータ
Components of Accelerator
Acceleratorの基本的なタスクは次のとおりです。
- チャネル、チェーンコード、および機能名の組み合わせによって決定される可能性がある宛先を使用して、受信したトランザクションを分類します。
- 分類された取引を新しいバッチ取引に集約する
- そして、一致したものを合意のためにブロックチェーンネットワークにルーティングします。
1. Classifier
アプリケーションによって要求されたすべてのトランザクションはClassifierに渡され、トランザクションタイプに従って分類されます。トランザクションタイプは現在、以下の要素の組み合わせによって定義されています。
- Channel name チャンネル名
- Chaincode name チェーンコード名
- Function name in the chaincode チェーンコード内の機能名
2. Aggregator
分類されたトランザクションを収集するために、トランザクションタイプごとに専用のキューが割り当てられます。 同じバッチ内の分類済みトランザクションは、それらをまとめて処理できるように、Aggregatorの同じキューに入れる必要があります。 アグリゲータは、次の条件に従って、バッチトランザクションを待機するかルーターに送信するかを決定します。
- Number of transactions トランザクション数
- Total size of transactions in bytes トランザクションの合計サイズ(バイト)
- Wait time of the first transaction 最初のトランザクションの待ち時間
- Occurrence of key duplication キー重複の発生
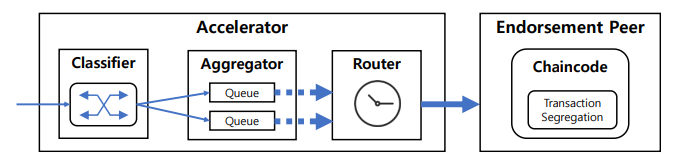
アグリゲーターは、通常ポリシーとして指定されている条件の組み合わせが満たされるとすぐに、キュー内のすべてのトランザクションで構成されるバッチトランザクションを作成します。 たとえば、収集用のトランザクション数を10、合計サイズを1 MB、待機時間を1秒としてポリシーを定義できます。 これらの条件のいずれかが満たされた場合、たとえば10個のトランザクションが最初に到着した場合、バッチトランザクションが生成され、ルータにフラッシュされます。
注目に値する条件は、キーの重複の発生をチェックすることです。これは、バッチトランザクションを無相関トランザクションのみで構成するために使用されます。 この機能の実装例の1つは、1)Aggregatorにトランザクションのキーのレコードを保持すること、および2)Aggregatorに新しい遷移が到着するたびにレコードにキーが存在することを確認することです。 重複が見つかった場合は、キュー内のトランザクションを使用して新しいバッチトランザクションが作成されます。 この場合、新しく到着したものは衝突を避けるためにバッチに含まれず、別のキューを占有します。 この条件チェックの前には、上記の3つの条件が必要です。
3. Router
ルーターは、アグリゲーターによって生成されたバッチトランザクションをHyperledger Fabric SDKを介してendorsementピアノードに送信します。 次に、ピアはバッチトランザクション内の各トランザクションに対して検証プロセスを実行します。 したがって、与えられたバッチトランザクションを個々の単一トランザクションに分離するチェーンコードは、endorsementピアに補足的にインストールされるべきです。 最後に、Routerはバッチトランザクションに含まれる個々のトランザクションを要求する各アプリケーションに結果を配信します。
EVALUATION
Software Test Configuration
次の図は、ユースケーステストの実行に使用されるソフトウェア構成を示しています。図4に示すように、IBM Cloudインフラストラクチャー上で実行されているテストの主要コンポーネントについて詳しく説明しています。
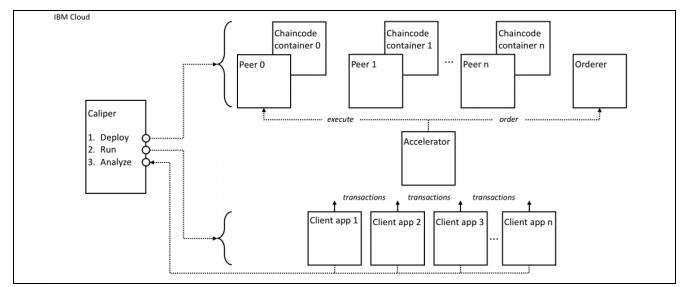
ソフトウェアテスト構成には、次のコンポーネントがあります。
-
Caliper: これは、テストのさまざまなコンポーネントのテストを展開し、テストを実行し、そして収集された結果を分析するために使用されるテストハーネステクノロジです。詳細については公式ウェブサイト[7]を参照してください。
-
Peer nodes: これらは、ブロックチェーンレジャーのコピーをホストするHyperledger Fabricノードです。可変数を設定できます。このペーパーの結果は3つのピアの設定のためです。ピアノードと注文者ノードは共同でブロックチェーンネットワークを形成します。
-
Ordering node: これは、順序付けされたトランザクションのブロックを作成し、それらを元帳内の異なるピアノードに配布するHyperledger Fabricコンポーネントです。ピアノードとOrdererは共同でブロックチェーンネットワークを形成します。
-
Client applications: これらはAcceleratorを介してネットワークにトランザクションを送信するアプリケーションです。クライアントアプリケーションは、通常のHyperledger Fabricネットワークとは異なり、ピアノードおよびOrdererと直接通信しません。それらはAcceleratorに接続します。
-
Accelerator: このコンポーネントは、クライアントアプリケーションと、ブロックチェーンネットワークを形成するピアノードおよびオーダーノードとの間のやり取りを仲介します。
This software configuration is running on IBM Cloud with the following resources allocated:
- 32GB of RAM
- 3.8 GHz quad core CPU
- 10 Gigabit network
- 960GB SSD
これらのリソースは、リアルタイムの需要に応じてテスト構成内のすべてのコンポーネントで利用可能です。 チェーンコードコンテナ、ピアノードとオーダーノード、クライアントアプリケーション、およびアクセラレータは、利用可能なネットワーク、ストレージ、およびCPUリソースを共有します。
Test Cases
この構成では、以下のユースケースが実行されます。
- Simple Query: 単一のピアで単純な元帳照会を測定するための技術的な使用例。
- Simple Open: 帳の単純な更新を測定するための技術的な使用例。
- Smallbank Query: 元帳の銀行口座に対するより「現実的な」クエリ。
- Smallbank Operations: 元帳に保持されている銀行口座へのより「現実的な」更新。
- Smallbank Clash: 銀行口座のより現実的な更新で、取引の再送信を必要とするさまざまな程度の口座の衝突があります。
Simple Queryでは、アプリケーションはAcceleratorを介してチェーンコードを呼び出します。Acceleratorは、一連の同時要求を単一のバッチ(ジョブと呼ばれる)にまとめます。 バッチがいっぱいになると(Aggregatorによると)、Acceleratorはジョブとともに変更されたチェーンコードを呼び出します。 チェーンコードの変更により、ジョブが個々の呼び出しにデブロックされ、その後通常の方法で実行されます。 Simple Queryでは、各呼び出しはgetState()APIを使用して単一の状態についてキーによって元帳を照会します。 集約された応答はアクセラレータに返され、アクセラレータはそれを解体してクエリの結果をアプリケーションに通知します。
Simple Openでは、処理はSimple Queryとして進行しますが、チェーンコードの呼び出しには、クエリではなく状態の変更が含まれます。 具体的には、チェーンコード呼び出しは、putState()APIを使用して新しい状態を作成することによって元帳を更新します。 集約された応答はAcceleratorに返され、そこでAcceleratorがトランザクションを作成し、それを順序付けし、コミットされたことを通知されるのを待ちます。 その後、トランザクションがコミットされた(または失敗した)ことを個々のアプリケーションに通知します。
Smallbankのユースケースは、Simpleのユースケースよりも現実的です。 彼らは、照会されているか、またはそれらの間で資金が移動している銀行口座の元帳をモデル化しようとします。 最も重要なのは、重複するトランザクションがほぼ同時に処理される場合にトランザクションの衝突が発生する可能性があることです。 処理はSimple Openとして進行しますが、チェーンコードの呼び出しはWorld Stateの衝突の影響を受けます。 具体的には、各チェーンコード呼び出しはgetState()およびputState()APIを使用して元帳を更新しますが、異なるトランザクションが同じ状態を更新する機会があります。 そのような衝突は、トランザクションが注文された後に無効なジョブトランザクションが検出され、その結果、ジョブ内のすべてのトランザクションが失敗することになります。
Detailed Result
図5のグラフは、シンプルクエリとシンプルオープンという2つの基本的なアクセラレータの使用例に対応しています。 どちらのユースケースでも、x軸の主導トランザクションレートがy軸の達成トランザクションレートにどのように影響するかを確認できます。 主導取引レートは変動し、達成された取引レートは従属変数です。 基本ケースでは、Acceleratorを使用しないと、1秒間に1,500トランザクション(TPS)まで直線的に増加します。 このレートを超えると、ドリブンレートがいくら増加しても、達成レートは向上しません。 この時点でシステムは効果的に飽和しています。
それまでの間、Acceleratorによる結果は大幅に改善されます。 最大1500 TPSのドリブントランザクションレートの場合、達成されたトランザクションレートは基本レートと同じ方法で増加することがわかります。 ただし、Acceleratorを使用すると、11,000の達成率までクエリトランザクションを直線的に駆動できます。 このレートを超えると、基本ケースと同様に、トランザクションがキューに入り始めます。 単純クエリでは、アクセラレータを使用すると約600%の改善が見られます。 Simple Openの場合、このユースケースにはより多くの作業が必要なため、達成されたレートはSimple Queryよりも低いことがわかります - トランザクションを実行し、整理して元帳に表示する前に検証する必要があります。 基本ケースでは、450 TPSまで直線的な増加が見られますが、この時点以降、システムが飽和状態になると、達成率は再び横ばいになります。
これもまた、Acceleratorによる結果は大幅に改善されています。 達成されたトランザクション率5,000 TPSまでほぼ直線的に成長していることがわかります。これは1,000%の改善に相当します。 これはクエリよりも優れています。 Acceleratorの使用は、照会スタイルのトランザクションよりも更新スタイルのトランザクションの方が有利です。
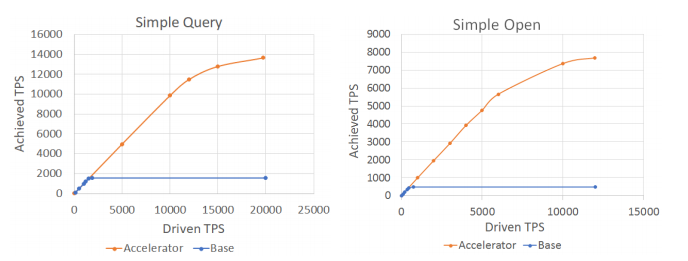
図5.単純なシナリオのパフォーマンスベンチマーク
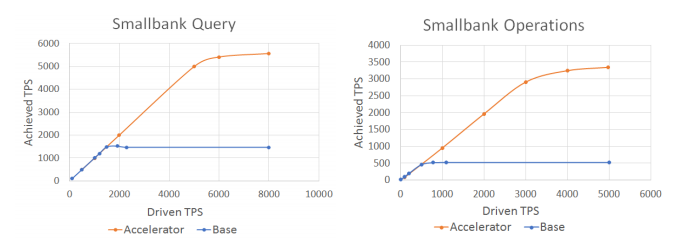
図6.衝突のないSmallbank Operationsのパフォーマンスベンチマーク
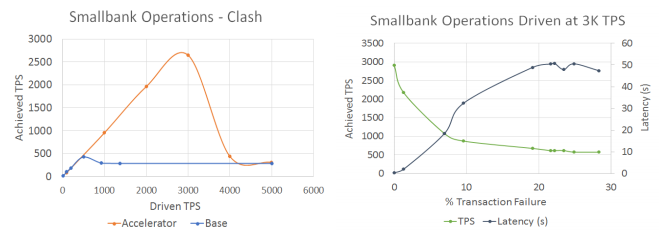
図7.衝突を伴うSmallbank Operationsのパフォーマンスベンチマーク
図7のグラフは、より現実的なバージョンのユースケース(SmallbankクエリとSmallbankオペレーション)に対応しています。 Smallbankのユースケースでは、Simpleのユースケースと非常によく似た動作が見られます。 Acceleratorは、これらのより現実的なユースケースのスループットに大きな違いをもたらします。改善率はそれぞれ300%と600%のオーダーです。アクセラレータを使用すると、クエリスタイルのトランザクションよりも更新スタイルのトランザクションの方が有利であることがわかりますが、どちらも大幅に改善されています。
しかし、Smallbankのユースケースとの最大の違いは、衝突が発生したときに明らかになります。以下のグラフは、衝突を含む実際のバージョンの元帳更新のユースケースに対応しています。最初のグラフはSmallbankの操作と同じですが、衝突が自然に発生しています。
最大約3,000 TPSまで、衝突はそれほど大きな速度では発生しません。そのため、達成されたトランザクションレートは、Smallbank Operationsと同じ軌跡をたどります。しかし、この速度を超えると、衝突が発生し始めます。増加し、したがってスループット率に影響を与えます。駆動速度が増加するにつれて、達成速度はアクセラレータなしの場合と同じになります。
要約すると、Smallbankの衝突のユースケースと上記の2つのグラフは、衝突率が約10%になるとAcceleratorの利点が失われることを示しています。 これは、Acceleratorが最適に機能するためには、トランザクションは互いに独立している必要があるという事実を補強します。
USE CASE RECOMMENDATION - SCENARIOS
Simple Example for IoT
IoTデバイスやセンサーアプリケーションは、Acceleratorに特に適した特性を示すアプリケーションの一種です。
すなわち、IoTアプリケーションは、(1)潜在的に極端に大量のトランザクションのために高いスループットを必要とし、(2)同時にトランザクションの独立性による加速に特に適している。IoTアプリケーションは、通常、各デバイスが独自の一意の識別子を持ち、各デバイスが定期的に時系列データまたは他のデバイスのデータと相関しないと思われる独立したセンサー測定値を定期的に生成するデータ特性そのため、通常、各トランザクションを別々の一意のキーに記録することができます。
これにより、相関データが発生する可能性が非常に低くなります(トランザクションがほぼ同じアドレスまたはキーでデータを更新しようとする場合など)。時間)。このような場合、Acceleratorはトランザクション間の衝突を予期せずに多数のトランザクションを集約できます。クライアント側のアクセラレーションスキームは、IoTアクセスポイントで使用されることがあります。
Simple Example for Financial Services
2番目のクラスのアプリケーションとして、トランザクションの相関と更新の競合が発生する可能性が高い金融サービスの分野から、サンプルのアプリケーションシナリオを選択しました。 このケースでは、多くの相関関係を持つ取引がある可能性がある、送金のための取引を個々の銀行口座所有者が送信しています。
可能であり、場合によっては、潜在的に多数のトランザクションが特定のアカウントに関連付けられる可能性があるため、ほぼ同時に同じキーを同時に更新しようとしているトランザクション更新の競合が発生する可能性が高くなります。 このような衝突状況は、これから説明するように、アクセラレータの適用が効率的でなくなる可能性があります。 しかしながら、より高い相関を有するトランザクションがほぼ同時に、すなわち同じブロック生成期間(例えば1秒)内に生成されない限り、それでもアクセラレータの利益を期待することができる。 サーバー側の高速化が適している可能性があります。 このカテゴリの最も実用的なシナリオでは、競合と同時更新が可能ですが、それらは一般的に長期間にわたって分散されるため、Acceleratorの使用は依然として非常に適しています。
Not applicable/Contraindicated use cases, in summary
Acceleratorは、多数の同時並行トランザクションが同じキーを使用してごく少数のアドレスを更新しようとしている場合にはあまり適していません。このような場合、同じキーの相互依存の同時更新が多数発生すると、潜在的に多数の更新の競合が発生し、その結果、Acceleratorのパフォーマンスが大幅に低下し、その使用が不適切になる可能性があります。
このようなシナリオには、多数のユーザーまたはブロックチェーンクライアントがごく少数のアドレスまたは同じキー値を使用してデータを更新したいというアプリケーションが含まれることがあります。例えば、シナリオは、多数の顧客のアカウントからの多数の同時要求を処理するための少数のパブリックアカウントでの金融データ交換(例えば、いくつかの証券取引シナリオ)を含むことができる(例えば、大量の証券取引を記録する必要がある)。
または少数の口座に関してネッティングまたは決済された場合)この場合、衝突を回避し続けるために、一度に集約されたトランザクション(つまり、「競合しない」トランザクション)の数は非常に少なくなります。これは、そのような場合には加速の増加が小さいかまったくないことを意味します。