はじめに
生成AIの勉強がしたかったので、以下のコースを一通りやったみたが、概要とかGoogle内のサービス紹介が多くて、理解が進まなかったので、実際に手を動かしてやってみることに。
https://www.cloudskillsboost.google/journeys/118
※本筋とそれるが、このコースは10の講義があるが、かなり重複があるのと、各講義とテストの内容があってないように思えることが多くて微妙だった…
コース内でVertex AIというプラットフォームの紹介がされていたため、そのチュートリアルを進める形でやっていこうと思う。
https://cloud.google.com/vertex-ai/docs/tutorials?hl=ja
Vertex AI is a machine learning (ML) platform that lets you train and deploy ML models and AI applications, and customize large language models (LLMs) for use in your AI-powered applications.
https://cloud.google.com/vertex-ai/docs/start/introduction-unified-platform
Vertex AIとは、データセットの作成やモデルのトレーニング、またそれを活用したアプリケーションの作成までカバーできる機械学習のためのプラットフォーム、らしい。
Vertex AI内で、モデルのトレーニング方法やアプリケーションのデプロイを行うにはいくつかやり方がある。
- AutoML
- Custom training
- Model Garden
- Generative AI
AutoMLはテーブルデータや画像、テキストなどをコードの記載なしで簡単に学習、活用できる仕組み。Custom Trainingは自分でコードを書いてトレーニングを行う仕組み。自分の好きなフレームワークの採用、パラメータチューニングができる。Model Gardenは他の人が作成したモデルを流用できる。Generative AIは、Googleが用意したLLMを活用できる。別途データを加えてチューニングすることも可能。今回はまず一番シンプルなAutoMLにてやってみる。
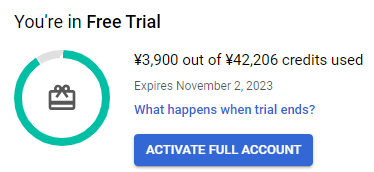
注意として、このチュートリアルを通すにはコストがかかる。自分の場合は、半年間のフリートライアルで300ドル分のクレジットを原資に実施しており、そこから3900円かかっている。
サービスアカウントの作成
- サービス用のアカウント(vertexlearn)を作成
- プロジェクトのオーナーロールを付与
- サービスアカウントキーの作成
json形式のテキストがPCにダウンロードされる。このユーザをCloud Shellで使うとはどういうこと?
このJSONを環境変数に指定するのはいいけど、それはこのPCの話であって、Cloud Shellには反映されないよね…。
しょっぱなから置いてきぼりなんだけど。
たぶんこれは汎用的にある項目で、実際AutoMLを使うなら、この項目はたぶん飛ばしていい。実際飛ばして何も問題はなかった。この辺りはちょっと不親切なのではと感じた。
データセットの作成
とりあえず、いったんスルーして続きを。
Vertex AIのページからデータセットを作成する。今回はラベルがあらかじめついたサンプルデータを使う。
cloud-samples-data/ai-platform/flowers/flowers.csv
このCSVを指定してあげればよい。このCSVには、画像のURLとそのラベルが以下のように記載されている。
gs://cloud-samples-data/ai-platform/flowers/daisy/10559679065_50d2b16f6d.jpg,daisy
gs://cloud-samples-data/ai-platform/flowers/dandelion/10828951106_c3cd47983f.jpg,dandelion
gs://cloud-samples-data/ai-platform/flowers/roses/14312910041_b747240d56_n.jpg,roses
gs://cloud-samples-data/ai-platform/flowers/sunflowers/127192624_afa3d9cb84.jpg,sunflowers
gs://cloud-samples-data/ai-platform/flowers/tulips/13979098645_50b9eebc02_n.jpg,tulips
つまり、何かネットからこうしたデータを拾ってくれば、それを使ってデータセットを作ることが可能。
まずは指示通りこの画像データ集からデータセットを作成する。インポートに時間がかかると記載があったが、自分の場合は40分程度でした。
またインポート後に画面上で画像とラベルを確認できるが、以下のように警告が出る。これは実際にユーザが遭遇しうるエラーの練習みたいなものらしく、想定されたものとのこと。

ここからアノテーションセットを作成することもできる。アノテーションとは、画像に注釈や説明を与えること全般を指すので、この場合はラベル付けと同義だと思っている。
トレーニング
続けてトレーニングを行う。AutoMLの場合は、パラメータなどもほとんどないので、単に実行するだけ。
ただしお金がかかるので、注意。
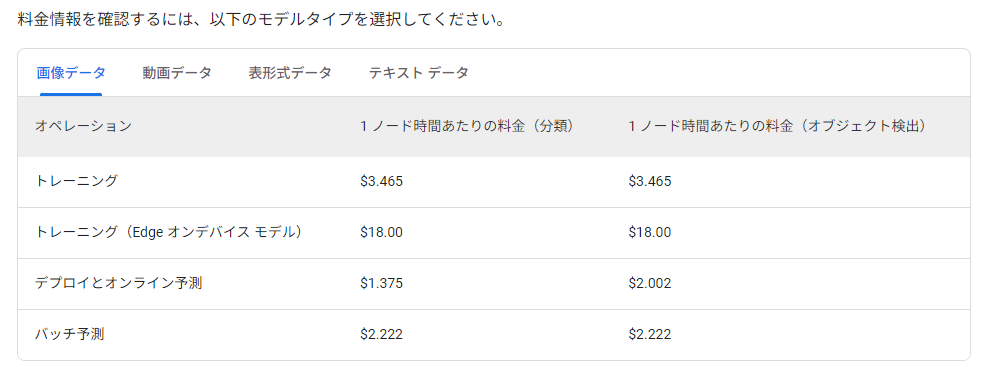
8-800ノード時間を指定可能。8だと25ドルくらいかかる可能性がある。一応今は300ドルのフリークレジットをもっているので、それを使う。予測だと1時間くらいで終わるらしいが、実際には2時間かかった。結果的に7ドルくらいということか。

評価
Model Development からTrainingの項目を選ぶと、トレーニングの完了したモデルの評価を見ることができる。ここで見るべきは誤って判定されているものを示すConfusion Matrix。

今回だとTulipとRoseが混同されているので、このあたりのデータをもっと与えれば精度が上がるだろう。
また具体的にどのイメージが間違って分類されていたか、それは実際は何のラベルが付与されていたか、も確認することができる。

この際には2つの問題に注意する必要あり。1つは不適切なラベル付け。これは見ればわかる。
もう1つはOutlinerと呼ばれるもの。これは、似たようなイメージがデータセットの中になかった場合にこう判定される。この場合も、似たようなイメージをデータセットに追加することで精度を上げられる可能性がある。
モデルのデプロイ
この画面にあるDEPLOY&TESTというタブから、エンドポイントのデプロイができる。エンドポイントというのは、オンラインで予想の受付が可能になるインスタンス(ウェブサーバみたいな)のことらしい。
作成すると、何ノード用意してどのようにリクエストのトラフィックを分散するかを指定できる。今回は分散せず、1つのノードで実施する。多分これもコストがかかるのか。また特に説明ないが、Loggingの設定も可能。これでもコストが変わるのかもしれないが、いったんデフォルトのオンにしておき、デプロイを開始する。これも完了まで少し時間がかかるらしい。自分の場合は30分程度。

テスト
Upload Imageというボタンから、自分で画像をアップロードして判定させることができます。The バラという画像ではほぼ正確に判別されています。

※愛知県が昔作った新種の画像をお借りしました。
https://www.pref.aichi.jp/soshiki/nogyo-keiei/0000083682.html
クリーンアップ
- モデルのアンデプロイ
- エンドポイントの削除
- モデルの削除
- データセットの削除
- Cloud Storage Bucketの削除
をマニュアルでやる必要があるので注意。構築の順番と若干違って、エンドポイント削除前にモデルのアンデプロイという操作が必要。
結構面倒ではある。特に最後はCloud Shellからコマンド実行だが、せっかくAutoMLとしてすべてGUI化しているのに、なぜここだけCLIなのだろう…。GUIで全然できるような…。またこのバケット削除もちょっと時間がかかる。自分の場合は10分くらい。
料金の確認
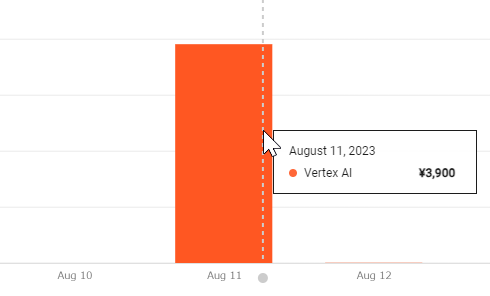
トータルで3900円かかった。ほぼ100%トレーニングのコストだが、1ノード時間で3.4ドルとのことで、2時間くらいしかかかっていないのにこれはどういうことだろう?。試用期間といっても上限の決まっているクレジットなので気になる…。

終わりに
Vertex AIの中の、AutoMLという仕組みの使い方はイメージできた。数年前に自分が画像判定の機械学習をした際には、この辺りすべてコード書いてやった記憶なので、格段にハードルは下がっているように思う。次のステップとしては自分のデータでやってみるとかになるか。
本当の目的はGenerative AIなので、それが終わったらCustom Trainingのパターンもやってみて、その上でGenerative AIのチュートリアルに進む予定。
ただ、けっこう湯水のようにコストかかりそうなので、要注意。