はじめに
我が家では家計簿をつけていますが、なぜか毎月山のように溜まるレシートを見て心が折れそうになります。快適な生活への第一歩としてレシートの画像から店名を判別する機械学習モデルを作りました。
15 店のレシート各 1 枚を使ってモデルを作成し、モデルによっては正解率 97% となりました。主に自分の行動範囲内のレシートを使っているため評価データとしては偏りがありますが思っていたより高い精度でした。
環境
- windows10
- conda 4.10.3
- Python 3.8.5
- opencv-python 4.3.0.36
- scikit-learn 0.23.2
- レシートの取り込みには Scansnap iX100 を使いました。
画像の準備
スキャナを使ってレシートを画像データにしました。scansnap は今回の目的にとても良くフィットするのでおすすめです。実用的にもカメラでレシートを撮影するより楽です。念のため通常のスキャナ (Canon TS8330) で読み込んでレシート部分だけトリミングしても判別できることを確認しています。
ラベル付け(ファイル名の変更)
お店ごとにレシートが 1 枚あればモデルを作成できます。+α があれば評価用に使えます。
フォルダ名を正解ラベルにしてその中に画像ファイルを入れていきます。画像ファイルの名前は 正解ラベル_枝番 (例: "seven_01.jpg") とします。数が多いと手作業では大変なので以下のコードで実行しました。このコードでは次のようなファイル構造を想定しています。スキャンした画像データは それぞれ seven/, famima/ などに仕分けます。関数に scan_data のパスを渡すことで中のフォルダ名を元に画像の名前を一括で変更して最初の 1 枚を training/ に、残りを validation/ に振り分けます。
.
├ scan_data/
│ ├ seven/
│ ├ famima/
│ └ lawson/
├ training/
└ validation/
import glob
import os
import shutil
def rename_files(scan_data_path):
"""
rename filenames to directory name plus serial, then move first file to training dir as a training image
:param scan_data_path: PATH to the directory of receipt files
:return:
"""
# training データ、validation データの保存場所を作成
training_dir = './training'
if not os.path.exists(training_dir):
os.mkdir(training_dir)
validation_dir = './validation'
if not os.path.exists(validation_dir):
os.mkdir(validation_dir)
# "desktop.ini" を拾わないようにリストから除く (windows 限定?)
files = os.listdir(scan_data_path)
if 'desktop.ini' in files:
files.remove('desktop.ini')
else:
pass
# フォルダ名を元にファイルをリネームして 1 枚目を学習データ、それ以外を validationデータに振り分ける
for store in os.listdir(scan_data_path):
path = scan_data_path + '/' + store
files = glob.glob(path + '/*')
files = [s for s in files if not s.endswith('desktop.ini')]
file_name = store
for i, file in enumerate(files):
os.rename(file, os.path.join(path, file_name + '_{0:02d}.jpg'.format(i)))
if i == 0:
shutil.move(os.path.join(path, file_name + '_{0:02d}.jpg'.format(i)), training_dir)
else:
shutil.move(os.path.join(path, file_name + '_{0:02d}.jpg'.format(i)), validation_dir)
# 実行例
rename_files('scan_data')
画像準備でハマったところ
windows 環境での問題なようですが、os.listdir はエクスプローラなどでは表示されない "desktop.ini" というファイルも認識します。そのまま実行するとこれもリネームして移動してしまうのですが、cv2 などで読もうとすると画像ファイルとして読み込めないので後のエラーの原因となります。見えない上に神出鬼没で幾度となくハマりました。files.remove('desktop.ini') や [s for s in files if not s.endswith('desktop.ini')] はこれをリストから除くために加えています。
画像の読み込み
続いて画像の取り込みです。レシートはお店や買い物によってサイズが変わりますので、入力データとしてサイズを統一する必要があります。今回は最も各店の特徴が出やすい頭の部分だけを使いました。横幅を 300 px に合わせてリサイズし、その状態で上から 150 px を切り取ります。例えばセブンイレブンでは以下の部分です。

トリミングは次の関数で実行しました。CNN では色情報が不要でも 3チャンネルの画像データが必要ですが、今回は 1 チャンネルで十分なので gray_scale=True で実行します。ここでは関数の定義だけで実行は以降の関数の中で行います。
import cv2
def img_prep(img, img_width=300, img_top_height=150, gray_scale=True):
"""
resize the image data to width of 300 px and trim top 150 px
:param img: from cv2.imread
:param img_width: target width
:param img_top_height: target height
:param gray_scale: True for a single channel, False for three channels
:return: 300 x 150 px image
"""
# gray scale で取り込む場合の処理
if gray_scale:
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
else:
pass
# img_width=300 を基準に縮小する
size = (img_width, img.shape[0]*img_width//img.shape[1])
img_resize = cv2.resize(img, size)
# 縮小した画像の上から 150px をスライスする
img_top = img_resize[: img_top_height, :size[0]]
return img_top
scikit-learn を使ったモデル作成
学習データの準備
ディープラーニングをやるわけではないですが、画像が 1 枚しかないのでデータ拡張(水増し)して増やします。augmentation() の関数で画像の 二値化 (thr), ぼかし (blur), 収縮 (erode), 膨張 (dialation) をして 2^4 = 16 枚にしました。その他 opening, closing や mosaic も試しましたが、やりすぎると画像がつぶれるだけでした。計算に時間がかかるだけで正解率はほとんど上がりませんでしたのでここでは False にしています。
run_augmentation() で 画像の準備で作成した training/ フォルダを対象に augmentation() を実行します。
import cv2
import os
import numpy as np
def augmentation(img, thr=True, blur=True, erode=True, dilation=True, opening=False, closing=False, mosaic=False):
# データ拡張のリストを作る
methods = [thr, blur, erode, dilation, opening, closing, mosaic]
filter1 = np.ones((3, 3))
images = [img]
# データ拡張する関数を設定
augment_func = np.array([
lambda x: cv2.threshold(x, 100, 255, cv2.THRESH_TOZERO)[1],
lambda x: cv2.GaussianBlur(x, (5, 5), 0),
lambda x: cv2.erode(x, filter1),
lambda x: cv2.dilate(x, filter1),
lambda x: cv2.morphologyEx(x, cv2.MORPH_OPEN, filter1),
lambda x: cv2.morphologyEx(x, cv2.MORPH_CLOSE, filter1),
lambda x: cv2.resize(cv2.resize(x, (x.shape[1] // 5, x.shape[0] // 5)), (x.shape[1], x.shape[0]))
])
# 画像を上記の関数のうち True としたもので逐次処理する
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
for func in augment_func[methods]:
images = doubling_images(func, images)
return images
def run_augmentation(training_data_path, augmented_data_path):
# 結果を入れるフォルダを作成
if not os.path.exists(augmented_data_path):
os.mkdir(augmented_data_path)
else:
pass
# "desktop.ini" を拾わないようにリストから除く (windows のみ)
files = os.listdir(training_data_path)
if 'desktop.ini' in files:
files.remove('desktop.ini')
else:
pass
# トレーニングデータを読み込みデータ拡張する
for file in files:
img = cv2.imread(training_data_path + '/' + file)
augmented_img = augmentation(img_prep(img))
# データ拡張した画像の保存場所を作成
if not os.path.exists(augmented_data_path + '/' + file[:-7]):
os.mkdir(augmented_data_path + '/' + file[:-7])
# データ拡張した画像に名前と枝番を付けて保存
for num, im in enumerate(augmented_img):
cv2.imwrite(augmented_data_path + '/' + file[:-7] + '/' + file[:-4] + '_' + str(num).zfill(2) + '.jpg', im)
# 実行例
run_augmentation('training', 'augmented_images')
データ拡張した画像ファイルを読み込みます。今回作成するモデルでは正解ラベル(カテゴリデータ)を数値データに変換する必要がありましたので LabelEncoder で変換しています。あとで数値化したデータを元の店名に戻すために 店名リスト store_list.txt を保存しています。
import cv2
import numpy as np
import os
from sklearn.preprocessing import LabelEncoder
def read_images(augmented_data_path):
augmented_dirs = os.listdir(augmented_data_path)
X = []
y = []
stores_list = []
# データ拡張して保存した画像を 学習データ X と 正解ラベル y として読み込む
for dir in augmented_dirs:
stores_list.append(dir)
for file in os.listdir(augmented_data_path + '/' + dir):
img = cv2.imread(augmented_data_path + '/' + dir + '/' + file)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
X.append(img_gray)
y.append(dir)
# 後に数値化したデータを元のカテゴリーに戻すために保存しておく
if not os.path.exists('models'):
os.mkdir('models')
with open('./models/stores_list.txt', 'w') as f:
for c in stores_list:
print(c, file=f)
# scikit-learn に入れられる型に変換する
X = np.array(X)
le = LabelEncoder()
y_num = le.fit_transform(y)
y_num = np.array(y_num)
return(X, y_num)
read_images() を実行した結果は次のようになります。X は (拡張後のレシート数 x 150 px x 300 px)、y は正解ラベルの数に応じた変数となっていることが分かります。
# 実行例
X, y_num = read_images('augmented_images')
print('X.shape: ', X.shape)
print('y_num: ', y_num)
# 実行結果例
# X.shape: ("拡張後のレシート数", 150, 300)
# y_num: [ 0 0 0 ... 5 5 5 ... (正解ラベル数 -1 まで)]
今回使う scikit-learn のモデルは 1 次元のデータとして入力する必要があるため レシートの数 x 2 次元データ ("レシートの数", 150, 300) となっている X を レシートの数 x 1 次元データ ("レシートの数", 45000) の X_flat の形に直します。関数 ml_data_prep() でこの処理を行い、さらに training data と test data に分割しています。
import numpy as np
from sklearn.model_selection import train_test_split
def ml_data_prep(X, y_num):
X_flat = []
for i in range(X.shape[0]):
X_flat.append(X[i].flatten())
X_flat = np.array(X_flat)
X_train, X_test, y_train, y_test = train_test_split(X_flat, y_num, test_size=0.2, random_state=1, stratify=y_num)
return X_train, X_test, y_train, y_test
モデルの作成
今回作成したモデルは LogisticRegression(), SVC(), DecisionTreeClassifier(), RandomForestClassifier(), KNeighborsClassifier() の 5 モデルです。
ランダムサーチを実行する関数 randomized_search() とそれを実行する make_ml_model() を作っています。改めて見返すともっと汎用性のある良い書き方がある気がしてきましたが、今は目をつぶって進めます...笑
ここではランダムサーチで決めたパラメータで作成した各モデルを pickle ファイルとして保存しています。
import numpy as np
import os
import pickle
import scipy.stats
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from sklearn.metrics import f1_score
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
def randomized_search(X_train, X_test, y_train, y_test, model):
# 各モデルに対してサーチするハイパーパラメータの範囲を設定する
model_param_set_random = {
'LogisticRegression()': {
'C': scipy.stats.uniform(10 ** (-5), 10 ** 5),
'max_iter': [100],
'penalty': ['l2'],
'multi_class': ['ovr', 'multinomial'],
'random_state': [42]
},
'SVC()': {
'C': scipy.stats.uniform(10 ** (-5), 10 ** 5),
'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],
'decision_function_shape': ['ovo', 'ovr'],
'random_state': [42]
},
'DecisionTreeClassifier()': {
'max_depth': scipy.stats.randint(1, 11),
'random_state': [42]
},
'RandomForestClassifier()': {
'n_estimators': scipy.stats.randint(1, 21),
'max_depth': scipy.stats.randint(1, 6),
'random_state': [42]
},
'KNeighborsClassifier()': {
'n_neighbors': scipy.stats.randint(1, 11)
}
}
params = model_param_set_random[str(model)]
# max_score を超えたらそのパラメータと一緒に逐次更新していく
max_score = 0
best_param = None
# RandomizedSearchCV を実行して最も高いスコアのパラメータのモデルを取得する
clf = RandomizedSearchCV(model, params)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
score = f1_score(y_test, y_pred, average='micro')
if max_score < score:
max_score = score
best_param = clf.best_params_
print('{} :\n best_score: {},\n best_param: {}'.format(str(model), max_score, best_param))
return clf
def make_ml_model(X_train, X_test, y_train, y_test):
models_dic = {'logistic_reg': LogisticRegression(),
'random_forest': RandomForestClassifier(),
'decision_tree': DecisionTreeClassifier(),
'svc': SVC(),
'knc': KNeighborsClassifier()}
# モデルを保存する場所を作成
if not os.path.exists('models/ML'):
os.mkdir('models/ML')
# 各モデルに対してランダムサーチを実行し、最適なモデルを保存する
for name, model in models_dic.items():
print('making ' + str(name) + '..')
clf = randomized_search(X_train, X_test, y_train, y_test, model)
with open(f'models/ML/model_{name}.pickle', mode='wb') as fp:
pickle.dump(clf, fp)
# モデル作成実行例
X_train, X_test, y_train, y_test = prep_ml_data(X, y_num)
make_ml_model(X_train, X_test, y_train, y_test)
モデルの評価
import os
import cv2
import numpy as np
import pickle
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from sklearn.metrics import f1_score
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
def validate_ml(model_path):
# 評価結果を保存する場所を作成
if not os.path.exists('models/summary/'):
os.mkdir('models/summary/')
# 保存しておいた stores_list をリストオブジェクトにする
classes = []
with open('./models/stores_list.txt', 'r') as f:
for c in f:
classes.append(c.rstrip())
# 保存したモデルを一つずつオブジェクト化する
res_summary = []
ml_scores = []
for model in os.listdir(model_path):
with open(model_path + '/' + model, mode='rb') as fp:
clf = pickle.load(fp)
val_data_path = './validation'
files = os.listdir(val_data_path)
if 'desktop.ini' in files:
files.remove('desktop.ini')
else:
pass
correct = 0
res = []
# 開いたモデルで validation データから予測し正解した回数をカウント
for i, file in enumerate(files):
val_img = cv2.imread('./validation/' + file)
val_img = img_prep(val_img, gray_scale=True)
X_sample = np.array(val_img)
X_sample = X_sample.flatten()
answer = clf.predict(X_sample.reshape(1, -1))[0]
if classes[answer] == file[:-7]:
correct += 1
else:
pass
# 結果の解析用に csv ファイルとして保存しておく
res.append([str(model), file[:-7], classes[answer]])
pd.DataFrame(res).to_csv('models/summary/' + str(model[:-7]) + '_res.csv')
# 出力用に正解率を計算する
res_summary.append([str(model), round(correct/len(files), 3)])
ml_scores.append(round(correct/len(files), 3))
return res_summary
# 上記関数を実行
print(validate_ml('models/ML'))
# 実行結果例
# [['model_decision_tree.pickle', 0.307], ['model_knc.pickle', 0.927],
# ['model_logistic_reg.pickle', 0.953], ['model_random_forest.pickle', 0.727],
# ['model_svc.pickle', 0.967]]
validate_ml() でモデルの pickle ファイルが入っているフォルダを指定することで各モデルの validation データに対する正解率を出せます。csv はおまけの解析用に出力しました。
結果発表
1位に輝いたのは SVC (96.7%) でした!第2位は Logistic 回帰 (95.3%) で、意外と言っては何ですが、K近傍法 (92.7%) が第3位と良い成績でした。この辺りの順位はデータによって前後しそうです。
今回は 15 店のレシート各一枚からモデルを作成し、合計 150 枚のレシートを validation データとして評価しました。できるだけ店舗違いを集める努力はしたのですがだいぶ偏りはあります。とはいえ割とクラシカルな機械学習モデルでも精度良く判別できることが分かりました。店舗数が増えたときにどうなるかなどを今後試してみたいと思います。
おまけ
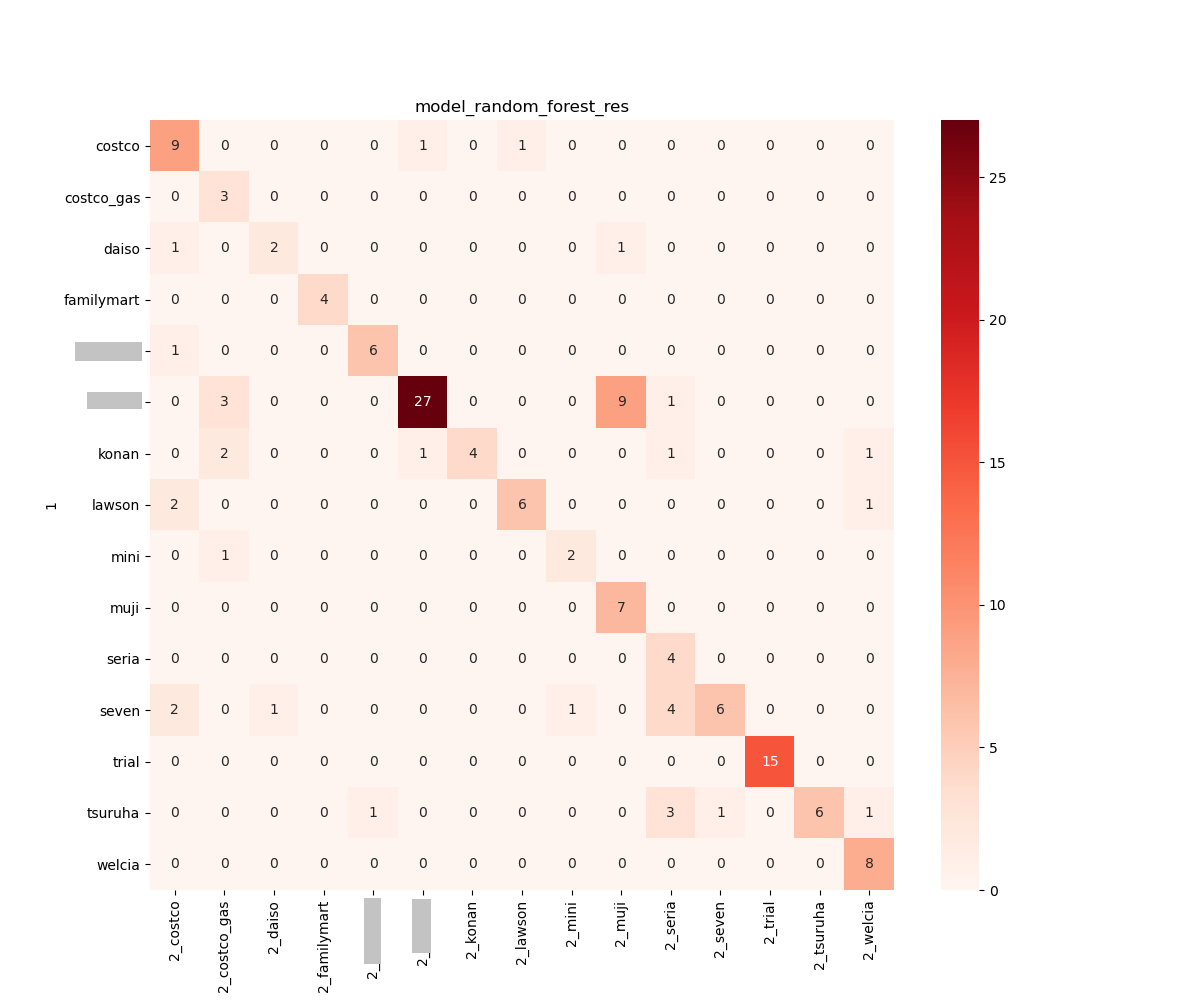
validate_ml() で出力しておいた csv ファイルを元にそれぞれのモデルの結果を可視化しました。
import matplotlib.pyplot as plt
import os
import pandas as pd
import seaborn as sns
def model_summary(model_summary_path):
for model_summary in os.listdir(model_summary_path):
df = pd.read_csv(model_summary_path + '/' + model_summary, index_col=0)
print(df)
# 正解ラベルと予測結果の対応表を作る
df_dummy = pd.get_dummies(df, columns=['2'])
df_dummy_g = df_dummy.groupby(['1']).sum()
print(df_dummy_g)
# snsでヒートマップを作成
fig = plt.figure(figsize=(12, 10))
ax = fig.add_subplot(1, 1, 1)
ax.set_title(model_summary[:-4])
sns.heatmap(df_dummy_g, ax=ax, annot=True, cmap='Reds')
plt.show()
plt.close('all')
# 実行例
model_summary('models/summary')
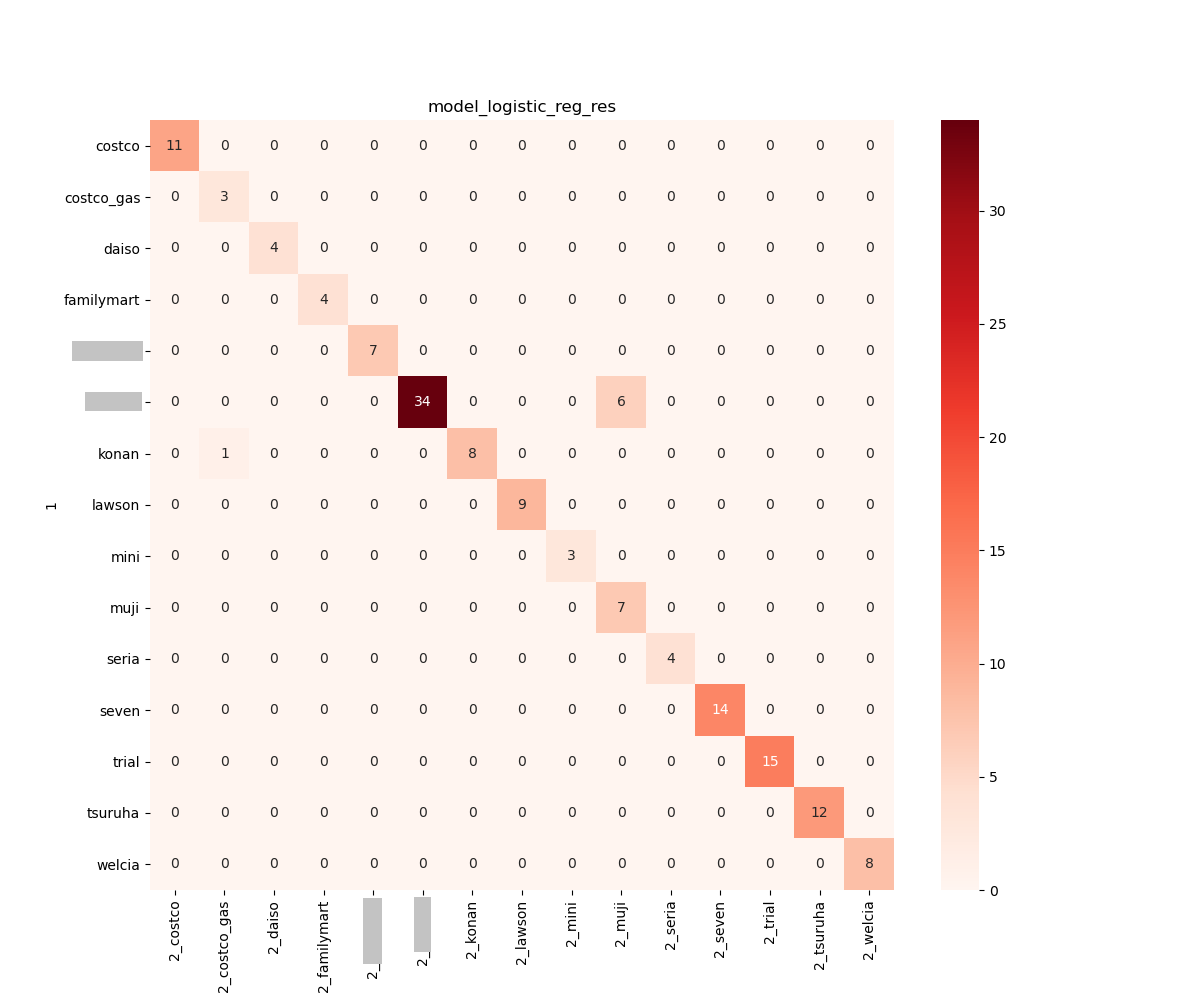
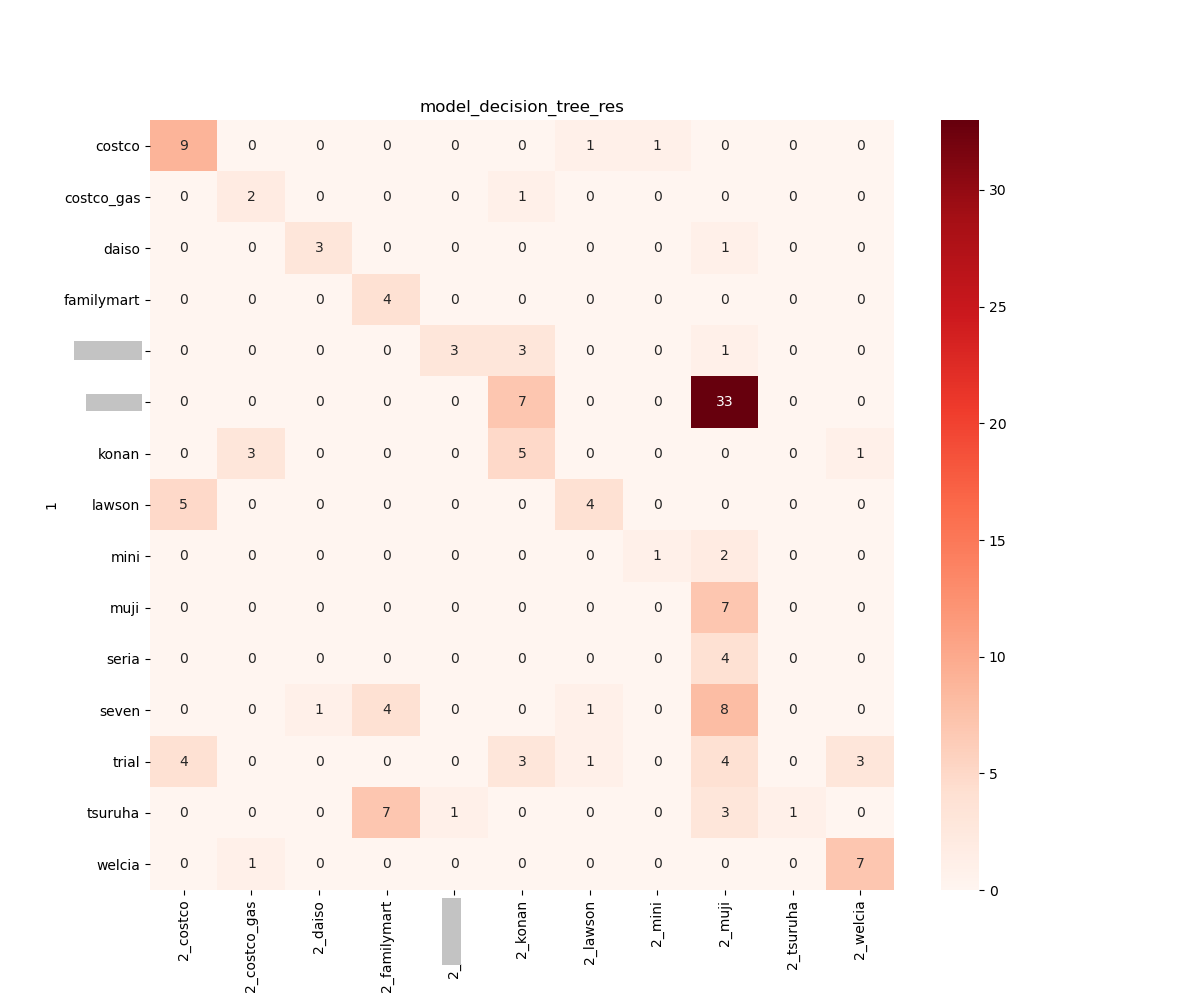
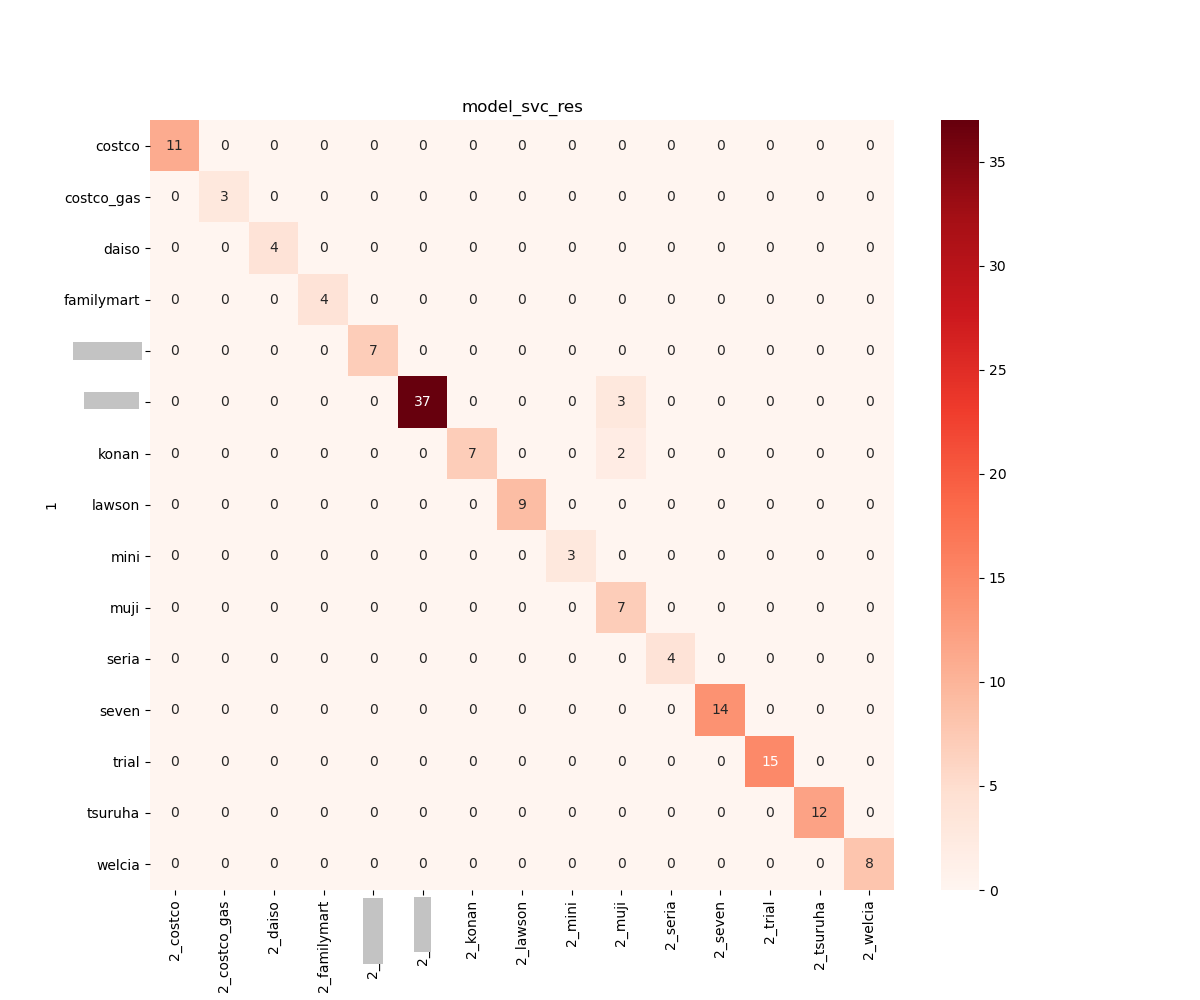
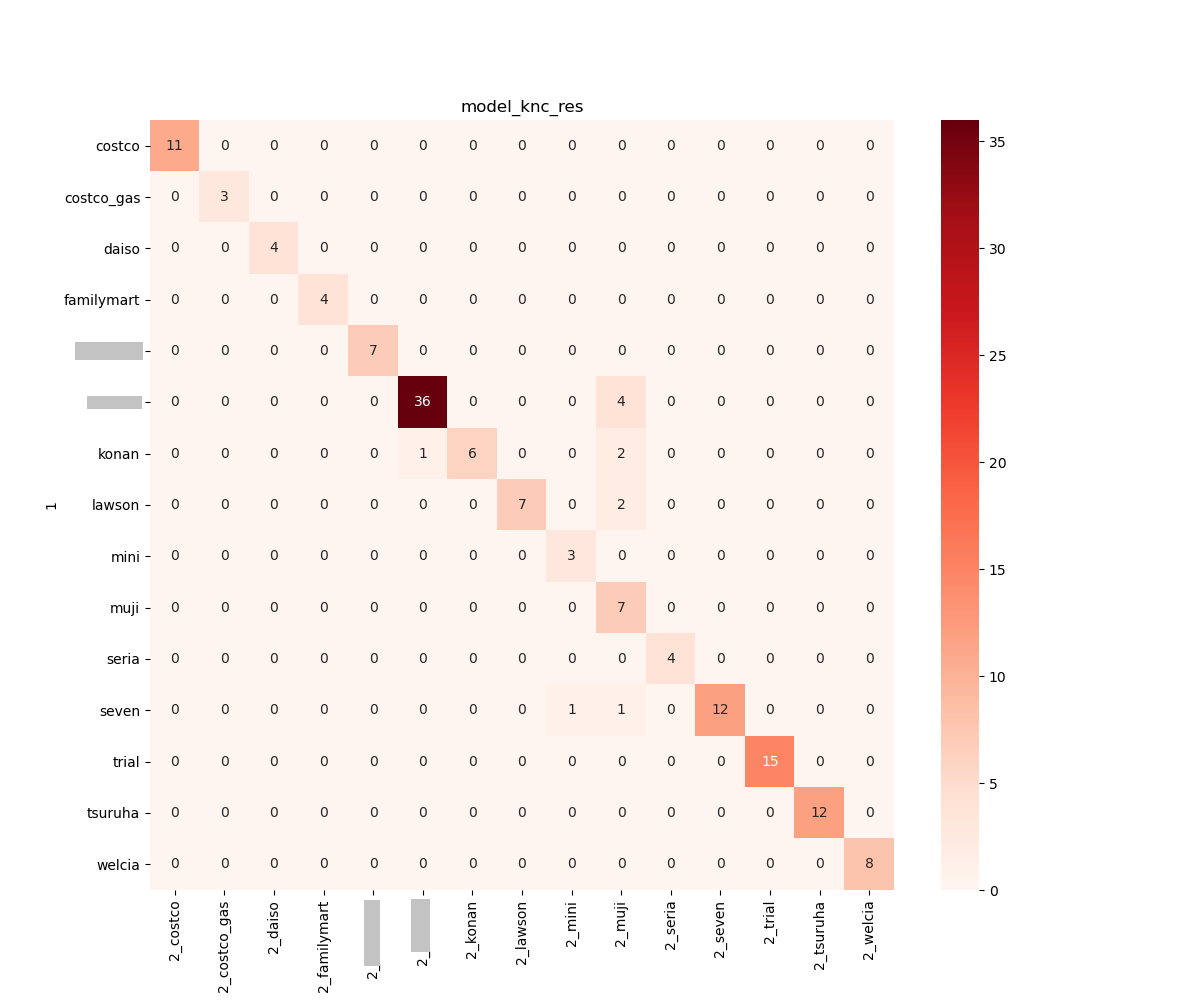
成績の良かった Logistic 回帰, SVC, K近傍法 は精度高く予測できていることが分かりますが、これらのモデルで共通して 「無印良品」 と誤認識してしまう間違いが多かったです。白い領域が多いもの同士の判別は難しいようです。

正解率は 70% 程度なものの、おぉ?!と思ったのが RandomForest です。LogisticRegression の pickle ファイルのサイズが 5 MB, SVC が 10 MB, K 近傍法に至っては 80 MB とかなり大きな容量となっているのに対して RandomForest はたったの 40 KB でした。シンプルなルールで比較的よい精度を出しているのかなと思います。
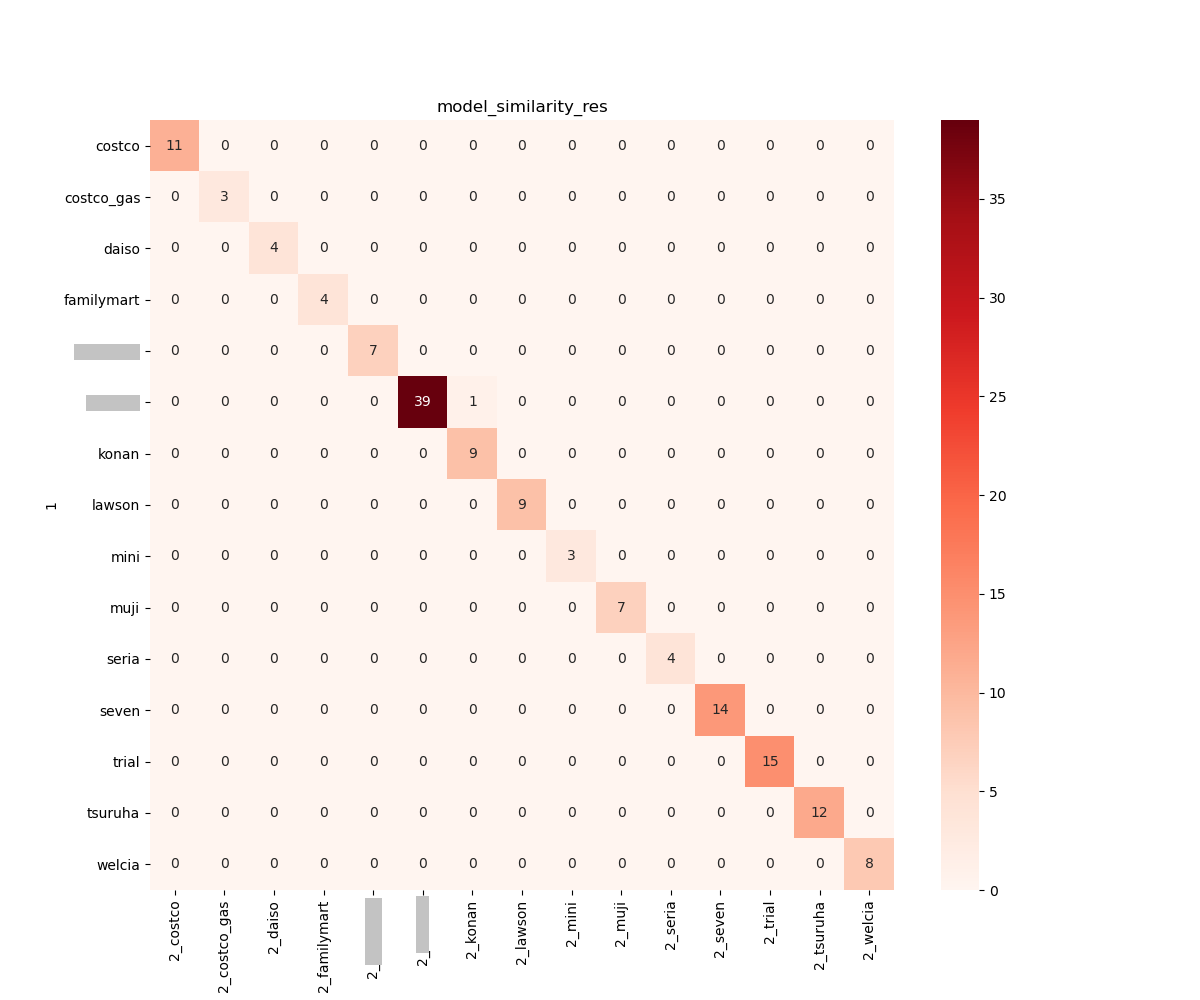
実は CNN も試したのですが、やはりレシート 1 枚では無謀すぎました(笑 結果は惨敗です。ハイパーパラメータの調整なども悩ましいところですが、その前に適切なモデルの選択は重要ですね。他に試したものの中で最も良かったのは cv2 の特徴点マッチング (99.3%) でした。もはや機械学習ではありませんが今回の目的にはこっちが最適かな
特徴点マッチングの結果だけ以下に示します。
おわりに
コンパクトにまとめるつもりが長文になってしまいました。目を通してくれた方ありがとうございます。
Qiita を含めネット上の情報に頼って学習しているので多少でも貢献できればうれしいです。
モデルの精度を上げることや、API を使った web アプリ化などしっかりラクすることを夢見て頑張っていますので、また機会があれば記事にしようと思います。
このモデルを使った web アプリを heroku にデプロイしていますのでリンクを貼っておきます。
https://aidemy-webapp.herokuapp.com/