Python ? 、R ?

決定木とは?
決定木は、教師あり学習の一つであり、分類モデルを作るために用いられる手法です。同じ分類モデルのサポートベクターマシーンやニューラルネットワークと比べて、説明変数がどのように影響しているのかがわかりやすいのが特徴です。
違いは、カテゴリー変数の扱いと分岐にあり!
Python(scikit-learn)の場合
Python(scikit-learn)でカテゴリー変数を扱う場合、ダミー変数に変換する必要があります。ダミー変数への変換はPandasのget_dummiesを使うと便利です。
また、scikit-learnで(決定木を含む)予測モデルを作る場合、PandasからNumpyに変換する必要があるので、as_matrixも扱えるようになると作業がはかどります。
scikit-learnで作成した決定木はGraphvizで可視化できます。以下のような図になります。
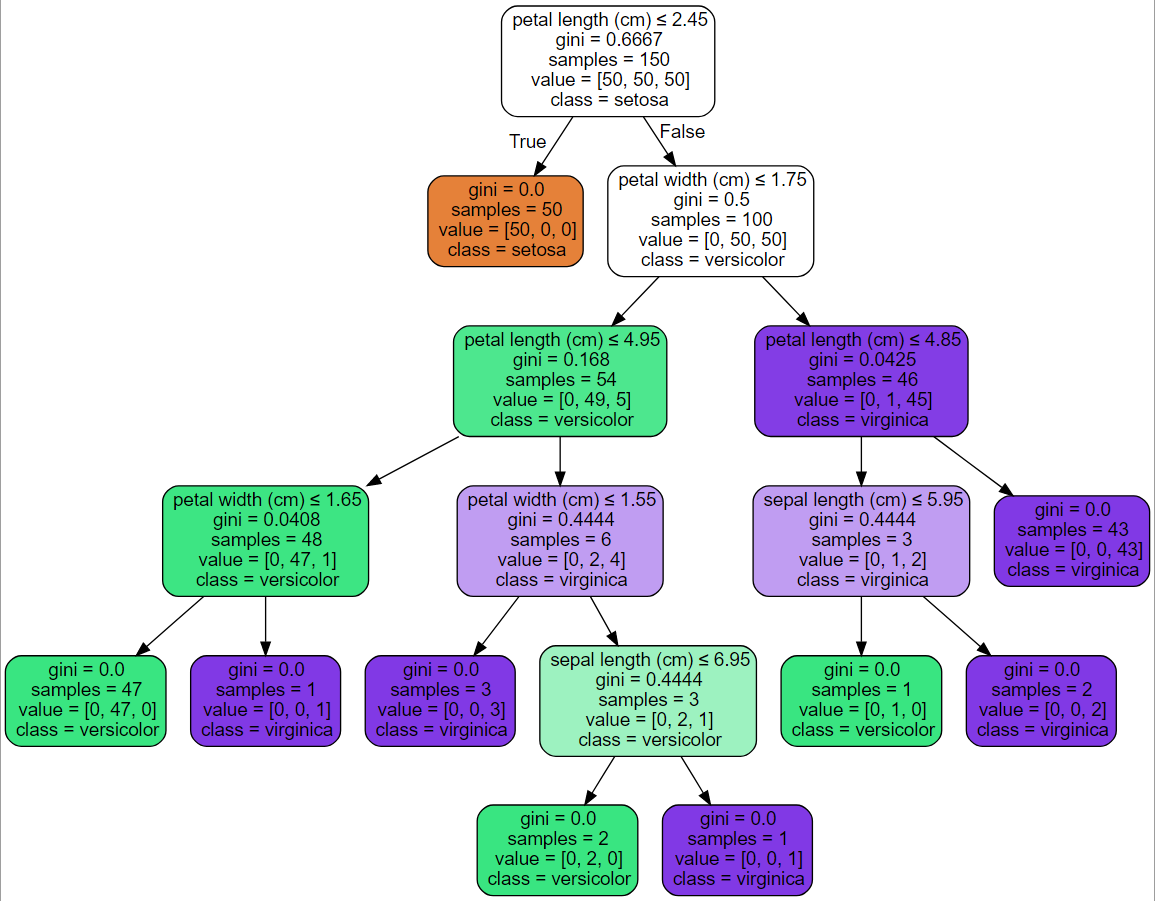
上図のように、ジニ係数が0になるか、指定した最大深さに到達するまで分岐し続けます。色を指定する場合、各ノードにおける色は到達したデータのクラスの割合を表し、色が濃い程、割合が偏り、色が薄い程偏りが弱いことを表します。白の場合、割合が50:50となります。
画像は公式から
Graphvizの画像が好みでない人にはD3.jsでグラフを描くのも良いでしょう。
こちらのPythonとJavaScriptではじめるデータビジュアライゼーションを参考にしてみてはいかがでしょうか?

R(rpart)の場合
R(rpart)の場合、Pythonと違い、カテゴリー変数をそのまま説明変数として扱うことができます。**文字列(日本語を含む)型でも問題ありません。また、OR条件**も適用されます。OR条件とは、例えば、カテゴリー変数に「都道府県」があった場合、「東京都、大阪府、北海道」のいずれかか、それ以外かで分岐するといった具合です。
rpartで作成した決定木はrpart.plotで可視化することができます。以下のような図になります。
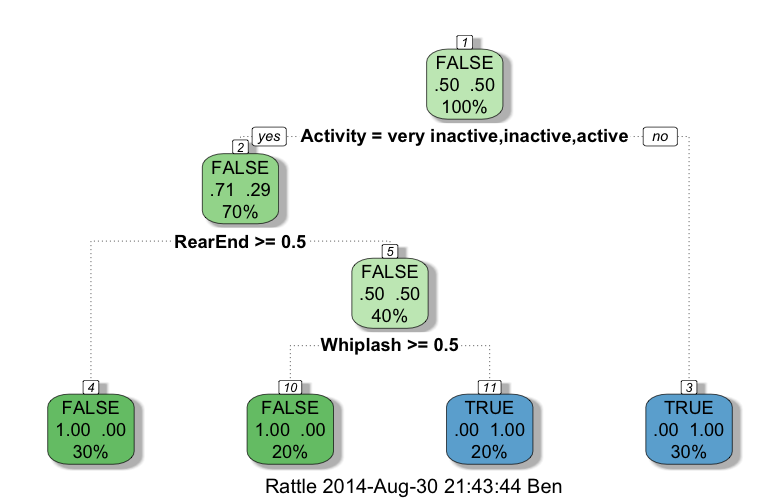
画像元はこちら
上図からもわかるように、R(rpart)で決定木を作成した場合、最初の分岐に注目するとカテゴリー変数をOR条件で分岐可能、ダミー変数へ変換を必要としないことがわかります。
OR条件で分岐可能なので、Python(scikit-learn)の決定木と比べて、細かく分岐しない点も特徴の一つです。
どっちが良いの?
PythonとRによる決定木の違いを書きましたが、どっちが良いか?それは、**予測精度が良い方**です。同じ決定木ですが、アルゴリズムが少し違います。そういう意味では、決定木とサポートベクターマシーン、ニューラルネットワークのどれが良いか?と同じ問題です。
そして、予測精度を上げるためには、**データが重要です。データがあってのモデルです。アルゴリズムよりも、分析可能なきれいなデータがあるか、適切に前処理**が出来ているかの方が重要です。
さいごに
PythonとRの決定木について書きましたが、おそらく決定木を作って終わりという人はいないのではないでしょうか?決定木で分類モデルを作成して予測結果をレポートにまとめる人もいれば、モデルをシステムに組み込むという人もいるでしょう。
個人的な意見ではありますが、システムに組み込む場合はPythonを、統計的な分析をする場合はRの方が便利かなと思っています。状況に応じて、両方を使いこなせるように精進したいと思います。
以上、
**「決定木、あなたはどっち派?」**のコーナーでした。