さいしょに
「AI」、「ビッグデータ」、「データサイエンティスト」、これらのキーワードに関する仕事がしたいと思っている人はどの程度いるでしょうか?その中に、どのように勉強すれば良いかわからない、勉強はしたけど挫折した、実践できるまでには至らなかった人はどの程度いるでしょうか?
本記事では、データサイエンスを勉強している中で、気付いたことをまとめています。あくまで、個人的に感じたことをまとめたものであり、勉強方法を決めつけるものではありません。
※機械学習の実装方法等、技術的な内容ではございません。
Kaggleとは?
公式より
Kaggleとは、
「企業や研究者がデータを投稿し、世界中の統計家やデータ分析家がその最適モデルを競い合う、予測モデリング及び分析手法関連プラットフォーム及びその運営会社である。 」 以上、Wikipediaより
要するに、企業等が分析してほしい課題を投稿し、世界中のデータサイエンティストが各々予測モデルを作成し、予測結果を提出する。その中で最も優れた予測モデルを作ったデータサイエンティストは報酬をもらえるデータサイエンスのコンテストです。
参加するための準備はこの記事が参考になると思います。
何故、Kaggleからはじめるのか?
その理由は、Kaggleはデータ分析の一連の流れを経験できるから
Kaggleは分析し、予測モデルを作成するためのデータと答えを予測するデータの2種類のデータを扱います。Kaggleをおすすめする一番の理由はこのデータにあります。
実は、与えられるデータはきれいなデータとは限りません。よって、データを分析できるようにきれいにする、データクレンジングを行わなければ良い予測モデルを作ることはできないのです。そして、このデータクレンジングはデータ分析プロジェクトにおいて7、8割の時間を費やすと言われています。
つまり、データ分析のほとんどは統計解析、機械学習をするためのデータの準備に労力を使うのです。すなわち、データを読み取る力がなければ、良い予測モデルを作ることはできないのです。データを見ることから始めるKaggleは良い勉強になります。
データ分析プロジェクト
ここで、データ分析プロジェクトについて少し説明します。
データ分析プロジェクトにおいて、どの業界に対しても共通となるフェーズを定義したCRISP-DM(CRoss-Industry Standard Process for Data Mining)という考え方があります。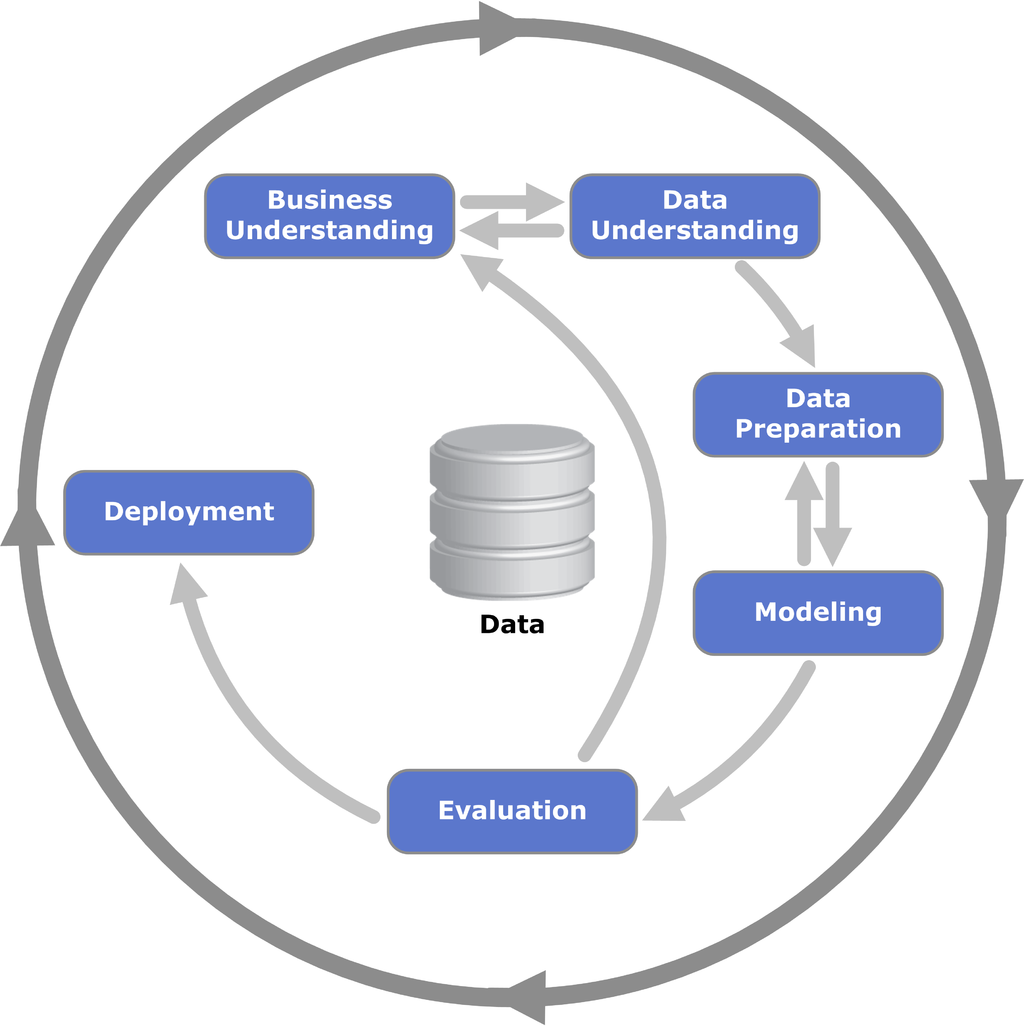
画像はコチラ
上図からもわかる通り、データ分析する上で、まずビジネス(課題)の理解から始まります。解決すべき課題を定義したら次に、データの理解となります。設定した課題を解決できるだけのデータがあるかどうかを見ます。
データがあればデータの準備に移ります。ここで、先述のデータクレンジング等予測モデルを作る準備をします。データがない場合、必要なデータを収集するか課題を設定し直すことになります。
予測モデル作成の準備が出来たらモデル作成、モデル評価(改善)をします。作成したモデルの予測精度が良ければデプロイ、納品となります。注意すべきは、作成、改善したモデルの精度が常に良くなるとは限らないということです。
モデルの精度が良くならない場合、再度、ビジネス理解のフェーズに戻り、課題設定からやり直します。
実際に、経験してみるとわかりますが、圧倒的にデータと睨めっこする時間が長いです。
統計学と機械学習
次に、モデル作成、評価(改善)について簡単に説明します。個人的には、統計学、機械学習の両方の知識が必要になると思っています。正確にいうと良い予測モデルをつくるには両方の知識が必要になります。
統計学の知識はデータを見るのに有効です。私の場合、統計学の勉強はしたことがなく、機械学習は勉強しているという状態ですが、変数にどれを選ぶかに困ります。正直に言うと勘でした。最近ですが、統計学を勉強する機会があったので、勉強したところ目的変数(導き出す答え)と説明変数(答えを導き出す要素)の相関をまず見るということを学びました。
機械学習の知識は答えを導き出すの有効です。アルゴリズムを用いて答えを導く、データ数が多い程、より精度の高い予測モデルを作ることができます。ビッグデータと言われるほど、現在、大量のデータが存在します(全て使えるわけではありません)。今後も生成されるデータが増えることはあっても、減ることはないと思われるので、今後も機械学習の技術は発展していくでしょう。
あくまで、個人的な見解になりますが、データを見るために統計学の知識が、答えを導くために機械学習の知識が必要だと思っています。
Kaggleだけでは足りない
Kaggleから勉強をはじめると学べることは非常に多くあると思いますが、Kaggleでは足りないことがあります。それは問題設定です。上記のビジネス(課題)の理解で設定する課題と同じです。
Kaggleの場合、コンテストなので問題が設定されているため、問題設定の練習ができません。しかし、データサイエンティストを目指すなら、問題設定ができないと分析できません。そして、問題設定できないとモデルの精度を評価することができません。
Kaggleで問題設定はできませんが、問題設定と予測モデルの精度の関係は知っておくべきでしょう。
モデルの精度のカラクリ
モデルの精度ってどう評価するか知っていますか?例えば、精度が90%のモデルは良いモデルでしょうか?
モデルの精度は問題設定の仕方によって下限は設定できるということを理解しておくべきだと思います。
例として、優秀な人を予測するモデルを作るとしましょう。まず、優秀な人の定義をするわけですが、テストを行い、テストの点数の上位10%を優秀な人と定義したとしましょう。
モデルの精度は優秀と予測して、優秀と優秀じゃないと予測して優秀じゃない数の合計が全体の何%かによって決まります。図で表すと、以下の水色の領域に当てはまる数が全体の何%に相当するかとなります。

ここで、仮に全員が優秀じゃないというモデルを作ったとしましょう。このモデルの精度は90%(優秀じゃないと予測して優秀:10%、優秀じゃないと予測して優秀じゃない:90%)になります。このモデルは良いモデルでしょうか?おそらく、良いモデルと納得する人はいないでしょう。
要するに、良いモデルとは**精度が○○%**ではなく、予測を全て0か1(上の例でいう、優秀か優秀じゃないか)とするモデルよりも良い精度を出せるモデルが良いモデルなのです。
すなわち、優秀かどうか判断するモデルは精度の下限は90%になるので、作成するモデルは精度が90%を超えていれば精度の良いモデルになるのです。
さいごに
データサイエンティストを目指すのに、Kaggleから勉強を始めると良いと書いてきました。最初に取り組む問題としてはTitanicの問題(Kaggleのチュートリアル的な問題)が良いでしょう。機械学習のモデル作成、改善だけでなく、どの変数を選択するか等、学べることはたくさんあります。
モデルが完成したら、答えを予測して提出しましょう。自分が何位なのか、Scoreは何点なのかわかります。上位にランクインできれば自信もつきますし、他のコンテストに参加して報酬を狙うのも良いでしょう。データサイエンティストとして働くことも夢ではありません。(他にもSQL等、勉強すべきことはありますが…)
この記事がデータサイエンティストを目指す人に少しでも参考になれば幸いです。よろしければいいねをお願いします。
以上、ポエムでした。