概要
この記事では、python(PyTorch)で実際にプライバシー攻撃を行い、差分プライバシー技術で保護できるのかを試した記事である。
今回行う攻撃は、「属性推論攻撃 (Attribute Inference Attack) 」と呼ばれるものである。
2025年7月22日更新:記載していたpythonコードに不備があったこと(DP-SGDで勾配ノルムの平均化をし忘れていた)と、それに合わせてDP-SGDの効果に関する記載を一部修正しました.
差分プライバシー技術の概要
- プライバシーを保護するための手法の一つ。
- AppleやGoogleなども一部のサービスで採用している手法である。
- 一言でいえば、「データに絶妙なノイズを加えて、個人の特定を難しくする技術」である。しかし、この「絶妙なノイズ」の加減が非常に奥深く、「どのくらいのノイズを加えれば安全か?」「安全性をどう測るのか?」といった点がこの技術の面白いところであり、難しい部分でもある。
- 差分プライバシーの概要やどういった実例があるかについては、LayerXさんのこの記事がわかりやすいと思うので、なぜこの技術が求められているのかについては、そちらを参照するのが良いと思う。
差分プライバシーが(機械学習やAIの文脈で)求められる背景
- 差分プライバシー自体は、プライバシー保護のための手法として研究開発されている。
- 機械学習モデルやAIの分野で差分プライバシーは「連合学習」とセットで語られることが多いと思うが、今回は差分プライバシーに絞って解説する。
- 差分プライバシーがどんな問題を解決するか?
- 一般的な機械学習モデルでは、一箇所にデータをまとめて、ビッグデータを使って機械学習モデルを構築し、それを何らかの形でサービスとして提供することが多い。この提供されている機械学習のモデルに対して、(悪意を持って)何度も問い合わせを行うと、機械学習モデルの学習データに含まれている個人情報を推察することができる。
- これを防ぐための手段の一つとして、差分プライバシーという技術が存在する。
- (生成AI(特にLLM)が登場したとき、モデルへのクエリが学習されてしまい、企業の機密情報が漏れてしまった事件が多々発生していたが、それに近いと思う。)
概要としてはこれだけなのだが、イメージが湧かないと思うので、実際に以下を行ってみる。
- プライバシー攻撃を行ってみる
- 差分プライバシー技術を使って、本当にプライバシーを守れるのか確認してみる
プライバシー攻撃と差分プライバシーによる保護の検証
シナリオ
- 今回は以下のシナリオで攻撃とそこから防御を行ってみる。
- 状況:
- ある銀行が、ローンの承認を予測するモデルが公開しているとする。このモデルは、「年齢」「年収」「大卒資格の有無」をもとに予測をするモデルである。
- 攻撃:
- 攻撃者は、ターゲットの「年齢」「大卒資格の有無」を知っているが、「年収」を知らない。モデルへの繰り返しの問い合わせを通じて、ターゲットの「年収」を推測する。
- 「特定の個人(Aさん)のレコードを抜き出す」というより、「Aさんが属しているであろうグループ(例:42歳・大卒資格なし)の最も典型的な特徴(ローンが承認されやすい年収帯)を推測する」
- 攻撃イメージは以下のようなイメージである。
- 攻撃者は、ターゲットであるAさんの「年齢」「大卒資格の有無」を知っているが、年収を知らない。既知の情報をモデルへ入力し、未知である「年収」の値をさまざまに変えながら何度もモデルへ問い合わせする。
- 年収300万円 の場合 → ローン承認確率: 15%
- 年収500万円 の場合 → ローン承認確率: 45%
- 年収800万円 の場合 → ローン承認確率: 85%
- このように何度も問い合わせを行い、モデルが最も高い承認確率を示した年収を探す。この値は、モデルが学習したデータセットの統計的な傾向を反映しているため、Aさんの年収がその範囲に含まれる可能性が極めて高いと推測できる。
- 攻撃者は、ターゲットであるAさんの「年齢」「大卒資格の有無」を知っているが、年収を知らない。既知の情報をモデルへ入力し、未知である「年収」の値をさまざまに変えながら何度もモデルへ問い合わせする。
属性推論攻撃を実施する
必要なライブラリをインストールする。
pip install torch pandas scikit-learn matplotlib japanize_matplotlib
ライブラリをインポートする。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
import pandas as pd
import numpy as np
import random
import os
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import japanize_matplotlib
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用するデバイス: {device}")
必須ではないが、実験再現性を高めるために、以下の関数を作成&実行する。
def seed_everything(seed: int = 42):
"""
PyTorch、NumPy、Python標準ライブラリの乱数シードを固定する関数。
Args:
seed (int): 固定するシード値。
"""
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # マルチGPUを使用している場合は、これも設定しておく
torch.backends.cudnn.deterministic = True # 計算速度が犠牲になるが、cuDNNの決定論的な挙動を保証する
torch.backends.cudnn.benchmark = False # `cudnn.deterministic=True`のケースでは、`cudnn.benchmark = False`が推奨されている
print(f"Random seed set to {seed}")
seed_everything()
データを作成する。
# データセットの作成
num_samples = 10_000
age = np.random.randint(22, 65, num_samples)
has_degree = np.random.randint(0, 2, num_samples)# 0: No, 1: Yes
income = np.random.randint(250, 1200, num_samples)# 万円単位
# 年収800万円で承認確率が最大となるデータを作る
# ガウス分布(釣鐘型カーブ)を利用して、800万円をピークとする確率を計算
peak_income = 800
std_dev = 150 # カーブの幅を調整
income_prob = 0.9 * np.exp(-((income - peak_income)**2) / (2 * std_dev**2))
# 学歴も少しだけ確率に影響させる
approve_probability = np.clip(income_prob + (has_degree * 0.1), 0, 1)
loan_approved = (np.random.rand(num_samples) < approve_probability).astype(np.int64)
# 作成したデータの可視化
plt.scatter(has_degree, income, c=approve_probability, cmap='viridis')
plt.colorbar(label='ローン承認確率')
plt.xlabel('大卒資格の有無')
plt.ylabel('年収')
plt.savefig("loan_approval_data_visualization.png")
# DataFrameにまとめる
df = pd.DataFrame({
'age': age,
'income': income,
'has_degree': has_degree,
'loan_approved': loan_approved
})
df_master = df.copy()
print("作成したデータセットの先頭5行:")
print(df.head())
# 特徴量(X)とターゲット(y)の準備
X = df[['age', 'income', 'has_degree']].values.astype(np.float32)
y = df['loan_approved'].values
# データを訓練用と検証用に分割
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# データを標準化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# PyTorchのDataLoaderの準備
# 訓練用データローダー
dataset = TensorDataset(torch.from_numpy(X_train_scaled), torch.from_numpy(y_train))
loader = DataLoader(dataset, batch_size=64, shuffle=True)
# 検証用データローダー
val_dataset = TensorDataset(torch.from_numpy(X_val_scaled), torch.from_numpy(y_val))
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False) # 検証データはシャッフル不要
実行結果
作成したデータセットの先頭5行:
age income has_degree loan_approved
0 60 893 0 0
1 50 546 1 1
2 36 372 1 0
3 64 904 1 1
4 29 943 1 1
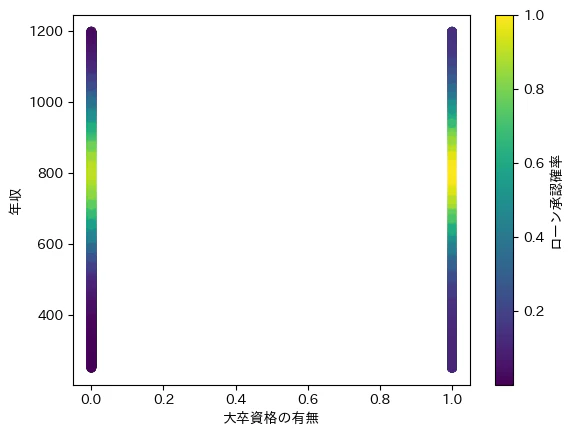
- 可視化したことで、想定した通りのデータが構成されていることがわかる。
- 年収が800万円をピークに承認確率が最大となること
- 同一年収であれば、大卒資格がある(=x軸の値が1.0)の時の方がローン承認率が高いこと。
学習のエポック数を指定する。
EPOCH_NUM = 5
簡単なネットワークのモデルを定義する。
# 単純なネットワークを定義
class LoanModel(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(3, 32), nn.ReLU(),
nn.Linear(32, 16), nn.ReLU(),
nn.Linear(16, 2)
)
def forward(self, x):
return self.net(x)
モデルと損失関数、オプティマイザーのインスタンス化をする。
model_without_dpsgd = LoanModel().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_without_dpsgd.parameters(), lr=0.001)
モデルを学習する。
# 学習する
model_without_dpsgd.train()
for epoch in range(EPOCH_NUM):
for data, labels in loader:
data, labels = data.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model_without_dpsgd(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
攻撃するターゲットの情報を取得する。
※※これは特定の個人(ID=5)を狙うという設定ではなく、単に攻撃に必要な「年齢」と「大卒資格の有無」の組み合わせの一例として、データセットの5番目の行を利用しているだけである点に注意。
model_without_dpsgd.eval()
# 攻撃対象のユーザとなる人物像(年齢と大卒資格の有無という2つ)の情報を取得する
target_idx = 5
target_user_features = df.iloc[target_idx]
# 攻撃者が知っている情報と知りたい情報
known_age = target_user_features["age"]
known_has_degree = target_user_features["has_degree"]
true_income = target_user_features["income"]
print(f"攻撃対象ユーザーの情報:")
print(f"既知: 年齢 = {known_age}, 大卒資格 = {'あり' if known_has_degree else 'なし'}")
実行結果
攻撃対象ユーザーの情報:
既知: 年齢 = 42, 大卒資格 = なし
攻撃者は、この人と同じ属性情報を持つ人の年収を当てに行くことになる。
攻撃を実行する。
# 年収を様々に変えてモデルに問い合わせる
potential_incomes = np.arange(250, 1201, 10) # 250万から1200万まで10万刻みで試す
approval_probabilities = []
for income_guess in potential_incomes:
# 問い合わせ用のデータを作成する
query_data = np.array(
[[known_age, income_guess, known_has_degree]],
dtype=np.float32
)
# モデル学習時と同じスケーラで標準化
query_scaled = torch.from_numpy(scaler.transform(query_data))
query_scaled = query_scaled.to(device)
# モデルの予測確率を取得
with torch.no_grad():
outputs = model_without_dpsgd(query_scaled)
probs = torch.softmax(outputs, dim=1)
approval_prob = probs[0,1].item()
approval_probabilities.append(approval_prob)
# 最も確率が高かった年収を推測結果とする
inferred_income_idx = np.argmax(approval_probabilities)
inferred_income = potential_incomes[inferred_income_idx]
print(f"攻撃による推測結果:")
print(f"参考:推測された年収: {inferred_income} 万円")
print(f"参考:実際の年収: {int(true_income)} 万円\n")
実行結果
攻撃による推測結果:
参考:推測された年収: 820 万円
参考:実際の年収: 953 万円
今回は上記したように、id=5のユーザの年収を当てることが目的ではないが参考として表示した。
攻撃者が得た年収の情報を可視化してみる。
# 攻撃者がtarget_idxのユーザについて得た結果を可視化
plt.figure(figsize=(10, 6))
plt.plot(potential_incomes, approval_probabilities, marker='o', linestyle='-')
plt.axvline(x=inferred_income, color='red', linestyle='--', label=f'推測された年収 ({inferred_income}万円)')
plt.title('攻撃者が試した年収とモデルのローン承認確率')
plt.xlabel('年収の推測値 (万円)')
plt.ylabel('ローン承認確率')
plt.grid(True)
plt.legend()
plt.show()
実行結果
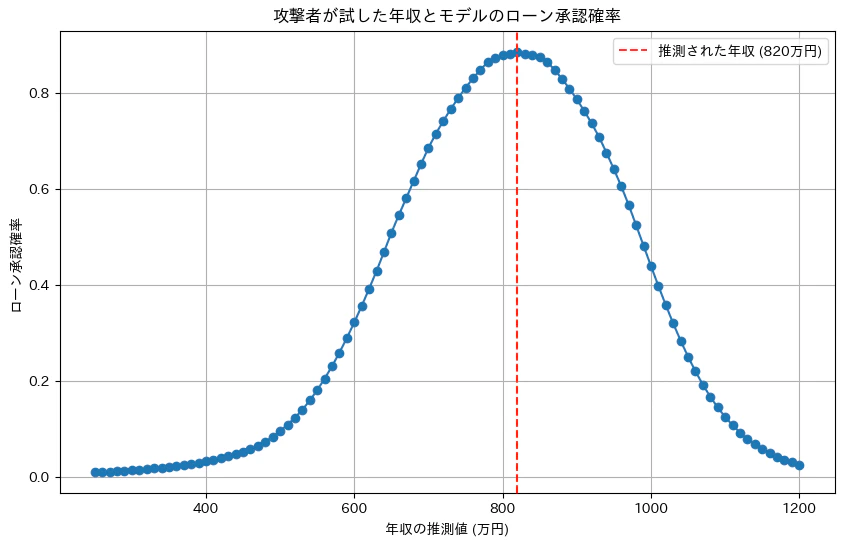
結果、800万円で承認確率が最大であるという山なりのカーブが得られた。
これは、学習データの「年収800万円付近の人のローン承認確率が高い」という分布の特徴が、モデルを通じて攻撃者に漏洩してしまったことを意味する。
この攻撃のポイントは、Aさんの正確な年収をピンポイントで当てることではない。モデルが学習したデータセットの「どういう人がローンを承認されやすいか」という統計的な傾向を盗み出すことで、そこからAさんの年収を高い確度で絞り込めてしまう点にある。
ここまでで、プライバシー攻撃によって、(当てずっぽうで年収を当てるよりも高精度に)年収を推測できそうであると言えそうである。 次は、差分プライバシー技術を使うことで、年収推測を困難にすることが可能なのか検証してみる。
差分プライバシー(今回はDP-SGD)でプライバシー保護できるかを検証する
DP-SGDと言う手法を今回は利用して、差分プライバシー技術による保護を検証してみる。 モデルの定義も合わせて行う。
# DP-SGDのパラメータ
max_grad_norm = 1.0
noise_multi = 1.0
microbatch_size = 1
# モデル
model_with_dpsgd = LoanModel().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_with_dpsgd.parameters(), lr=0.001)
DP-SGDでモデルを学習させる。
model_with_dpsgd.train()
for epoch in range(EPOCH_NUM):
for data, labels in loader:
accumulated = [torch.zeros_like(p) for p in model_with_dpsgd.parameters()] # INFO:マイクロバッチ毎の勾配を累積するための箱
data, labels = data.to(device), labels.to(device)
# マイクロバッチ毎に学習ループを回す
for i in range(0, data.size(0), microbatch_size):
xi, yi = data[i:i+microbatch_size], labels[i:i+microbatch_size]
optimizer.zero_grad()
outputs = model_with_dpsgd(xi)
loss = criterion(outputs, yi)
loss.backward()
# 勾配クリッピング (L2ノルム)
torch.nn.utils.clip_grad_norm_(model_with_dpsgd.parameters(), max_grad_norm)
# マイクロバッチの勾配を累積
for j, p in enumerate(model_with_dpsgd.parameters()):
if p.grad is not None:
accumulated[j] += p.grad.detach().clone()
# ミニバッチ全体の勾配に対してノイズを加える
# (opacusなどのライブラリを使うとより正確に実装できるが、勉強のために、ここではopacusを使わない)
batch_size = data.size(0)
scale = noise_multi * max_grad_norm / batch_size
for j, p in enumerate(model_with_dpsgd.parameters()):
if accumulated[j] is not None:
avg_grad = accumulated[j] / batch_size
noise = torch.randn_like(accumulated[j]) * scale
p.grad = avg_grad + noise # ノイズを加えた勾配をoptimizerに渡す
optimizer.step()
print(f"Epoch {epoch+1}/{EPOCH_NUM} complete")
DP-SGDは、通常のミニバッチ学習と少し異なる。1サンプル(1レコード)単位から計算した勾配がモデルに与える影響を一定以下に抑えるための処理が入る。
- ①勾配の計算とクリッピング:1サンプル毎に勾配を計算し、そのノルムが事前に設定した上限値(
max_grad_norm)を超えないようにクリッピングする。それを累積する。 - ②ノイズの付加とモデル更新:ミニバッチに含まれているサンプル全体に対して①を完了させたら、累積した勾配に対してノイズを付加する。この「ノイズが乗った」勾配を使って、モデルのパラメータを更新する。
攻撃を行う対象のデータを取得する(先ほどと同じ条件で取得する)。
model_with_dpsgd.eval()
# 攻撃対象のユーザとなる人物像(年齢と大卒資格の有無という2つ)の情報を取得する
target_idx = 5
df = df_master.copy()
target_user_features = df.iloc[target_idx]
# 攻撃者が知っている情報と知りたい情報
known_age = target_user_features["age"]
known_has_degree = target_user_features["has_degree"]
true_income = target_user_features["income"]
print(f"攻撃対象ユーザーの情報:")
print(f"既知: 年齢 = {known_age}, 大卒資格 = {'あり' if known_has_degree else 'なし'}")
実行結果
攻撃対象ユーザーの情報:
既知: 年齢 = 42, 大卒資格 = なし
差分プライバシーで学習したモデルに対して攻撃を行う。
# 年収を様々に変えてモデルに問い合わせる
potential_incomes = np.arange(250, 1201, 10) # 250万から1200万まで10万刻みで試す
approval_probabilities = []
for income_guess in potential_incomes:
# 問い合わせ用のデータを作成する
query_data = np.array(
[[known_age, income_guess, known_has_degree]],
dtype=np.float32
)
# モデル学習時と同じスケーラで標準化
query_scaled = torch.from_numpy(scaler.transform(query_data))
query_scaled = query_scaled.to(device)
# モデルの予測確率を取得
with torch.no_grad():
outputs = model_with_dpsgd(query_scaled)
probs = torch.softmax(outputs, dim=1)
approval_prob = probs[0,1].item()
approval_probabilities.append(approval_prob)
# 最も確率が高かった年収を推測結果とする
inferred_income_idx = np.argmax(approval_probabilities)
inferred_income = potential_incomes[inferred_income_idx]
print(f"攻撃による推測結果:")
print(f"参考:推測された年収: {inferred_income} 万円")
print(f"参考:実際の年収: {int(true_income)} 万円\n")
実行結果
攻撃による推測結果:
参考:推測された年収: 770 万円
参考:実際の年収: 953 万円
推測された年収が770万円で、先ほどは820万円であった。あまり変わっていない。
ただ、改めてであるが、この953万円を当てに行くわけではないので、これはあくまでも参考値で表示しているだけである。
攻撃者が得た年収に関する情報を可視化する。
# 攻撃者がtarget_idxのユーザについて得た結果を可視化
plt.figure(figsize=(10, 6))
plt.plot(potential_incomes, approval_probabilities, marker='o', linestyle='-')
plt.axvline(x=inferred_income, color='red', linestyle='--', label=f'推測された年収 ({inferred_income}万円)')
plt.title('攻撃者が試した年収とモデルのローン承認確率')
plt.xlabel('年収の推測値 (万円)')
plt.ylabel('ローン承認確率')
plt.grid(True)
plt.legend()
plt.show()
実行結果
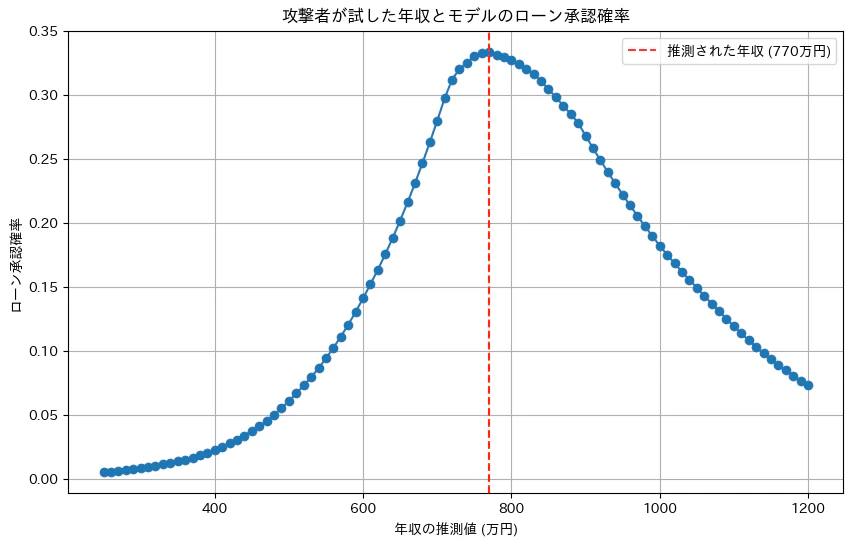
結果、DPなしの場合と同様に山なりのグラフになった。しかし、最も重要な違いは、グラフ全体の確率が大幅に低下している点である。DPなしのモデルでは85%近かったピーク時の確率が、今回は約33%にまで落ち込んでいる。
これは、攻撃者にとって「最も可能性の高い年収を特定できたとしても、その確率はわずか33%だ」ということを意味し、推測結果に対する確信度を著しく下げる効果がある。このようにして、差分プライバシーはモデルからの情報漏洩を防ぎ、プライバシーを保護することができる。
今回の結果から、差分プライバシーを使ったことで、攻撃者が知りたかった情報「年収」情報の推測が難しくなっていることを確認できた。 (※本来は、複数回の試行をした上で、統計学的な検定を実施した上で結論を出すべきである。しかし、今回は、筆者の勉強目的が主であるため、今回は一度の試行だけとしていることにご容赦いただきたい。)
まとめ
- 今回は、まず、差分プライバシー技術の概要の紹介を行った。次に、属性推論攻撃を行い、差分プライバシー技術として
DP-SGDを利用した場合にプライバシーの保護をどれくらい実現できるかを実験した。